 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Promoting Exploration in Memory-Augmented Adam using Critical Momenta
Jul 18, 2023

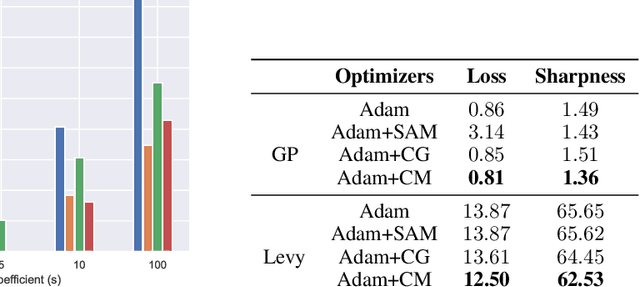

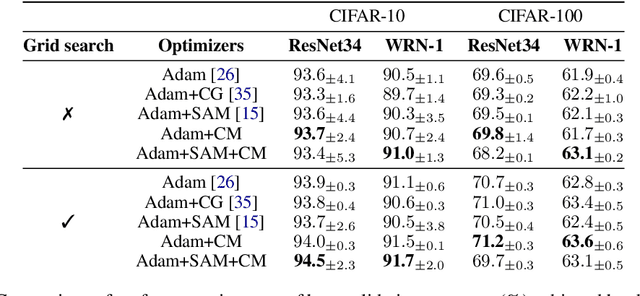
Adaptive gradient-based optimizers, particularly Adam, have left their mark in training large-scale deep learning models. The strength of such optimizers is that they exhibit fast convergence while being more robust to hyperparameter choice. However, they often generalize worse than non-adaptive methods. Recent studies have tied this performance gap to flat minima selection: adaptive methods tend to find solutions in sharper basins of the loss landscape, which in turn hurts generalization. To overcome this issue, we propose a new memory-augmented version of Adam that promotes exploration towards flatter minima by using a buffer of critical momentum terms during training. Intuitively, the use of the buffer makes the optimizer overshoot outside the basin of attraction if it is not wide enough. We empirically show that our method improves the performance of several variants of Adam on standard supervised language modelling and image classification tasks.
Mitigating Calibration Bias Without Fixed Attribute Grouping for Improved Fairness in Medical Imaging Analysis
Jul 04, 2023Trustworthy deployment of deep learning medical imaging models into real-world clinical practice requires that they be calibrated. However, models that are well calibrated overall can still be poorly calibrated for a sub-population, potentially resulting in a clinician unwittingly making poor decisions for this group based on the recommendations of the model. Although methods have been shown to successfully mitigate biases across subgroups in terms of model accuracy, this work focuses on the open problem of mitigating calibration biases in the context of medical image analysis. Our method does not require subgroup attributes during training, permitting the flexibility to mitigate biases for different choices of sensitive attributes without re-training. To this end, we propose a novel two-stage method: Cluster-Focal to first identify poorly calibrated samples, cluster them into groups, and then introduce group-wise focal loss to improve calibration bias. We evaluate our method on skin lesion classification with the public HAM10000 dataset, and on predicting future lesional activity for multiple sclerosis (MS) patients. In addition to considering traditional sensitive attributes (e.g. age, sex) with demographic subgroups, we also consider biases among groups with different image-derived attributes, such as lesion load, which are required in medical image analysis. Our results demonstrate that our method effectively controls calibration error in the worst-performing subgroups while preserving prediction performance, and outperforming recent baselines.
