 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Evaluating the Robustness of Text-to-image Diffusion Models against Real-world Attacks
Jun 16, 2023


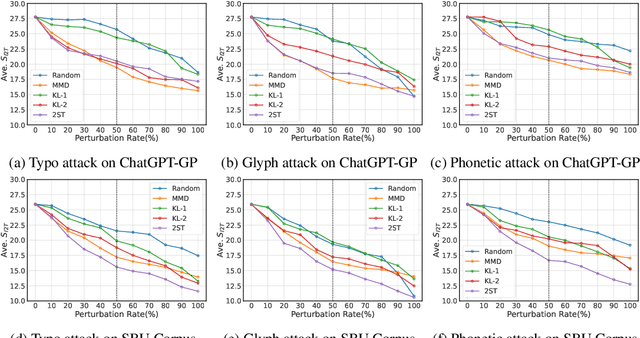
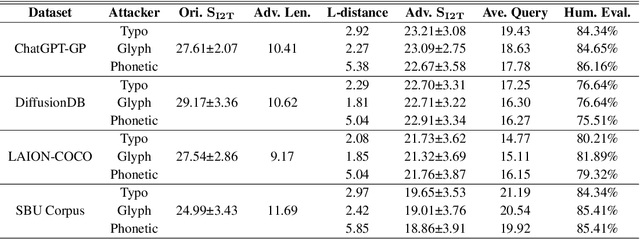
Text-to-image (T2I) diffusion models (DMs) have shown promise in generating high-quality images from textual descriptions. The real-world applications of these models require particular attention to their safety and fidelity, but this has not been sufficiently explored. One fundamental question is whether existing T2I DMs are robust against variations over input texts. To answer it, this work provides the first robustness evaluation of T2I DMs against real-world attacks. Unlike prior studies that focus on malicious attacks involving apocryphal alterations to the input texts, we consider an attack space spanned by realistic errors (e.g., typo, glyph, phonetic) that humans can make, to ensure semantic consistency. Given the inherent randomness of the generation process, we develop novel distribution-based attack objectives to mislead T2I DMs. We perform attacks in a black-box manner without any knowledge of the model. Extensive experiments demonstrate the effectiveness of our method for attacking popular T2I DMs and simultaneously reveal their non-trivial robustness issues. Moreover, we provide an in-depth analysis of our method to show that it is not designed to attack the text encoder in T2I DMs solely.
Mobile Image Restoration via Prior Quantization
May 10, 2023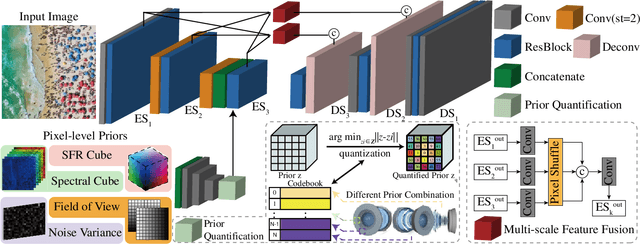
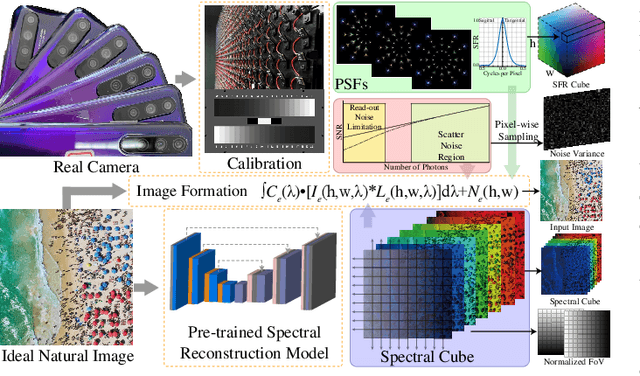

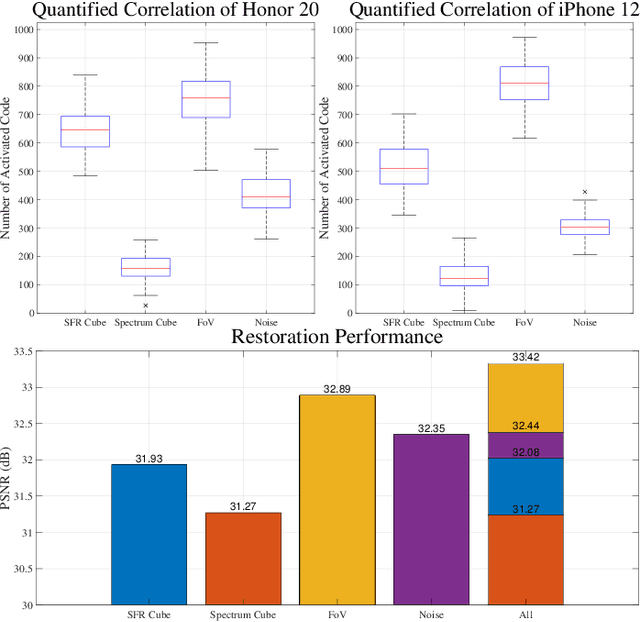
In digital images, the performance of optical aberration is a multivariate degradation, where the spectral of the scene, the lens imperfections, and the field of view together contribute to the results. Besides eliminating it at the hardware level, the post-processing system, which utilizes various prior information, is significant for correction. However, due to the content differences among priors, the pipeline that aligns these factors shows limited efficiency and unoptimized restoration. Here, we propose a prior quantization model to correct the optical aberrations in image processing systems. To integrate these messages, we encode various priors into a latent space and quantify them by the learnable codebooks. After quantization, the prior codes are fused with the image restoration branch to realize targeted optical aberration correction. Comprehensive experiments demonstrate the flexibility of the proposed method and validate its potential to accomplish targeted restoration for a specific camera. Furthermore, our model promises to analyze the correlation between the various priors and the optical aberration of devices, which is helpful for joint soft-hardware design.
