 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Theoretical Justification for Image Inpainting using Denoising Diffusion Probabilistic Models
Feb 02, 2023
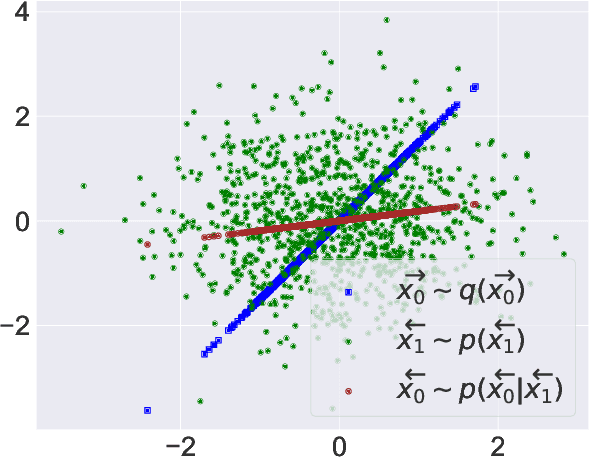
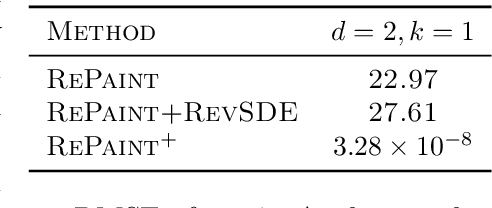
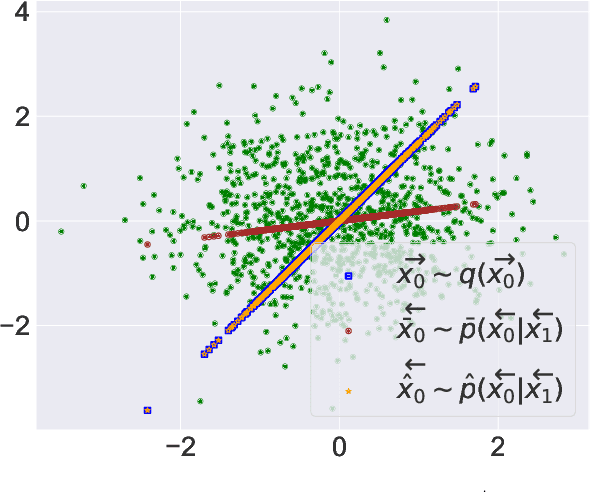
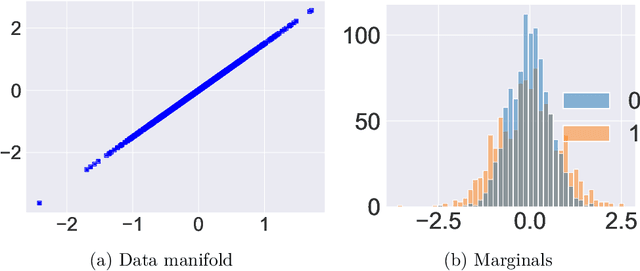
We provide a theoretical justification for sample recovery using diffusion based image inpainting in a linear model setting. While most inpainting algorithms require retraining with each new mask, we prove that diffusion based inpainting generalizes well to unseen masks without retraining. We analyze a recently proposed popular diffusion based inpainting algorithm called RePaint (Lugmayr et al., 2022), and show that it has a bias due to misalignment that hampers sample recovery even in a two-state diffusion process. Motivated by our analysis, we propose a modified RePaint algorithm we call RePaint$^+$ that provably recovers the underlying true sample and enjoys a linear rate of convergence. It achieves this by rectifying the misalignment error present in drift and dispersion of the reverse process. To the best of our knowledge, this is the first linear convergence result for a diffusion based image inpainting algorithm.
