 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Hamming Similarity and Graph Laplacians for Class Partitioning and Adversarial Image Detection
May 06, 2023
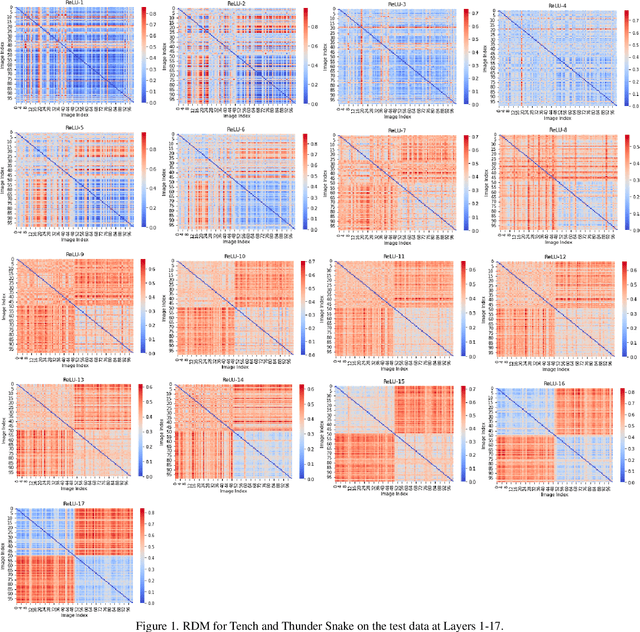

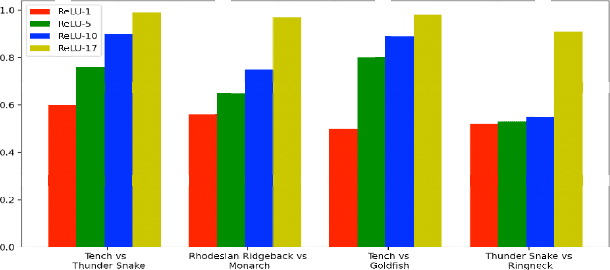

Researchers typically investigate neural network representations by examining activation outputs for one or more layers of a network. Here, we investigate the potential for ReLU activation patterns (encoded as bit vectors) to aid in understanding and interpreting the behavior of neural networks. We utilize Representational Dissimilarity Matrices (RDMs) to investigate the coherence of data within the embedding spaces of a deep neural network. From each layer of a network, we extract and utilize bit vectors to construct similarity scores between images. From these similarity scores, we build a similarity matrix for a collection of images drawn from 2 classes. We then apply Fiedler partitioning to the associated Laplacian matrix to separate the classes. Our results indicate, through bit vector representations, that the network continues to refine class detectability with the last ReLU layer achieving better than 95\% separation accuracy. Additionally, we demonstrate that bit vectors aid in adversarial image detection, again achieving over 95\% accuracy in separating adversarial and non-adversarial images using a simple classifier.
FlowFace++: Explicit Semantic Flow-supervised End-to-End Face Swapping
Jun 26, 2023


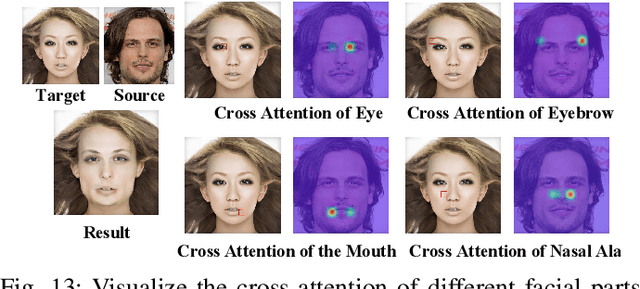
This work proposes a novel face-swapping framework FlowFace++, utilizing explicit semantic flow supervision and end-to-end architecture to facilitate shape-aware face-swapping. Specifically, our work pretrains a facial shape discriminator to supervise the face swapping network. The discriminator is shape-aware and relies on a semantic flow-guided operation to explicitly calculate the shape discrepancies between the target and source faces, thus optimizing the face swapping network to generate highly realistic results. The face swapping network is a stack of a pre-trained face-masked autoencoder (MAE), a cross-attention fusion module, and a convolutional decoder. The MAE provides a fine-grained facial image representation space, which is unified for the target and source faces and thus facilitates final realistic results. The cross-attention fusion module carries out the source-to-target face swapping in a fine-grained latent space while preserving other attributes of the target image (e.g. expression, head pose, hair, background, illumination, etc). Lastly, the convolutional decoder further synthesizes the swapping results according to the face-swapping latent embedding from the cross-attention fusion module. Extensive quantitative and qualitative experiments on in-the-wild faces demonstrate that our FlowFace++ outperforms the state-of-the-art significantly, particularly while the source face is obstructed by uneven lighting or angle offset.
