 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
SigVIC: Spatial Importance Guided Variable-Rate Image Compression
Mar 16, 2023
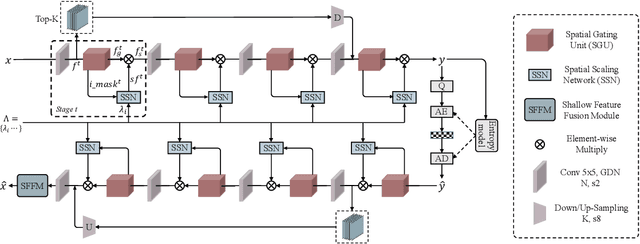
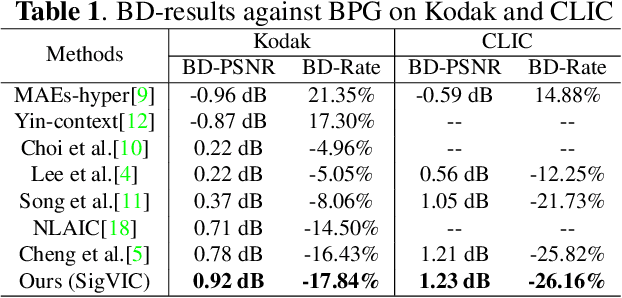
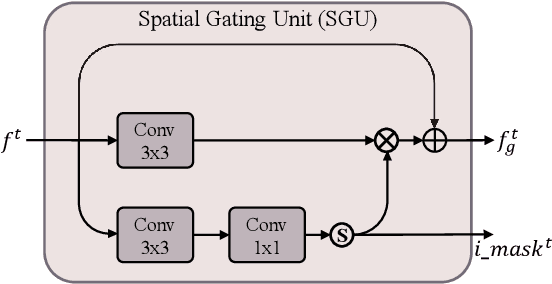

Variable-rate mechanism has improved the flexibility and efficiency of learning-based image compression that trains multiple models for different rate-distortion tradeoffs. One of the most common approaches for variable-rate is to channel-wisely or spatial-uniformly scale the internal features. However, the diversity of spatial importance is instructive for bit allocation of image compression. In this paper, we introduce a Spatial Importance Guided Variable-rate Image Compression (SigVIC), in which a spatial gating unit (SGU) is designed for adaptively learning a spatial importance mask. Then, a spatial scaling network (SSN) takes the spatial importance mask to guide the feature scaling and bit allocation for variable-rate. Moreover, to improve the quality of decoded image, Top-K shallow features are selected to refine the decoded features through a shallow feature fusion module (SFFM). Experiments show that our method outperforms other learning-based methods (whether variable-rate or not) and traditional codecs, with storage saving and high flexibility.
Omni Aggregation Networks for Lightweight Image Super-Resolution
Apr 20, 2023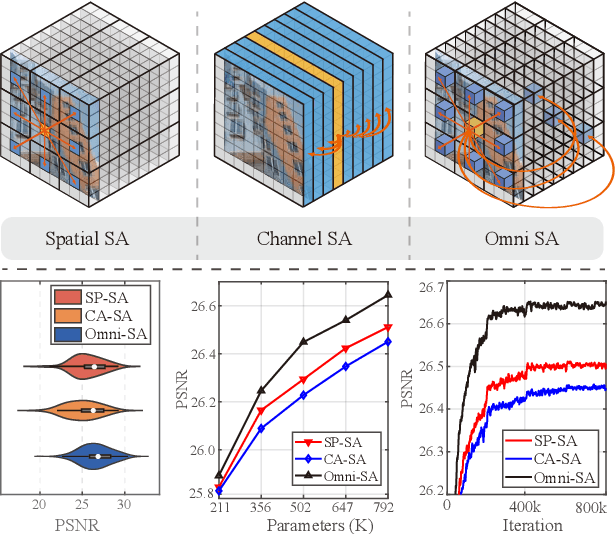
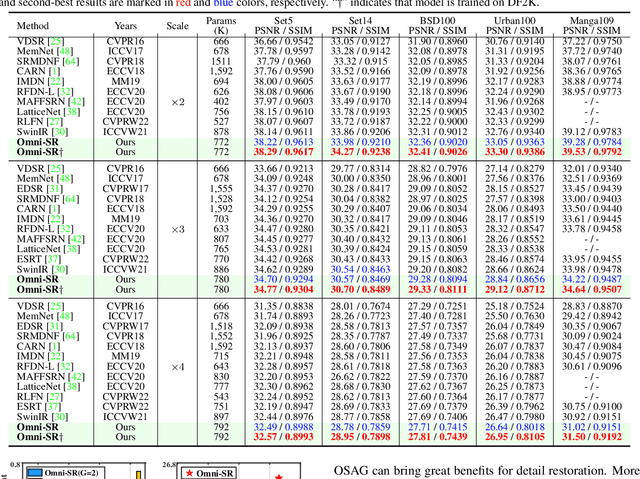
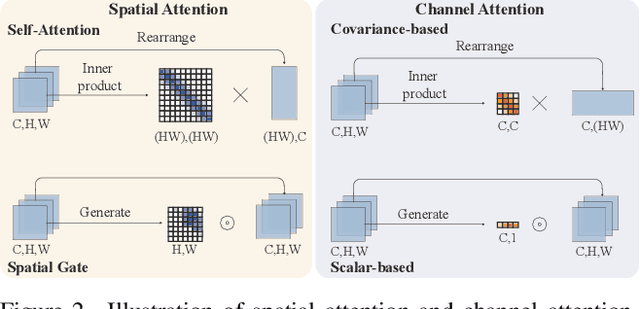