Figments and Misalignments: A Framework for Fine-grained Crossmodal Misinformation Detection
Apr 27, 2023
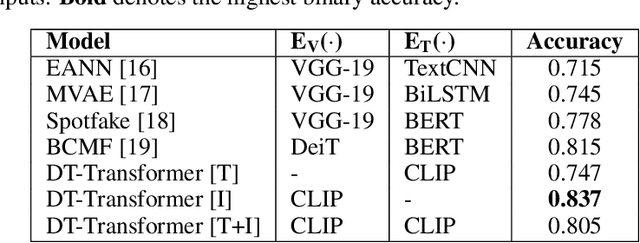
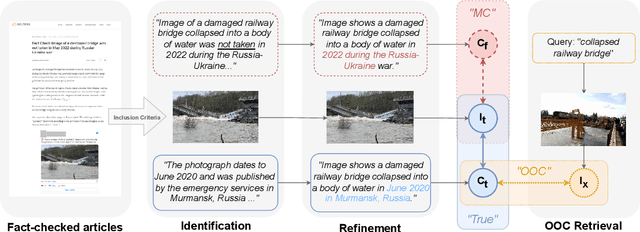
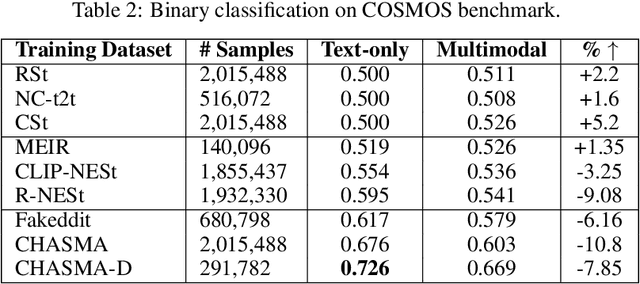
Multimedia content has become ubiquitous on social media platforms, leading to the rise of multimodal misinformation and the urgent need for effective strategies to detect and prevent its spread. This study focuses on CrossModal Misinformation (CMM) where image-caption pairs work together to spread falsehoods. We contrast CMM with Asymmetric Multimodal Misinformation (AMM), where one dominant modality propagates falsehoods while other modalities have little or no influence. We show that AMM adds noise to the training and evaluation process while exacerbating the unimodal bias, where text-only or image-only detectors can seemingly outperform their multimodal counterparts on an inherently multimodal task. To address this issue, we collect and curate FIGMENTS, a robust evaluation benchmark for CMM, which consists of real world cases of misinformation, excludes AMM and utilizes modality balancing to successfully alleviate unimodal bias. FIGMENTS also provides a first step towards fine-grained CMM detection by including three classes: truthful, out-of-context, and miscaptioned image-caption pairs. Furthermore, we introduce a method for generating realistic synthetic training data that maintains crossmodal relations between legitimate images and false human-written captions that we term Crossmodal HArd Synthetic MisAlignment (CHASMA). We conduct extensive comparative study using a Transformer-based architecture. Our results show that incorporating CHASMA in conjunction with other generated datasets consistently improved the overall performance on FIGMENTS in both binary (+6.26%) and multiclass settings (+15.8%).We release our code at: https://github.com/stevejpapad/figments-and-misalignments
A Generalized Framework for Critical Heat Flux Detection Using Unsupervised Image-to-Image Translation
Dec 25, 2022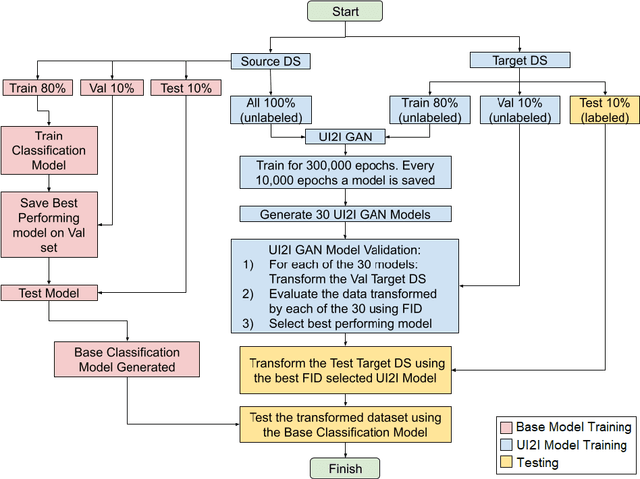
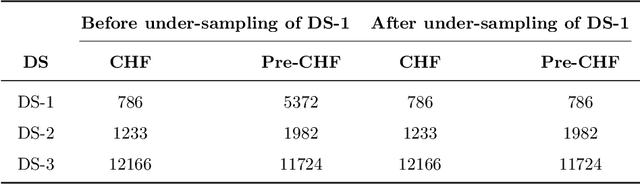
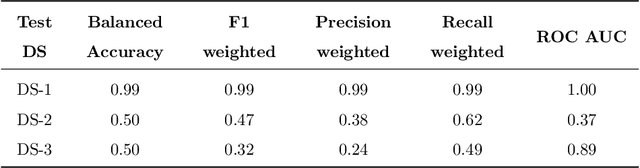

This work proposes a framework developed to generalize Critical Heat Flux (CHF) detection classification models using an Unsupervised Image-to-Image (UI2I) translation model. The framework enables a typical classification model that was trained and tested on boiling images from domain A to predict boiling images coming from domain B that was never seen by the classification model. This is done by using the UI2I model