Deep learning-based image exposure enhancement as a pre-processing for an accurate 3D colon surface reconstruction
Apr 14, 2023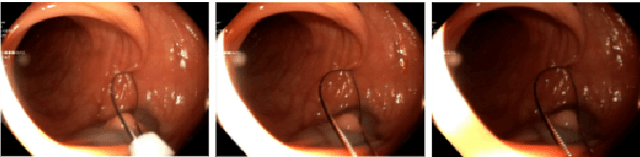

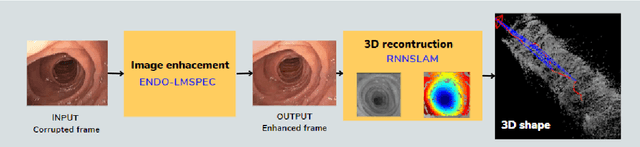
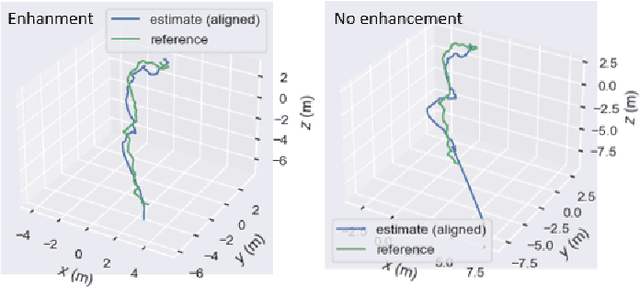
This contribution shows how an appropriate image pre-processing can improve a deep-learning based 3D reconstruction of colon parts. The assumption is that, rather than global image illumination corrections, local under- and over-exposures should be corrected in colonoscopy. An overview of the pipeline including the image exposure correction and a RNN-SLAM is first given. Then, this paper quantifies the reconstruction accuracy of the endoscope trajectory in the colon with and without appropriate illumination correction
Increasing Textual Context Size Boosts Medical Image-Text Matching
Mar 23, 2023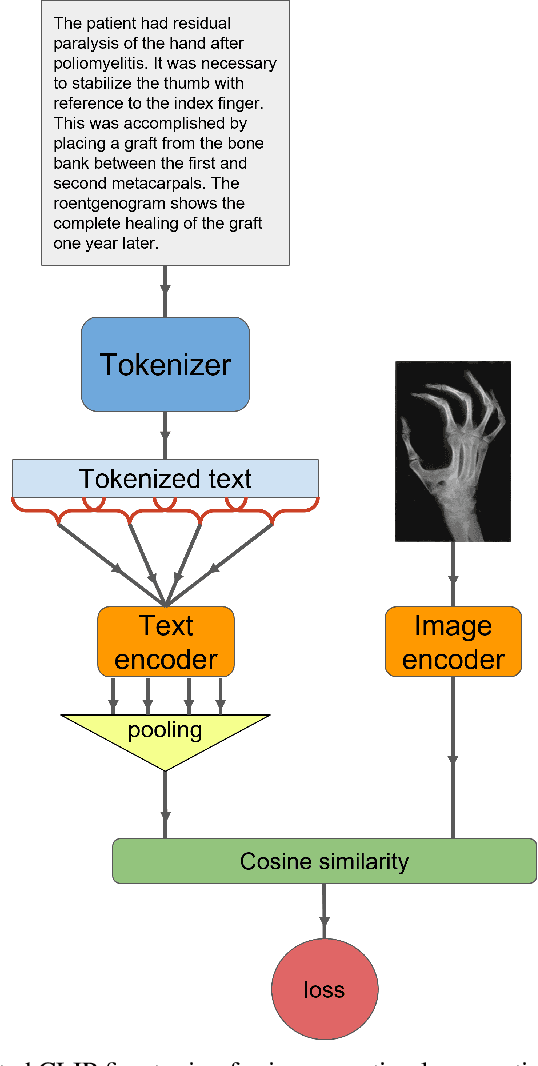
