 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Human Hands to Robotic Limbs: A Study in Motor Skill Embodiment for Telemanipulation
Feb 04, 2025This paper presents a teleoperation system for controlling a redundant degree of freedom robot manipulator using human arm gestures. We propose a GRU-based Variational Autoencoder to learn a latent representation of the manipulator's configuration space, capturing its complex joint kinematics. A fully connected neural network maps human arm configurations into this latent space, allowing the system to mimic and generate corresponding manipulator trajectories in real time through the VAE decoder. The proposed method shows promising results in teleoperating the manipulator, enabling the generation of novel manipulator configurations from human features that were not present during training.
Efficient MedSAMs: Segment Anything in Medical Images on Laptop
Dec 20, 2024


Promptable segmentation foundation models have emerged as a transformative approach to addressing the diverse needs in medical images, but most existing models require expensive computing, posing a big barrier to their adoption in clinical practice. In this work, we organized the first international competition dedicated to promptable medical image segmentation, featuring a large-scale dataset spanning nine common imaging modalities from over 20 different institutions. The top teams developed lightweight segmentation foundation models and implemented an efficient inference pipeline that substantially reduced computational requirements while maintaining state-of-the-art segmentation accuracy. Moreover, the post-challenge phase advanced the algorithms through the design of performance booster and reproducibility tasks, resulting in improved algorithms and validated reproducibility of the winning solution. Furthermore, the best-performing algorithms have been incorporated into the open-source software with a user-friendly interface to facilitate clinical adoption. The data and code are publicly available to foster the further development of medical image segmentation foundation models and pave the way for impactful real-world applications.
AI Age Discrepancy: A Novel Parameter for Frailty Assessment in Kidney Tumor Patients
Jul 02, 2024Kidney cancer is a global health concern, and accurate assessment of patient frailty is crucial for optimizing surgical outcomes. This paper introduces AI Age Discrepancy, a novel metric derived from machine learning analysis of preoperative abdominal CT scans, as a potential indicator of frailty and postoperative risk in kidney cancer patients. This retrospective study of 599 patients from the 2023 Kidney Tumor Segmentation (KiTS) challenge dataset found that a higher AI Age Discrepancy is significantly associated with longer hospital stays and lower overall survival rates, independent of established factors. This suggests that AI Age Discrepancy may provide valuable insights into patient frailty and could thus inform clinical decision-making in kidney cancer treatment.
3D Reconstruction in Noisy Agricultural Environments: A Bayesian Optimization Perspective for View Planning
Sep 29, 20233D reconstruction is a fundamental task in robotics that gained attention due to its major impact in a wide variety of practical settings, including agriculture, underwater, and urban environments. An important approach for this task, known as view planning, is to judiciously place a number of cameras in positions that maximize the visual information improving the resulting 3D reconstruction. Circumventing the need for a large number of arbitrary images, geometric criteria can be applied to select fewer yet more informative images to markedly improve the 3D reconstruction performance. Nonetheless, incorporating the noise of the environment that exists in various real-world scenarios into these criteria may be challenging, particularly when prior information about the noise is not provided. To that end, this work advocates a novel geometric function that accounts for the existing noise, relying solely on a relatively small number of noise realizations without requiring its closed-form expression. With no analytic expression of the geometric function, this work puts forth a Bayesian optimization algorithm for accurate 3D reconstruction in the presence of noise. Numerical tests on noisy agricultural environments showcase the impressive merits of the proposed approach for 3D reconstruction with even a small number of available cameras.
The KiTS21 Challenge: Automatic segmentation of kidneys, renal tumors, and renal cysts in corticomedullary-phase CT
Jul 05, 2023



This paper presents the challenge report for the 2021 Kidney and Kidney Tumor Segmentation Challenge (KiTS21) held in conjunction with the 2021 international conference on Medical Image Computing and Computer Assisted Interventions (MICCAI). KiTS21 is a sequel to its first edition in 2019, and it features a variety of innovations in how the challenge was designed, in addition to a larger dataset. A novel annotation method was used to collect three separate annotations for each region of interest, and these annotations were performed in a fully transparent setting using a web-based annotation tool. Further, the KiTS21 test set was collected from an outside institution, challenging participants to develop methods that generalize well to new populations. Nonetheless, the top-performing teams achieved a significant improvement over the state of the art set in 2019, and this performance is shown to inch ever closer to human-level performance. An in-depth meta-analysis is presented describing which methods were used and how they faired on the leaderboard, as well as the characteristics of which cases generally saw good performance, and which did not. Overall KiTS21 facilitated a significant advancement in the state of the art in kidney tumor segmentation, and provides useful insights that are applicable to the field of semantic segmentation as a whole.
