 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Structure Preserving Cycle-GAN for Unsupervised Medical Image Domain Adaptation
Apr 18, 2023
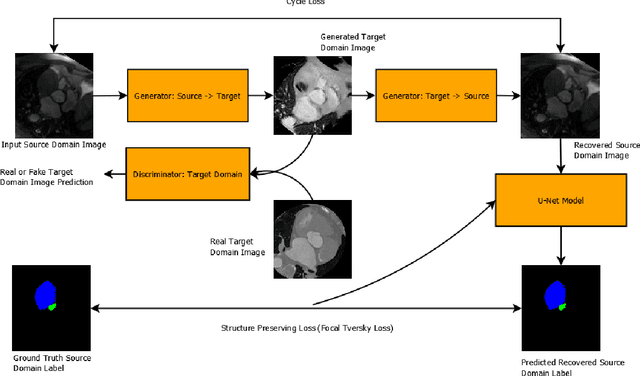

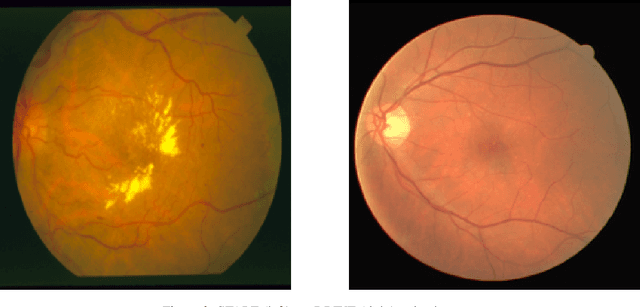

The presence of domain shift in medical imaging is a common issue, which can greatly impact the performance of segmentation models when dealing with unseen image domains. Adversarial-based deep learning models, such as Cycle-GAN, have become a common model for approaching unsupervised domain adaptation of medical images. These models however, have no ability to enforce the preservation of structures of interest when translating medical scans, which can lead to potentially poor results for unsupervised domain adaptation within the context of segmentation. This work introduces the Structure Preserving Cycle-GAN (SP Cycle-GAN), which promotes medical structure preservation during image translation through the enforcement of a segmentation loss term in the overall Cycle-GAN training process. We demonstrate the structure preserving capability of the SP Cycle-GAN both visually and through comparison of Dice score segmentation performance for the unsupervised domain adaptation models. The SP Cycle-GAN is able to outperform baseline approaches and standard Cycle-GAN domain adaptation for binary blood vessel segmentation in the STARE and DRIVE datasets, and multi-class Left Ventricle and Myocardium segmentation in the multi-modal MM-WHS dataset. SP Cycle-GAN achieved a state of the art Myocardium segmentation Dice score (DSC) of 0.7435 for the MR to CT MM-WHS domain adaptation problem, and excelled in nearly all categories for the MM-WHS dataset. SP Cycle-GAN also demonstrated a strong ability to preserve blood vessel structure in the DRIVE to STARE domain adaptation problem, achieving a 4% DSC increase over a default Cycle-GAN implementation.