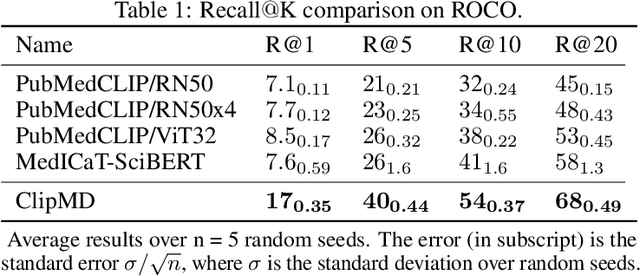
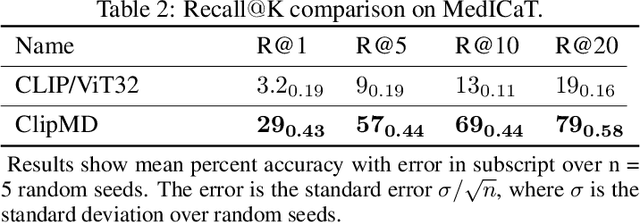
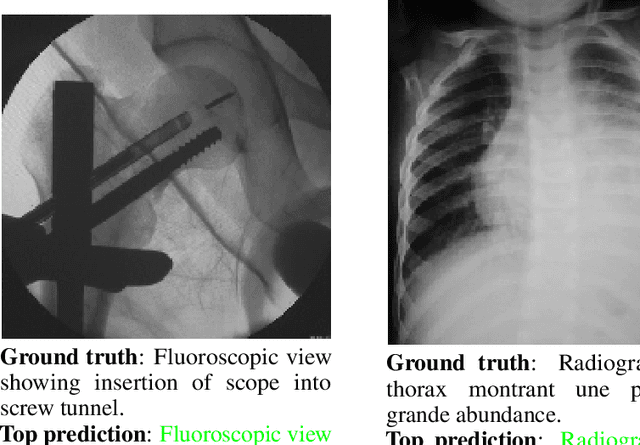
This short technical report demonstrates a simple technique that yields state of the art results in medical image-text matching tasks. We analyze the use of OpenAI's CLIP, a general image-text matching model, and observe that CLIP's limited textual input size has negative impact on downstream performance in the medical domain where encoding longer textual contexts is often required. We thus train and release ClipMD, which is trained with a simple sliding window technique to encode textual captions. ClipMD was tested on two medical image-text datasets and compared with other image-text matching models. The results show that ClipMD outperforms other models on both datasets by a large margin. We make our code and pretrained model publicly available.
