 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
NerfDiff: Single-image View Synthesis with NeRF-guided Distillation from 3D-aware Diffusion
Feb 20, 2023
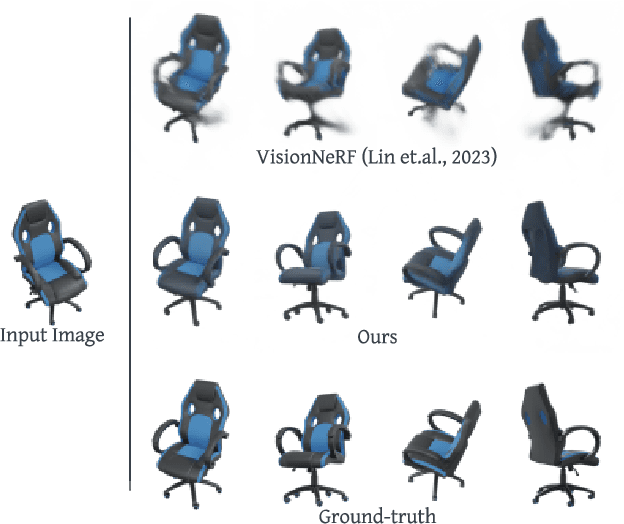
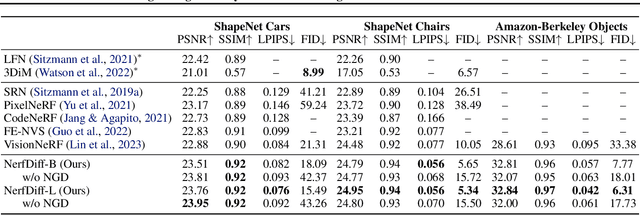
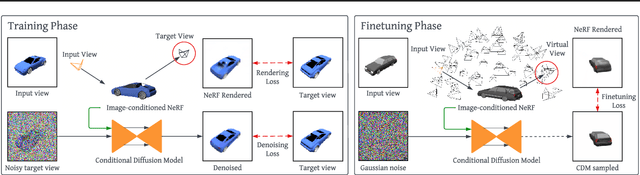
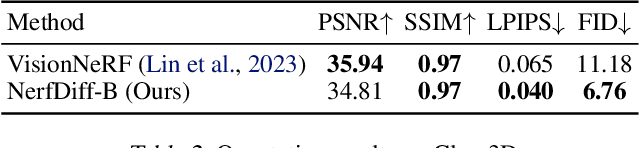
Novel view synthesis from a single image requires inferring occluded regions of objects and scenes whilst simultaneously maintaining semantic and physical consistency with the input. Existing approaches condition neural radiance fields (NeRF) on local image features, projecting points to the input image plane, and aggregating 2D features to perform volume rendering. However, under severe occlusion, this projection fails to resolve uncertainty, resulting in blurry renderings that lack details. In this work, we propose NerfDiff, which addresses this issue by distilling the knowledge of a 3D-aware conditional diffusion model (CDM) into NeRF through synthesizing and refining a set of virtual views at test time. We further propose a novel NeRF-guided distillation algorithm that simultaneously generates 3D consistent virtual views from the CDM samples, and finetunes the NeRF based on the improved virtual views. Our approach significantly outperforms existing NeRF-based and geometry-free approaches on challenging datasets, including ShapeNet, ABO, and Clevr3D.