Benchmark data to study the influence of pre-training on explanation performance in MR image classification
Jun 21, 2023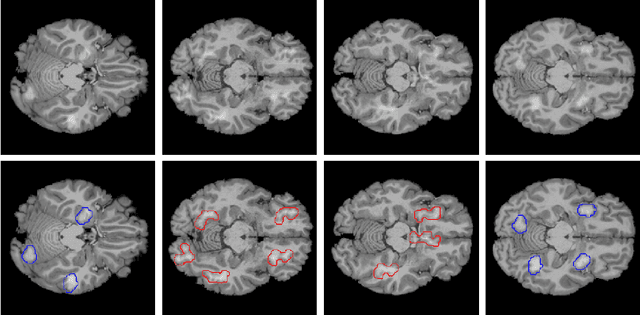
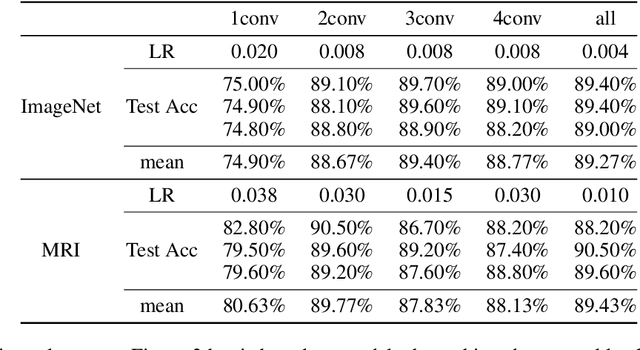

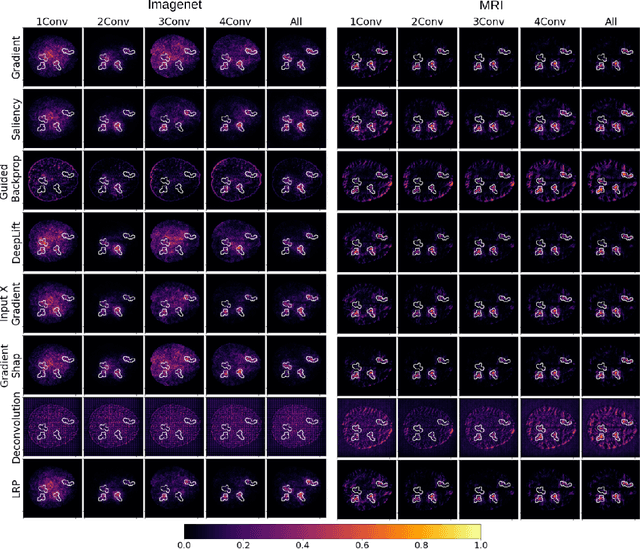
Convolutional Neural Networks (CNNs) are frequently and successfully used in medical prediction tasks. They are often used in combination with transfer learning, leading to improved performance when training data for the task are scarce. The resulting models are highly complex and typically do not provide any insight into their predictive mechanisms, motivating the field of 'explainable' artificial intelligence (XAI). However, previous studies have rarely quantitatively evaluated the 'explanation performance' of XAI methods against ground-truth data, and transfer learning and its influence on objective measures of explanation performance has not been investigated. Here, we propose a benchmark dataset that allows for quantifying explanation performance in a realistic magnetic resonance imaging (MRI) classification task. We employ this benchmark to understand the influence of transfer learning on the quality of explanations. Experimental results show that popular XAI methods applied to the same underlying model differ vastly in performance, even when considering only correctly classified examples. We further observe that explanation performance strongly depends on the task used for pre-training and the number of CNN layers pre-trained. These results hold after correcting for a substantial correlation between explanation and classification performance.
DreamSim: Learning New Dimensions of Human Visual Similarity using Synthetic Data
Jun 15, 2023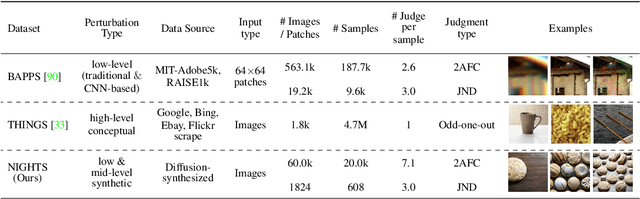
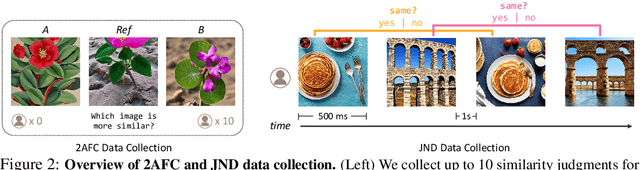
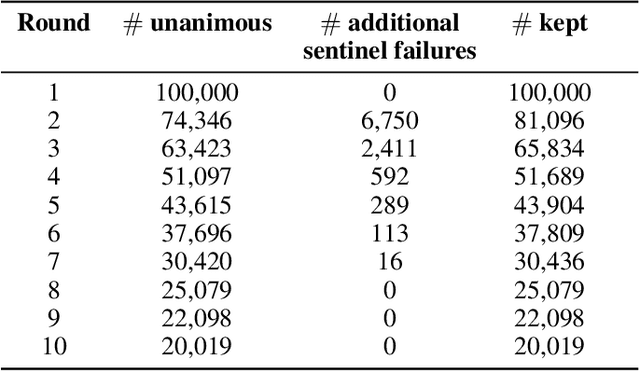
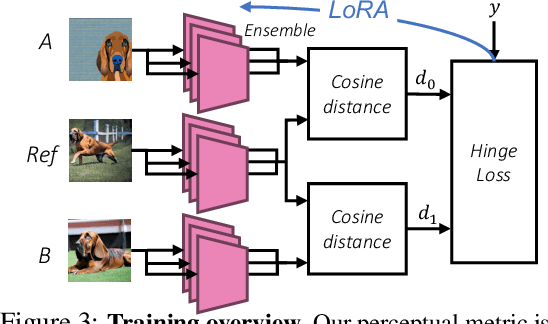
Current perceptual similarity metrics operate at the level of pixels and patches. These metrics compare images in terms of their low-level colors and textures, but fail to capture mid-level similarities and differences in image layout, object pose, and semantic content. In this paper, we develop a perceptual metric that assesses images holistically. Our first step is to collect a new dataset of human similarity judgments over image pairs that are alike in diverse ways. Critical to this dataset is that judgments are nearly automatic and shared by all