 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Deep Learning Applications Based on WISE Infrared Data: Classification of Stars, Galaxies and Quasars
May 17, 2023

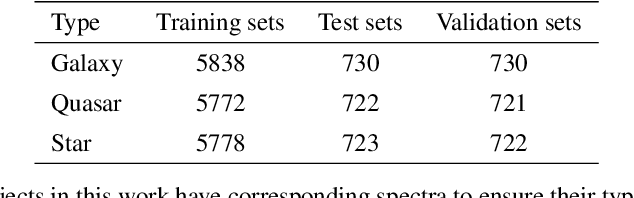
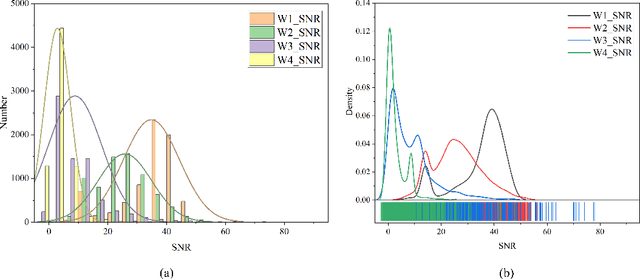
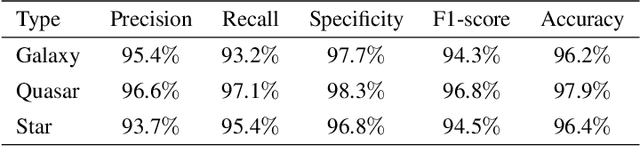
The Wide-field Infrared Survey Explorer (WISE) has detected hundreds of millions of sources over the entire sky. However, classifying them reliably is a great challenge due to degeneracies in WISE multicolor space and low detection levels in its two longest-wavelength bandpasses. In this paper, the deep learning classification network, IICnet (Infrared Image Classification network), is designed to classify sources from WISE images to achieve a more accurate classification goal. IICnet shows good ability on the feature extraction of the WISE sources. Experiments demonstrates that the classification results of IICnet are superior to some other methods; it has obtained 96.2% accuracy for galaxies, 97.9% accuracy for quasars, and 96.4% accuracy for stars, and the Area Under Curve (AUC) of the IICnet classifier can reach more than 99%. In addition, the superiority of IICnet in processing infrared images has been demonstrated in the comparisons with VGG16, GoogleNet, ResNet34, MobileNet, EfficientNetV2, and RepVGG-fewer parameters and faster inference. The above proves that IICnet is an effective method to classify infrared sources.
DualVector: Unsupervised Vector Font Synthesis with Dual-Part Representation
May 17, 2023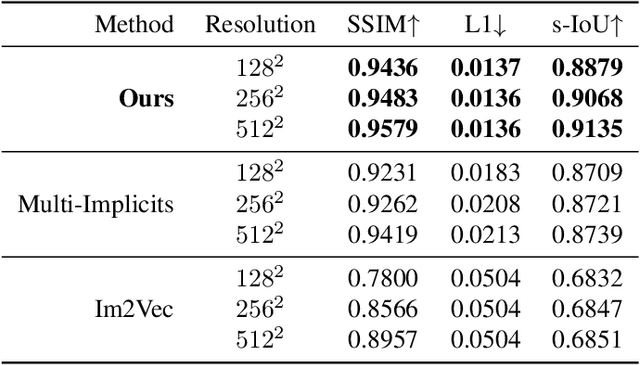

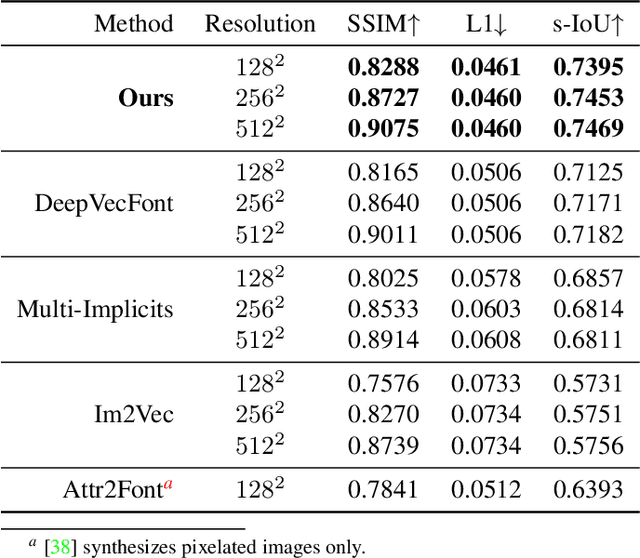

Automatic generation of fonts can be an important aid to typeface design. Many current approaches regard glyphs as pixelated images, which present artifacts when scaling and inevitable quality losses after vectorization. On the other hand, existing vector font synthesis methods either fail to represent the shape concisely or require vector supervision during training. To push the quality of vector font synthesis to the next level, we propose a novel dual-part representation for vector glyphs, where each glyph is modeled as a collection of closed "positive" and "negative" path pairs. The glyph contour is then obtained by boolean operations on these paths. We first learn such a representation only from glyph images and devise a subsequent contour refinement step to align the contour with an image representation to further enhance details. Our method, named DualVector, outperforms state-of-the-art methods in vector font synthesis both quantitatively and qualitatively. Our synthesized vector fonts can be easily converted to common digital font formats like TrueType Font for practical use. The code is released at https://github.com/thuliu-yt16/dualvector.
