 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHOTFLoc++: End-to-End Hierarchical LiDAR Place Recognition, Re-Ranking, and 6-DoF Metric Localisation in Forests
Nov 12, 2025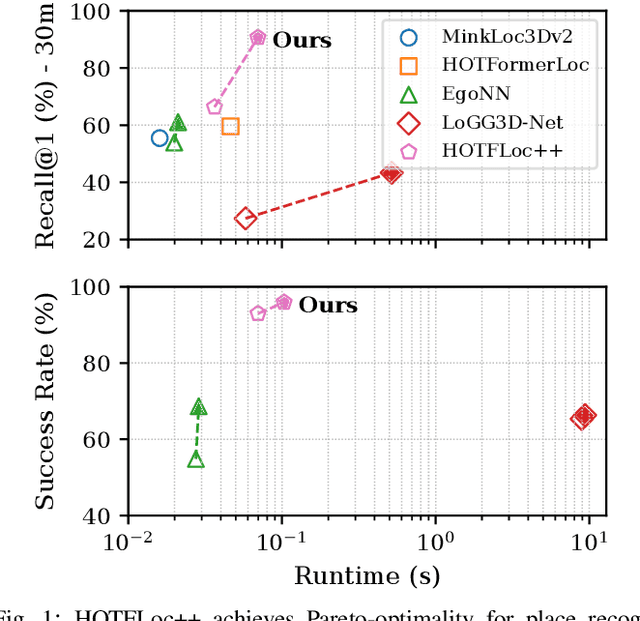
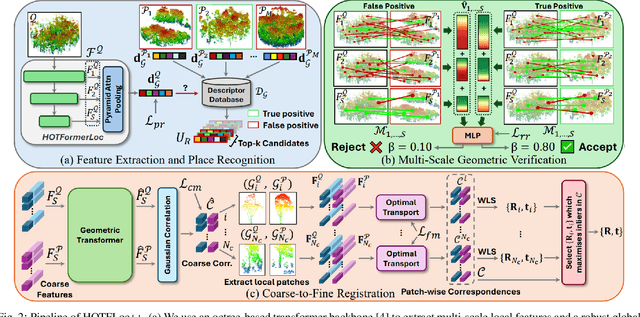
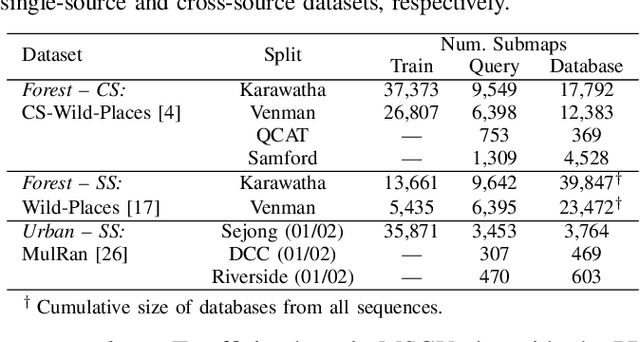

This article presents HOTFLoc++, an end-to-end framework for LiDAR place recognition, re-ranking, and 6-DoF metric localisation in forests. Leveraging an octree-based transformer, our approach extracts hierarchical local descriptors at multiple granularities to increase robustness to clutter, self-similarity, and viewpoint changes in challenging scenarios, including ground-to-ground and ground-to-aerial in forest and urban environments. We propose a learnable multi-scale geometric verification module to reduce re-ranking failures in the presence of degraded single-scale correspondences. Our coarse-to-fine registration approach achieves comparable or lower localisation errors to baselines, with runtime improvements of two orders of magnitude over RANSAC for dense point clouds. Experimental results on public datasets show the superiority of our approach compared to state-of-the-art methods, achieving an average Recall@1 of 90.7% on CS-Wild-Places: an improvement of 29.6 percentage points over baselines, while maintaining high performance on single-source benchmarks with an average Recall@1 of 91.7% and 96.0% on Wild-Places and MulRan, respectively. Our method achieves under 2 m and 5 degrees error for 97.2% of 6-DoF registration attempts, with our multi-scale re-ranking module reducing localisation errors by ~2$\times$ on average. The code will be available upon acceptance.
HOTFormerLoc: Hierarchical Octree Transformer for Versatile Lidar Place Recognition Across Ground and Aerial Views
Mar 11, 2025