observers. To achieve this we use recent text-to-image models to create synthetic pairs that are perturbed along various dimensions. We observe that popular perceptual metrics fall short of explaining our new data, and we introduce a new metric, DreamSim, tuned to better align with human perception. We analyze how our metric is affected by different visual attributes, and find that it focuses heavily on foreground objects and semantic content while also being sensitive to color and layout. Notably, despite being trained on synthetic data, our metric generalizes to real images, giving strong results on retrieval and reconstruction tasks. Furthermore, our metric outperforms both prior learned metrics and recent large vision models on these tasks.
Modularity Trumps Invariance for Compositional Robustness
Jun 15, 2023
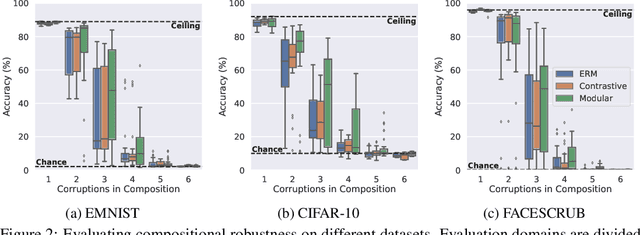
By default neural networks are not robust to changes in data distribution. This has been demonstrated with simple image corruptions, such as blurring or adding noise, degrading image classification performance. Many methods have been proposed to mitigate these issues but for the most part models are evaluated on single corruptions. In reality, visual space is compositional in nature, that is, that as well as robustness to elemental corruptions, robustness to compositions of corruptions is also needed. In this work we develop a compositional image classification task where, given a few elemental corruptions, models are asked to generalize to compositions of these corruptions. That is, to achieve compositional robustness. We experimentally compare empirical risk minimization with an invariance building pairwise contrastive loss and, counter to common intuitions in domain generalization, achieve only marginal improvements in compositional robustness by encouraging invariance. To move beyond invariance, following previously proposed inductive biases that model architectures should reflect data structure, we introduce a modular architecture whose structure replicates the compositional nature of the task. We then show that this modular approach consistently achieves better compositional robustness than non-modular approaches. We additionally find empirical evidence that the degree of invariance between representations of 'in-distribution' elemental corruptions fails to correlate with robustness to 'out-of-distribution' compositions of corruptions.