to transform the domain B images to look like domain A images that the classification model is familiar with. Although CNN was used as the classification model and Fixed-Point GAN (FP-GAN) was used as the UI2I model, the framework is model agnostic. Meaning, that the framework can generalize any image classification model type, making it applicable to a variety of similar applications and not limited to the boiling crisis detection problem. It also means that the more the UI2I models advance, the better the performance of the framework.
Stable Attribute Group Editing for Reliable Few-shot Image Generation
Feb 01, 2023
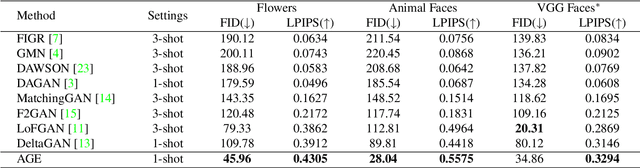
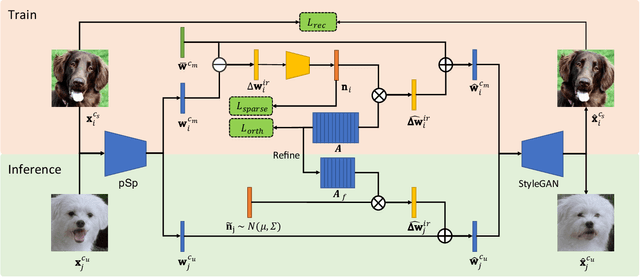
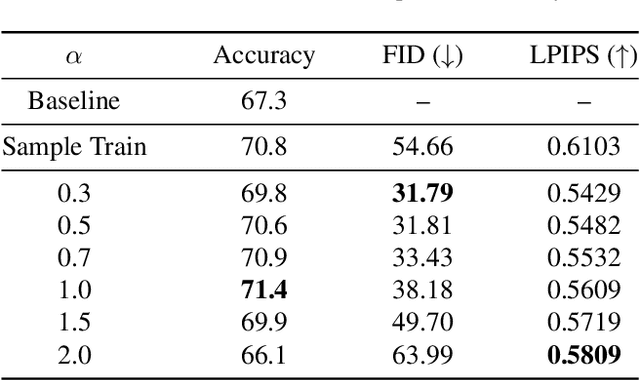
Few-shot image generation aims to generate data of an unseen category based on only a few samples. Apart from basic content generation, a bunch of downstream applications hopefully benefit from this task, such as low-data detection and few-shot classification. To achieve this goal, the generated images should guarantee category retention for classification beyond the visual quality and diversity. In our preliminary work, we present an ``editing-based'' framework Attribute Group Editing (AGE) for reliable few-shot image generation, which largely improves the generation performance. Nevertheless, AGE's performance on downstream classification is not as satisfactory as expected. This paper investigates the class inconsistency problem and proposes Stable Attribute Group Editing (SAGE) for more stable class-relevant image generation. SAGE takes use of all given few-shot images and estimates a class center embedding based on the category-relevant attribute dictionary. Meanwhile, according to the projection weights on the category-relevant attribute dictionary, we can select category-irrelevant attributes from the similar seen categories. Consequently, SAGE injects the whole distribution of the novel class into StyleGAN's latent space, thus largely remains the category retention and stability of the generated images. Going one step further, we find that class inconsistency is a common problem in GAN-generated images for downstream classification. Even though the generated images look photo-realistic and requires no category-relevant editing, they are usually of limited help for downstream classification. We systematically discuss this issue from both the generative model and classification model perspectives, and propose to boost the downstream classification performance of SAGE by enhancing the pixel and frequency components.
