 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Not So Robust After All: Evaluating the Robustness of Deep Neural Networks to Unseen Adversarial Attacks
Aug 12, 2023
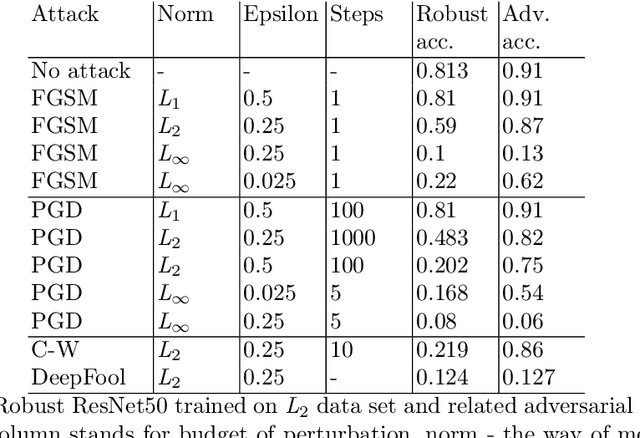
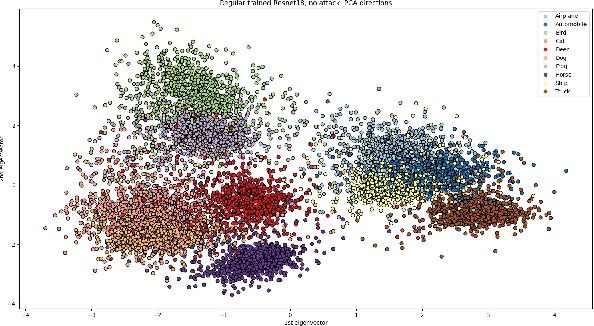
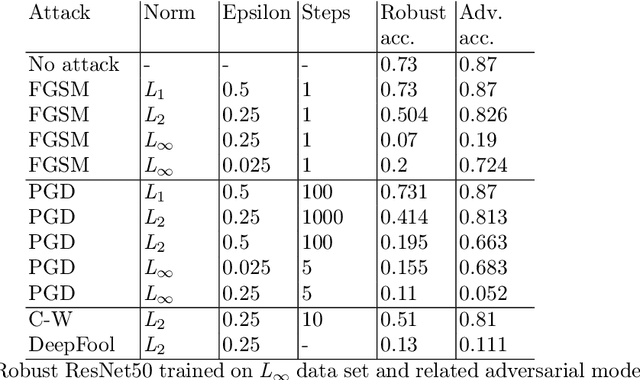
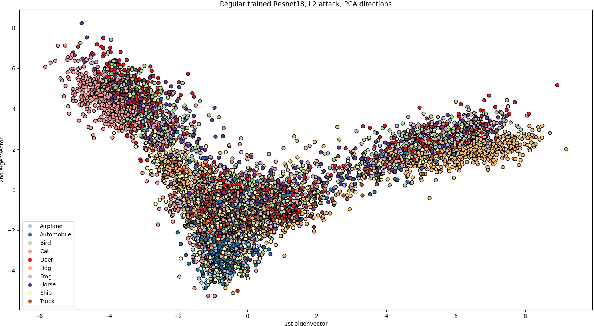
Deep neural networks (DNNs) have gained prominence in various applications, such as classification, recognition, and prediction, prompting increased scrutiny of their properties. A fundamental attribute of traditional DNNs is their vulnerability to modifications in input data, which has resulted in the investigation of adversarial attacks. These attacks manipulate the data in order to mislead a DNN. This study aims to challenge the efficacy and generalization of contemporary defense mechanisms against adversarial attacks. Specifically, we explore the hypothesis proposed by Ilyas et. al, which posits that DNN image features can be either robust or non-robust, with adversarial attacks targeting the latter. This hypothesis suggests that training a DNN on a dataset consisting solely of robust features should produce a model resistant to adversarial attacks. However, our experiments demonstrate that this is not universally true. To gain further insights into our findings, we analyze the impact of adversarial attack norms on DNN representations, focusing on samples subjected to $L_2$ and $L_{\infty}$ norm attacks. Further, we employ canonical correlation analysis, visualize the representations, and calculate the mean distance between these representations and various DNN decision boundaries. Our results reveal a significant difference between $L_2$ and $L_{\infty}$ norms, which could provide insights into the potential dangers posed by $L_{\infty}$ norm attacks, previously underestimated by the research community.
Adversarial Latent Autoencoder with Self-Attention for Structural Image Synthesis
Jul 19, 2023