Training Energy-Based Models with Diffusion Contrastive Divergences
Jul 04, 2023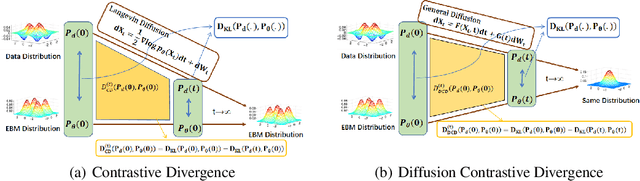


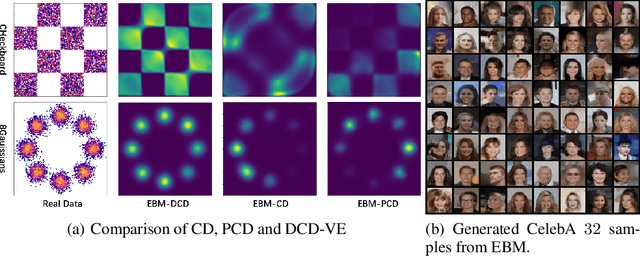
Energy-Based Models (EBMs) have been widely used for generative modeling. Contrastive Divergence (CD), a prevailing training objective for EBMs, requires sampling from the EBM with Markov Chain Monte Carlo methods (MCMCs), which leads to an irreconcilable trade-off between the computational burden and the validity of the CD. Running MCMCs till convergence is computationally intensive. On the other hand, short-run MCMC brings in an extra non-negligible parameter gradient term that is difficult to handle. In this paper, we provide a general interpretation of CD, viewing it as a special instance of our proposed Diffusion Contrastive Divergence (DCD) family. By replacing the Langevin dynamic used in CD with other EBM-parameter-free diffusion processes, we propose a more efficient divergence. We show that the proposed DCDs are both more computationally efficient than the CD and are not limited to a non-negligible gradient term. We conduct intensive experiments, including both synthesis data modeling and high-dimensional image denoising and generation, to show the advantages of the proposed DCDs. On the synthetic data learning and image denoising experiments, our proposed DCD outperforms CD by a large margin. In image generation experiments, the proposed DCD is capable of training an energy-based model for generating the Celab-A $32\times 32$ dataset, which is comparable to existing EBMs.
DifFSS: Diffusion Model for Few-Shot Semantic Segmentation
Jul 03, 2023Diffusion models have demonstrated excellent performance in image generation. Although various few-shot semantic segmentation (FSS) models with different network structures have been proposed, performance improvement has reached a bottleneck. This paper presents the first work to leverage the diffusion model for FSS task, called DifFSS. DifFSS, a novel FSS paradigm, can further improve the performance of the state-of-the-art FSS models by a large margin without modifying their network structure. Specifically, we utilize the powerful generation ability of diffusion models to generate diverse auxiliary support images by using the semantic mask, scribble or soft HED boundary of the support image as control conditions. This generation process simulates the variety within the class of the query image, such as color, texture variation, lighting, $etc$. As a result, FSS models can refer to more diverse support images, yielding more robust representations, thereby achieving a consistent improvement in segmentation performance. Extensive experiments on three publicly available datasets based on existing advanced FSS models demonstrate the effectiveness of the diffusion model for FSS task. Furthermore, we explore in detail the impact of different input settings of the diffusion model on segmentation performance. Hopefully, this completely new paradigm will bring inspiration to the study of FSS task integrated with AI-generated content.