ADS_UNet: A Nested UNet for Histopathology Image Segmentation
Apr 10, 2023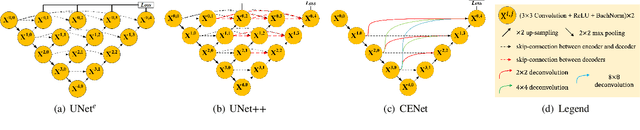
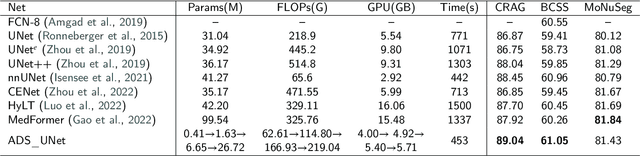
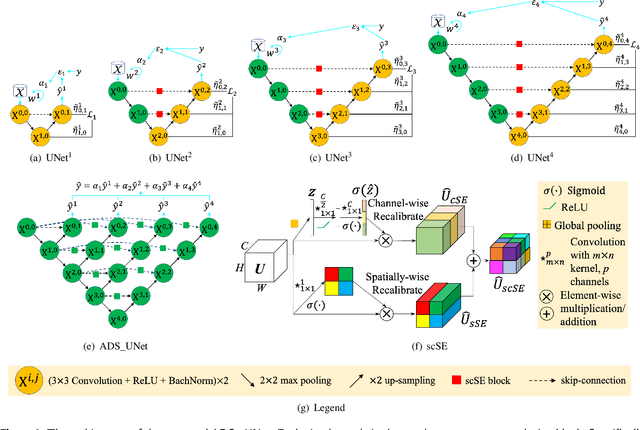

The UNet model consists of fully convolutional network (FCN) layers arranged as contracting encoder and upsampling decoder maps. Nested arrangements of these encoder and decoder maps give rise to extensions of the UNet model, such as UNete and UNet++. Other refinements include constraining the outputs of the convolutional layers to discriminate between segment labels when trained end to end, a property called deep supervision. This reduces feature diversity in these nested UNet models despite their large parameter space. Furthermore, for texture segmentation, pixel correlations at multiple scales contribute to the classification task; hence, explicit deep supervision of shallower layers is likely to enhance performance. In this paper, we propose ADS UNet, a stage-wise additive training algorithm that incorporates resource-efficient deep supervision in shallower layers and takes performance-weighted combinations of the sub-UNets to create the segmentation model. We provide empirical evidence on three histopathology datasets to support the claim that the proposed ADS UNet reduces correlations between constituent features and improves performance while being more resource efficient. We demonstrate that ADS_UNet outperforms state-of-the-art Transformer-based models by 1.08 and 0.6 points on CRAG and BCSS datasets, and yet requires only 37% of GPU consumption and 34% of training time as that required by Transformers.