CNN-BiLSTM model for English Handwriting Recognition: Comprehensive Evaluation on the IAM Dataset
Jul 02, 2023

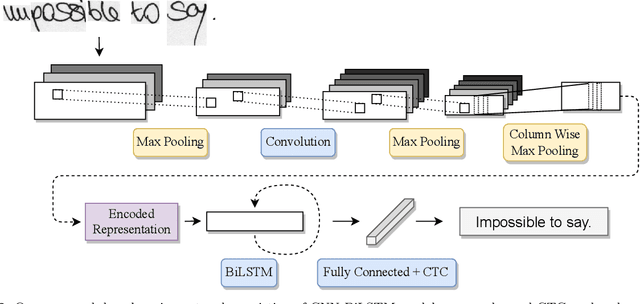
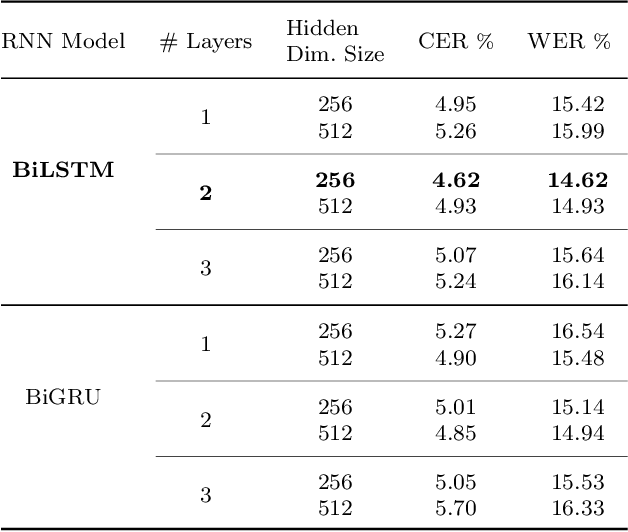
We present a CNN-BiLSTM system for the problem of offline English handwriting recognition, with extensive evaluations on the public IAM dataset, including the effects of model size, data augmentation and the lexicon. Our best model achieves 3.59\% CER and 9.44\% WER using CNN-BiLSTM network with CTC layer. Test time augmentation with rotation and shear transformations applied to the input image, is proposed to increase recognition of difficult cases and found to reduce the word error rate by 2.5\% points. We also conduct an error analysis of our proposed method on IAM dataset, show hard cases of handwriting images and explore samples with erroneous labels. We provide our source code as public-domain, to foster further research to encourage scientific reproducibility.
Channel Adaptive DL based Joint Source-Channel Coding without A Prior Knowledge
Jun 27, 2023
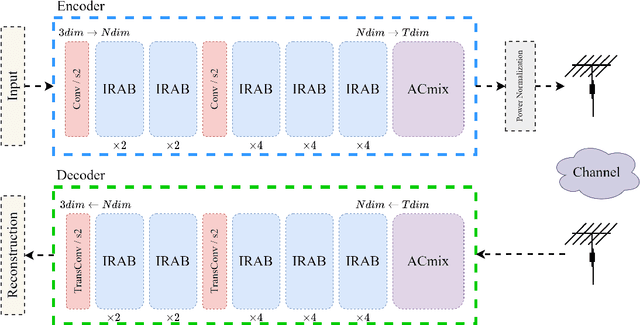
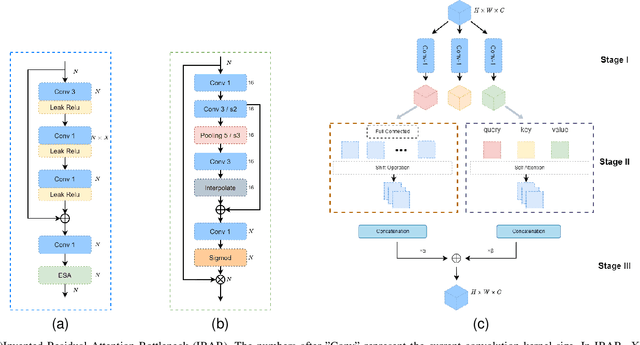
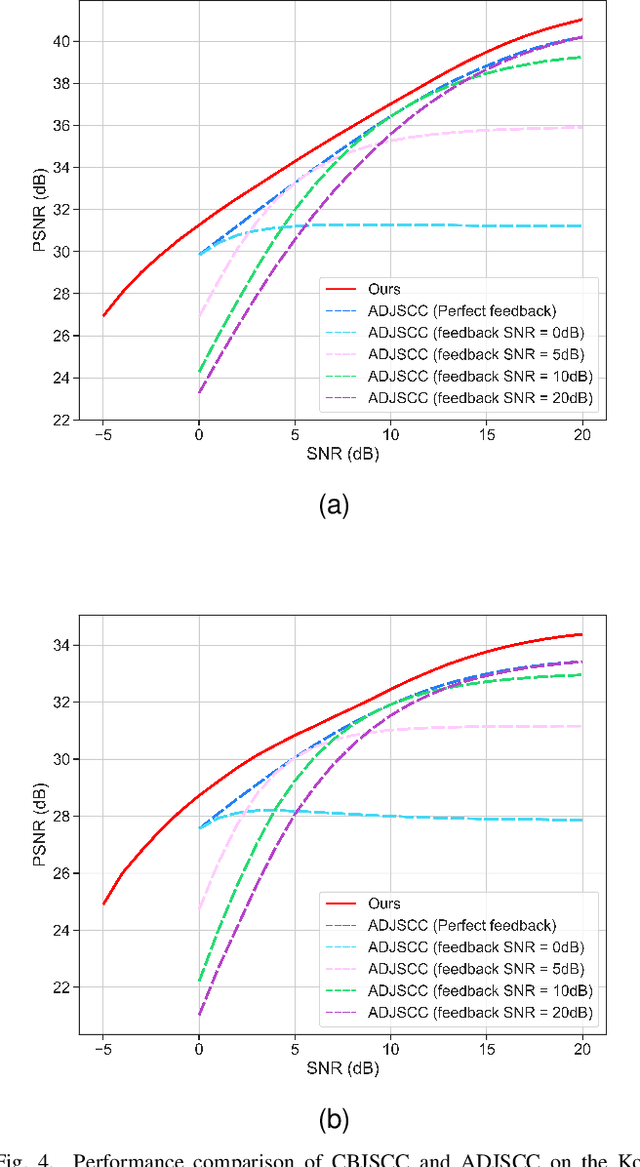
Significant progress has been made in wireless Joint Source-Channel Coding (JSCC) using deep learning techniques. The latest DL-based image JSCC methods have demonstrated exceptional performance across various signal-to-noise ratio (SNR) levels during transmission, while also avoiding cliff effects. However, current channel adaptive JSCC methods rely heavily on channel prior knowledge, which can lead to performance degradation in practical applications due to channel mismatch effects. This paper proposes a novel approach for image transmission, called Channel Blind Joint Source-Channel Coding (CBJSCC). CBJSCC utilizes Deep Learning techniques to achieve exceptional performance