M3PT: A Multi-Modal Model for POI Tagging
Jun 16, 2023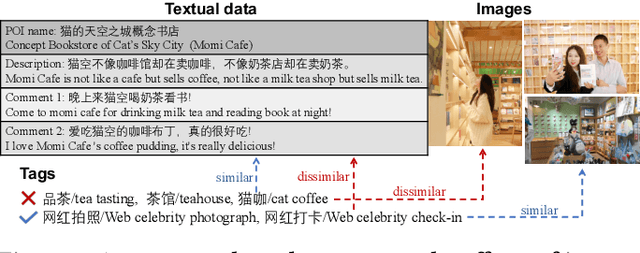

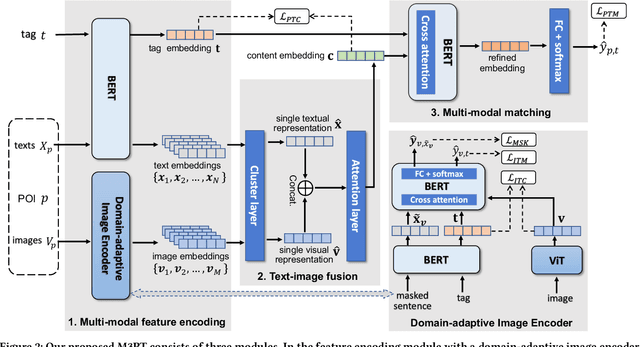

POI tagging aims to annotate a point of interest (POI) with some informative tags, which facilitates many services related to POIs, including search, recommendation, and so on. Most of the existing solutions neglect the significance of POI images and seldom fuse the textual and visual features of POIs, resulting in suboptimal tagging performance. In this paper, we propose a novel Multi-Modal Model for POI Tagging, namely M3PT, which achieves enhanced POI tagging through fusing the target POI's textual and visual features, and the precise matching between the multi-modal representations. Specifically, we first devise a domain-adaptive image encoder (DIE) to obtain the image embeddings aligned to their gold tags' semantics. Then, in M3PT's text-image fusion module (TIF), the textual and visual representations are fully fused into the POIs' content embeddings for the subsequent matching. In addition, we adopt a contrastive learning strategy to further bridge the gap between the representations of different modalities. To evaluate the tagging models' performance, we have constructed two high-quality POI tagging datasets from the real-world business scenario of Ali Fliggy. Upon the datasets, we conducted the extensive experiments to demonstrate our model's advantage over the baselines of uni-modality and multi-modality, and verify the effectiveness of important components in M3PT, including DIE, TIF and the contrastive learning strategy.
Compositionally Equivariant Representation Learning
Jun 17, 2023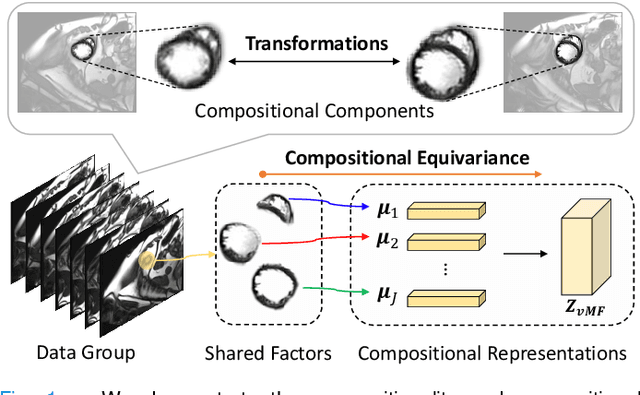
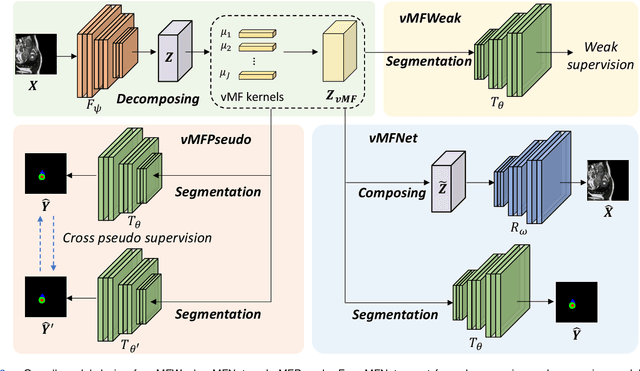
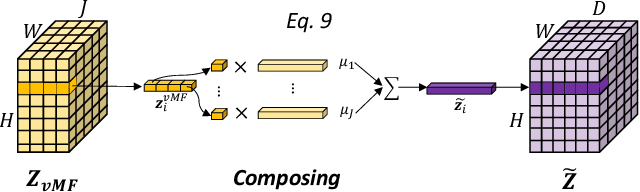
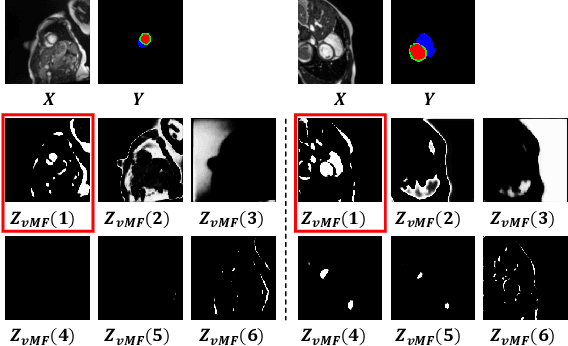