Improving Statistical Fidelity for Neural Image Compression with Implicit Local Likelihood Models
Jan 28, 2023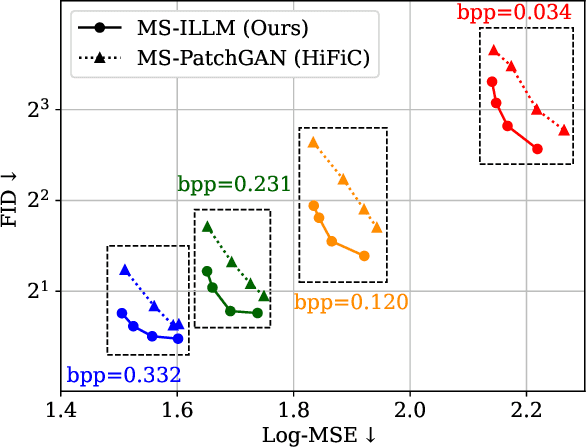
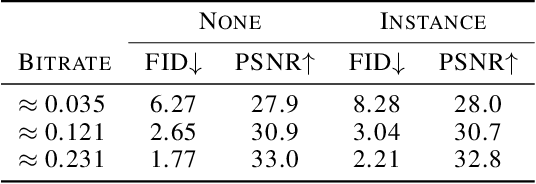
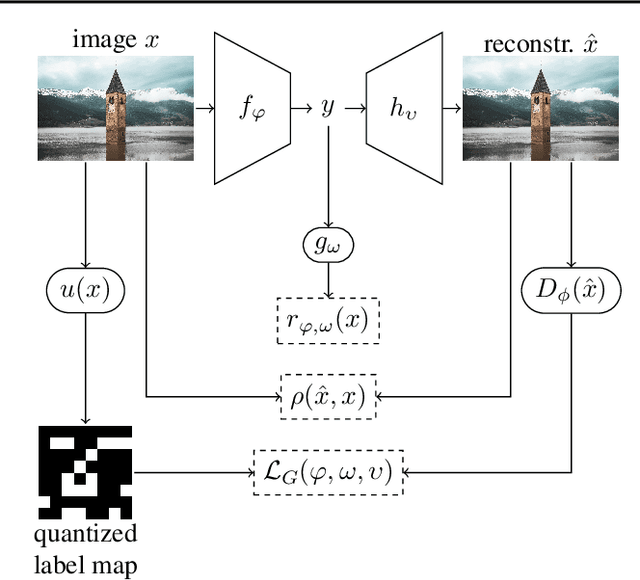

Lossy image compression aims to represent images in as few bits as possible while maintaining fidelity to the original. Theoretical results indicate that optimizing distortion metrics such as PSNR or MS-SSIM necessarily leads to a discrepancy in the statistics of original images from those of reconstructions, in particular at low bitrates, often manifested by the blurring of the compressed images. Previous work has leveraged adversarial discriminators to improve statistical fidelity. Yet these binary discriminators adopted from generative modeling tasks may not be ideal for image compression. In this paper, we introduce a non-binary discriminator that is conditioned on quantized local image representations obtained via VQ-VAE autoencoders. Our evaluations on the CLIC2020, DIV2K and Kodak datasets show that our discriminator is more effective for jointly optimizing distortion (e.g., PSNR) and statistical fidelity (e.g., FID) than the state-of-the-art HiFiC model. On the CLIC2020 test set, we obtain the same FID as HiFiC with 30-40% fewer bits.