LIBERO: Benchmarking Knowledge Transfer for Lifelong Robot Learning
Jun 05, 2023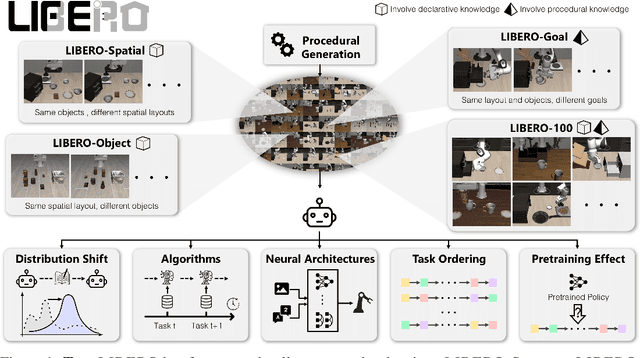
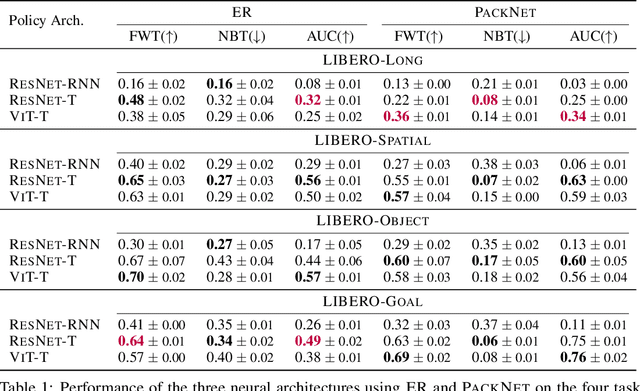
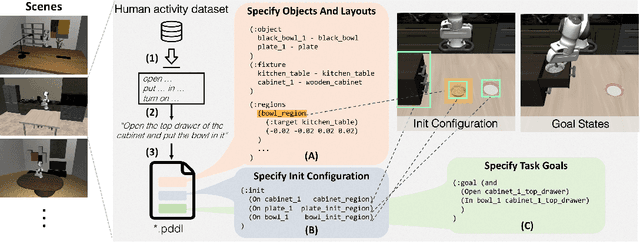
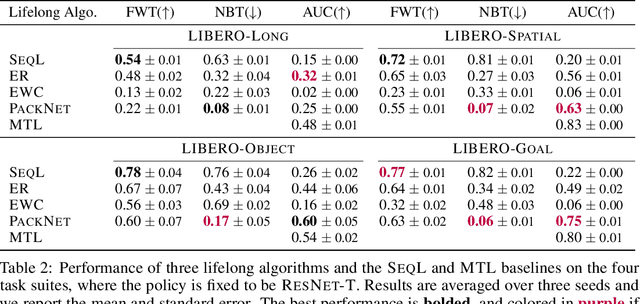
Lifelong learning offers a promising paradigm of building a generalist agent that learns and adapts over its lifespan. Unlike traditional lifelong learning problems in image and text domains, which primarily involve the transfer of declarative knowledge of entities and concepts, lifelong learning in decision-making (LLDM) also necessitates the transfer of procedural knowledge, such as actions and behaviors. To advance research in LLDM, we introduce LIBERO, a novel benchmark of lifelong learning for robot manipulation. Specifically, LIBERO highlights five key research topics in LLDM: 1) how to efficiently transfer declarative knowledge, procedural knowledge, or the mixture of both; 2) how to design effective policy architectures and 3) effective algorithms for LLDM; 4) the robustness of a lifelong learner with respect to task ordering; and 5) the effect of model pretraining for LLDM. We develop an extendible procedural generation pipeline that can in principle generate infinitely many tasks. For benchmarking purpose, we create four task suites (130 tasks in total) that we use to investigate the above-mentioned research topics. To support sample-efficient learning, we provide high-quality human-teleoperated demonstration data for all tasks. Our extensive experiments present several insightful or even unexpected discoveries: sequential finetuning outperforms existing lifelong learning methods in forward transfer, no single visual encoder architecture excels at all types of knowledge transfer, and naive supervised pretraining can hinder agents' performance in the subsequent LLDM. Check the website at https://libero-project.github.io for the code and the datasets.
