 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCheapNVS: Real-Time On-Device Narrow-Baseline Novel View Synthesis
Jan 24, 2025



Single-view novel view synthesis (NVS) is a notorious problem due to its ill-posed nature, and often requires large, computationally expensive approaches to produce tangible results. In this paper, we propose CheapNVS: a fully end-to-end approach for narrow baseline single-view NVS based on a novel, efficient multiple encoder/decoder design trained in a multi-stage fashion. CheapNVS first approximates the laborious 3D image warping with lightweight learnable modules that are conditioned on the camera pose embeddings of the target view, and then performs inpainting on the occluded regions in parallel to achieve significant performance gains. Once trained on a subset of Open Images dataset, CheapNVS outperforms the state-of-the-art despite being 10 times faster and consuming 6% less memory. Furthermore, CheapNVS runs comfortably in real-time on mobile devices, reaching over 30 FPS on a Samsung Tab 9+.
Rethinking Encoder-Decoder Flow Through Shared Structures
Jan 24, 2025



Dense prediction tasks have enjoyed a growing complexity of encoder architectures, decoders, however, have remained largely the same. They rely on individual blocks decoding intermediate feature maps sequentially. We introduce banks, shared structures that are used by each decoding block to provide additional context in the decoding process. These structures, through applying them via resampling and feature fusion, improve performance on depth estimation for state-of-the-art transformer-based architectures on natural and synthetic images whilst training on large-scale datasets.
Trick-GS: A Balanced Bag of Tricks for Efficient Gaussian Splatting
Jan 24, 2025Gaussian splatting (GS) for 3D reconstruction has become quite popular due to their fast training, inference speeds and high quality reconstruction. However, GS-based reconstructions generally consist of millions of Gaussians, which makes them hard to use on computationally constrained devices such as smartphones. In this paper, we first propose a principled analysis of advances in efficient GS methods. Then, we propose Trick-GS, which is a careful combination of several strategies including (1) progressive training with resolution, noise and Gaussian scales, (2) learning to prune and mask primitives and SH bands by their significance, and (3) accelerated GS training framework. Trick-GS takes a large step towards resource-constrained GS, where faster run-time, smaller and faster-convergence of models is of paramount concern. Our results on three datasets show that Trick-GS achieves up to 2x faster training, 40x smaller disk size and 2x faster rendering speed compared to vanilla GS, while having comparable accuracy.
Finding Waldo: Towards Efficient Exploration of NeRF Scene Spaces
Mar 08, 2024



Neural Radiance Fields (NeRF) have quickly become the primary approach for 3D reconstruction and novel view synthesis in recent years due to their remarkable performance. Despite the huge interest in NeRF methods, a practical use case of NeRFs has largely been ignored; the exploration of the scene space modelled by a NeRF. In this paper, for the first time in the literature, we propose and formally define the scene exploration framework as the efficient discovery of NeRF model inputs (i.e. coordinates and viewing angles), using which one can render novel views that adhere to user-selected criteria. To remedy the lack of approaches addressing scene exploration, we first propose two baseline methods called Guided-Random Search (GRS) and Pose Interpolation-based Search (PIBS). We then cast scene exploration as an optimization problem, and propose the criteria-agnostic Evolution-Guided Pose Search (EGPS) for efficient exploration. We test all three approaches with various criteria (e.g. saliency maximization, image quality maximization, photo-composition quality improvement) and show that our EGPS performs more favourably than other baselines. We finally highlight key points and limitations, and outline directions for future research in scene exploration.
A Modular System for Enhanced Robustness of Multimedia Understanding Networks via Deep Parametric Estimation
Feb 29, 2024In multimedia understanding tasks, corrupted samples pose a critical challenge, because when fed to machine learning models they lead to performance degradation. In the past, three groups of approaches have been proposed to handle noisy data: i) enhancer and denoiser modules to improve the quality of the noisy data, ii) data augmentation approaches, and iii) domain adaptation strategies. All the aforementioned approaches come with drawbacks that limit their applicability; the first has high computational costs and requires pairs of clean-corrupted data for training, while the others only allow deployment of the same task/network they were trained on (\ie, when upstream and downstream task/network are the same). In this paper, we propose SyMPIE to solve these shortcomings. To this end, we design a small, modular, and efficient (just 2GFLOPs to process a Full HD image) system to enhance input data for robust downstream multimedia understanding with minimal computational cost. Our SyMPIE is pre-trained on an upstream task/network that should not match the downstream ones and does not need paired clean-corrupted samples. Our key insight is that most input corruptions found in real-world tasks can be modeled through global operations on color channels of images or spatial filters with small kernels. We validate our approach on multiple datasets and tasks, such as image classification (on ImageNetC, ImageNetC-Bar, VizWiz, and a newly proposed mixed corruption benchmark named ImageNetC-mixed) and semantic segmentation (on Cityscapes, ACDC, and DarkZurich) with consistent improvements of about 5\% relative accuracy gain across the board. The code of our approach and the new ImageNetC-mixed benchmark will be made available upon publication.
HybridAugment++: Unified Frequency Spectra Perturbations for Model Robustness
Jul 21, 2023