Improving CT Image Segmentation Accuracy Using StyleGAN Driven Data Augmentation
Feb 07, 2023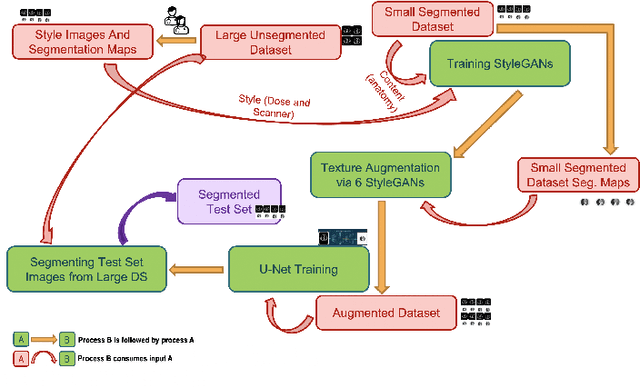
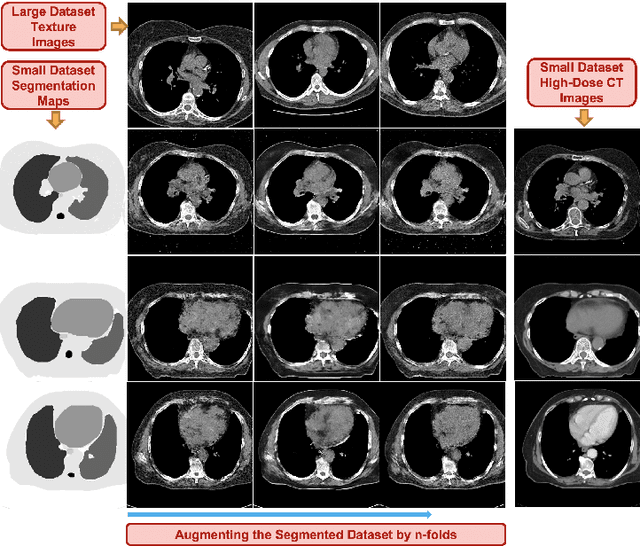

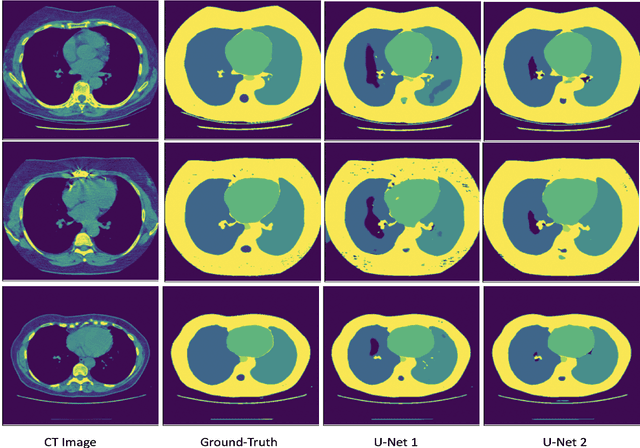
Medical Image Segmentation is a useful application for medical image analysis including detecting diseases and abnormalities in imaging modalities such as MRI, CT etc. Deep learning has proven to be promising for this task but usually has a low accuracy because of the lack of appropriate publicly available annotated or segmented medical datasets. In addition, the datasets that are available may have a different texture because of different dosage values or scanner properties than the images that need to be segmented. This paper presents a StyleGAN-driven approach for segmenting publicly available large medical datasets by using readily available extremely small annotated datasets in similar modalities. The approach involves augmenting the small segmented dataset and eliminating texture differences between the two datasets. The dataset is augmented by being passed through six different StyleGANs that are trained on six different style images taken from the large non-annotated dataset we want to segment. Specifically, style transfer is used to augment the training dataset. The annotations of the training dataset are hence combined with the textures of the non-annotated dataset to generate new anatomically sound images. The augmented dataset is then used to train a U-Net segmentation network which displays a significant improvement in the segmentation accuracy in segmenting the large non-annotated dataset.