We present HOTFormerLoc, a novel and versatile Hierarchical Octree-based Transformer, for large-scale 3D place recognition in both ground-to-ground and ground-to-aerial scenarios across urban and forest environments. We propose an octree-based multi-scale attention mechanism that captures spatial and semantic features across granularities. To address the variable density of point distributions from spinning lidar, we present cylindrical octree attention windows to reflect the underlying distribution during attention. We introduce relay tokens to enable efficient global-local interactions and multi-scale representation learning at reduced computational cost. Our pyramid attentional pooling then synthesises a robust global descriptor for end-to-end place recognition in challenging environments. In addition, we introduce CS-Wild-Places, a novel 3D cross-source dataset featuring point cloud data from aerial and ground lidar scans captured in dense forests. Point clouds in CS-Wild-Places contain representational gaps and distinctive attributes such as varying point densities and noise patterns, making it a challenging benchmark for cross-view localisation in the wild. HOTFormerLoc achieves a top-1 average recall improvement of 5.5% - 11.5% on the CS-Wild-Places benchmark. Furthermore, it consistently outperforms SOTA 3D place recognition methods, with an average performance gain of 5.8% on well-established urban and forest datasets. The code and CS-Wild-Places benchmark is available at https://csiro-robotics.github.io/HOTFormerLoc .
Online 6DoF Pose Estimation in Forests using Cross-View Factor Graph Optimisation and Deep Learned Re-localisation
Sep 25, 2024



This paper presents a novel approach for robust global localisation and 6DoF pose estimation of ground robots in forest environments by leveraging cross-view factor graph optimisation and deep-learned re-localisation. The proposed method addresses the challenges of aligning aerial and ground data for pose estimation, which is crucial for accurate point-to-point navigation in GPS-denied environments. By integrating information from both perspectives into a factor graph framework, our approach effectively estimates the robot's global position and orientation. We validate the performance of our method through extensive experiments in diverse forest scenarios, demonstrating its superiority over existing baselines in terms of accuracy and robustness in these challenging environments. Experimental results show that our proposed localisation system can achieve drift-free localisation with bounded positioning errors, ensuring reliable and safe robot navigation under canopies.
Towards Long-term Robotics in the Wild
Apr 29, 2024



In this paper, we emphasise the critical importance of large-scale datasets for advancing field robotics capabilities, particularly in natural environments. While numerous datasets exist for urban and suburban settings, those tailored to natural environments are scarce. Our recent benchmarks WildPlaces and WildScenes address this gap by providing synchronised image, lidar, semantic and accurate 6-DoF pose information in forest-type environments. We highlight the multi-modal nature of this dataset and discuss and demonstrate its utility in various downstream tasks, such as place recognition and 2D and 3D semantic segmentation tasks.
WildScenes: A Benchmark for 2D and 3D Semantic Segmentation in Large-scale Natural Environments
Dec 23, 2023



Recent progress in semantic scene understanding has primarily been enabled by the availability of semantically annotated bi-modal (camera and lidar) datasets in urban environments. However, such annotated datasets are also needed for natural, unstructured environments to enable semantic perception for applications, including conservation, search and rescue, environment monitoring, and agricultural automation. Therefore, we introduce WildScenes, a bi-modal benchmark dataset consisting of multiple large-scale traversals in natural environments, including semantic annotations in high-resolution 2D images and dense 3D lidar point clouds, and accurate 6-DoF pose information. The data is (1) trajectory-centric with accurate localization and globally aligned point clouds, (2) calibrated and synchronized to support bi-modal inference, and (3) containing different natural environments over 6 months to support research on domain adaptation. Our 3D semantic labels are obtained via an efficient automated process that transfers the human-annotated 2D labels from multiple views into 3D point clouds, thus circumventing the need for expensive and time-consuming human annotation in 3D. We introduce benchmarks on 2D and 3D semantic segmentation and evaluate a variety of recent deep-learning techniques to demonstrate the challenges in semantic segmentation in natural environments. We propose train-val-test splits for standard benchmarks as well as domain adaptation benchmarks and utilize an automated split generation technique to ensure the balance of class label distributions. The data, evaluation scripts and pretrained models will be released upon acceptance at https://csiro-robotics.github.io/WildScenes.
Deep Robust Multi-Robot Re-localisation in Natural Environments
Jul 26, 2023



The success of re-localisation has crucial implications for the practical deployment of robots operating within a prior map or relative to one another in real-world scenarios. Using single-modality, place recognition and localisation can be compromised in challenging environments such as forests. To address this, we propose a strategy to prevent lidar-based re-localisation failure using lidar-image cross-modality. Our solution relies on self-supervised 2D-3D feature matching to predict alignment and misalignment. Leveraging a deep network for lidar feature extraction and relative pose estimation between point clouds, we train a model to evaluate the estimated transformation. A model predicting the presence of misalignment is learned by analysing image-lidar similarity in the embedding space and the geometric constraints available within the region seen in both modalities in Euclidean space. Experimental results using real datasets (offline and online modes) demonstrate the effectiveness of the proposed pipeline for robust re-localisation in unstructured, natural environments.