Advances and Challenges in Multimodal Remote Sensing Image Registration
Feb 05, 2023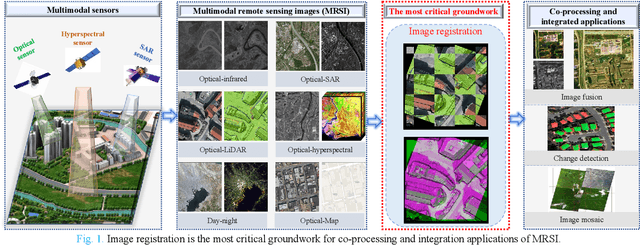
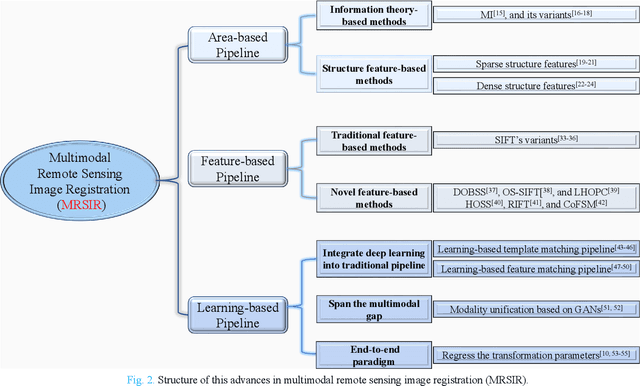
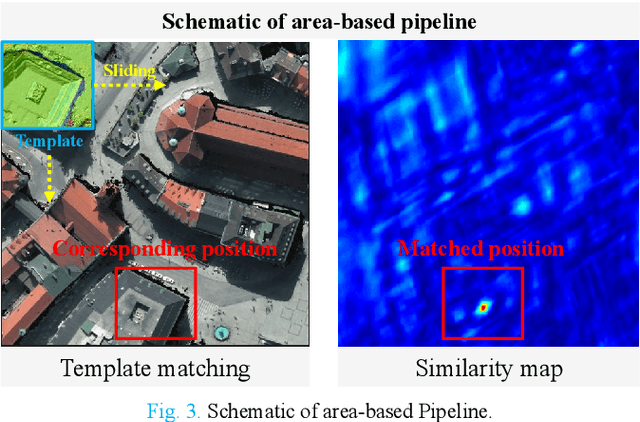

Over the past few decades, with the rapid development of global aerospace and aerial remote sensing technology, the types of sensors have evolved from the traditional monomodal sensors (e.g., optical sensors) to the new generation of multimodal sensors [e.g., multispectral, hyperspectral, light detection and ranging (LiDAR) and synthetic aperture radar (SAR) sensors]. These advanced devices can dynamically provide various and abundant multimodal remote sensing images with different spatial, temporal, and spectral resolutions according to different application requirements. Since then, it is of great scientific significance to carry out the research of multimodal remote sensing image registration, which is a crucial step for integrating the complementary information among multimodal data and making comprehensive observations and analysis of the Earths surface. In this work, we will present our own contributions to the field of multimodal image registration, summarize the advantages and limitations of existing multimodal image registration methods, and then discuss the remaining challenges and make a forward-looking prospect for the future development of the field.
Deep Attention Unet: A Network Model with Global Feature Perception Ability
Apr 21, 2023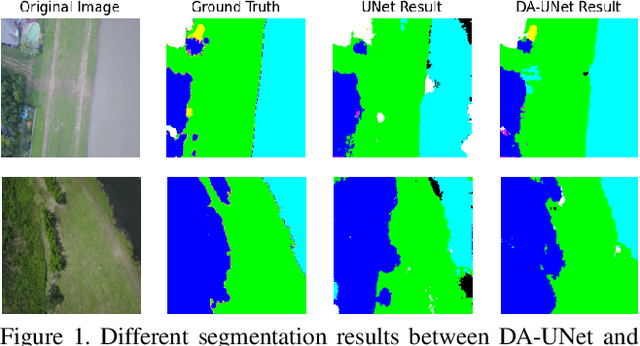
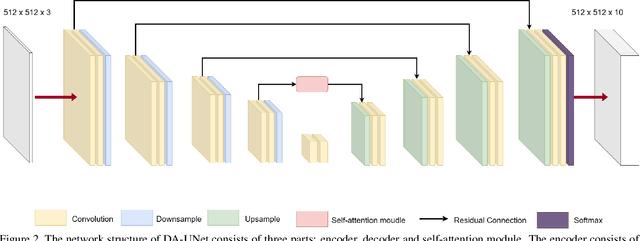
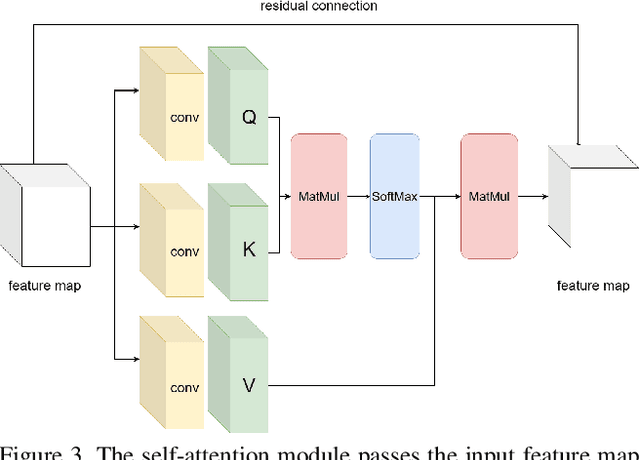
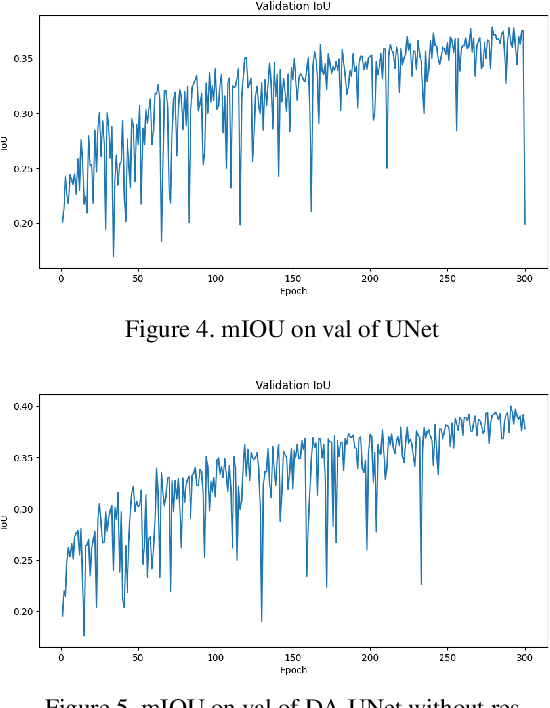
Remote sensing image segmentation is a specific task of remote sensing image interpretation. A good remote sensing image segmentation algorithm can provide guidance for environmental protection, agricultural production, and urban construction. This paper proposes a new type of UNet image segmentation algorithm based on channel self attention mechanism and residual connection called . In my experiment, the new network model improved mIOU by 2.48% compared to traditional UNet on the FoodNet dataset. The image segmentation algorithm proposed in this article enhances the internal connections between different items in the image, thus achieving better segmentation results for remote sensing images with occlusion.