Deep Learning-Based UAV Aerial Triangulation without Image Control Points
Jan 07, 2023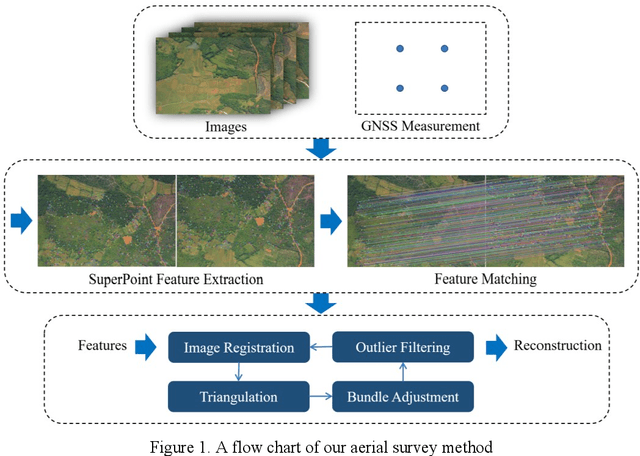
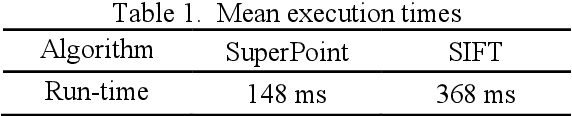
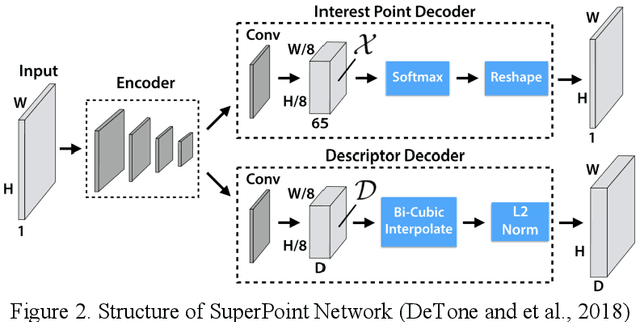
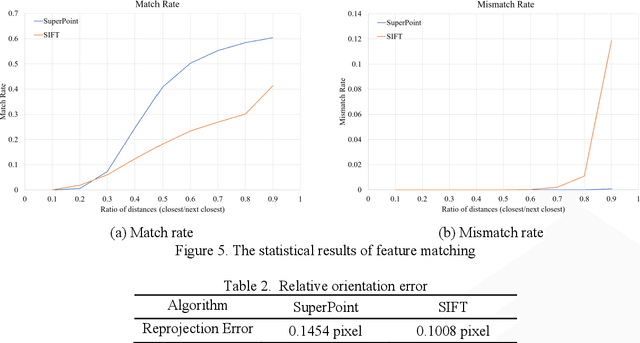
The emerging drone aerial survey has the advantages of low cost, high efficiency, and flexible use. However, UAVs are often equipped with cheap POS systems and non-measurement cameras, and their flight attitudes are easily affected. How to realize the large-scale mapping of UAV image-free control supported by POS faces many technical problems. The most basic and important core technology is how to accurately realize the absolute orientation of images through advanced aerial triangulation technology. In traditional aerial triangulation, image matching algorithms are constrained to varying degrees by preset prior knowledge. In recent years, deep learning has developed rapidly in the field of photogrammetric computer vision. It has surpassed the performance of traditional handcrafted features in many aspects. It has shown stronger stability in image-based navigation and positioning tasks, especially it has better resistance to unfavorable factors such as blur, illumination changes, and geometric distortion. Based on the introduction of the key technologies of aerial triangulation without image control points, this paper proposes a new drone image registration method based on deep learning image features to solve the problem of high mismatch rate in traditional methods. It adopts SuperPoint as the feature detector, uses the superior generalization performance of CNN to extract precise feature points from the UAV image, thereby achieving high-precision aerial triangulation. Experimental results show that under the same pre-processing and post-processing conditions, compared with the traditional method based on the SIFT algorithm, this method achieves suitable precision more efficiently, which can meet the requirements of UAV aerial triangulation without image control points in large-scale surveys.