While lightweight ViT framework has made tremendous progress in image super-resolution, its uni-dimensional self-attention modeling, as well as homogeneous aggregation scheme, limit its effective receptive field (ERF) to include more comprehensive interactions from both spatial and channel dimensions. To tackle these drawbacks, this work proposes two enhanced components under a new Omni-SR architecture. First, an Omni Self-Attention (OSA) block is proposed based on dense interaction principle, which can simultaneously model pixel-interaction from both spatial and channel dimensions, mining the potential correlations across omni-axis (i.e., spatial and channel). Coupling with mainstream window partitioning strategies, OSA can achieve superior performance with compelling computational budgets. Second, a multi-scale interaction scheme is proposed to mitigate sub-optimal ERF (i.e., premature saturation) in shallow models, which facilitates local propagation and meso-/global-scale interactions, rendering an omni-scale aggregation building block. Extensive experiments demonstrate that Omni-SR achieves record-high performance on lightweight super-resolution benchmarks (e.g., 26.95 dB@Urban100 $\times 4$ with only 792K parameters). Our code is available at \url{https://github.com/Francis0625/Omni-SR}.
Towards Language Models That Can See: Computer Vision Through the LENS of Natural Language
Jun 28, 2023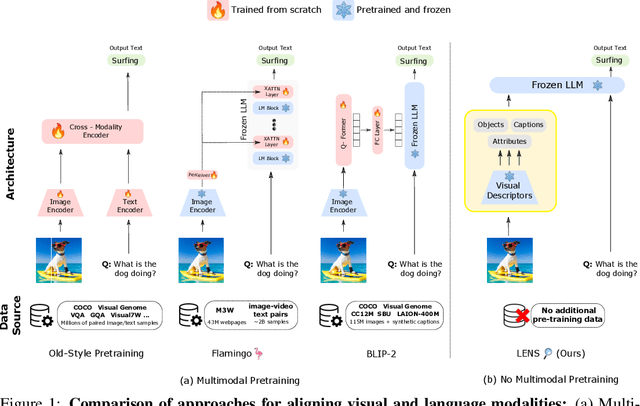
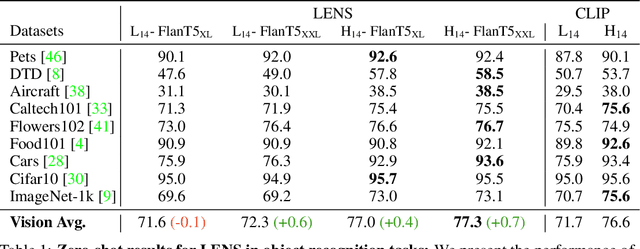
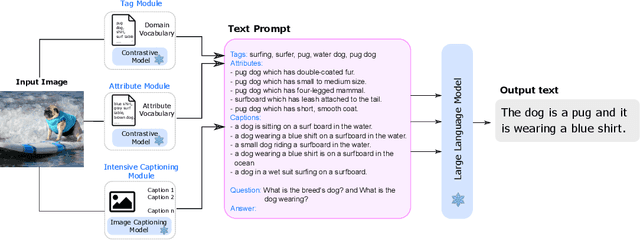
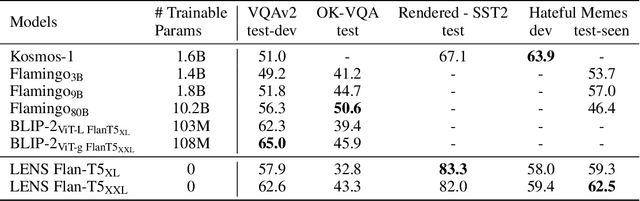
We propose LENS, a modular approach for tackling computer vision problems by leveraging the power of large language models (LLMs). Our system uses a language model to reason over outputs from a set of independent and highly descriptive vision modules that provide exhaustive information about an image. We evaluate the approach on pure computer vision settings such as zero- and few-shot object recognition, as well as on vision and language problems. LENS can be applied to any