Quantifying the effect of X-ray scattering for data generation in real-time defect detection
May 22, 2023
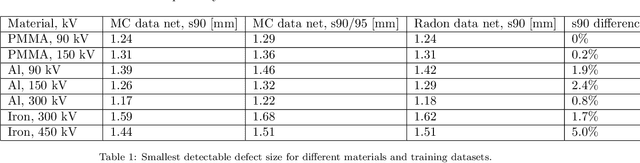
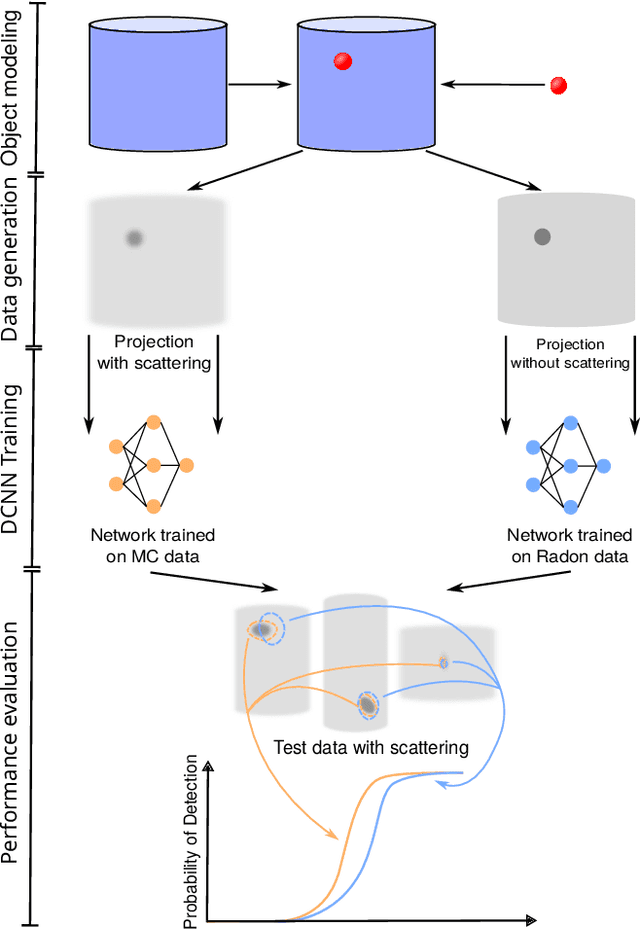
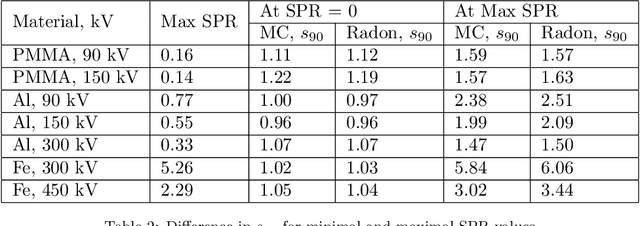
X-ray imaging is widely used for non-destructive detection of defects in industrial products on a conveyor belt. Real-time detection requires highly accurate, robust, and fast algorithms to analyze X-ray images. Deep convolutional neural networks (DCNNs) satisfy these requirements if a large amount of labeled data is available. To overcome the challenge of collecting these data, different methods of X-ray image generation can be considered. Depending on the desired level of similarity to real data, various physical effects either should be simulated or can be ignored. X-ray scattering is known to be computationally expensive to simulate, and this effect can heavily influence the accuracy of a generated X-ray image. We propose a methodology for quantitative evaluation of the effect of scattering on defect detection. This methodology compares the accuracy of DCNNs trained on different versions of the same data that include and exclude the scattering signal. We use the Probability of Detection (POD) curves to find the size of the smallest defect that can be detected with a DCNN and evaluate how this size is affected by the choice of training data. We apply the proposed methodology to a model problem of defect detection in cylinders. Our results show that the exclusion of the scattering signal from the training data has the largest effect on the smallest detectable defects. Furthermore, we demonstrate that accurate inspection is more reliant on high-quality training data for images with a high quantity of scattering. We discuss how the presented methodology can be used for other tasks and objects.
