 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
CNOS: A Strong Baseline for CAD-based Novel Object Segmentation
Aug 03, 2023
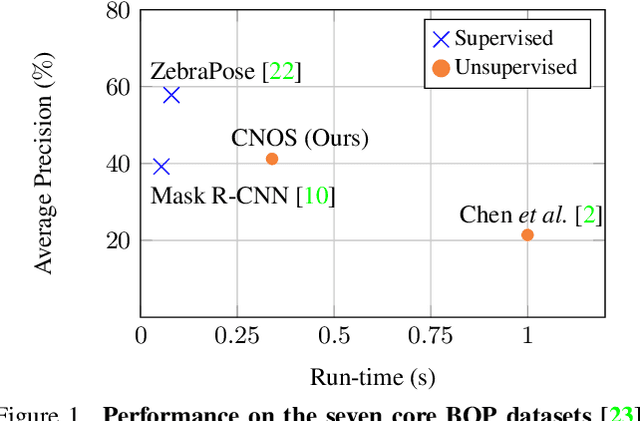
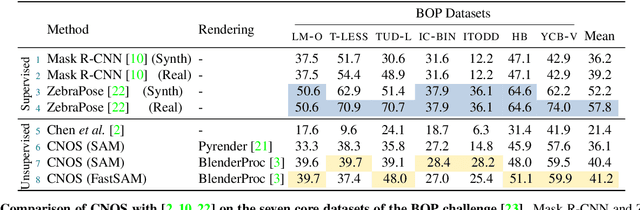
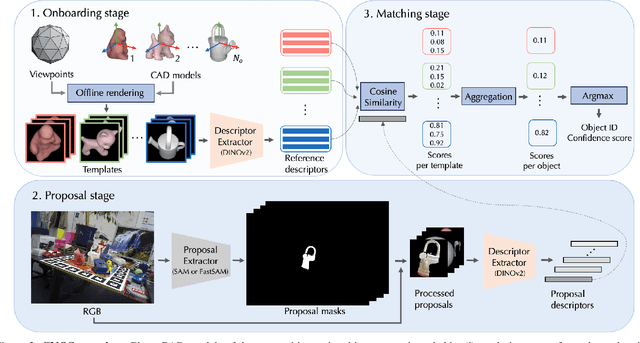

We propose a simple three-stage approach to segment unseen objects in RGB images using their CAD models. Leveraging recent powerful foundation models, DINOv2 and Segment Anything, we create descriptors and generate proposals, including binary masks for a given input RGB image. By matching proposals with reference descriptors created from CAD models, we achieve precise object ID assignment along with modal masks. We experimentally demonstrate that our method achieves state-of-the-art results in CAD-based novel object segmentation, surpassing existing approaches on the seven core datasets of the BOP challenge by 19.8% AP using the same BOP evaluation protocol. Our source code is available at https://github.com/nv-nguyen/cnos.
MultiFusion: Fusing Pre-Trained Models for Multi-Lingual, Multi-Modal Image Generation
May 24, 2023



The recent popularity of text-to-image diffusion models (DM) can largely be attributed to the intuitive interface they provide to users. The intended generation can be expressed in natural language, with the model producing faithful interpretations of text prompts. However, expressing complex or nuanced ideas in text alone can be difficult. To ease image generation, we propose MultiFusion that allows one to express complex and nuanced concepts with arbitrarily interleaved inputs of multiple modalities and languages. MutliFusion leverages pre-trained models and aligns them for integration into a cohesive system, thereby avoiding the need for extensive training from scratch. Our experimental results demonstrate the efficient transfer of capabilities from individual modules to the downstream model. Specifically, the fusion of all independent components allows the image generation module to utilize multilingual, interleaved multimodal inputs despite being trained solely on monomodal data in a single language.