SDVRF: Sparse-to-Dense Voxel Region Fusion for Multi-modal 3D Object Detection
May 02, 2023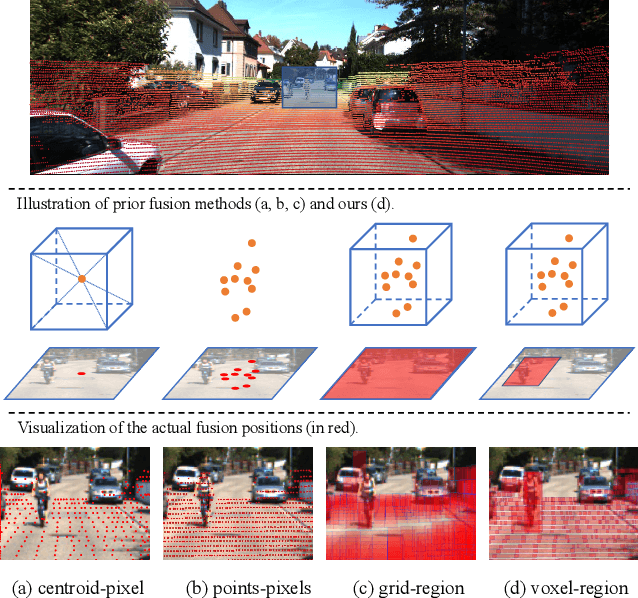
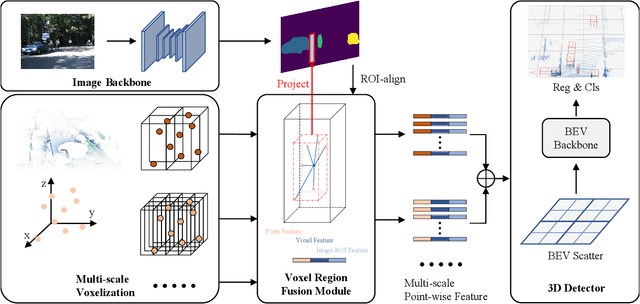
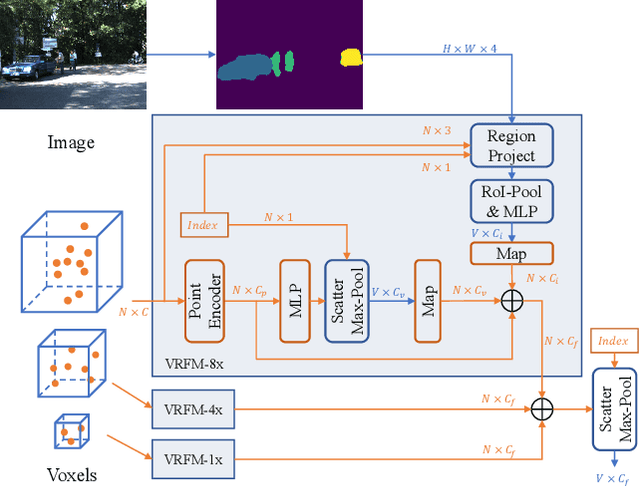

In the perception task of autonomous driving, multi-modal methods have become a trend due to the complementary characteristics of LiDAR point clouds and image data. However, the performance of previous methods is usually limited by the sparsity of the point cloud or the noise problem caused by the misalignment between LiDAR and the camera. To solve these two problems, we present a new concept, Voxel Region (VR), which is obtained by projecting the sparse local point clouds in each voxel dynamically. And we propose a novel fusion method, named Sparse-to-Dense Voxel Region Fusion (SDVRF). Specifically, more pixels of the image feature map inside the VR are gathered to supplement the voxel feature extracted from sparse points and achieve denser fusion. Meanwhile, different from prior methods, which project the size-fixed grids, our strategy of generating dynamic regions achieves better alignment and avoids introducing too much background noise. Furthermore, we propose a multi-scale fusion framework to extract more contextual information and capture the features of objects of different sizes. Experiments on the KITTI dataset show that our method improves the performance of different baselines, especially on classes of small size, including Pedestrian and Cyclist.