SF-FSDA: Source-Free Few-Shot Domain Adaptive Object Detection with Efficient Labeled Data Factory
Jun 07, 2023
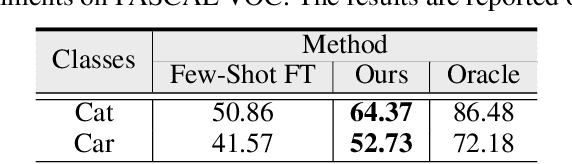
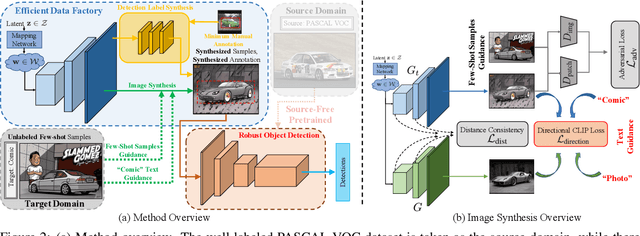
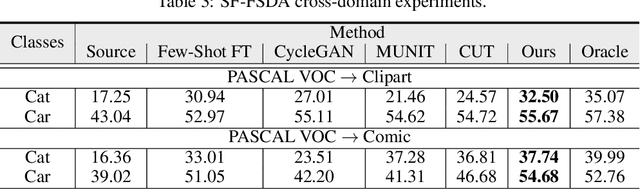
Domain adaptive object detection aims to leverage the knowledge learned from a labeled source domain to improve the performance on an unlabeled target domain. Prior works typically require the access to the source domain data for adaptation, and the availability of sufficient data on the target domain. However, these assumptions may not hold due to data privacy and rare data collection. In this paper, we propose and investigate a more practical and challenging domain adaptive object detection problem under both source-free and few-shot conditions, named as SF-FSDA. To overcome this problem, we develop an efficient labeled data factory based approach. Without accessing the source domain, the data factory renders i) infinite amount of synthesized target-domain like images, under the guidance of the few-shot image samples and text description from the target domain; ii) corresponding bounding box and category annotations, only demanding minimum human effort, i.e., a few manually labeled examples. On the one hand, the synthesized images mitigate the knowledge insufficiency brought by the few-shot condition. On the other hand, compared to the popular pseudo-label technique, the generated annotations from data factory not only get rid of the reliance on the source pretrained object detection model, but also alleviate the unavoidably pseudo-label noise due to domain shift and source-free condition. The generated dataset is further utilized to adapt the source pretrained object detection model, realizing the robust object detection under SF-FSDA. The experiments on different settings showcase that our proposed approach outperforms other state-of-the-art methods on SF-FSDA problem. Our codes and models will be made publicly available.