StawGAN: Structural-Aware Generative Adversarial Networks for Infrared Image Translation
May 18, 2023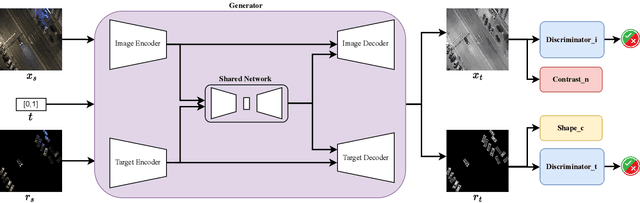

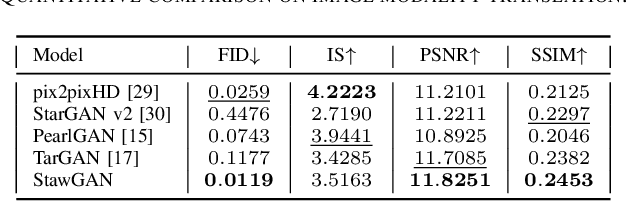
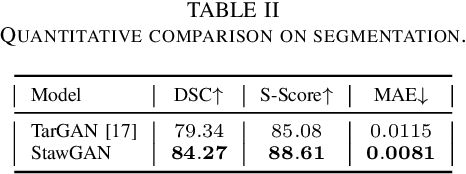
This paper addresses the problem of translating night-time thermal infrared images, which are the most adopted image modalities to analyze night-time scenes, to daytime color images (NTIT2DC), which provide better perceptions of objects. We introduce a novel model that focuses on enhancing the quality of the target generation without merely colorizing it. The proposed structural aware (StawGAN) enables the translation of better-shaped and high-definition objects in the target domain. We test our model on aerial images of the DroneVeichle dataset containing RGB-IR paired images. The proposed approach produces a more accurate translation with respect to other state-of-the-art image translation models. The source code is available at https://github.com/LuigiSigillo/StawGAN
Expert load matters: operating networks at high accuracy and low manual effort
Aug 09, 2023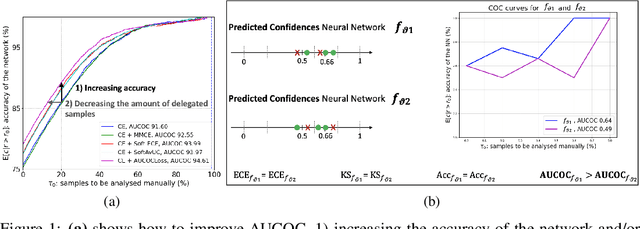
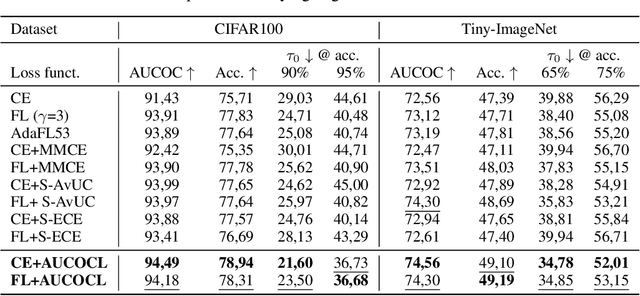
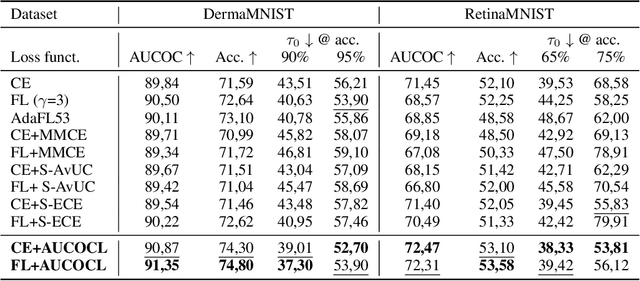
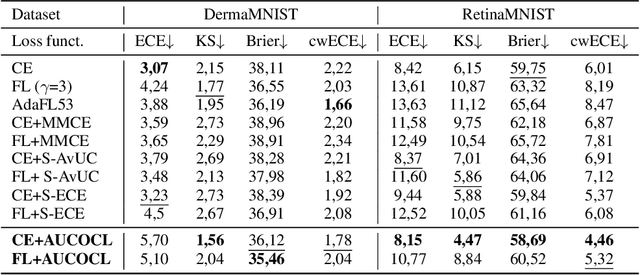
In human-AI collaboration systems for critical applications, in order to ensure minimal error, users should set an operating point based on model confidence to determine when the decision should be delegated to human experts. Samples for which model confidence is lower than the operating point would be manually analysed by experts to avoid mistakes. Such systems can become truly useful only if they consider two aspects: models should be confident only for samples for which they are accurate, and the number of samples delegated to experts should be minimized. The latter aspect is especially crucial for applications where available expert time is limited and expensive, such as healthcare. The trade-off between the model accuracy and the number of samples delegated to experts can be represented by a curve that is similar