Convolutional Neural Networks (CNN) are known to exhibit poor generalization performance under distribution shifts. Their generalization have been studied extensively, and one line of work approaches the problem from a frequency-centric perspective. These studies highlight the fact that humans and CNNs might focus on different frequency components of an image. First, inspired by these observations, we propose a simple yet effective data augmentation method HybridAugment that reduces the reliance of CNNs on high-frequency components, and thus improves their robustness while keeping their clean accuracy high. Second, we propose HybridAugment++, which is a hierarchical augmentation method that attempts to unify various frequency-spectrum augmentations. HybridAugment++ builds on HybridAugment, and also reduces the reliance of CNNs on the amplitude component of images, and promotes phase information instead. This unification results in competitive to or better than state-of-the-art results on clean accuracy (CIFAR-10/100 and ImageNet), corruption benchmarks (ImageNet-C, CIFAR-10-C and CIFAR-100-C), adversarial robustness on CIFAR-10 and out-of-distribution detection on various datasets. HybridAugment and HybridAugment++ are implemented in a few lines of code, does not require extra data, ensemble models or additional networks.
TrickVOS: A Bag of Tricks for Video Object Segmentation
Jun 28, 2023



Space-time memory (STM) network methods have been dominant in semi-supervised video object segmentation (SVOS) due to their remarkable performance. In this work, we identify three key aspects where we can improve such methods; i) supervisory signal, ii) pretraining and iii) spatial awareness. We then propose TrickVOS; a generic, method-agnostic bag of tricks addressing each aspect with i) a structure-aware hybrid loss, ii) a simple decoder pretraining regime and iii) a cheap tracker that imposes spatial constraints in model predictions. Finally, we propose a lightweight network and show that when trained with TrickVOS, it achieves competitive results to state-of-the-art methods on DAVIS and YouTube benchmarks, while being one of the first STM-based SVOS methods that can run in real-time on a mobile device.
MobileVOS: Real-Time Video Object Segmentation Contrastive Learning meets Knowledge Distillation
Mar 14, 2023This paper tackles the problem of semi-supervised video object segmentation on resource-constrained devices, such as mobile phones. We formulate this problem as a distillation task, whereby we demonstrate that small space-time-memory networks with finite memory can achieve competitive results with state of the art, but at a fraction of the computational cost (32 milliseconds per frame on a Samsung Galaxy S22). Specifically, we provide a theoretically grounded framework that unifies knowledge distillation with supervised contrastive representation learning. These models are able to jointly benefit from both pixel-wise contrastive learning and distillation from a pre-trained teacher. We validate this loss by achieving competitive J&F to state of the art on both the standard DAVIS and YouTube benchmarks, despite running up to 5x faster, and with 32x fewer parameters.
Adaptive Mask-based Pyramid Network for Realistic Bokeh Rendering
Oct 28, 2022