Deep learning models often need sufficient supervision (i.e. labelled data) in order to be trained effectively. By contrast, humans can swiftly learn to identify important anatomy in medical images like MRI and CT scans, with minimal guidance. This recognition capability easily generalises to new images from different medical facilities and to new tasks in different settings. This rapid and generalisable learning ability is largely due to the compositional structure of image patterns in the human brain, which are not well represented in current medical models. In this paper, we study the utilisation of compositionality in learning more interpretable and generalisable representations for medical image segmentation. Overall, we propose that the underlying generative factors that are used to generate the medical images satisfy compositional equivariance property, where each factor is compositional (e.g. corresponds to the structures in human anatomy) and also equivariant to the task. Hence, a good representation that approximates well the ground truth factor has to be compositionally equivariant. By modelling the compositional representations with learnable von-Mises-Fisher (vMF) kernels, we explore how different design and learning biases can be used to enforce the representations to be more compositionally equivariant under un-, weakly-, and semi-supervised settings. Extensive results show that our methods achieve the best performance over several strong baselines on the task of semi-supervised domain-generalised medical image segmentation. Code will be made publicly available upon acceptance at https://github.com/vios-s.
Learning Iterative Neural Optimizers for Image Steganography
Mar 27, 2023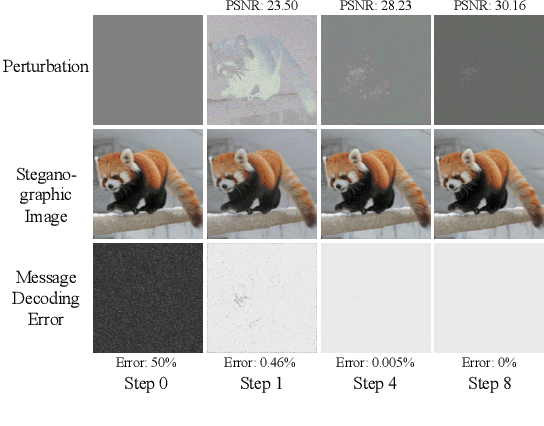
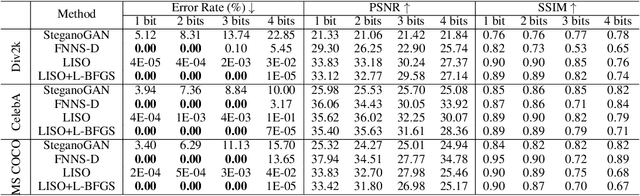
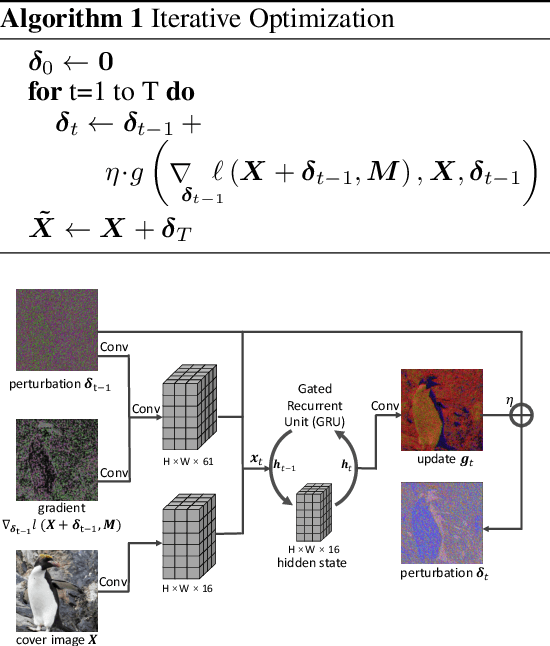

Image steganography is the process of concealing secret information in images through imperceptible changes. Recent work has formulated this task as a classic constrained optimization problem. In this paper, we argue that image steganography is inherently performed on the (elusive) manifold of natural images, and propose an iterative