Fine-Grained Visual Prompting
Jun 07, 2023
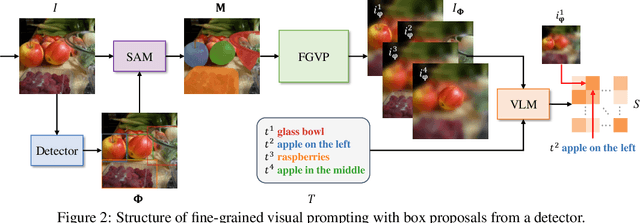
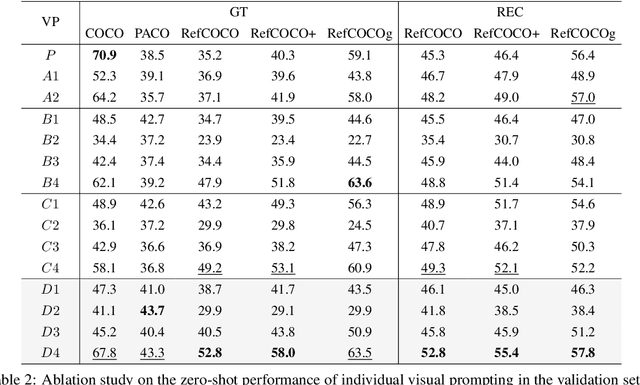
Vision-Language Models (VLMs), such as CLIP, have demonstrated impressive zero-shot transfer capabilities in image-level visual perception. However, these models have shown limited performance in instance-level tasks that demand precise localization and recognition. Previous works have suggested that incorporating visual prompts, such as colorful boxes or circles, can improve the ability of models to recognize objects of interest. Nonetheless, compared to language prompting, visual prompting designs are rarely explored. Existing approaches, which employ coarse visual cues such as colorful boxes or circles, often result in sub-optimal performance due to the inclusion of irrelevant and noisy pixels. In this paper, we carefully study the visual prompting designs by exploring more fine-grained markings, such as segmentation masks and their variations. In addition, we introduce a new zero-shot framework that leverages pixel-level annotations acquired from a generalist segmentation model for fine-grained visual prompting. Consequently, our investigation reveals that a straightforward application of blur outside the target mask, referred to as the Blur Reverse Mask, exhibits exceptional effectiveness. This proposed prompting strategy leverages the precise mask annotations to reduce focus on weakly related regions while retaining spatial coherence between the target and the surrounding background. Our Fine-Grained Visual Prompting (FGVP) demonstrates superior performance in zero-shot comprehension of referring expressions on the RefCOCO, RefCOCO+, and RefCOCOg benchmarks. It outperforms prior methods by an average margin of 3.0% to 4.6%, with a maximum improvement of 12.5% on the RefCOCO+ testA subset. The part detection experiments conducted on the PACO dataset further validate the preponderance of FGVP over existing visual prompting techniques. Code and models will be made available.