Bokeh effect highlights an object (or any part of the image) while blurring the rest of the image, and creates a visually pleasant artistic effect. Due to the sensor-based limitations on mobile devices, machine learning (ML) based bokeh rendering has gained attention as a reliable alternative. In this paper, we focus on several improvements in ML-based bokeh rendering; i) on-device performance with high-resolution images, ii) ability to guide bokeh generation with user-editable masks and iii) ability to produce varying blur strength. To this end, we propose Adaptive Mask-based Pyramid Network (AMPN), which is formed of a Mask-Guided Bokeh Generator (MGBG) block and a Laplacian Pyramid Refinement (LPR) block. MGBG consists of two lightweight networks stacked to each other to generate the bokeh effect, and LPR refines and upsamples the output of MGBG to produce the high-resolution bokeh image. We achieve i) via our lightweight, mobile-friendly design choices, ii) via the stacked-network design of MGBG and the weakly-supervised mask prediction scheme and iii) via manually or automatically editing the intensity values of the mask that guide the bokeh generation. In addition to these features, our results show that AMPN produces competitive or better results compared to existing methods on the EBB! dataset, while being faster and smaller than the alternatives.
How Robust are Discriminatively Trained Zero-Shot Learning Models?
Jan 27, 2022
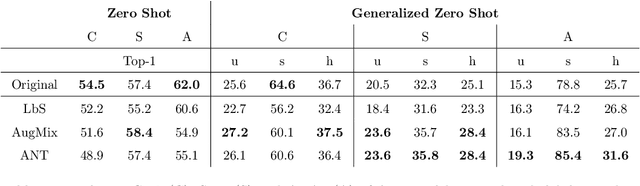
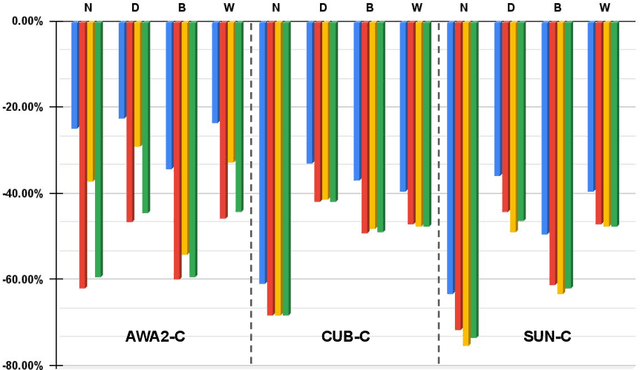
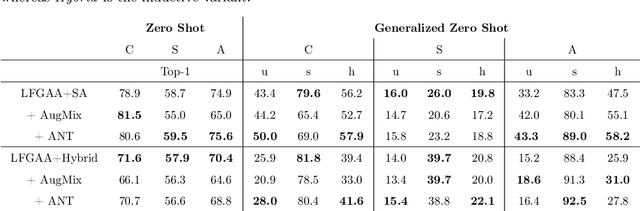
Data shift robustness has been primarily investigated from a fully supervised perspective, and robustness of zero-shot learning (ZSL) models have been largely neglected. In this paper, we present novel analyses on the robustness of discriminative ZSL to image corruptions. We subject several ZSL models to a large set of common corruptions and defenses. In order to realize the corruption analysis, we curate and release the first ZSL corruption robustness datasets SUN-C, CUB-C and AWA2-C. We analyse our results by taking into account the dataset characteristics, class imbalance, class transitions between seen and unseen classes and the discrepancies between ZSL and GZSL performances. Our results show that discriminative ZSL suffers from corruptions and this trend is further exacerbated by the severe class imbalance and model weakness inherent in ZSL methods. We then combine our findings with those based on adversarial attacks in ZSL, and highlight the different effects of corruptions and adversarial examples, such as the pseudo-robustness effect present under adversarial attacks. We also obtain new strong baselines for both models with the defense methods. Finally, our experiments show that although existing methods to improve robustness somewhat work for ZSL models, they do not produce a tangible effect.