Universal Domain Adaptation for Remote Sensing Image Scene Classification
Jan 26, 2023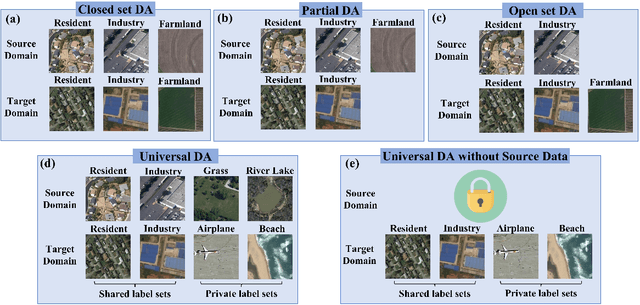
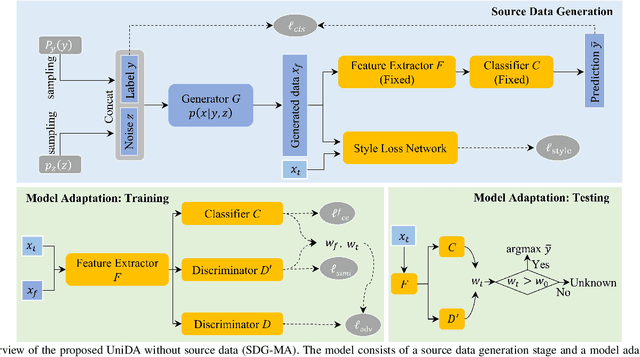

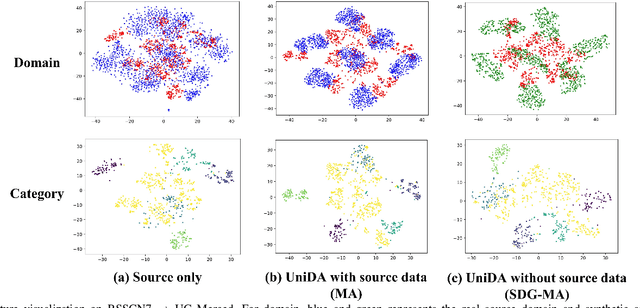
The domain adaptation (DA) approaches available to date are usually not well suited for practical DA scenarios of remote sensing image classification, since these methods (such as unsupervised DA) rely on rich prior knowledge about the relationship between label sets of source and target domains, and source data are often not accessible due to privacy or confidentiality issues. To this end, we propose a practical universal domain adaptation setting for remote sensing image scene classification that requires no prior knowledge on the label sets. Furthermore, a novel universal domain adaptation method without source data is proposed for cases when the source data is unavailable. The architecture of the model is divided into two parts: the source data generation stage and the model adaptation stage. The first stage estimates the conditional distribution of source data from the pre-trained model using the knowledge of class-separability in the source domain and then synthesizes the source data. With this synthetic source data in hand, it becomes a universal DA task to classify a target sample correctly if it belongs to any category in the source label set, or mark it as ``unknown" otherwise. In the second stage, a novel transferable weight that distinguishes the shared and private label sets in each domain promotes the adaptation in the automatically discovered shared label set and recognizes the ``unknown'' samples successfully. Empirical results show that the proposed model is effective and practical for remote sensing image scene classification, regardless of whether the source data is available or not. The code is available at https://github.com/zhu-xlab/UniDA.