off-the-shelf LLM and we find that the LLMs with LENS perform highly competitively with much bigger and much more sophisticated systems, without any multimodal training whatsoever. We open-source our code at https://github.com/ContextualAI/lens and provide an interactive demo.
Conditional Image-to-Video Generation with Latent Flow Diffusion Models
Mar 24, 2023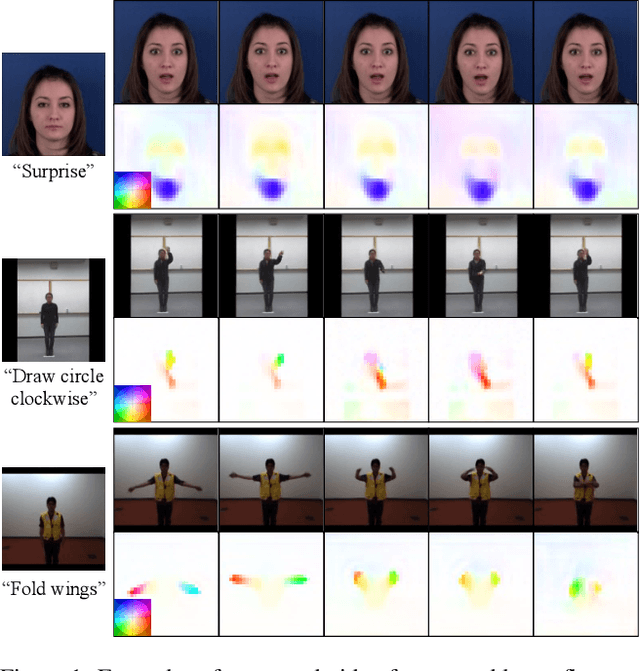

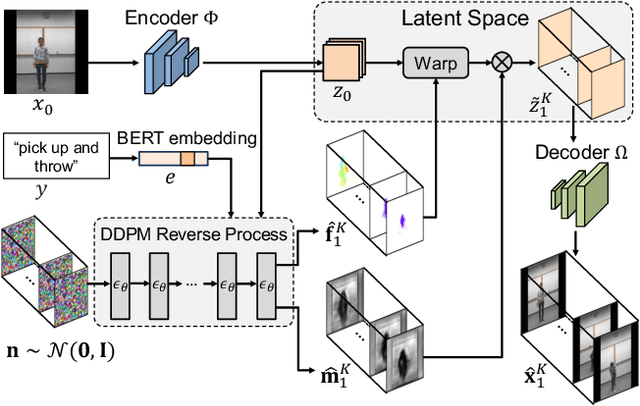
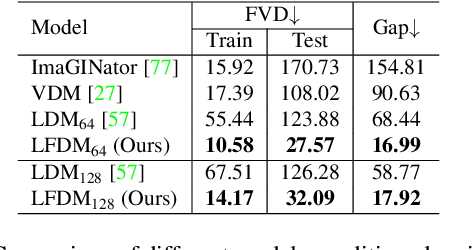
Conditional image-to-video (cI2V) generation aims to synthesize a new plausible video starting from an image (e.g., a person's face) and a condition (e.g., an action class label like smile). The key challenge of the cI2V task lies in the simultaneous generation of realistic spatial appearance and temporal dynamics corresponding to the given image and condition. In this paper, we propose an approach for cI2V using novel latent flow diffusion models (LFDM) that synthesize an optical flow sequence in the latent space based on the given condition to warp the given image. Compared to previous direct-synthesis-based works, our proposed LFDM can better synthesize spatial details and temporal motion by fully utilizing the spatial content of the given image and warping it in the latent space according to the generated temporally-coherent flow. The training of LFDM consists of two separate stages: (1) an unsupervised learning stage to train a latent flow auto-encoder for spatial content generation, including a flow predictor to estimate latent flow between pairs of video frames, and (2) a conditional learning stage to train a 3D-UNet-based diffusion model (DM) for temporal latent flow generation. Unlike previous DMs operating in pixel space or latent feature space that couples spatial and temporal