Development of pericardial fat count images using a combination of three different deep-learning models
Jul 25, 2023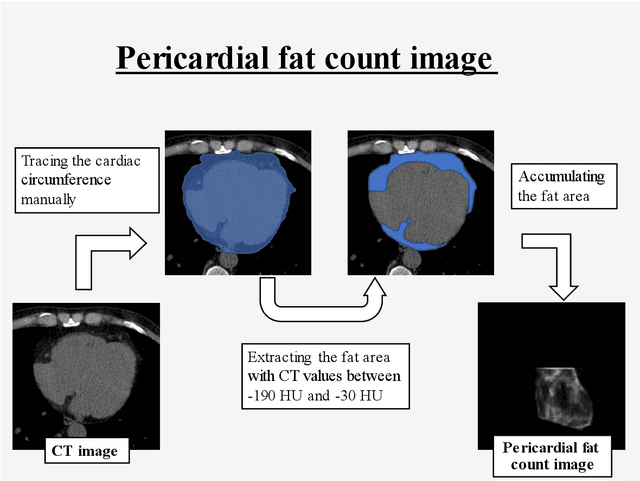
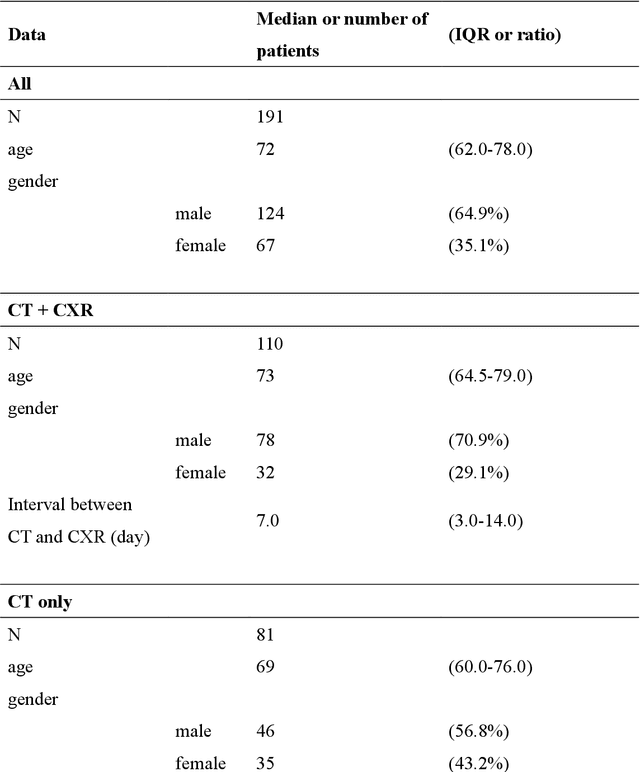
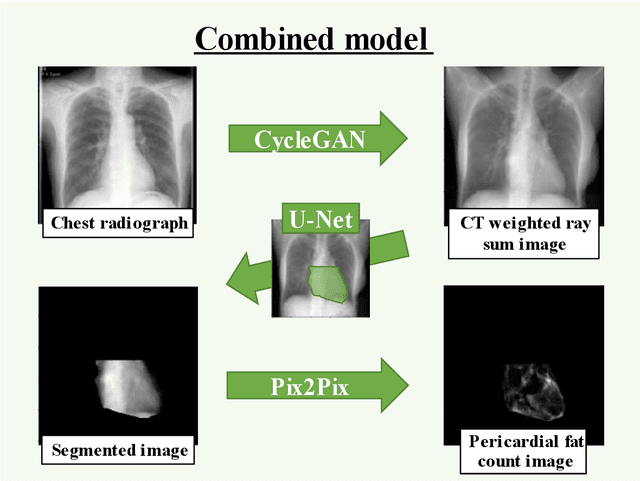
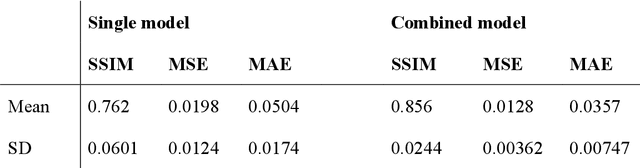
Rationale and Objectives: Pericardial fat (PF), the thoracic visceral fat surrounding the heart, promotes the development of coronary artery disease by inducing inflammation of the coronary arteries. For evaluating PF, this study aimed to generate pericardial fat count images (PFCIs) from chest radiographs (CXRs) using a dedicated deep-learning model. Materials and Methods: The data of 269 consecutive patients who underwent coronary computed tomography (CT) were reviewed. Patients with metal implants, pleural effusion, history of thoracic surgery, or that of malignancy were excluded. Thus, the data of 191 patients were used. PFCIs were generated from the projection of three-dimensional CT images, where fat accumulation was represented by a high pixel value. Three different deep-learning models, including CycleGAN, were combined in the proposed method to generate PFCIs from CXRs. A single CycleGAN-based model was used to generate PFCIs from CXRs for comparison with the proposed method. To evaluate the image quality of the generated PFCIs, structural similarity index measure (SSIM), mean squared error (MSE), and mean absolute error (MAE) of (i) the PFCI generated using the proposed method and (ii) the PFCI generated using the single model were compared. Results: The mean SSIM, MSE, and MAE were as follows: 0.856, 0.0128, and 0.0357, respectively, for the proposed model; and 0.762, 0.0198, and 0.0504, respectively, for the single CycleGAN-based model. Conclusion: PFCIs generated from CXRs with the proposed model showed better performance than those with the single model. PFCI evaluation without CT may be possible with the proposed method.