across various signal-to-noise ratio (SNR) levels during transmission, without relying on channel prior information. We have designed an Inverted Residual Attention Bottleneck (IRAB) module for the model, which can effectively reduce the number of parameters while expanding the receptive field. In addition, we have incorporated a convolution and self-attention mixed encoding module to establish long-range dependency relationships between channel symbols. Our experiments have shown that CBJSCC outperforms existing channel adaptive DL-based JSCC methods that rely on feedback information. Furthermore, we found that channel estimation does not significantly benefit CBJSCC, which provides insights for the future design of DL-based JSCC methods. The reliability of the proposed method is further demonstrated through an analysis of the model bottleneck and its adaptability to different domains, as shown by our experiments.
WiCo: Win-win Cooperation of Bottom-up and Top-down Referring Image Segmentation
Jun 19, 2023
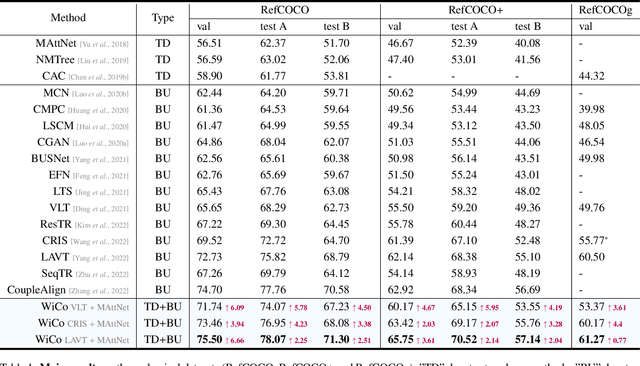
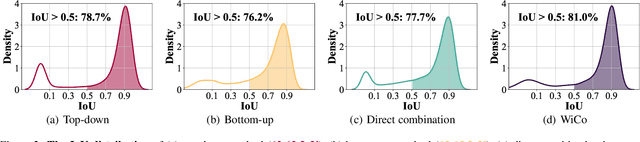
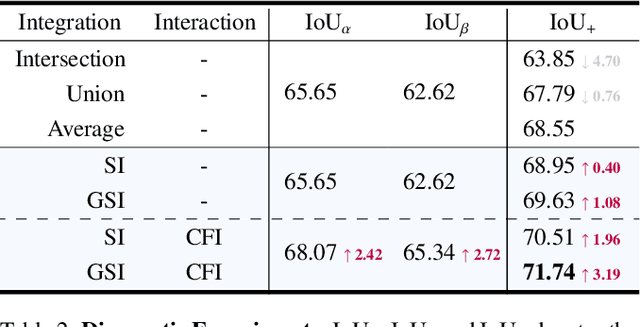
The top-down and bottom-up methods are two mainstreams of referring segmentation, while both methods have their own intrinsic weaknesses. Top-down methods are chiefly disturbed by Polar Negative (PN) errors owing to the lack of fine-grained cross-modal alignment. Bottom-up methods are mainly perturbed by Inferior Positive (IP) errors due to the lack of prior object information. Nevertheless, we discover that two types of methods are highly complementary for restraining respective weaknesses but the direct average combination leads to harmful interference. In this context, we build Win-win Cooperation (WiCo) to exploit complementary nature of two types of methods on both interaction and integration aspects for achieving