Frequency-aware Learned Image Compression for Quality Scalability
Jan 03, 2023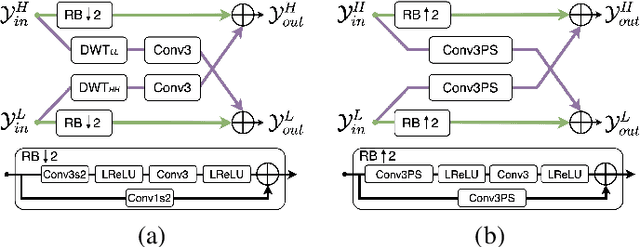
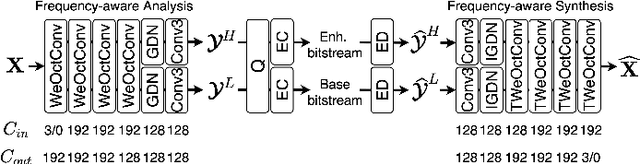

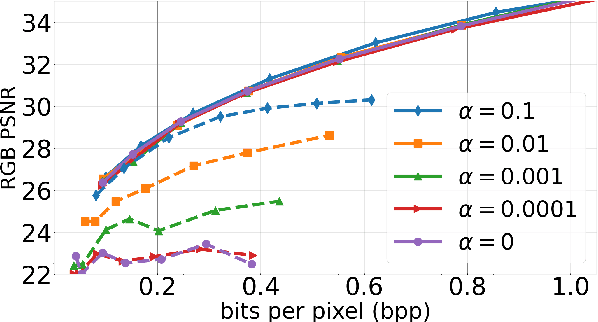
Spatial frequency analysis and transforms serve a central role in most engineered image and video lossy codecs, but are rarely employed in neural network (NN)-based approaches. We propose a novel NN-based image coding framework that utilizes forward wavelet transforms to decompose the input signal by spatial frequency. Our encoder generates separate bitstreams for each latent representation of low and high frequencies. This enables our decoder to selectively decode bitstreams in a quality-scalable manner. Hence, the decoder can produce an enhanced image by using an enhancement bitstream in addition to the base bitstream. Furthermore, our method is able to enhance only a specific region of interest (ROI) by using a corresponding part of the enhancement latent representation. Our experiments demonstrate that the proposed method shows competitive rate-distortion performance compared to several non-scalable image codecs. We also showcase the effectiveness of our two-level quality scalability, as well as its practicality in ROI quality enhancement.
Vision Learners Meet Web Image-Text Pairs
Jan 17, 2023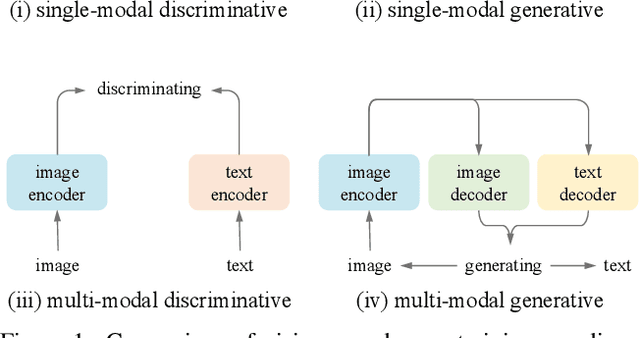
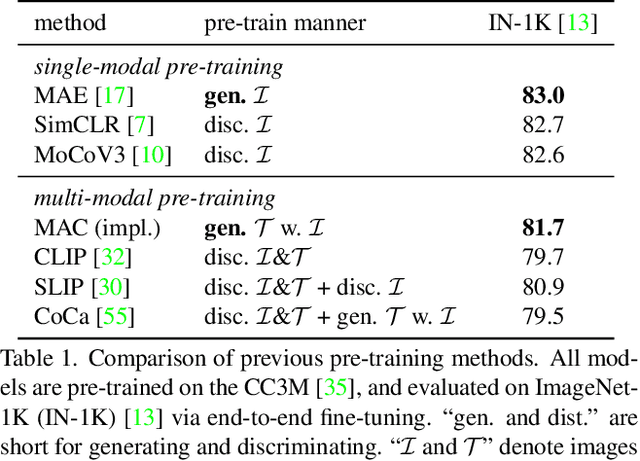

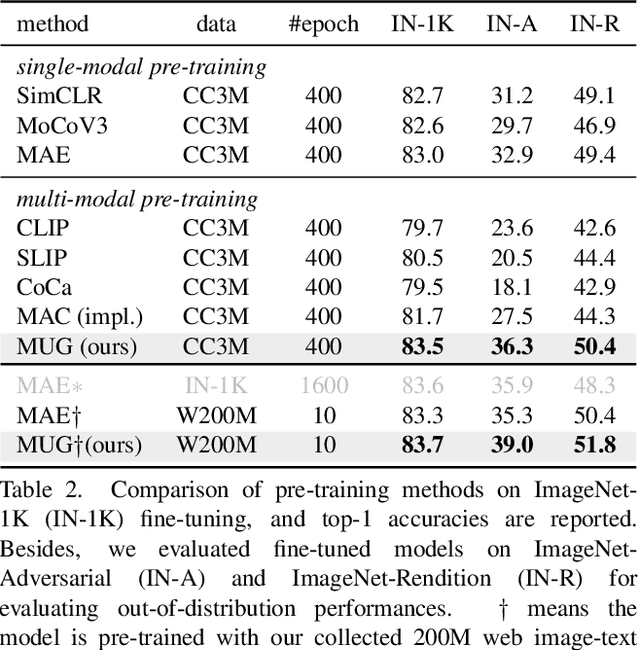
Most recent self-supervised learning~(SSL) methods are pre-trained on the well-curated ImageNet-1K dataset. In this work, we consider SSL pre-training on noisy web image-text paired data due to the excellent scalability of web data. First, we conduct a benchmark study of representative SSL pre-training methods on large-scale web data in a fair condition. Methods include single-modal ones such as MAE and multi-modal ones such as CLIP. We observe that multi-modal methods cannot outperform single-modal ones on vision transfer