Foundational Models Defining a New Era in Vision: A Survey and Outlook
Jul 25, 2023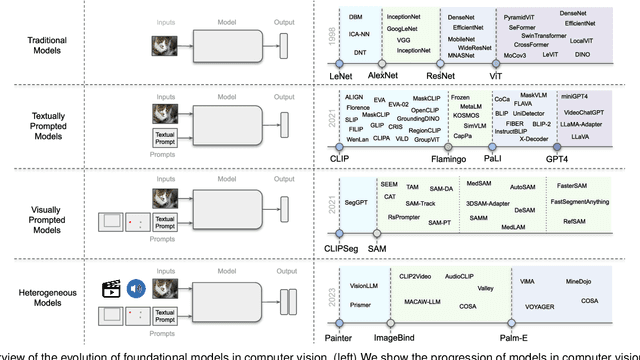
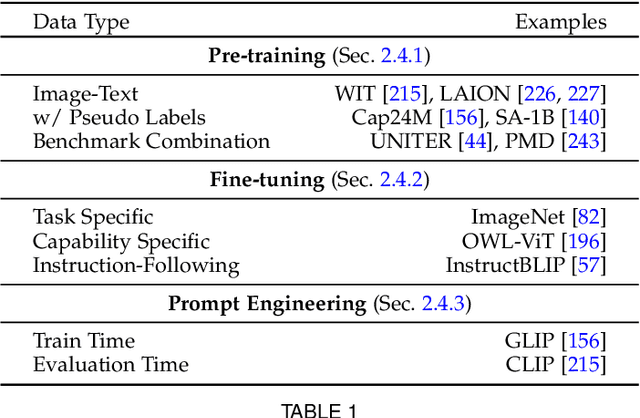
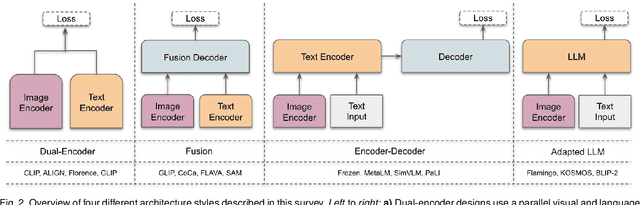
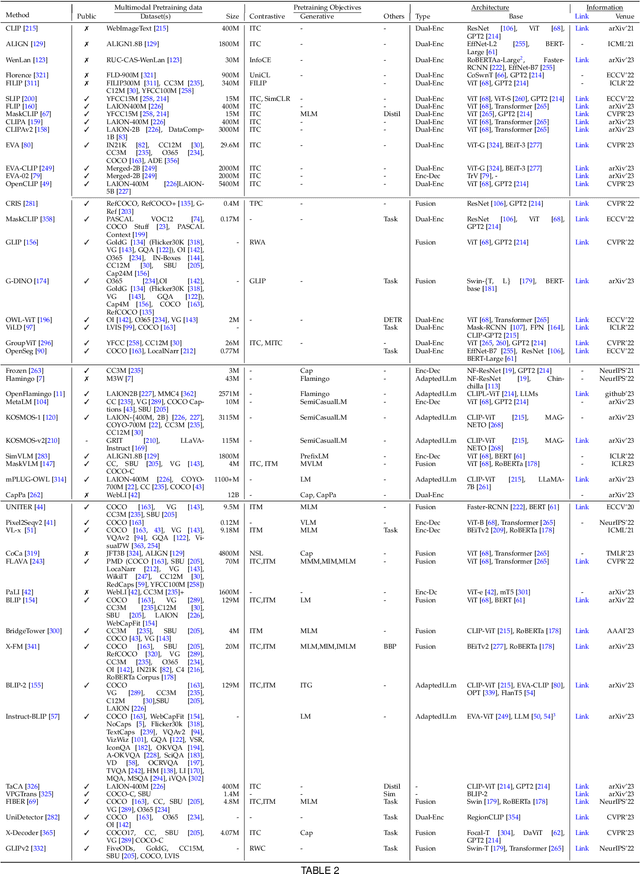
Vision systems to see and reason about the compositional nature of visual scenes are fundamental to understanding our world. The complex relations between objects and their locations, ambiguities, and variations in the real-world environment can be better described in human language, naturally governed by grammatical rules and other modalities such as audio and depth. The models learned to bridge the gap between such modalities coupled with large-scale training data facilitate contextual reasoning, generalization, and prompt capabilities at test time. These models are referred to as foundational models. The output of such models can be modified through human-provided prompts without retraining, e.g., segmenting a particular object by providing a bounding box, having interactive dialogues by asking questions about an image or video scene or manipulating the robot's behavior through language instructions. In this survey, we provide a comprehensive review of such emerging foundational models, including typical architecture designs to combine different modalities (vision, text, audio, etc), training objectives (contrastive, generative), pre-training datasets, fine-tuning mechanisms, and the common prompting patterns; textual, visual, and heterogeneous. We discuss the open challenges and research directions for foundational models in computer vision, including difficulties in their evaluations and benchmarking, gaps in their real-world understanding, limitations of their contextual understanding, biases, vulnerability to adversarial attacks, and