Collaborative Auto-encoding for Blind Image Quality Assessment
May 24, 2023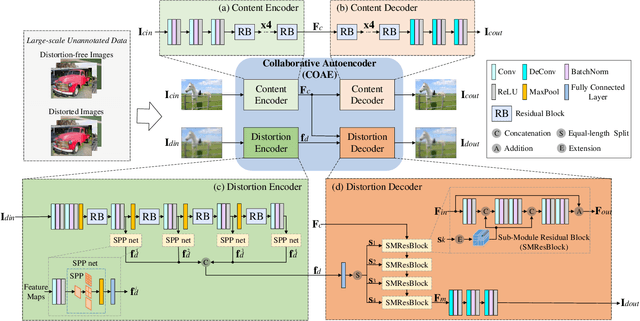
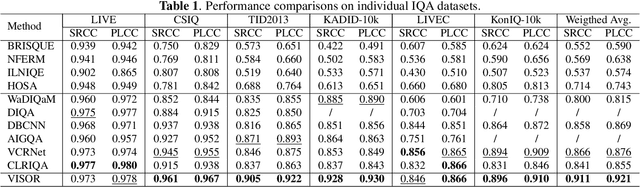
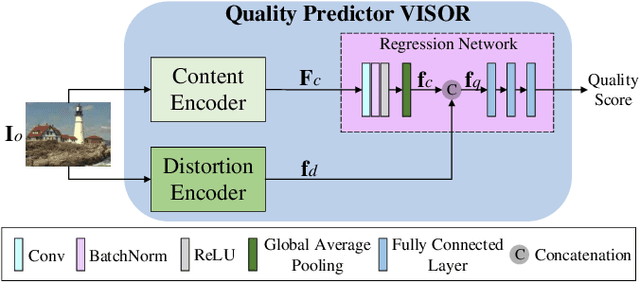
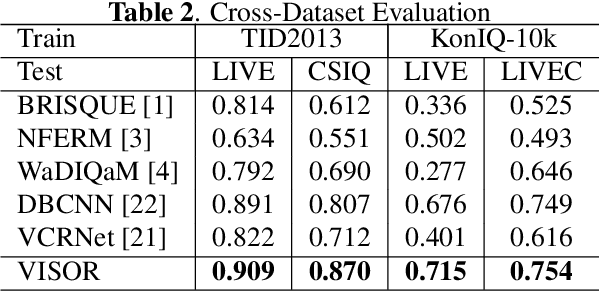
Blind image quality assessment (BIQA) is a challenging problem with important real-world applications. Recent efforts attempting to exploit powerful representations by deep neural networks (DNN) are hindered by the lack of subjectively annotated data. This paper presents a novel BIQA method which overcomes this fundamental obstacle. Specifically, we design a pair of collaborative autoencoders (COAE) consisting of a content autoencoder (CAE) and a distortion autoencoder (DAE) that work together to extract content and distortion representations, which are shown to be highly descriptive of image quality. While the CAE follows a standard codec procedure, we introduce the CAE-encoded feature as an extra input to the DAE's decoder for reconstructing distorted images, thus effectively forcing DAE's encoder to extract distortion representations. The self-supervised learning framework allows the COAE including two feature extractors to be trained by almost unlimited amount of data, thus leaving limited samples with annotations to finetune a BIQA model. We will show that the proposed BIQA method achieves state-of-the-art performance and has superior generalization capability over other learning based models. The codes are available at: https://github.com/Macro-Zhou/NRIQA-VISOR/.
Pyramid Diffusion Models For Low-light Image Enhancement
May 17, 2023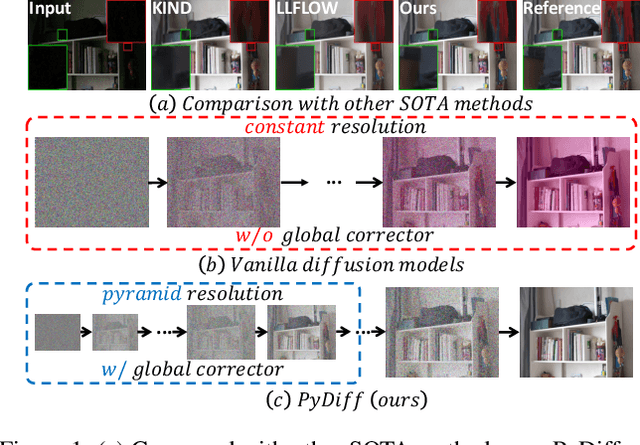
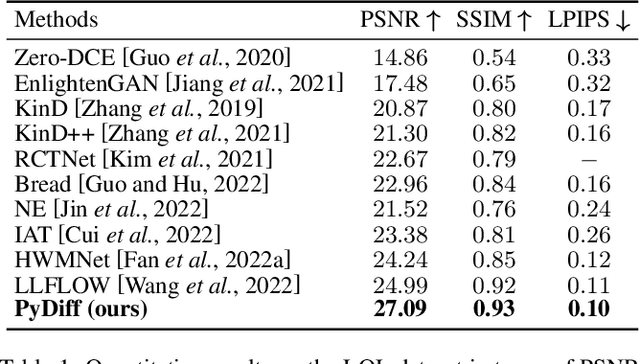
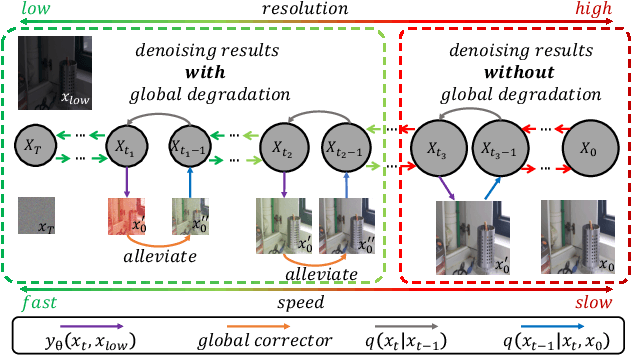
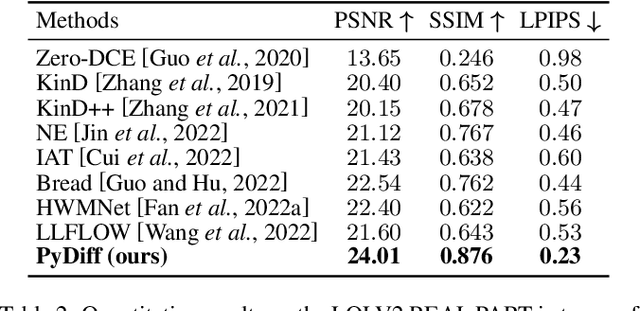