neural network trained to perform the optimization steps. In contrast to classical optimization methods like L-BFGS or projected gradient descent, we train the neural network to also stay close to the manifold of natural images throughout the optimization. We show that our learned neural optimization is faster and more reliable than classical optimization approaches. In comparison to previous state-of-the-art encoder-decoder-based steganography methods, it reduces the recovery error rate by multiple orders of magnitude and achieves zero error up to 3 bits per pixel (bpp) without the need for error-correcting codes.
Text-Conditioned Sampling Framework for Text-to-Image Generation with Masked Generative Models
Apr 04, 2023
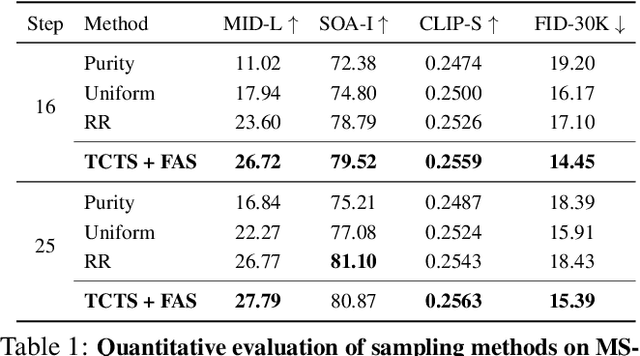

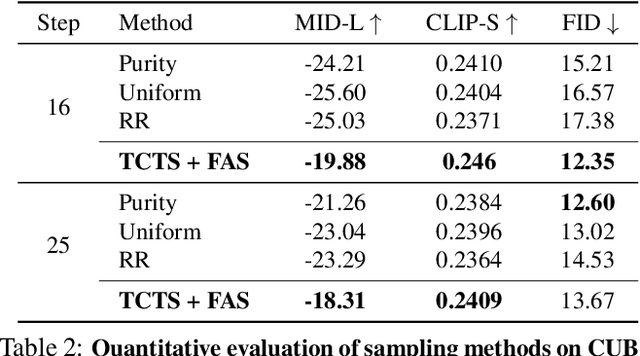
Token-based masked generative models are gaining popularity for their fast inference time with parallel decoding. While recent token-based approaches achieve competitive performance to diffusion-based models, their generation performance is still suboptimal as they sample multiple tokens simultaneously without considering the dependence among them. We empirically investigate this problem and propose a learnable sampling model, Text-Conditioned Token Selection (TCTS), to select optimal tokens via localized supervision with text information. TCTS improves not only the image quality but also the semantic alignment of the generated images with the given texts. To further improve the image quality, we introduce a cohesive sampling strategy, Frequency Adaptive Sampling (FAS), to each group of tokens divided according to the self-attention maps. We validate the efficacy of TCTS combined with FAS with various generative tasks, demonstrating that it significantly outperforms the baselines in image-text alignment and image quality. Our text-conditioned sampling framework further reduces the original inference time by more than 50% without modifying the original generative model.