interpretability issues. We review recent developments in this field, covering a wide range of applications of foundation models systematically and comprehensively. A comprehensive list of foundational models studied in this work is available at \url{https://github.com/awaisrauf/Awesome-CV-Foundational-Models}.
Multimodal Document Analytics for Banking Process Automation
Jul 21, 2023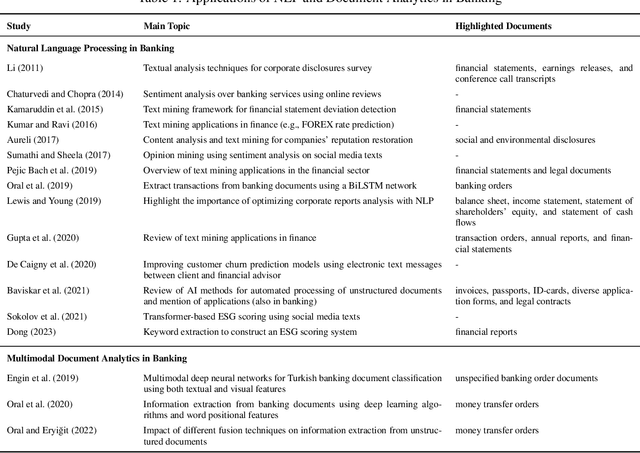
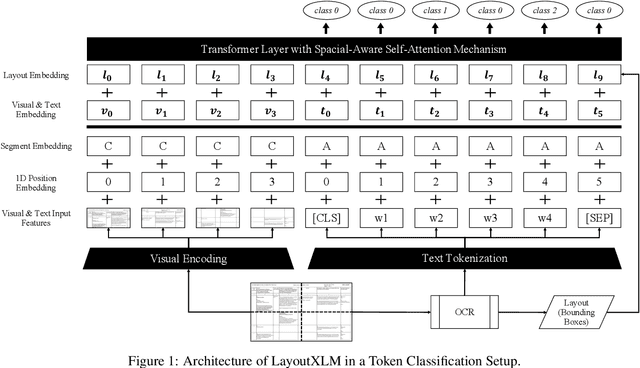
In response to growing FinTech competition and the need for improved operational efficiency, this research focuses on understanding the potential of advanced document analytics, particularly using multimodal models, in banking processes. We perform a comprehensive analysis of the diverse banking document landscape, highlighting the opportunities for efficiency gains through automation and advanced analytics techniques in the customer business. Building on the rapidly evolving field of natural language processing (NLP), we illustrate the potential of models such as LayoutXLM, a cross-lingual, multimodal, pre-trained model, for analyzing diverse documents in the banking sector. This model performs a text token classification on German company register extracts with an overall F1 score performance of around 80\%. Our empirical evidence confirms the critical role of layout information in improving model performance and further underscores the benefits of integrating image information. Interestingly, our study shows that over 75% F1 score can be achieved with only 30% of the training data, demonstrating the efficiency of LayoutXLM. Through addressing state-of-the-art document analysis frameworks, our study aims to enhance process efficiency and demonstrate the real-world applicability and benefits of multimodal models within banking.