Pre-Clustering Point Clouds of Crop Fields Using Scalable Methods
Jul 22, 2021
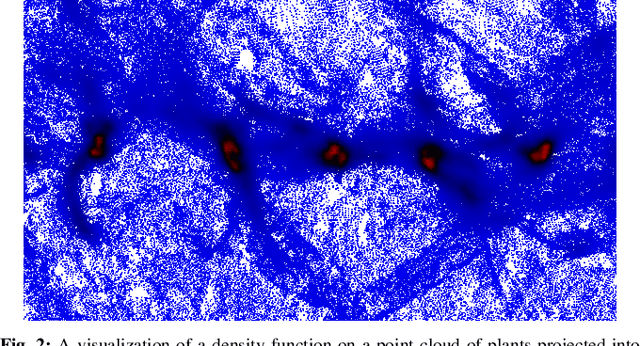


In order to apply the recent successes of automated plant phenotyping and machine learning on a large scale, efficient and general algorithms must be designed to intelligently split crop fields into small, yet actionable, portions that can then be processed by more complex algorithms. In this paper we notice a similarity between the current state-of-the-art for this problem and a commonly used density-based clustering algorithm, Quickshift. Exploiting this similarity we propose a number of novel, application specific algorithms with the goal of producing a general and scalable plant segmentation algorithm. The novel algorithms proposed in this work are shown to produce quantitatively better results than the current state-of-the-art while being less sensitive to input parameters and maintaining the same algorithmic time complexity. When incorporated into field-scale phenotyping systems, the proposed algorithms should work as a drop in replacement that can greatly improve the accuracy of results while ensuring that performance and scalability remain undiminished.
Learning Log-Determinant Divergences for Positive Definite Matrices
Apr 13, 2021
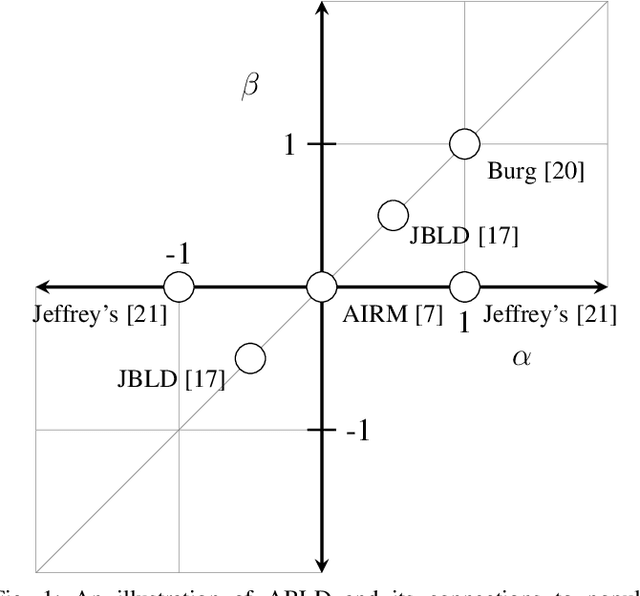

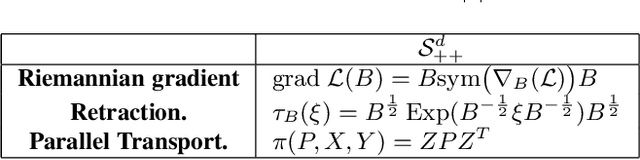
Representations in the form of Symmetric Positive Definite (SPD) matrices have been popularized in a variety of visual learning applications due to their demonstrated ability to capture rich second-order statistics of visual data. There exist several similarity measures for comparing SPD matrices with documented benefits. However, selecting an appropriate measure for a given problem remains a challenge and in most cases, is the result of a trial-and-error process. In this paper, we propose to learn similarity measures in a data-driven manner. To this end, we capitalize on the \alpha\beta-log-det divergence, which is a meta-divergence parametrized by scalars \alpha and \beta, subsuming a wide family of popular information divergences on SPD matrices for distinct and discrete values of these parameters. Our key idea is to cast these parameters in a continuum and learn them from data. We systematically extend this idea to learn vector-valued parameters, thereby increasing the expressiveness of the underlying non-linear measure. We conjoin the divergence learning problem with several standard tasks in machine learning, including supervised discriminative dictionary learning and unsupervised SPD matrix clustering. We present Riemannian gradient descent schemes for optimizing our formulations efficiently, and show the usefulness of our method on eight standard computer vision tasks.