information, the DM in our LFDM only needs to learn a low-dimensional latent flow space for motion generation, thus being more computationally efficient. We conduct comprehensive experiments on multiple datasets, where LFDM consistently outperforms prior arts. Furthermore, we show that LFDM can be easily adapted to new domains by simply finetuning the image decoder. Our code is available at https://github.com/nihaomiao/CVPR23_LFDM.
Fill-Up: Balancing Long-Tailed Data with Generative Models
Jun 12, 2023

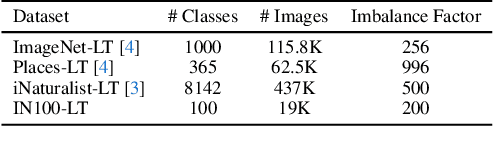
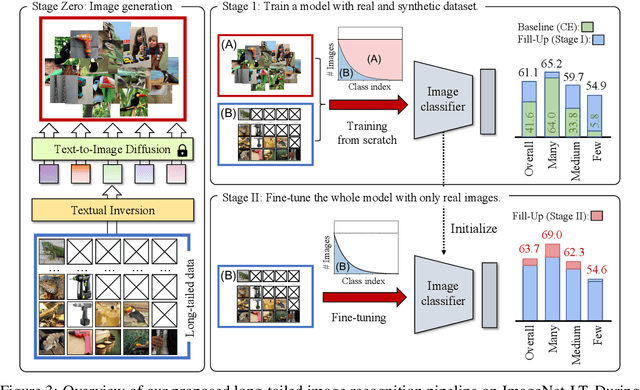
Modern text-to-image synthesis models have achieved an exceptional level of photorealism, generating high-quality images from arbitrary text descriptions. In light of the impressive synthesis ability, several studies have exhibited promising results in exploiting generated data for image recognition. However, directly supplementing data-hungry situations in the real-world (e.g. few-shot or long-tailed scenarios) with existing approaches result in marginal performance gains, as they suffer to thoroughly reflect the distribution of the real data. Through extensive experiments, this paper proposes a new image synthesis pipeline for long-tailed situations using Textual Inversion. The study demonstrates that generated images from textual-inverted text tokens effectively aligns with the real domain, significantly enhancing the recognition ability of a standard ResNet50 backbone. We also show that real-world data imbalance scenarios can be successfully mitigated by filling up the imbalanced data with synthetic images. In conjunction with techniques in the area of long-tailed recognition, our method achieves state-of-the-art results on standard long-tailed benchmarks when trained from scratch.