Membership inference attack with relative decision boundary distance
Jun 07, 2023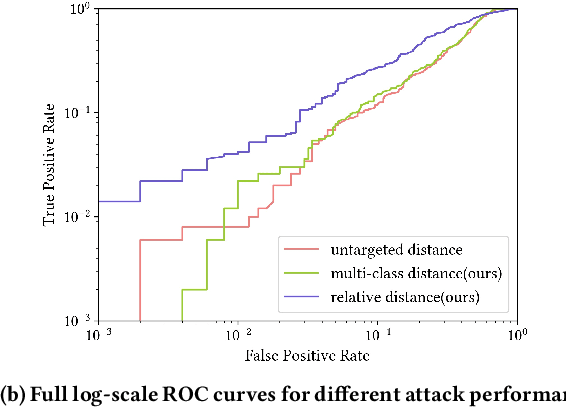
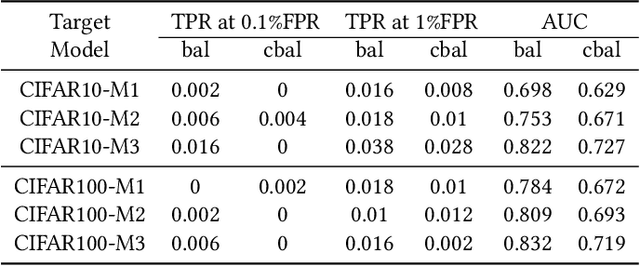
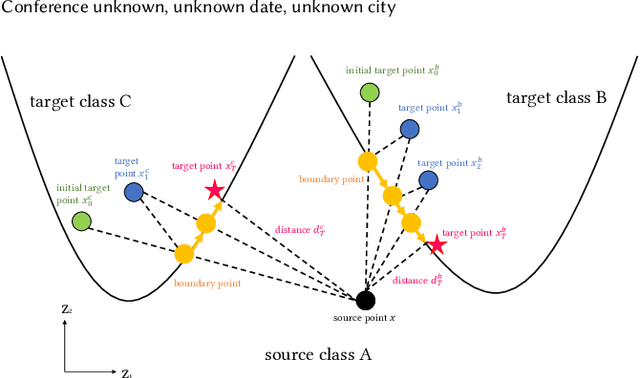
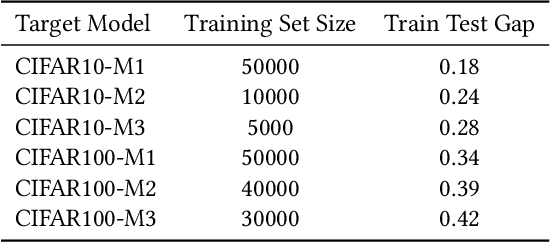
Membership inference attack is one of the most popular privacy attacks in machine learning, which aims to predict whether a given sample was contained in the target model's training set. Label-only membership inference attack is a variant that exploits sample robustness and attracts more attention since it assumes a practical scenario in which the adversary only has access to the predicted labels of the input samples. However, since the decision boundary distance, which measures robustness, is strongly affected by the random initial image, the adversary may get opposite results even for the same input samples. In this paper, we propose a new attack method, called muti-class adaptive membership inference attack in the label-only setting. All decision boundary distances for all target classes have been traversed in the early attack iterations, and the subsequent attack iterations continue with the shortest decision boundary distance to obtain a stable and optimal decision boundary distance. Instead of using a single boundary distance, the relative boundary distance between samples and neighboring points has also been employed as a new membership score to distinguish between member samples inside the training set and nonmember samples outside the training set. Experiments show that previous label-only membership inference attacks using the untargeted HopSkipJump algorithm fail to achieve optimal decision bounds in more than half of the samples, whereas our multi-targeted HopSkipJump algorithm succeeds in almost all samples. In addition, extensive experiments show that our multi-class adaptive MIA outperforms current label-only membership inference attacks in the CIFAR10, and CIFAR100 datasets, especially for the true positive rate at low false positive rates metric.