a win-win improvement. For the interaction aspect, Complementary Feature Interaction (CFI) provides fine-grained information to top-down branch and introduces prior object information to bottom-up branch for complementary feature enhancement. For the integration aspect, Gaussian Scoring Integration (GSI) models the gaussian performance distributions of two branches and weightedly integrates results by sampling confident scores from the distributions. With our WiCo, several prominent top-down and bottom-up combinations achieve remarkable improvements on three common datasets with reasonable extra costs, which justifies effectiveness and generality of our method.
MQ-Coder inspired arithmetic coder for synthetic DNA data storage
Jun 22, 2023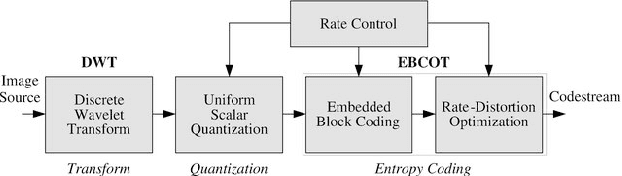
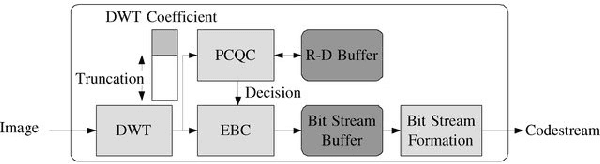

Over the past years, the ever-growing trend on data storage demand, more specifically for "cold" data (i.e. rarely accessed), has motivated research for alternative systems of data storage. Because of its biochemical characteristics, synthetic DNA molecules are now considered as serious candidates for this new kind of storage. This paper introduces a novel arithmetic coder for DNA data storage, and presents some results on a lossy JPEG 2000 based image compression method adapted for DNA data storage that uses this novel coder. The DNA coding algorithms presented here have been designed to efficiently compress images, encode them into a quaternary code, and finally store them into synthetic DNA molecules. This work also aims at making the compression models better fit the problematic that we encounter when storing data into DNA, namely the fact that the DNA writing, storing and reading methods are error prone processes. The main take away of this work is our arithmetic coder and it's integration into a performant image codec.