to an ROC curve, which we refer to as confidence operating characteristic (COC) curve. In this paper, we argue that deep neural networks should be trained by taking into account both accuracy and expert load and, to that end, propose a new complementary loss function for classification that maximizes the area under this COC curve. This promotes simultaneously the increase in network accuracy and the reduction in number of samples delegated to humans. We perform experiments on multiple computer vision and medical image datasets for classification. Our results demonstrate that the proposed loss improves classification accuracy and delegates less number of decisions to experts, achieves better out-of-distribution samples detection and on par calibration performance compared to existing loss functions.
Hierarchical Diffusion Autoencoders and Disentangled Image Manipulation
Apr 25, 2023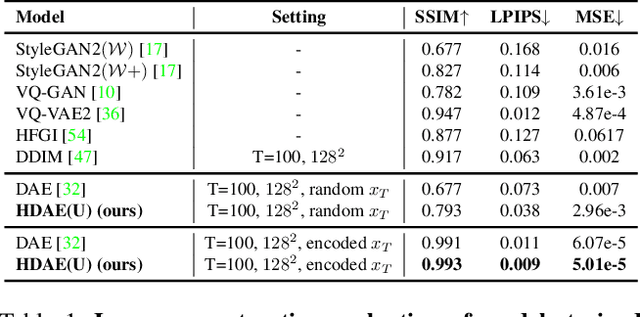
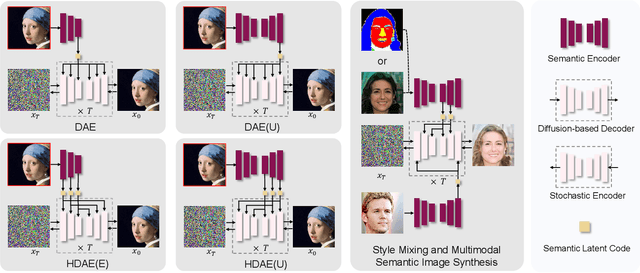

Diffusion models have attained impressive visual quality for image synthesis. However, how to interpret and manipulate the latent space of diffusion models has not been extensively explored. Prior work diffusion autoencoders encode the semantic representations into a semantic latent code, which fails to reflect the rich information of details and the intrinsic feature hierarchy. To mitigate those limitations, we propose Hierarchical Diffusion Autoencoders (HDAE) that exploit the fine-grained-to-abstract and lowlevel-to-high-level feature hierarchy for the latent space of diffusion models. The hierarchical latent space of HDAE inherently encodes different abstract levels of semantics and provides more comprehensive semantic representations. In addition, we propose a truncated-feature-based approach for disentangled image manipulation. We demonstrate the effectiveness of our proposed approach with extensive experiments and applications on image reconstruction, style mixing, controllable interpolation, detail-preserving and disentangled image manipulation, and multi-modal semantic image synthesis.