Recovering noise-covered details from low-light images is challenging, and the results given by previous methods leave room for improvement. Recent diffusion models show realistic and detailed image generation through a sequence of denoising refinements and motivate us to introduce them to low-light image enhancement for recovering realistic details. However, we found two problems when doing this, i.e., 1) diffusion models keep constant resolution in one reverse process, which limits the speed; 2) diffusion models sometimes result in global degradation (e.g., RGB shift). To address the above problems, this paper proposes a Pyramid Diffusion model (PyDiff) for low-light image enhancement. PyDiff uses a novel pyramid diffusion method to perform sampling in a pyramid resolution style (i.e., progressively increasing resolution in one reverse process). Pyramid diffusion makes PyDiff much faster than vanilla diffusion models and introduces no performance degradation. Furthermore, PyDiff uses a global corrector to alleviate the global degradation that may occur in the reverse process, significantly improving the performance and making the training of diffusion models easier with little additional computational consumption. Extensive experiments on popular benchmarks show that PyDiff achieves superior performance and efficiency. Moreover, PyDiff can generalize well to unseen noise and illumination distributions.
On the Effectiveness of Spectral Discriminators for Perceptual Quality Improvement
Jul 22, 2023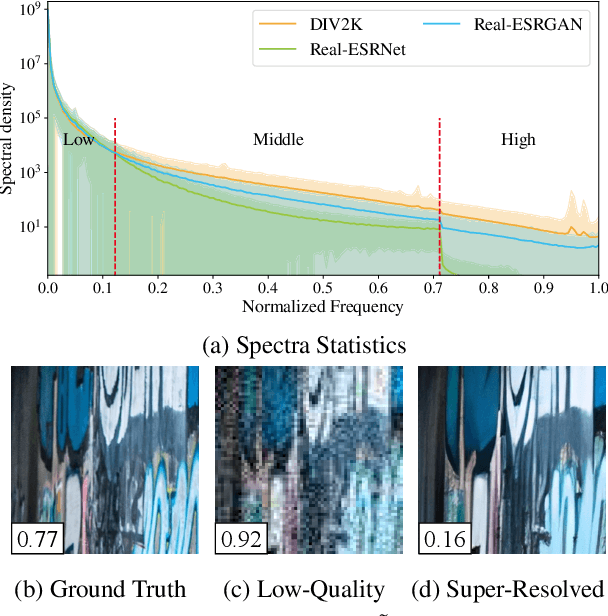

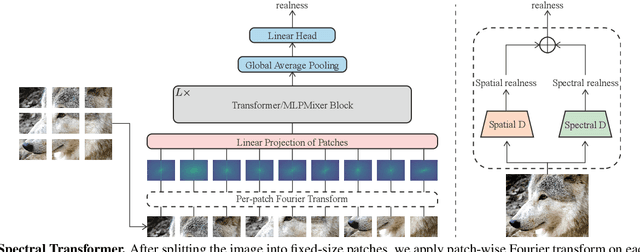
Several recent studies advocate the use of spectral discriminators, which evaluate the Fourier spectra of images for generative modeling. However, the effectiveness of the spectral discriminators is not well interpreted yet. We tackle this issue by examining the spectral discriminators in the context of perceptual image super-resolution (i.e., GAN-based SR), as SR image quality is susceptible to spectral changes. Our analyses reveal that the spectral discriminator indeed performs better than the ordinary (a.k.a. spatial) discriminator in identifying the differences in the high-frequency