The ImSPOC snapshot imaging spectrometer: image formation model and device characterization
Mar 27, 2023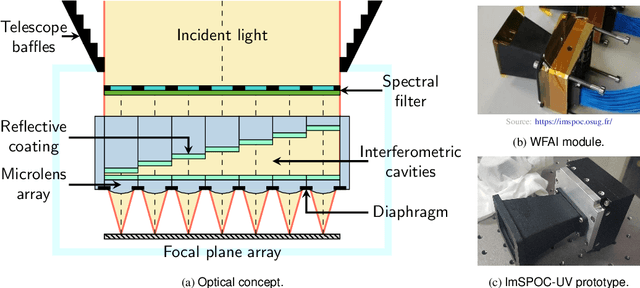
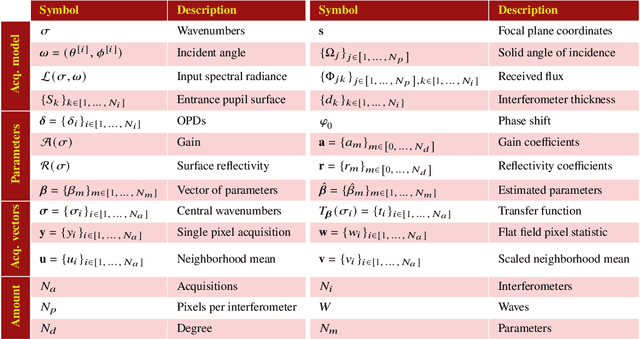
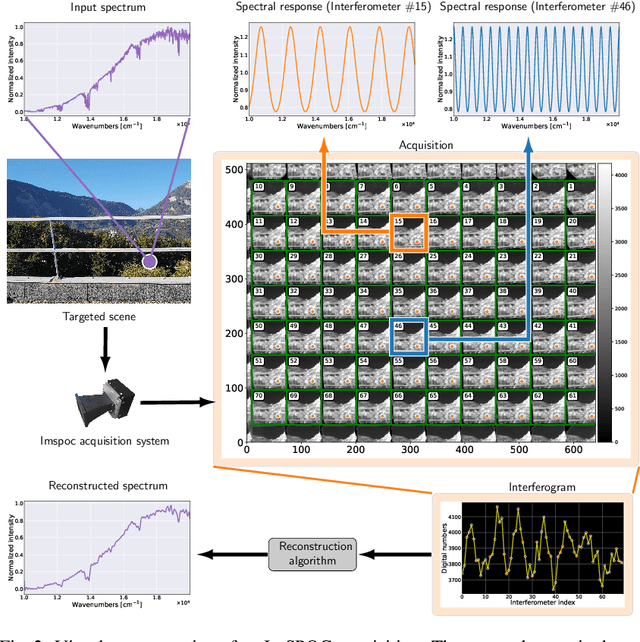
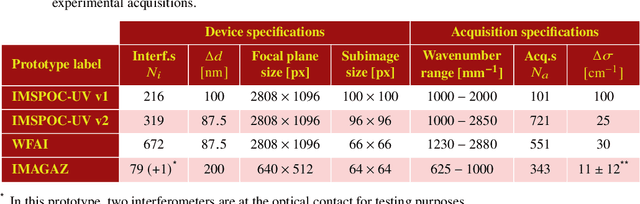
In recent years, the demand for capturing spectral information with finer detail has increased, requiring hyperspectral imaging devices capable of acquiring the required information with increased temporal, spatial and spectral resolution. In this work, we present the image acquisition model of the Image SPectrometer On Chip (ImSPOC), a novel compact snapshot image spectrometer based on the interferometry of Fabry-Perot. Additionally, we propose the interferometer response characterization algorithm (IRCA), a robust three-step procedure to characterize the ImSPOC device that estimates the optical parameters of the composing interferometers' transfer function. The proposed algorithm processes the image output from a set of monochromatic light sources, refining the results through nonlinear regression after an ad-hoc initialization. Experimental analysis confirms the performances of the proposed approach for the characterization of four different ImSPOC prototypes. The source code associated to this paper is available at https://github.com/danaroth83/irca.