The state of the art in kidney and kidney tumor segmentation in contrast-enhanced CT imaging: Results of the KiTS19 Challenge
Dec 02, 2019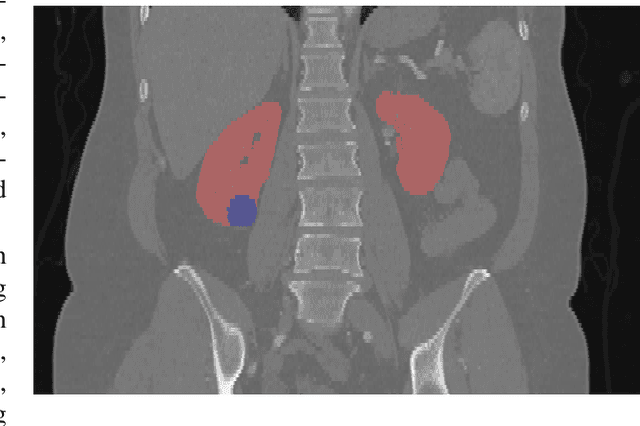
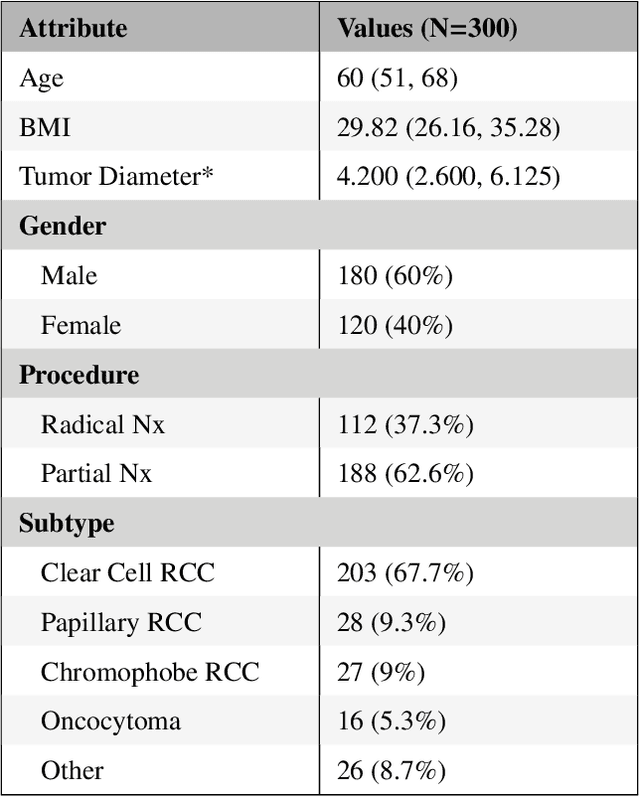
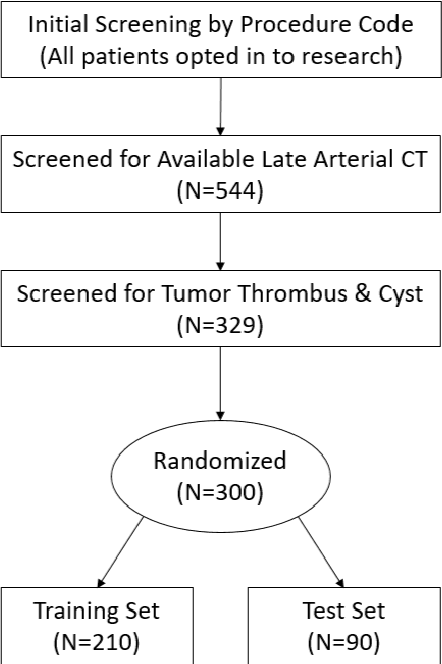
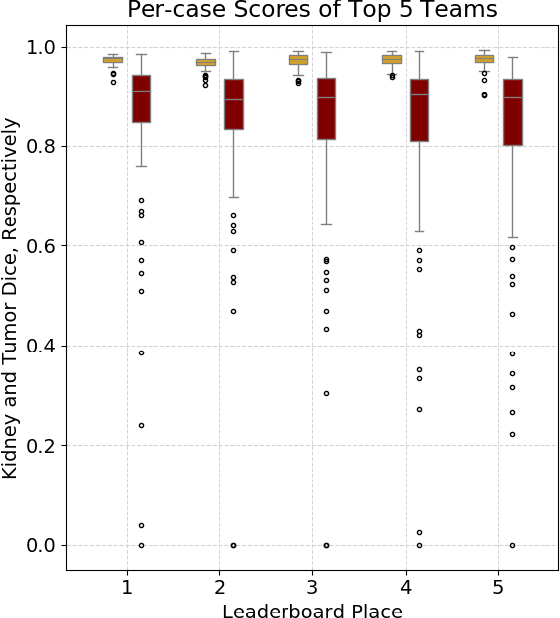
There is a large body of literature linking anatomic and geometric characteristics of kidney tumors to perioperative and oncologic outcomes. Semantic segmentation of these tumors and their host kidneys is a promising tool for quantitatively characterizing these lesions, but its adoption is limited due to the manual effort required to produce high-quality 3D segmentations of these structures. Recently, methods based on deep learning have shown excellent results in automatic 3D segmentation, but they require large datasets for training, and there remains little consensus on which methods perform best. The 2019 Kidney and Kidney Tumor Segmentation challenge (KiTS19) was a competition held in conjunction with the 2019 International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI) which sought to address these issues and stimulate progress on this automatic segmentation problem. A training set of 210 cross sectional CT images with kidney tumors was publicly released with corresponding semantic segmentation masks. 106 teams from five continents used this data to develop automated systems to predict the true segmentation masks on a test set of 90 CT images for which the corresponding ground truth segmentations were kept private. These predictions were scored and ranked according to their average So rensen-Dice coefficient between the kidney and tumor across all 90 cases. The winning team achieved a Dice of 0.974 for kidney and 0.851 for tumor, approaching the inter-annotator performance on kidney (0.983) but falling short on tumor (0.923). This challenge has now entered an "open leaderboard" phase where it serves as a challenging benchmark in 3D semantic segmentation.