range; however, the spatial discriminator holds an advantage in the low-frequency range. Thus, we suggest that the spectral and spatial discriminators shall be used simultaneously. Moreover, we improve the spectral discriminators by first calculating the patch-wise Fourier spectrum and then aggregating the spectra by Transformer. We verify the effectiveness of the proposed method twofold. On the one hand, thanks to the additional spectral discriminator, our obtained SR images have their spectra better aligned to those of the real images, which leads to a better PD tradeoff. On the other hand, our ensembled discriminator predicts the perceptual quality more accurately, as evidenced in the no-reference image quality assessment task.
Deep Robust Multi-Robot Re-localisation in Natural Environments
Jul 26, 2023

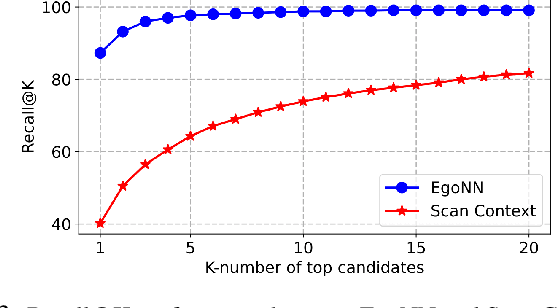
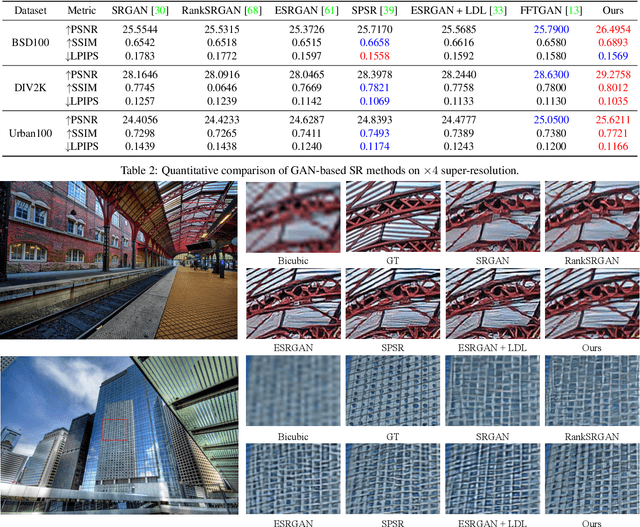
The success of re-localisation has crucial implications for the practical deployment of robots operating within a prior map or relative to one another in real-world scenarios. Using single-modality, place recognition and localisation can be compromised in challenging environments such as forests. To address this, we propose a strategy to prevent lidar-based re-localisation failure using lidar-image cross-modality. Our solution relies on self-supervised 2D-3D feature matching to predict alignment and misalignment. Leveraging a deep network for lidar feature extraction and relative pose estimation between point clouds, we train a model to evaluate the estimated transformation. A model predicting the presence of misalignment is learned by analysing image-lidar similarity in the embedding space and the geometric constraints available within the region seen in both modalities in Euclidean space. Experimental results using real datasets (offline and online modes) demonstrate the effectiveness of the proposed pipeline for robust re-localisation in unstructured, natural environments.