A Novel Dual-pooling Attention Module for UAV Vehicle Re-identification
Jun 25, 2023
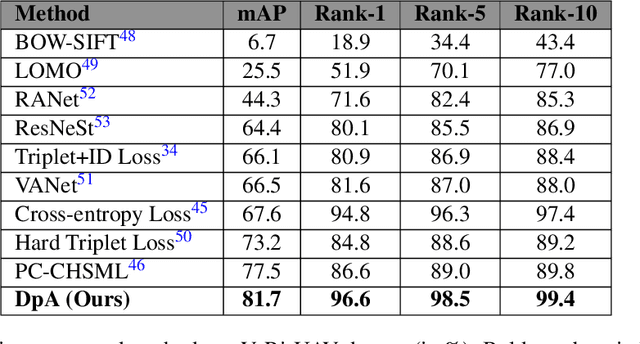
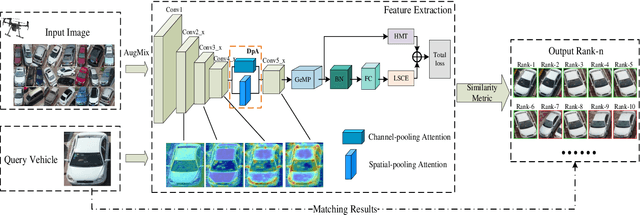
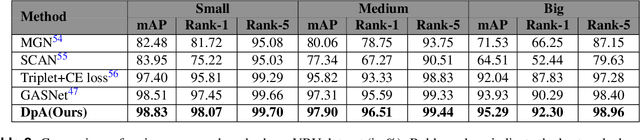
Vehicle re-identification (Re-ID) involves identifying the same vehicle captured by other cameras, given a vehicle image. It plays a crucial role in the development of safe cities and smart cities. With the rapid growth and implementation of unmanned aerial vehicles (UAVs) technology, vehicle Re-ID in UAV aerial photography scenes has garnered significant attention from researchers. However, due to the high altitude of UAVs, the shooting angle of vehicle images sometimes approximates vertical, resulting in fewer local features for Re-ID. Therefore, this paper proposes a novel dual-pooling attention (DpA) module, which achieves the extraction and enhancement of locally important information about vehicles from both channel and spatial dimensions by constructing two branches of channel-pooling attention (CpA) and spatial-pooling attention (SpA), and employing multiple pooling operations to enhance the attention to fine-grained information of vehicles. Specifically, the CpA module operates between the channels of the feature map and splices features by combining four pooling operations so that vehicle regions containing discriminative information are given greater attention. The SpA module uses the same pooling operations strategy to identify discriminative representations and merge vehicle features in image regions in a weighted manner. The feature information of both dimensions is finally fused and trained jointly using label smoothing cross-entropy loss and hard mining triplet loss, thus solving the problem of missing detail information due to the high height of UAV shots. The proposed method's effectiveness is demonstrated through extensive experiments on the UAV-based vehicle datasets VeRi-UAV and VRU.