HybridAugment++: Unified Frequency Spectra Perturbations for Model Robustness
Jul 21, 2023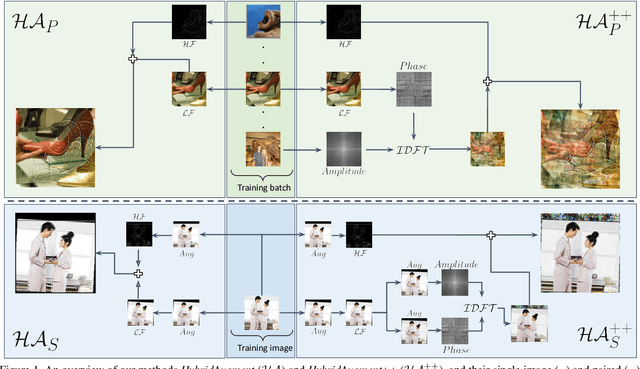
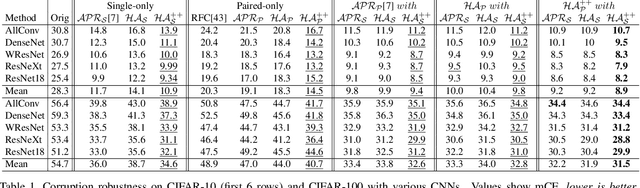
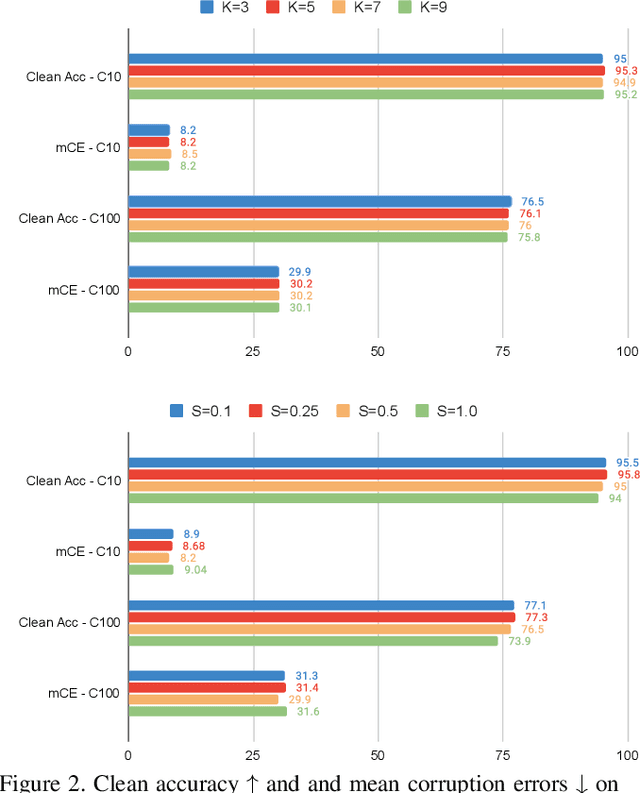
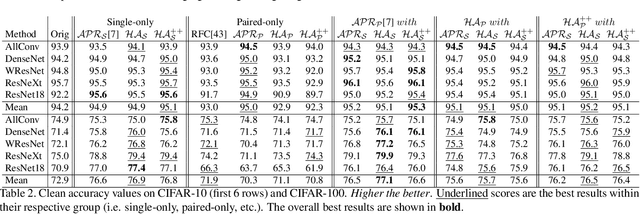
Convolutional Neural Networks (CNN) are known to exhibit poor generalization performance under distribution shifts. Their generalization have been studied extensively, and one line of work approaches the problem from a frequency-centric perspective. These studies highlight the fact that humans and CNNs might focus on different frequency components of an image. First, inspired by these observations, we propose a simple yet effective data augmentation method HybridAugment that reduces the reliance of CNNs on high-frequency components, and thus improves their robustness while keeping their clean accuracy high. Second, we propose HybridAugment++, which is a hierarchical augmentation method that attempts to unify various frequency-spectrum augmentations. HybridAugment++ builds on HybridAugment, and also reduces the reliance of CNNs on the amplitude component of images, and promotes phase information instead. This unification results in competitive to or better than state-of-the-art results on clean accuracy (CIFAR-10/100 and ImageNet), corruption benchmarks (ImageNet-C, CIFAR-10-C and CIFAR-100-C), adversarial robustness on CIFAR-10 and out-of-distribution detection on various datasets. HybridAugment and HybridAugment++ are implemented in a few lines of code, does not require extra data, ensemble models or additional networks.