Controllable Image Generation via Collage Representations
Apr 26, 2023


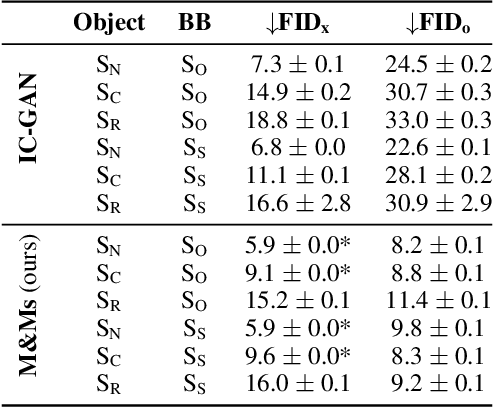
Recent advances in conditional generative image models have enabled impressive results. On the one hand, text-based conditional models have achieved remarkable generation quality, by leveraging large-scale datasets of image-text pairs. To enable fine-grained controllability, however, text-based models require long prompts, whose details may be ignored by the model. On the other hand, layout-based conditional models have also witnessed significant advances. These models rely on bounding boxes or segmentation maps for precise spatial conditioning in combination with coarse semantic labels. The semantic labels, however, cannot be used to express detailed appearance characteristics. In this paper, we approach fine-grained scene controllability through image collages which allow a rich visual description of the desired scene as well as the appearance and location of the objects therein, without the need of class nor attribute labels. We introduce "mixing and matching scenes" (M&Ms), an approach that consists of an adversarially trained generative image model which is conditioned on appearance features and spatial positions of the different elements in a collage, and integrates these into a coherent image. We train our model on the OpenImages (OI) dataset and evaluate it on collages derived from OI and MS-COCO datasets. Our experiments on the OI dataset show that M&Ms outperforms baselines in terms of fine-grained scene controllability while being very competitive in terms of image quality and sample diversity. On the MS-COCO dataset, we highlight the generalization ability of our model by outperforming DALL-E in terms of the zero-shot FID metric, despite using two magnitudes fewer parameters and data. Collage based generative models have the potential to advance content creation in an efficient and effective way as they are intuitive to use and yield high quality generations.
Cross-supervised Dual Classifiers for Semi-supervised Medical Image Segmentation
May 25, 2023
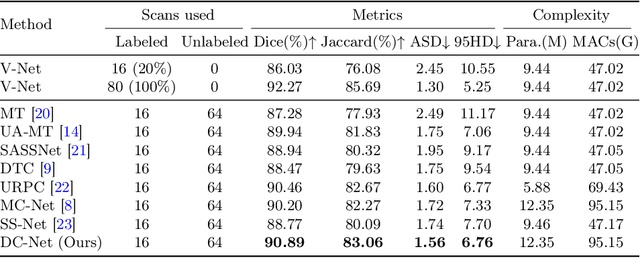
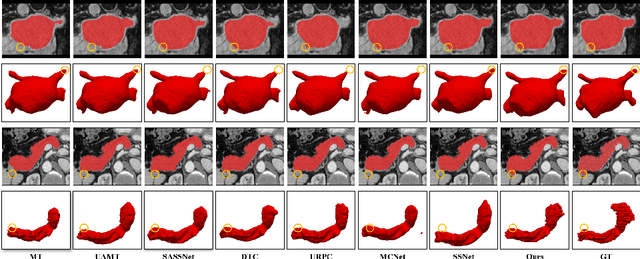
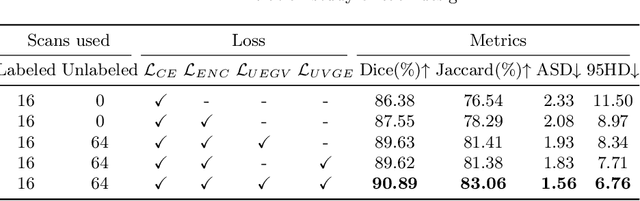
Semi-supervised medical image segmentation offers a promising solution for large-scale medical image analysis by significantly reducing the annotation burden while achieving comparable performance. Employing this method exhibits a high degree of potential for optimizing the segmentation process and increasing its feasibility in clinical settings during translational investigations. Recently, cross-supervised training based on different co-training sub-networks has become a standard paradigm for this task. Still, the critical issues of sub-network disagreement and label-noise suppression require further attention and progress in cross-supervised training. This paper proposes a cross-supervised learning framework based on dual classifiers (DC-Net), including an evidential classifier and a vanilla classifier. The two classifiers exhibit complementary characteristics, enabling them to handle disagreement effectively and generate more robust and accurate pseudo-labels for unlabeled data. We also incorporate the uncertainty estimation from the evidential classifier into cross-supervised training to alleviate the negative effect of the error supervision signal. The extensive experiments on LA and Pancreas-CT dataset illustrate that DC-Net outperforms other state-of-the-art methods for semi-supervised segmentation. The code will be released soon.