Facing off World Model Backbones: RNNs, Transformers, and S4
Jul 05, 2023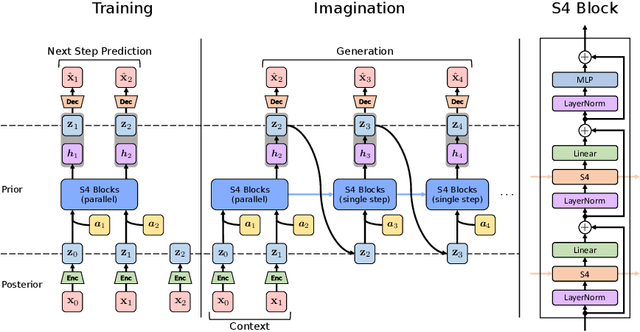

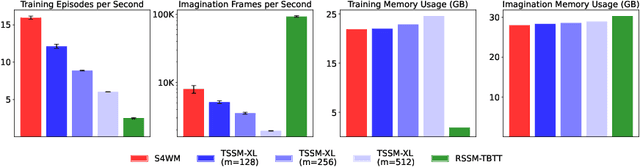
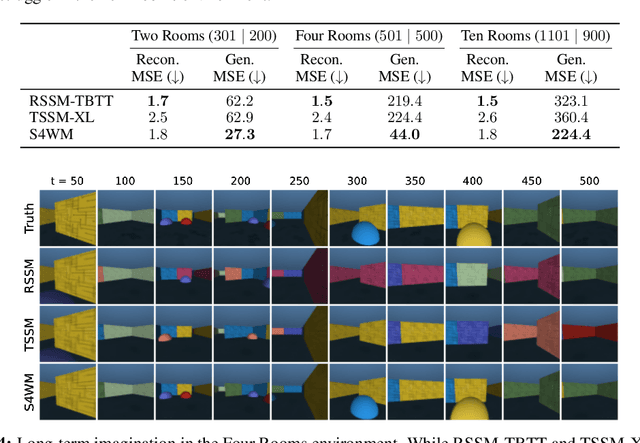
World models are a fundamental component in model-based reinforcement learning (MBRL) agents. To perform temporally extended and consistent simulations of the future in partially observable environments, world models need to possess long-term memory. However, state-of-the-art MBRL agents, such as Dreamer, predominantly employ recurrent neural networks (RNNs) as their world model backbone, which have limited memory capacity. In this paper, we seek to explore alternative world model backbones for improving long-term memory. In particular, we investigate the effectiveness of Transformers and Structured State Space Sequence (S4) models, motivated by their remarkable ability to capture long-range dependencies in low-dimensional sequences and their complementary strengths. We propose S4WM, the first S4-based world model that can generate high-dimensional image sequences through latent imagination. Furthermore, we extensively compare RNN-, Transformer-, and S4-based world models across four sets of environments, which we have specifically tailored to assess crucial memory capabilities of world models, including long-term imagination, context-dependent recall, reward prediction, and memory-based reasoning. Our findings demonstrate that S4WM outperforms Transformer-based world models in terms of long-term memory, while exhibiting greater efficiency during training and imagination. These results pave the way for the development of stronger MBRL agents.