Inter-Instance Similarity Modeling for Contrastive Learning
Jun 21, 2023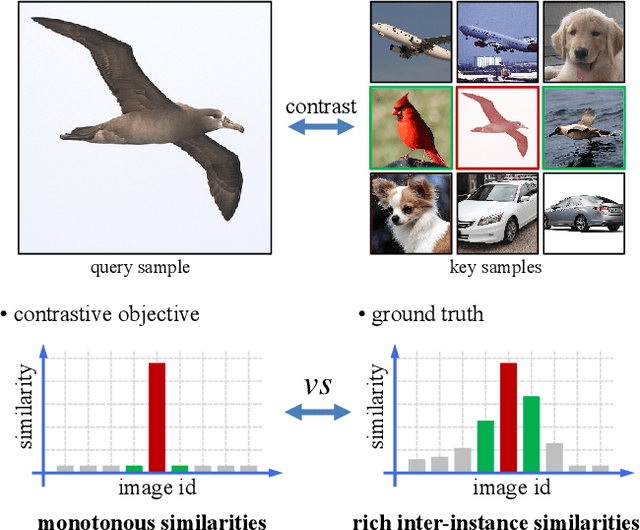

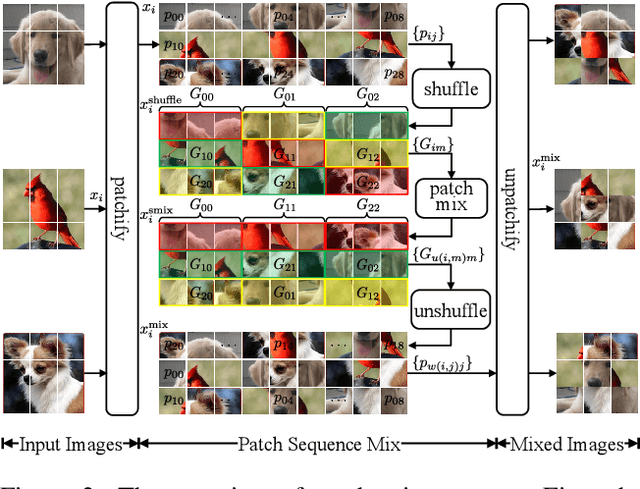
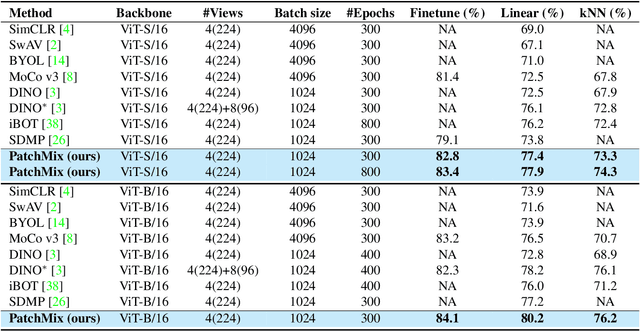
The existing contrastive learning methods widely adopt one-hot instance discrimination as pretext task for self-supervised learning, which inevitably neglects rich inter-instance similarities among natural images, then leading to potential representation degeneration. In this paper, we propose a novel image mix method, PatchMix, for contrastive learning in Vision Transformer (ViT), to model inter-instance similarities among images. Following the nature of ViT, we randomly mix multiple images from mini-batch in patch level to construct mixed image patch sequences for ViT. Compared to the existing sample mix methods, our PatchMix can flexibly and efficiently mix more than two images and simulate more complicated similarity relations among natural images. In this manner, our contrastive framework can significantly reduce the gap between contrastive objective and ground truth in reality. Experimental results demonstrate that our proposed method significantly outperforms the previous state-of-the-art on both ImageNet-1K and CIFAR datasets, e.g., 3.0% linear accuracy improvement on ImageNet-1K and 8.7% kNN accuracy improvement on CIFAR100. Moreover, our method achieves the leading transfer performance on downstream tasks, object detection and instance segmentation on COCO dataset. The code is available at https://github.com/visresearch/patchmix.