Robust Visual Question Answering: Datasets, Methods, and Future Challenges
Jul 21, 2023
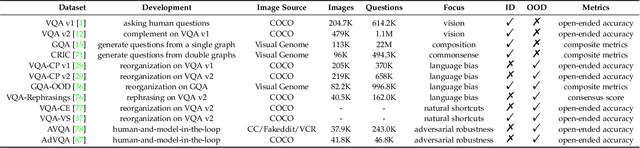
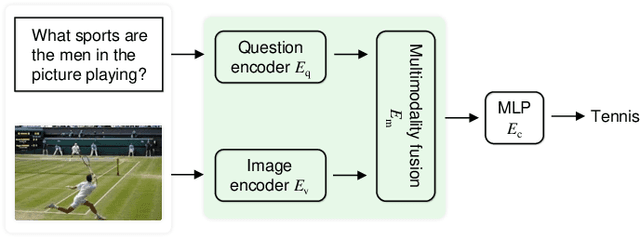
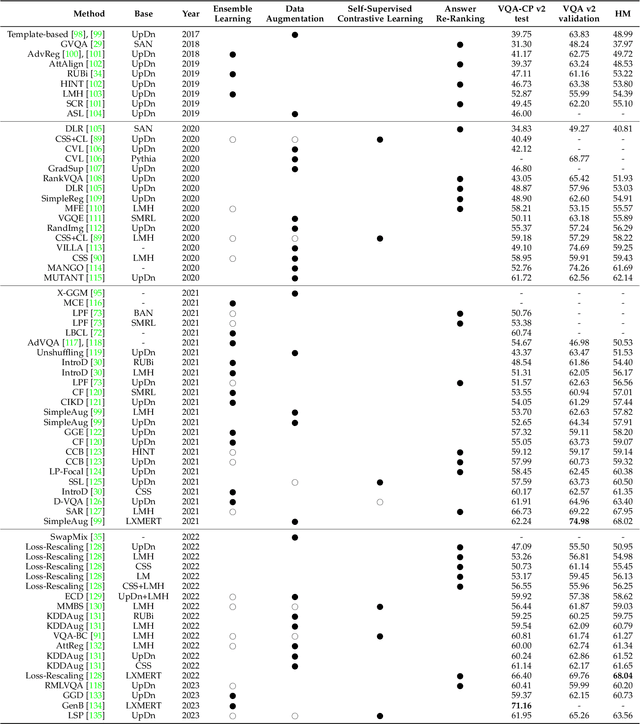
Visual question answering requires a system to provide an accurate natural language answer given an image and a natural language question. However, it is widely recognized that previous generic VQA methods often exhibit a tendency to memorize biases present in the training data rather than learning proper behaviors, such as grounding images before predicting answers. Therefore, these methods usually achieve high in-distribution but poor out-of-distribution performance. In recent years, various datasets and debiasing methods have been proposed to evaluate and enhance the VQA robustness, respectively. This paper provides the first comprehensive survey focused on this emerging fashion. Specifically, we first provide an overview of the development process of datasets from in-distribution and out-of-distribution perspectives. Then, we examine the evaluation metrics employed by these datasets. Thirdly, we propose a typology that presents the development process, similarities and differences, robustness comparison, and technical features of existing debiasing methods. Furthermore, we analyze and discuss the robustness of representative vision-and-language pre-training models on VQA. Finally, through a thorough review of the available literature and experimental analysis, we discuss the key areas for future research from various viewpoints.