The KiTS21 Challenge: Automatic segmentation of kidneys, renal tumors, and renal cysts in corticomedullary-phase CT
Jul 05, 2023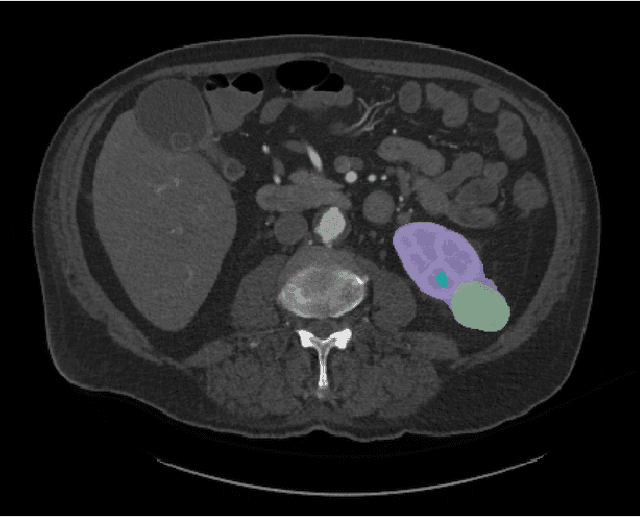
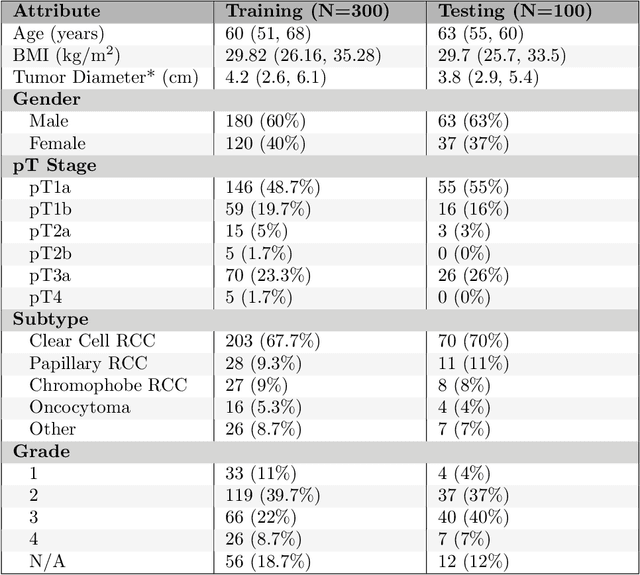
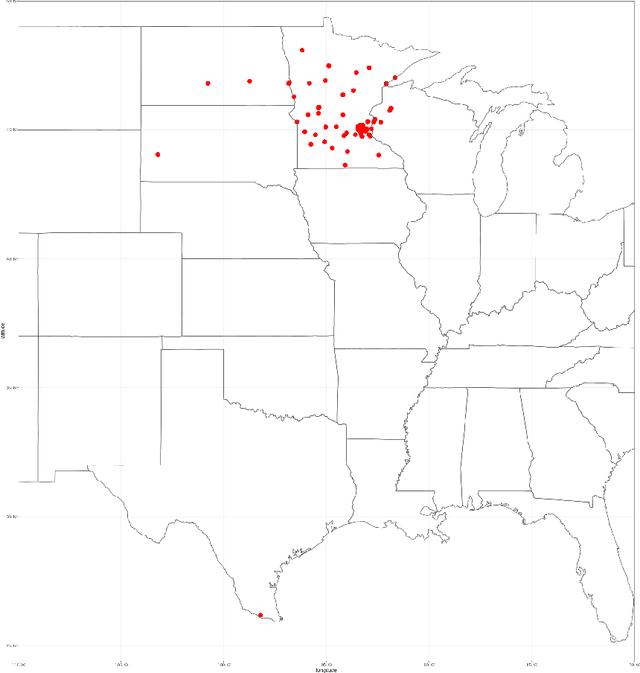
This paper presents the challenge report for the 2021 Kidney and Kidney Tumor Segmentation Challenge (KiTS21) held in conjunction with the 2021 international conference on Medical Image Computing and Computer Assisted Interventions (MICCAI). KiTS21 is a sequel to its first edition in 2019, and it features a variety of innovations in how the challenge was designed, in addition to a larger dataset. A novel annotation method was used to collect three separate annotations for each region of interest, and these annotations were performed in a fully transparent setting using a web-based annotation tool. Further, the KiTS21 test set was collected from an outside institution, challenging participants to develop methods that generalize well to new populations. Nonetheless, the top-performing teams achieved a significant improvement over the state of the art set in 2019, and this performance is shown to inch ever closer to human-level performance. An in-depth meta-analysis is presented describing which methods were used and how they faired on the leaderboard, as well as the characteristics of which cases generally saw good performance, and which did not. Overall KiTS21 facilitated a significant advancement in the state of the art in kidney tumor segmentation, and provides useful insights that are applicable to the field of semantic segmentation as a whole.