Centroid-aware feature recalibration for cancer grading in pathology images
Jul 26, 2023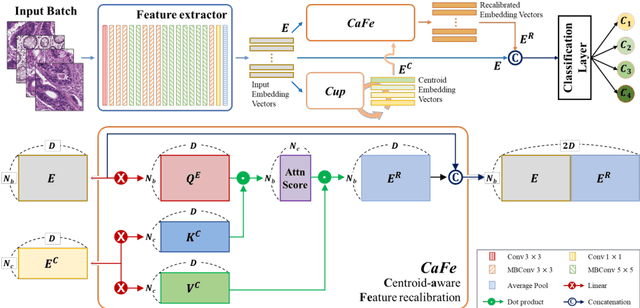
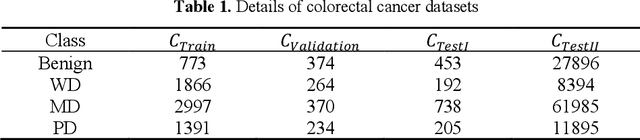
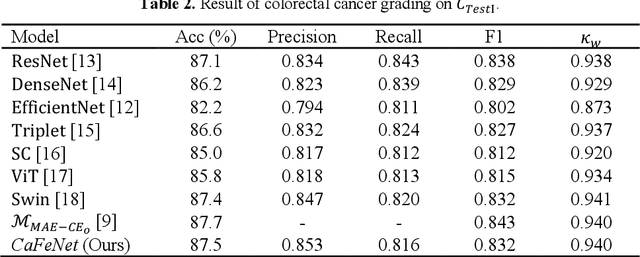
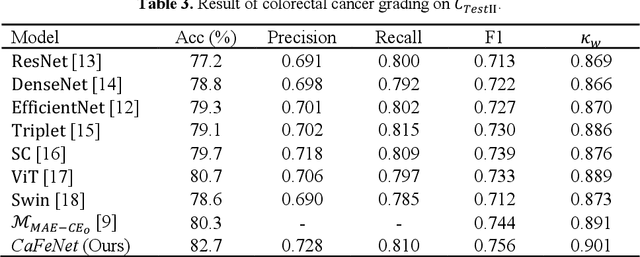
Cancer grading is an essential task in pathology. The recent developments of artificial neural networks in computational pathology have shown that these methods hold great potential for improving the accuracy and quality of cancer diagnosis. However, the issues with the robustness and reliability of such methods have not been fully resolved yet. Herein, we propose a centroid-aware feature recalibration network that can conduct cancer grading in an accurate and robust manner. The proposed network maps an input pathology image into an embedding space and adjusts it by using centroids embedding vectors of different cancer grades via attention mechanism. Equipped with the recalibrated embedding vector, the proposed network classifiers the input pathology image into a pertinent class label, i.e., cancer grade. We evaluate the proposed network using colorectal cancer datasets that were collected under different environments. The experimental results confirm that the proposed network is able to conduct cancer grading in pathology images with high accuracy regardless of the environmental changes in the datasets.
SA-BEV: Generating Semantic-Aware Bird's-Eye-View Feature for Multi-view 3D Object Detection
Jul 21, 2023
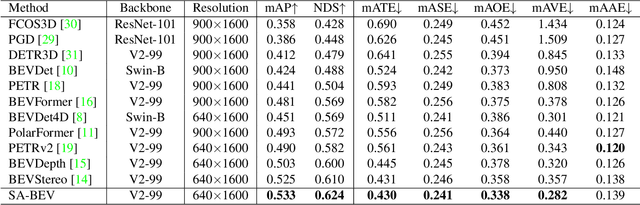
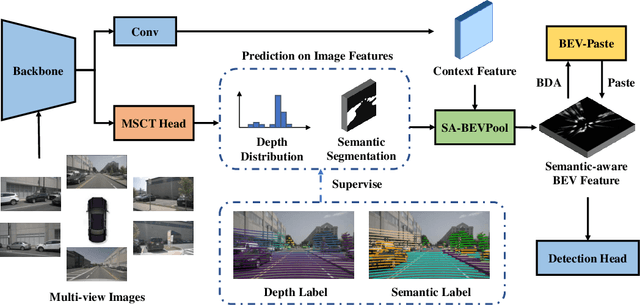
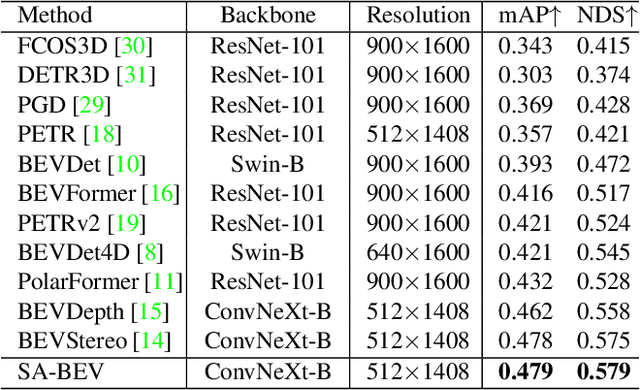
Recently, the pure camera-based Bird's-Eye-View (BEV) perception provides a feasible solution for economical autonomous driving. However, the existing BEV-based multi-view 3D detectors generally transform all image features into BEV features, without considering the problem that the large proportion of background information may submerge the object information. In this paper, we propose Semantic-Aware BEV Pooling (SA-BEVPool), which can filter out background information according to the