ID-Pose: Sparse-view Camera Pose Estimation by Inverting Diffusion Models
Jun 29, 2023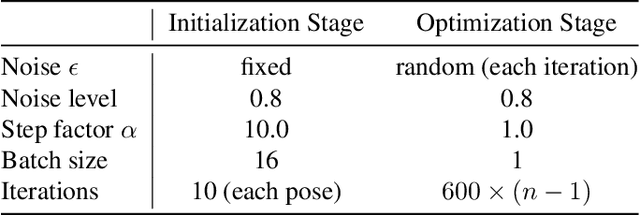
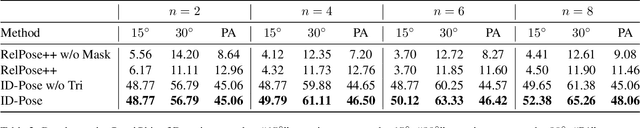
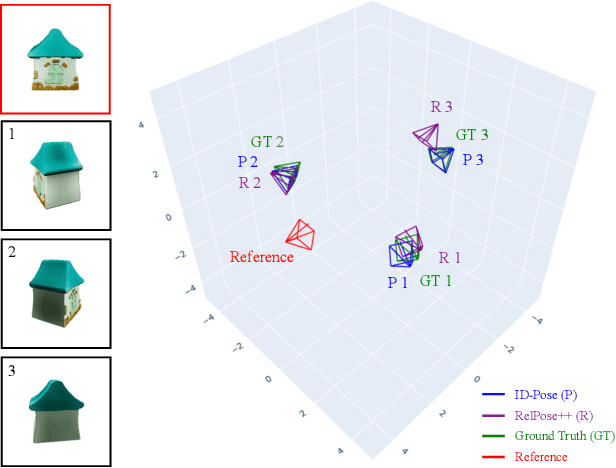
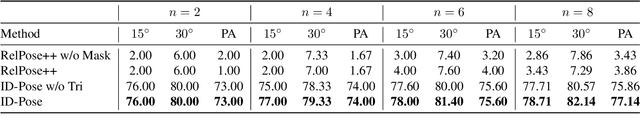
Given sparse views of an object, estimating their camera poses is a long-standing and intractable problem. We harness the pre-trained diffusion model of novel views conditioned on viewpoints (Zero-1-to-3). We present ID-Pose which inverses the denoising diffusion process to estimate the relative pose given two input images. ID-Pose adds a noise on one image, and predicts the noise conditioned on the other image and a decision variable for the pose. The prediction error is used as the objective to find the optimal pose with the gradient descent method. ID-Pose can handle more than two images and estimate each of the poses with multiple image pairs from triangular relationships. ID-Pose requires no training and generalizes to real-world images. We conduct experiments using high-quality real-scanned 3D objects, where ID-Pose significantly outperforms state-of-the-art methods.