Fourier Analysis on Robustness of Graph Convolutional Neural Networks for Skeleton-based Action Recognition
May 29, 2023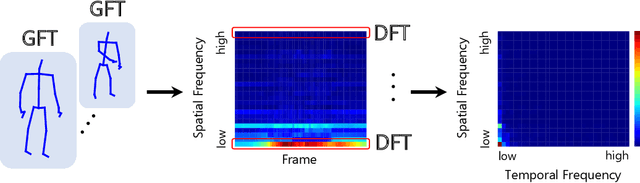
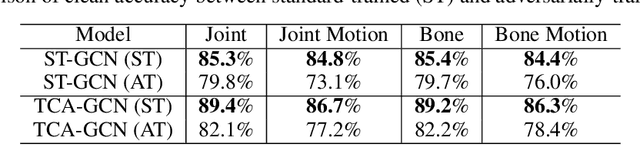
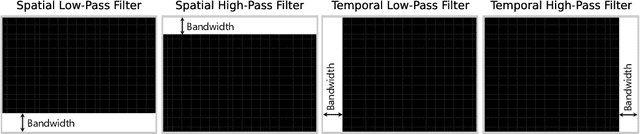
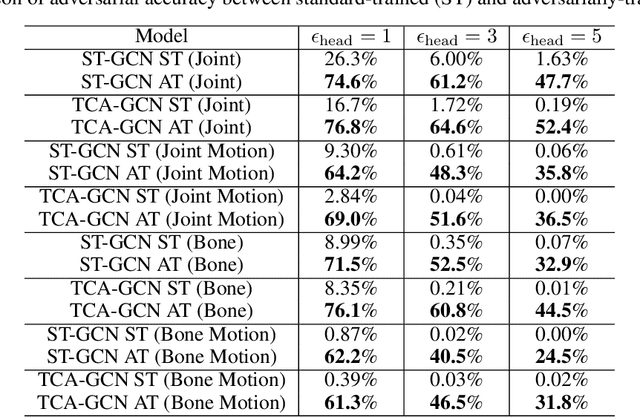
Using Fourier analysis, we explore the robustness and vulnerability of graph convolutional neural networks (GCNs) for skeleton-based action recognition. We adopt a joint Fourier transform (JFT), a combination of the graph Fourier transform (GFT) and the discrete Fourier transform (DFT), to examine the robustness of adversarially-trained GCNs against adversarial attacks and common corruptions. Experimental results with the NTU RGB+D dataset reveal that adversarial training does not introduce a robustness trade-off between adversarial attacks and low-frequency perturbations, which typically occurs during image classification based on convolutional neural networks. This finding indicates that adversarial training is a practical approach to enhancing robustness against adversarial attacks and common corruptions in skeleton-based action recognition. Furthermore, we find that the Fourier approach cannot explain vulnerability against skeletal part occlusion corruption, which highlights its limitations. These findings extend our understanding of the robustness of GCNs, potentially guiding the development of more robust learning methods for skeleton-based action recognition.
Pedestrian detection with high-resolution event camera
May 29, 2023
Despite the dynamic development of computer vision algorithms, the implementation of perception and control systems for autonomous vehicles such as drones and self-driving cars still poses many challenges. A video stream captured by traditional cameras is often prone to problems such as motion blur or degraded image quality due to challenging lighting conditions. In addition, the frame rate - typically 30 or 60 frames per second - can be a limiting factor in certain scenarios. Event cameras (DVS -- Dynamic Vision Sensor) are a potentially interesting technology to address the above mentioned problems. In this paper, we compare two methods of processing event data by means of deep learning for the task of pedestrian detection. We used a representation in the form of video frames, convolutional neural networks and asynchronous sparse convolutional neural networks. The results obtained illustrate the potential of event cameras and allow the evaluation of the accuracy and efficiency of the methods used for high-resolution (1280 x 720 pixels) footage.