Improving Log-Cumulant Based Estimation of Roughness Information in SAR imagery
Jun 22, 2023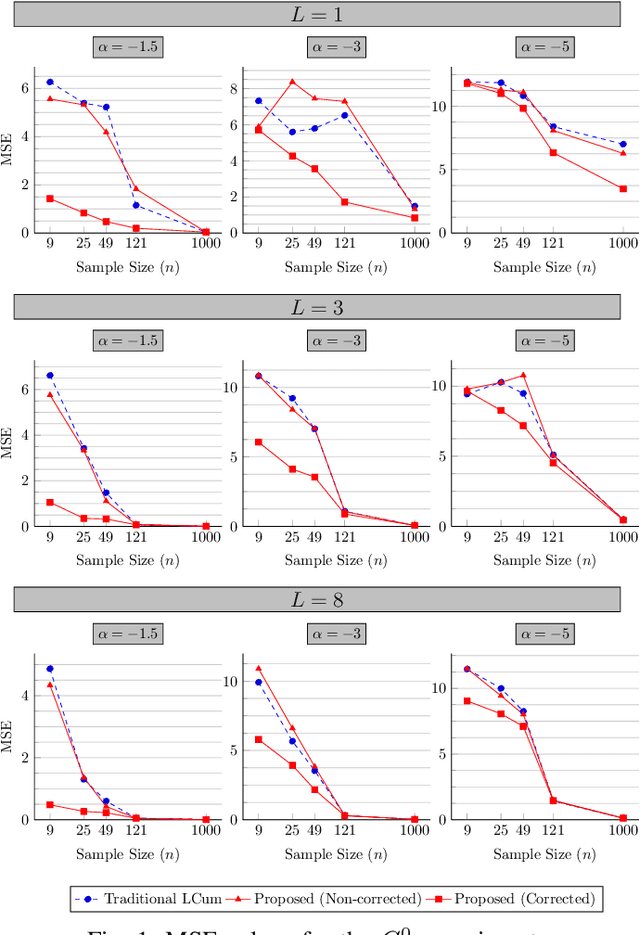
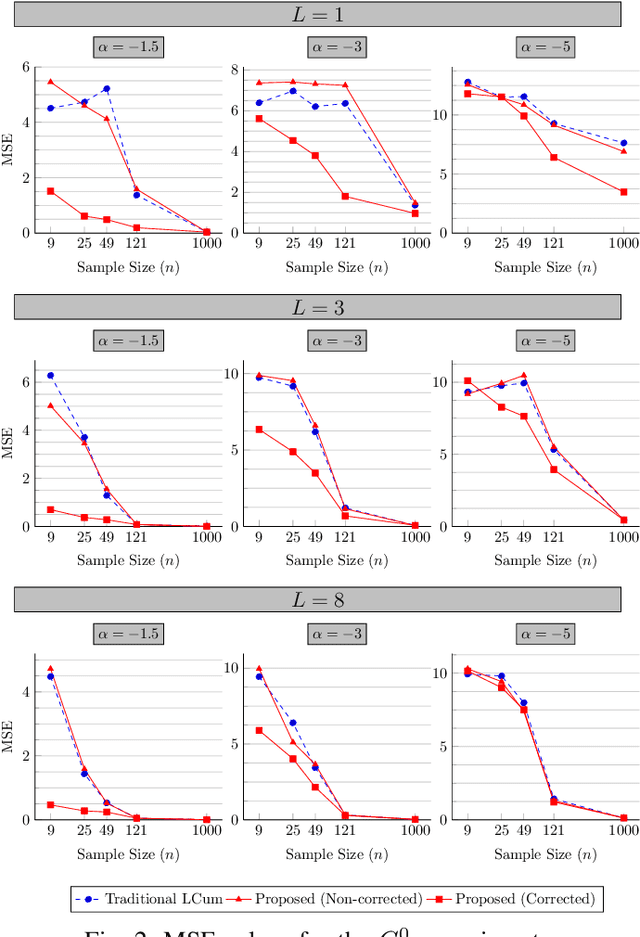

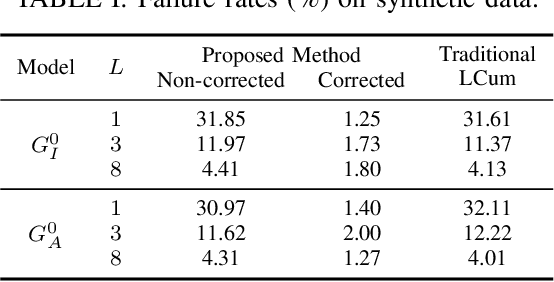
Synthetic Aperture Radar (SAR) image understanding is crucial in remote sensing applications, but it is hindered by its intrinsic noise contamination, called speckle. Sophisticated statistical models, such as the $\mathcal{G}^0$ family of distributions, have been employed to SAR data and many of the current advancements in processing this imagery have been accomplished through extracting information from these models. In this paper, we propose improvements to parameter estimation in $\mathcal{G}^0$ distributions using the Method of Log-Cumulants. First, using Bayesian modeling, we construct that regularly produce reliable roughness estimates under both $\mathcal{G}^0_A$ and $\mathcal{G}^0_I$ models. Second, we make use of an approximation of the Trigamma function to compute the estimated roughness in constant time, making it considerably faster than the existing method for this task. Finally, we show how we can use this method to achieve fast and reliable SAR image understanding based on roughness information.