semantic segmentation of image features and transform image features into semantic-aware BEV features. Accordingly, we propose BEV-Paste, an effective data augmentation strategy that closely matches with semantic-aware BEV feature. In addition, we design a Multi-Scale Cross-Task (MSCT) head, which combines task-specific and cross-task information to predict depth distribution and semantic segmentation more accurately, further improving the quality of semantic-aware BEV feature. Finally, we integrate the above modules into a novel multi-view 3D object detection framework, namely SA-BEV. Experiments on nuScenes show that SA-BEV achieves state-of-the-art performance. Code has been available at https://github.com/mengtan00/SA-BEV.git.
SACReg: Scene-Agnostic Coordinate Regression for Visual Localization
Jul 21, 2023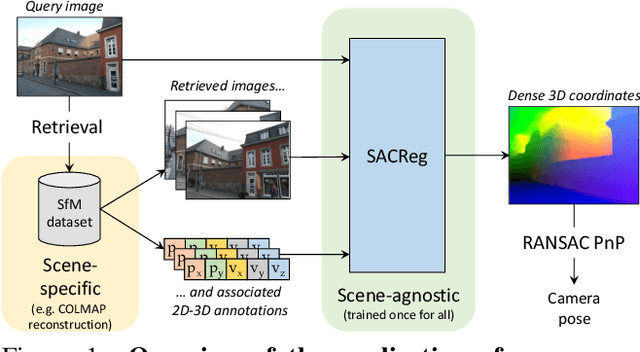
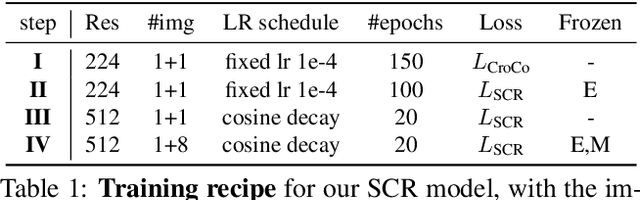
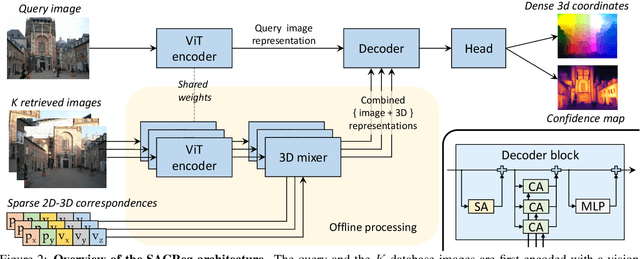
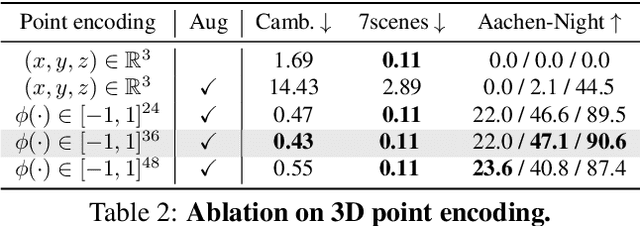
Scene coordinates regression (SCR), i.e., predicting 3D coordinates for every pixel of a given image, has recently shown promising potential. However, existing methods remain mostly scene-specific or limited to small scenes and thus hardly scale to realistic datasets. In this paper, we propose a new paradigm where a single generic SCR model is trained once to be then deployed to new test scenes, regardless of their scale and without further finetuning. For a given query image, it collects inputs from off-the-shelf image retrieval techniques and Structure-from-Motion databases: a list of relevant database images with sparse pointwise 2D-3D annotations. The model is based on the transformer architecture and can take a variable number of images and sparse 2D-3D annotations as input. It is trained on a few diverse datasets and significantly outperforms other scene regression approaches on several benchmarks, including scene-specific models, for visual localization. In particular, we set a new state of the art on the Cambridge localization benchmark, even outperforming feature-matching-based approaches.