A metric to compare the anatomy variation between image time series
Feb 23, 2023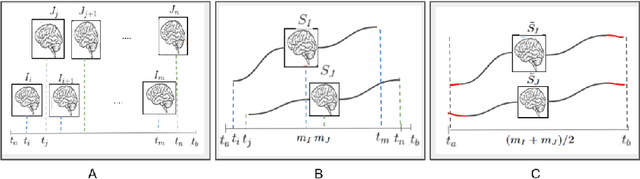
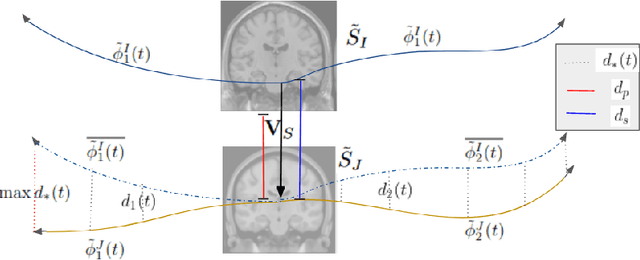
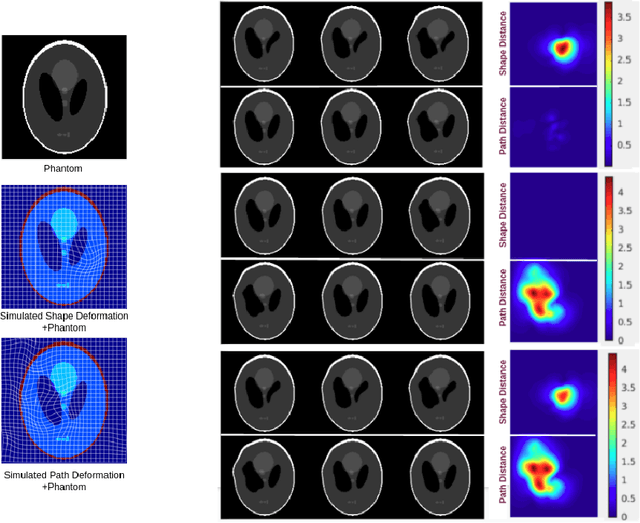
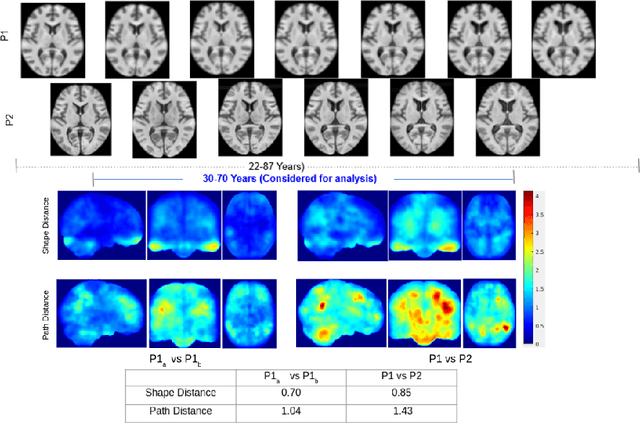
Biological processes like growth, aging, and disease progression are generally studied with follow-up scans taken at different time points, i.e., with image time series (TS) based analysis. Comparison between TS representing a biological process of two individuals/populations is of interest. A metric to quantify the difference between TS is desirable for such a comparison. The two TS represent the evolution of two different subject/population average anatomies through two paths. A method to untangle and quantify the path and inter-subject anatomy(shape) difference between the TS is presented in this paper. The proposed metric is a generalized version of Fr\'echet distance designed to compare curves. The proposed method is evaluated with simulated and adult and fetal neuro templates. Results show that the metric is able to separate and quantify the path and shape differences between TS.