Parameter-Free Channel Attention for Image Classification and Super-Resolution
Mar 20, 2023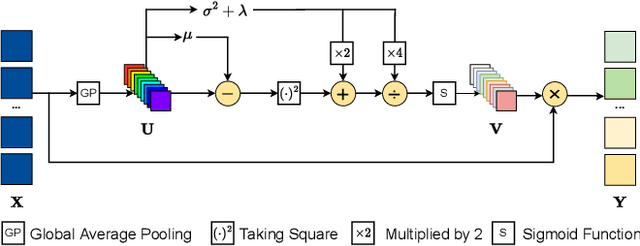
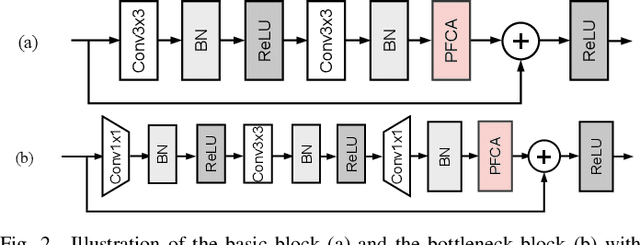
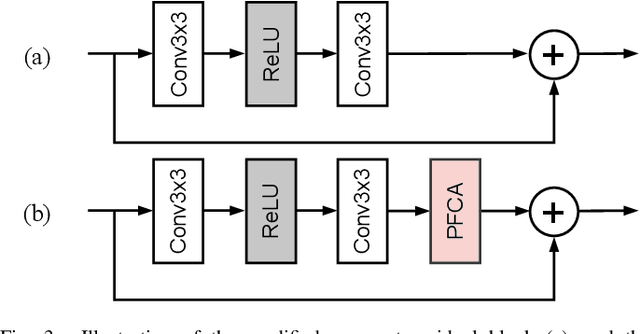
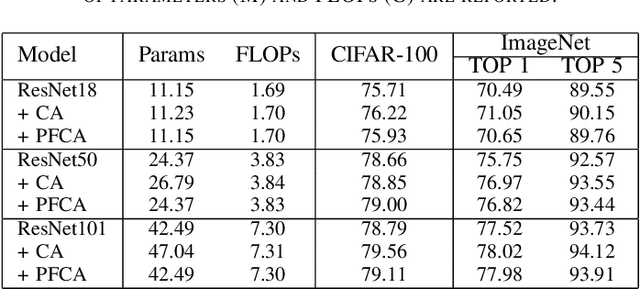
The channel attention mechanism is a useful technique widely employed in deep convolutional neural networks to boost the performance for image processing tasks, eg, image classification and image super-resolution. It is usually designed as a parameterized sub-network and embedded into the convolutional layers of the network to learn more powerful feature representations. However, current channel attention induces more parameters and therefore leads to higher computational costs. To deal with this issue, in this work, we propose a Parameter-Free Channel Attention (PFCA) module to boost the performance of popular image classification and image super-resolution networks, but completely sweep out the parameter growth of channel attention. Experiments on CIFAR-100, ImageNet, and DIV2K validate that our PFCA module improves the performance of ResNet on image classification and improves the performance of MSRResNet on image super-resolution tasks, respectively, while bringing little growth of parameters and FLOPs.