FLIGHT Mode On: A Feather-Light Network for Low-Light Image Enhancement
May 18, 2023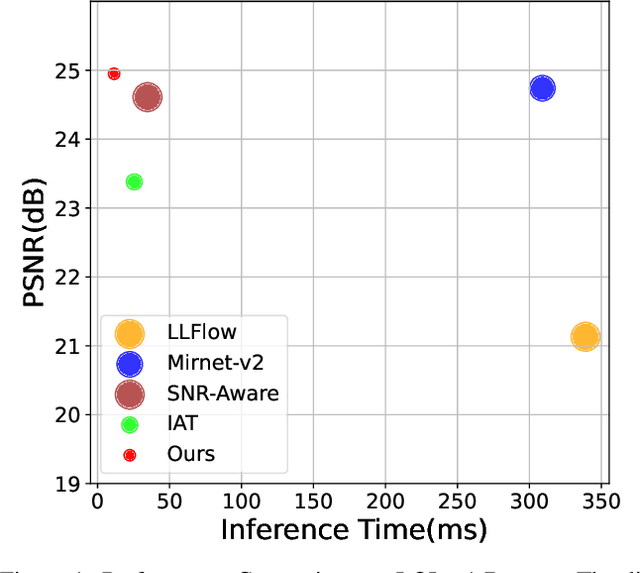
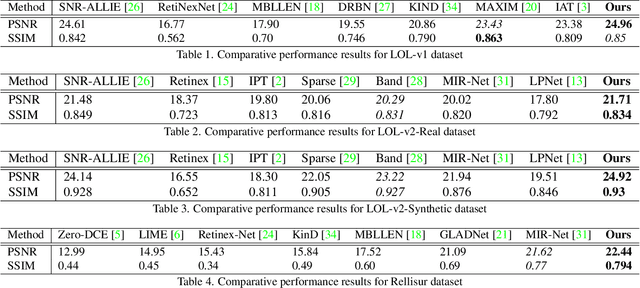
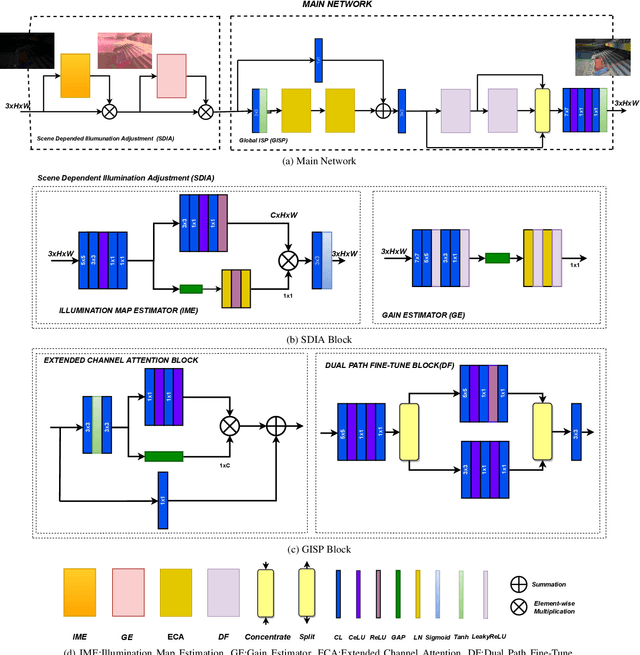

Low-light image enhancement (LLIE) is an ill-posed inverse problem due to the lack of knowledge of the desired image which is obtained under ideal illumination conditions. Low-light conditions give rise to two main issues: a suppressed image histogram and inconsistent relative color distributions with low signal-to-noise ratio. In order to address these problems, we propose a novel approach named FLIGHT-Net using a sequence of neural architecture blocks. The first block regulates illumination conditions through pixel-wise scene dependent illumination adjustment. The output image is produced in the output of the second block, which includes channel attention and denoising sub-blocks. Our highly efficient neural network architecture delivers state-of-the-art performance with only 25K parameters. The method's code, pretrained models and resulting images will be publicly available.