RSA-INR: Riemannian Shape Autoencoding via 4D Implicit Neural Representations
May 22, 2023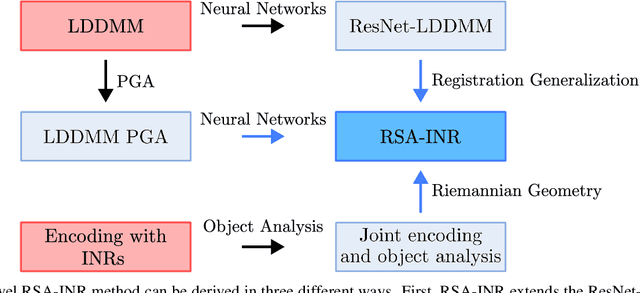

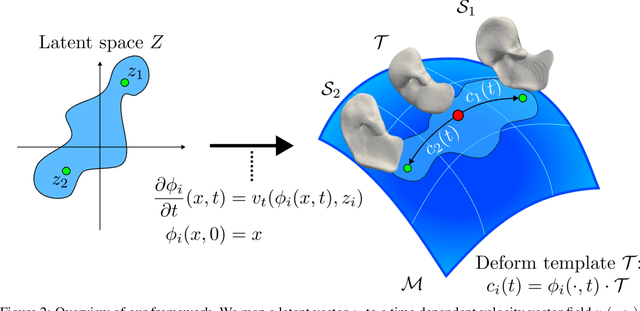
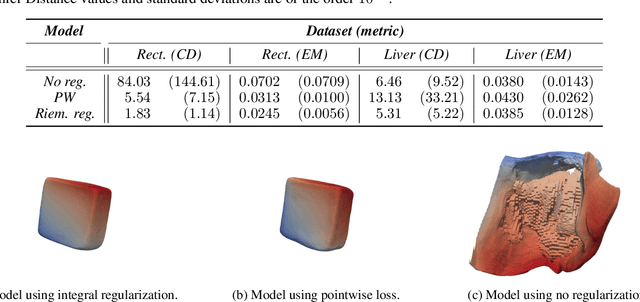
Shape encoding and shape analysis are valuable tools for comparing shapes and for dimensionality reduction. A specific framework for shape analysis is the Large Deformation Diffeomorphic Metric Mapping (LDDMM) framework, which is capable of shape matching and dimensionality reduction. Researchers have recently introduced neural networks into this framework. However, these works can not match more than two objects simultaneously or have suboptimal performance in shape variability modeling. The latter limitation occurs as the works do not use state-of-the-art shape encoding methods. Moreover, the literature does not discuss the connection between the LDDMM Riemannian distance and the Riemannian geometry for deep learning literature. Our work aims to bridge this gap by demonstrating how LDDMM can integrate Riemannian geometry into deep learning. Furthermore, we discuss how deep learning solves and generalizes shape matching and dimensionality reduction formulations of LDDMM. We achieve both goals by designing a novel implicit encoder for shapes. This model extends a neural network-based algorithm for LDDMM-based pairwise registration, results in a nonlinear manifold PCA, and adds a Riemannian geometry aspect to deep learning models for shape variability modeling. Additionally, we demonstrate that the Riemannian geometry component improves the reconstruction procedure of the implicit encoder in terms of reconstruction quality and stability to noise. We hope our discussion paves the way to more research into how Riemannian geometry, shape/image analysis, and deep learning can be combined.