learning tasks. We derive an information-theoretical view to explain the benchmarking results, which provides insights into designing novel vision learners. Inspired by the above explorations, we present a visual representation pre-training method, MUlti-modal Generator~(MUG), for scalable web image-text data. MUG achieves state-of-the-art transferring performances on a variety of tasks and shows promising scaling behavior. Models and codes will be made public. Demo available at https://huggingface.co/spaces/tennant/MUG_caption
Towards Local Visual Modeling for Image Captioning
Feb 13, 2023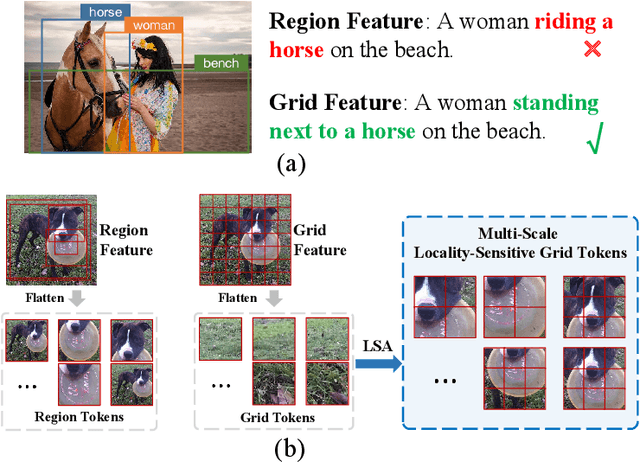
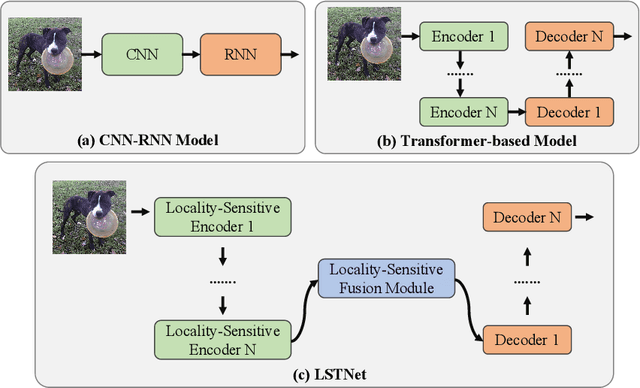
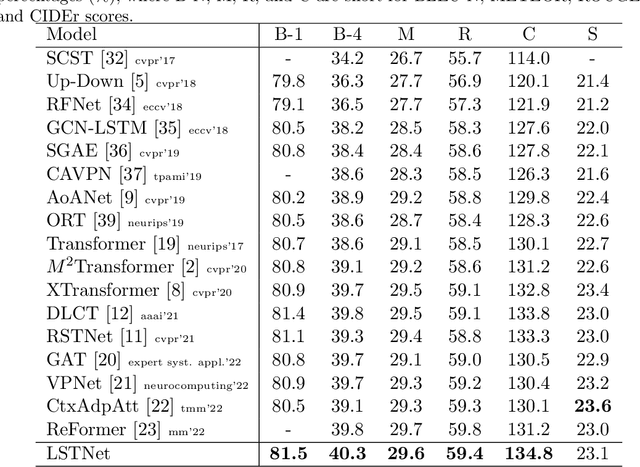
In this paper, we study the local visual modeling with grid features for image captioning, which is critical for generating accurate and detailed captions. To achieve this target, we propose a Locality-Sensitive Transformer Network (LSTNet) with two novel designs, namely Locality-Sensitive Attention (LSA) and Locality-Sensitive Fusion (LSF). LSA is deployed for the intra-layer interaction in Transformer via modeling the relationship between each grid and its neighbors. It reduces the difficulty of local object recognition during captioning. LSF is used for inter-layer information fusion, which aggregates the information of different encoder layers for cross-layer semantical complementarity. With these two novel designs, the proposed LSTNet can model the local visual information of grid features to improve the captioning quality. To validate LSTNet, we conduct extensive experiments on the competitive MS-COCO benchmark. The experimental results show that LSTNet is not only capable of local visual modeling, but also outperforms a bunch of state-of-the-art captioning models on offline and online testings, i.e., 134.8 CIDEr and 136.3 CIDEr, respectively. Besides, the generalization of LSTNet is also verified on the Flickr8k and Flickr30k datasets