StyleGAN knows Normal, Depth, Albedo, and More
Jun 01, 2023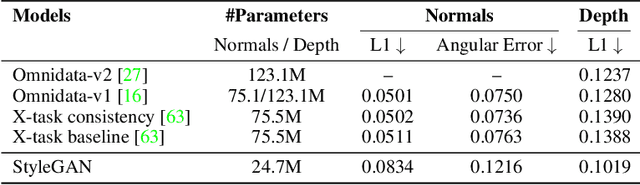
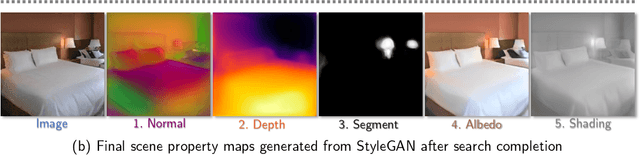
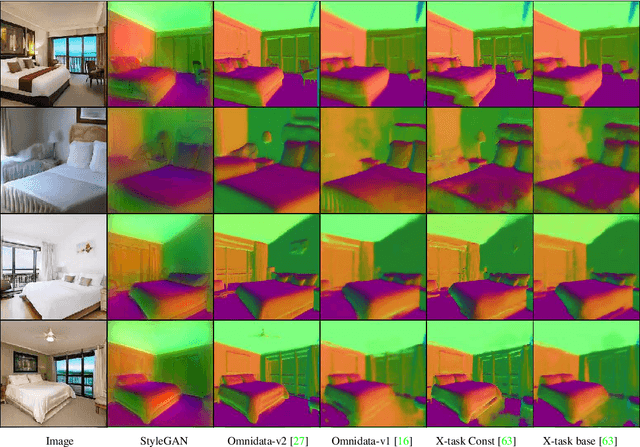
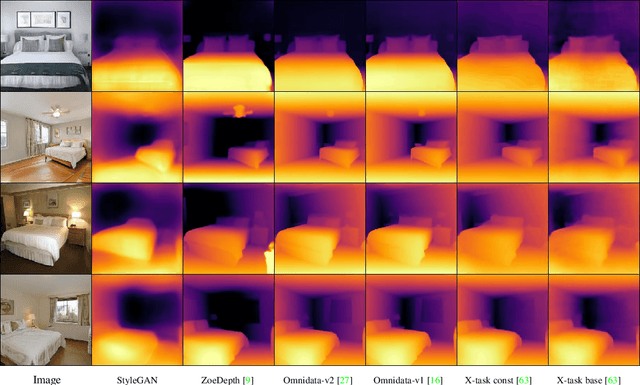
Intrinsic images, in the original sense, are image-like maps of scene properties like depth, normal, albedo or shading. This paper demonstrates that StyleGAN can easily be induced to produce intrinsic images. The procedure is straightforward. We show that, if StyleGAN produces $G({w})$ from latents ${w}$, then for each type of intrinsic image, there is a fixed offset ${d}_c$ so that $G({w}+{d}_c)$ is that type of intrinsic image for $G({w})$. Here ${d}_c$ is {\em independent of ${w}$}. The StyleGAN we used was pretrained by others, so this property is not some accident of our training regime. We show that there are image transformations StyleGAN will {\em not} produce in this fashion, so StyleGAN is not a generic image regression engine. It is conceptually exciting that an image generator should ``know'' and represent intrinsic images. There may also be practical advantages to using a generative model to produce intrinsic images. The intrinsic images obtained from StyleGAN compare well both qualitatively and quantitatively with those obtained by using SOTA image regression techniques; but StyleGAN's intrinsic images are robust to relighting effects, unlike SOTA methods.
MMNet: Multi-Collaboration and Multi-Supervision Network for Sequential Deepfake Detection
Jul 06, 2023Advanced manipulation techniques have provided criminals with opportunities to make social panic or gain illicit profits through the generation of deceptive media, such as forged face images. In response, various deepfake detection methods have been proposed to assess image authenticity. Sequential deepfake detection, which is an extension of deepfake detection, aims to identify forged facial regions with the correct sequence for recovery. Nonetheless, due to the different combinations of spatial and sequential manipulations, forged face images exhibit substantial discrepancies that severely impact detection performance. Additionally, the recovery of forged images requires knowledge of the manipulation model to implement inverse transformations, which is difficult to ascertain as relevant techniques are often concealed by attackers. To address these issues, we propose Multi-Collaboration and Multi-Supervision Network (MMNet) that handles various spatial scales and sequential permutations in forged face images and achieve recovery without requiring knowledge of the corresponding manipulation method. Furthermore, existing evaluation metrics only consider detection accuracy at a single inferring step, without accounting for the matching degree with ground-truth under continuous multiple steps. To overcome this limitation, we propose a novel evaluation metric called Complete Sequence Matching (CSM), which considers the detection accuracy at multiple inferring steps, reflecting the ability to detect integrally forged sequences. Extensive experiments on several typical datasets demonstrate that MMNet achieves state-of-the-art detection performance and independent recovery performance.