LaMD: Latent Motion Diffusion for Video Generation
Apr 23, 2023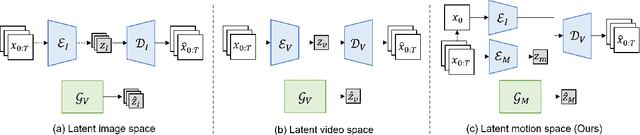

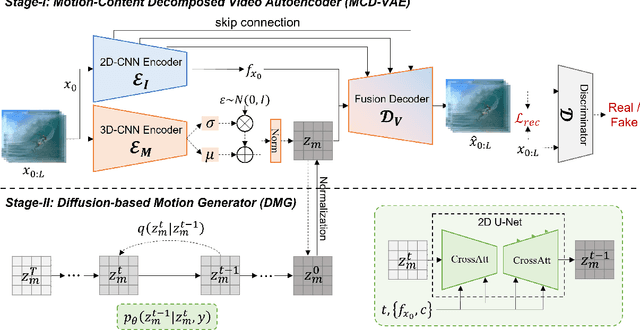
Generating coherent and natural movement is the key challenge in video generation. This research proposes to condense video generation into a problem of motion generation, to improve the expressiveness of motion and make video generation more manageable. This can be achieved by breaking down the video generation process into latent motion generation and video reconstruction. We present a latent motion diffusion (LaMD) framework, which consists of a motion-decomposed video autoencoder and a diffusion-based motion generator, to implement this idea. Through careful design, the motion-decomposed video autoencoder can compress patterns in movement into a concise latent motion representation. Meanwhile, the diffusion-based motion generator is able to efficiently generate realistic motion on a continuous latent space under multi-modal conditions, at a cost that is similar to that of image diffusion models. Results show that LaMD generates high-quality videos with a wide range of motions, from stochastic dynamics to highly controllable movements. It achieves new state-of-the-art performance on benchmark datasets, including BAIR, Landscape and CATER-GENs, for Image-to-Video (I2V) and Text-Image-to-Video (TI2V) generation. The source code of LaMD will be made available soon.
Progressive Learning of 3D Reconstruction Network from 2D GAN Data
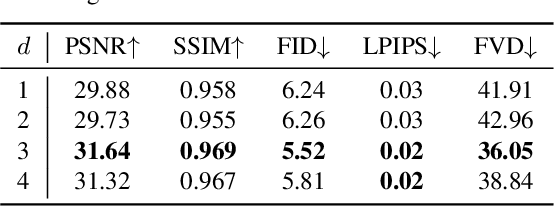
May 18, 2023
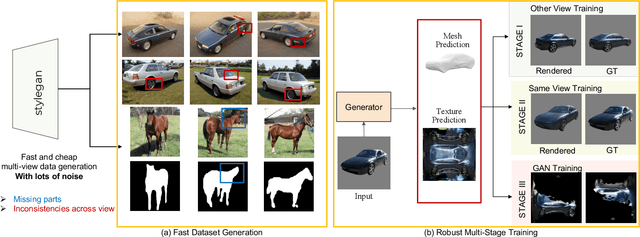
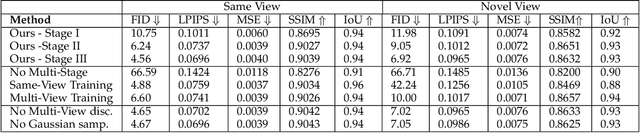
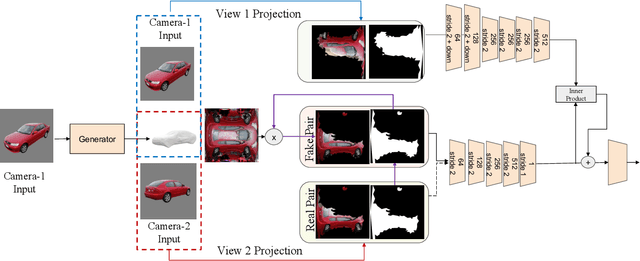
This paper presents a method to reconstruct high-quality textured 3D models from single images. Current methods rely on datasets with expensive annotations; multi-view images and their camera parameters. Our method relies on GAN generated multi-view image datasets which have a negligible annotation cost. However, they are not strictly multi-view consistent and sometimes GANs output distorted images. This results in degraded reconstruction qualities. In this work, to overcome these limitations of generated datasets, we have two main contributions which lead us to achieve state-of-the-art results on challenging objects: 1) A robust multi-stage learning scheme that gradually relies more on the models own predictions when calculating losses, 2) A novel adversarial learning pipeline with online pseudo-ground truth generations to achieve fine details. Our work provides a bridge from 2D supervisions of GAN models to 3D reconstruction models and removes the expensive annotation efforts. We show significant improvements over previous methods whether they were trained on GAN generated multi-view images or on real images with expensive annotations. Please visit our web-page for 3D visuals: https://research.nvidia.com/labs/adlr/progressive-3d-learning