Paced-Curriculum Distillation with Prediction and Label Uncertainty for Image Segmentation
Feb 02, 2023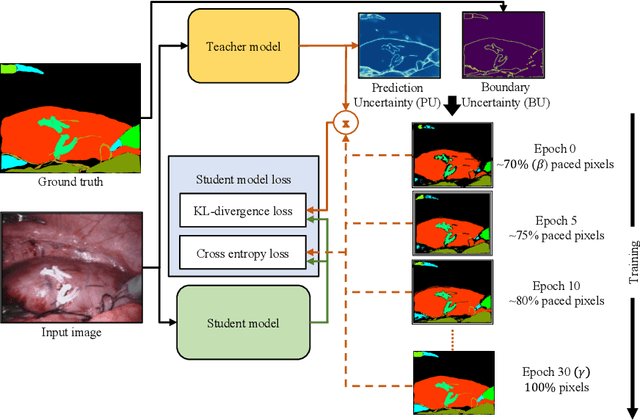
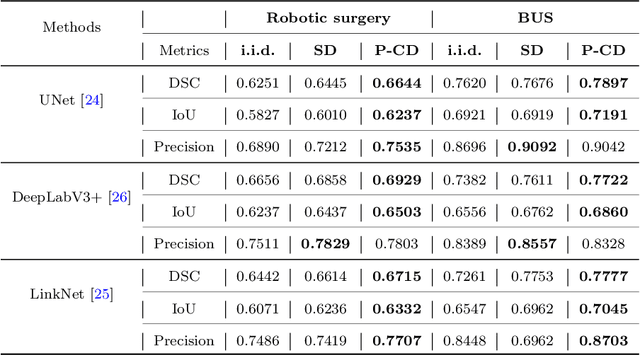
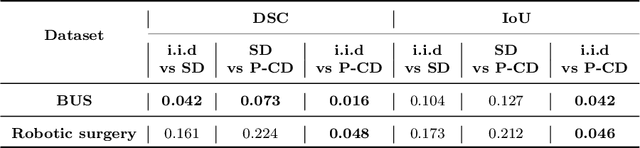

Purpose: In curriculum learning, the idea is to train on easier samples first and gradually increase the difficulty, while in self-paced learning, a pacing function defines the speed to adapt the training progress. While both methods heavily rely on the ability to score the difficulty of data samples, an optimal scoring function is still under exploration. Methodology: Distillation is a knowledge transfer approach where a teacher network guides a student network by feeding a sequence of random samples. We argue that guiding student networks with an efficient curriculum strategy can improve model generalization and robustness. For this purpose, we design an uncertainty-based paced curriculum learning in self distillation for medical image segmentation. We fuse the prediction uncertainty and annotation boundary uncertainty to develop a novel paced-curriculum distillation (PCD). We utilize the teacher model to obtain prediction uncertainty and spatially varying label smoothing with Gaussian kernel to generate segmentation boundary uncertainty from the annotation. We also investigate the robustness of our method by applying various types and severity of image perturbation and corruption. Results: The proposed technique is validated on two medical datasets of breast ultrasound image segmentation and robotassisted surgical scene segmentation and achieved significantly better performance in terms of segmentation and robustness. Conclusion: P-CD improves the performance and obtains better generalization and robustness over the dataset shift. While curriculum learning requires extensive tuning of hyper-parameters for pacing function, the level of performance improvement suppresses this limitation.