Design and Experiments with a Robot-Driven Underwater Holographic Microscope for Low-Cost In Situ Particle Measurements
Nov 22, 2019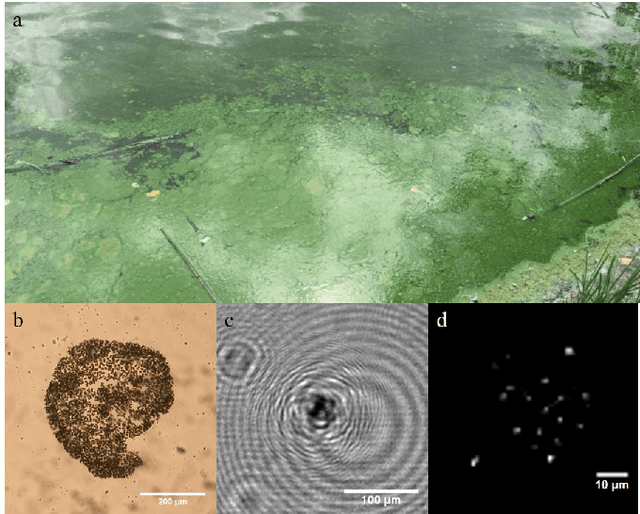



Microscopic analysis of micro particles in situ in diverse water environments is necessary for monitoring water quality and localizing contamination sources. Conventional sensors such as optical microscopes and fluorometers often require complex sample preparation, are restricted to small sample volumes, and are unable to simultaneously capture all pertinent details of a sample such as particle size, shape, concentration, and three dimensional motion. In this article we propose a novel and cost-effective robotic system for mobile microscopic analysis of particles in situ at various depths which are fully controlled by the robot system itself. A miniature underwater digital in-line holographic microscope (DIHM) performs high resolution imaging of microparticles (e.g., algae cells, plastic debris, sediments) while movement allows measurement of particle distributions covering a large area of water. The main contribution of this work is the creation of a low-cost, comprehensive, and small underwater robotic holographic microscope that can assist in a variety of tasks in environmental monitoring and overall assessment of water quality such as contaminant detection and localization. The resulting system provides some unique capabilities such as expanded and systematic coverage of large bodies of water at a low cost. Several challenges such as the trade-off between image quality and cost are addressed to satisfy the aforementioned goals.
The Role of Publicly Available Data in MICCAI Papers from 2014 to 2018
Aug 12, 2019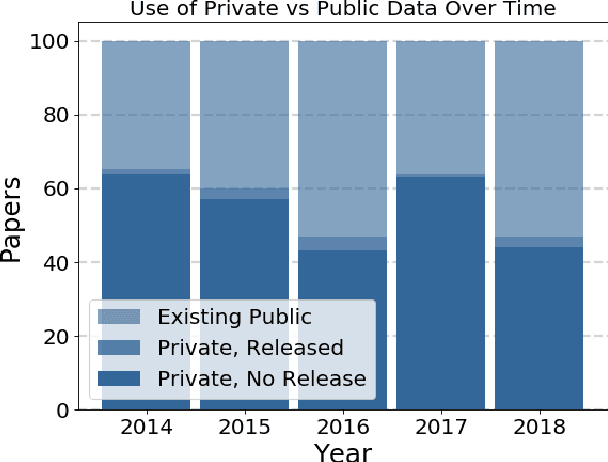
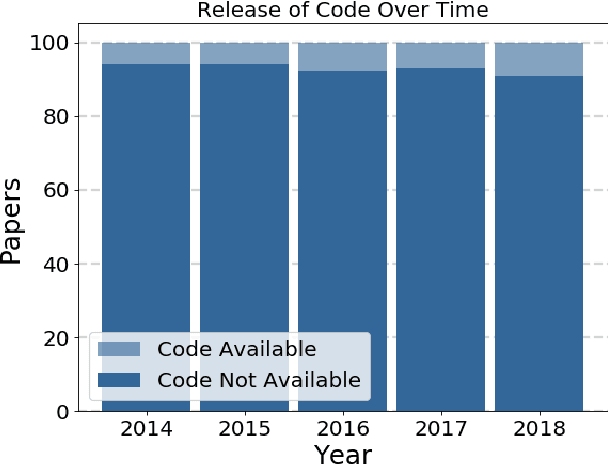
Widely-used public benchmarks are of huge importance to computer vision and machine learning research, especially with the computational resources required to reproduce state of the art results quickly becoming untenable. In medical image computing, the wide variety of image modalities and problem formulations yields a huge task-space for benchmarks to cover, and thus the widespread adoption of standard benchmarks has been slow, and barriers to releasing medical data exacerbate this issue. In this paper, we examine the role that publicly available data has played in MICCAI papers from the past five years. We find that more than half of these papers are based on private data alone, although this proportion seems to be decreasing over time. Additionally, we observed that after controlling for open access publication and the release of code, papers based on public data were cited over 60% more per year than their private-data counterparts. Further, we found that more than 20% of papers using public data did not provide a citation to the dataset or associated manuscript, highlighting the "second-rate" status that data contributions often take compared to theoretical ones. We conclude by making recommendations for MICCAI policies which could help to better incentivise data sharing and move the field toward more efficient and reproducible science.