Enhancing Cell Tracking with a Time-Symmetric Deep Learning Approach
Aug 04, 2023
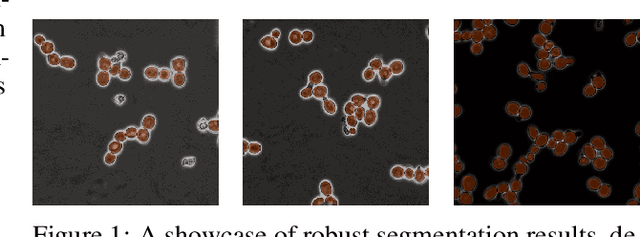
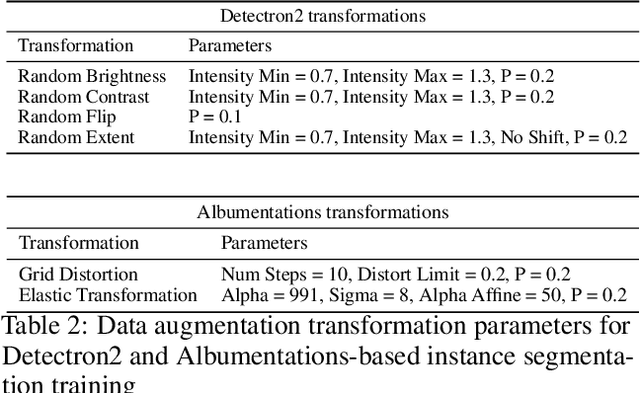

The accurate tracking of live cells using video microscopy recordings remains a challenging task for popular state-of-the-art image processing based object tracking methods. In recent years, several existing and new applications have attempted to integrate deep-learning based frameworks for this task, but most of them still heavily rely on consecutive frame based tracking embedded in their architecture or other premises that hinder generalized learning. To address this issue, we aimed to develop a new deep-learning based tracking method that relies solely on the assumption that cells can be tracked based on their spatio-temporal neighborhood, without restricting it to consecutive frames. The proposed method has the additional benefit that the motion patterns of the cells can be learned completely by the predictor without any prior assumptions, and it has the potential to handle a large number of video frames with heavy artifacts. The efficacy of the proposed method is demonstrated through multiple biologically motivated validation strategies and compared against several state-of-the-art cell tracking methods.
Model-free Grasping with Multi-Suction Cup Grippers for Robotic Bin Picking
Jul 31, 2023This paper presents a novel method for model-free prediction of grasp poses for suction grippers with multiple suction cups. Our approach is agnostic to the design of the gripper and does not require gripper-specific training data. In particular, we propose a two-step approach, where first, a neural network predicts pixel-wise grasp quality for an input image to indicate areas that are generally graspable. Second, an optimization step determines the optimal gripper selection and corresponding grasp poses based on configured gripper layouts and activation schemes. In addition, we introduce a method for automated labeling for supervised training of the grasp quality network. Experimental evaluations on a real-world industrial application with bin picking scenes of varying difficulty demonstrate the effectiveness of our method.
Unsupervised Camouflaged Object Segmentation as Domain Adaptation
Aug 08, 2023Deep learning for unsupervised image segmentation remains challenging due to the absence of human labels. The common idea is to train a segmentation head, with the supervision of pixel-wise pseudo-labels generated based on the representation of self-supervised backbones. By doing so, the model performance depends much on the distance between the distributions of target datasets and the pre-training dataset (e.g., ImageNet). In this work, we investigate a new task, namely unsupervised camouflaged object segmentation (UCOS), where the target objects own a common rarely-seen attribute, i.e., camouflage. Unsurprisingly, we find that the state-of-the-art unsupervised models struggle in adapting UCOS, due to the domain gap between the properties of generic and camouflaged objects. To this end, we formulate the UCOS as a source-free unsupervised domain adaptation task (UCOS-DA), where both source labels and target labels are absent during the whole model training process. Specifically, we define a source model consisting of self-supervised vision transformers pre-trained on ImageNet. On the other hand, the target domain includes a simple linear layer (i.e., our target model) and unlabeled camouflaged objects. We then design a pipeline for foreground-background-contrastive self-adversarial domain adaptation, to achieve robust UCOS. As a result, our baseline model achieves superior segmentation performance when compared with competing unsupervised models on the UCOS benchmark, with the training set which's scale is only one tenth of the supervised COS counterpart.