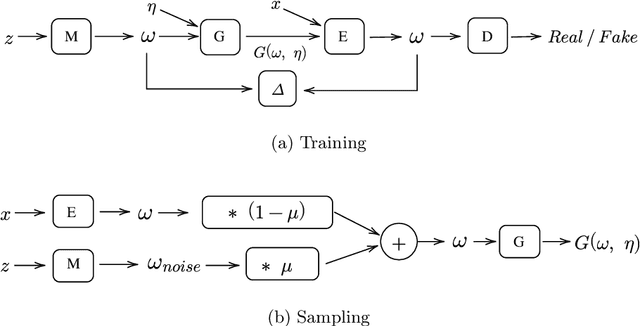

Generative Engineering Design approaches driven by Deep Generative Models (DGM) have been proposed to facilitate industrial engineering processes. In such processes, designs often come in the form of images, such as blueprints, engineering drawings, and CAD models depending on the level of detail. DGMs have been successfully employed for synthesis of natural images, e.g., displaying animals, human faces and landscapes. However, industrial design images are fundamentally different from natural scenes in that they contain rich structural patterns and long-range dependencies, which are challenging for convolution-based DGMs to generate. Moreover, DGM-driven generation process is typically triggered based on random noisy inputs, which outputs unpredictable samples and thus cannot perform an efficient industrial design exploration. We tackle these challenges by proposing a novel model Self-Attention Adversarial Latent Autoencoder (SA-ALAE), which allows generating feasible design images of complex engineering parts. With SA-ALAE, users can not only explore novel variants of an existing design, but also control the generation process by operating in latent space. The potential of SA-ALAE is shown by generating engineering blueprints in a real automotive design task.
MutateNN: Mutation Testing of Image Recognition Models Deployed on Hardware Accelerators
Jun 02, 2023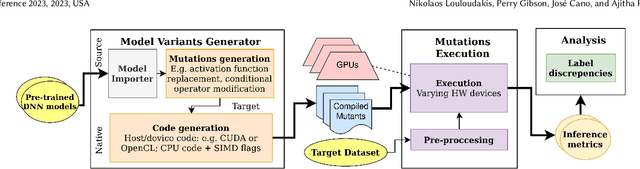
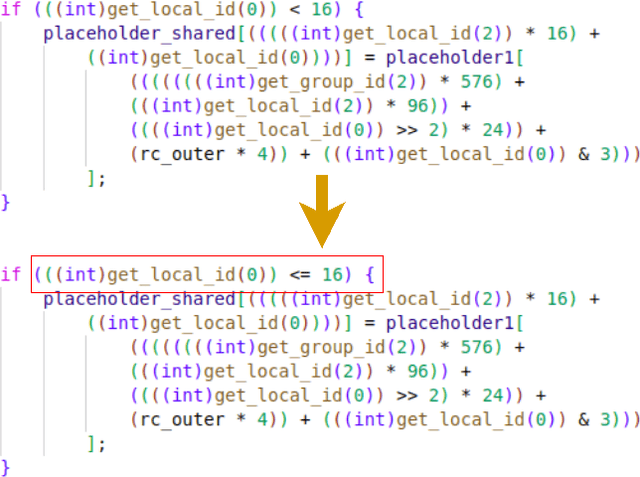
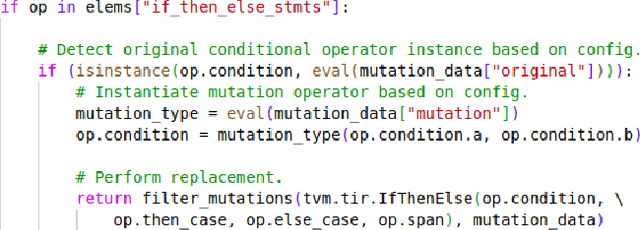

With the research advancement of Artificial Intelligence in the last years, there are new opportunities to mitigate real-world problems and advance technologically. Image recognition models in particular, are assigned with perception tasks to mitigate complex real-world challenges and lead to new solutions. Furthermore, the computational complexity and demand for resources of such models has also increased. To mitigate this, model optimization and hardware acceleration has come into play, but effectively integrating such concepts is a challenging and error-prone process. In order to allow developers and researchers to explore the robustness of deep learning image recognition models deployed on different hardware acceleration devices, we propose MutateNN, a tool that provides mutation testing and analysis capabilities for that purpose. To showcase its capabilities, we utilized 21 mutations for 7 widely-known pre-trained deep neural network models. We deployed our mutants on 4 different devices of varying computational capabilities and observed discrepancies in mutants related to conditional operations, as well as some unstable behaviour with those related to arithmetic types.
Self-Supervised Monocular Depth Estimation by Direction-aware Cumulative Convolution Network
Aug 10, 2023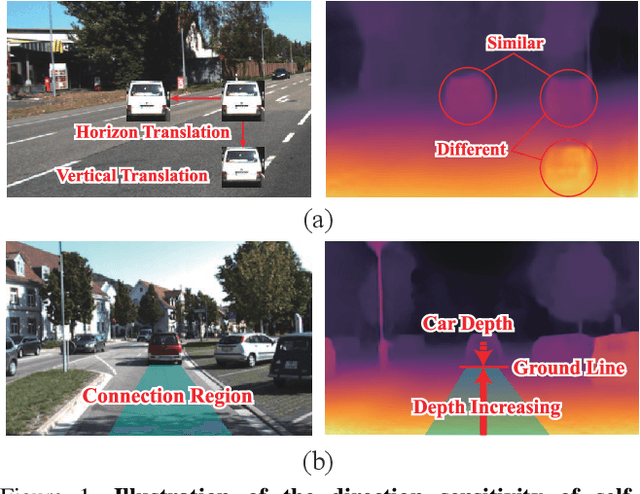
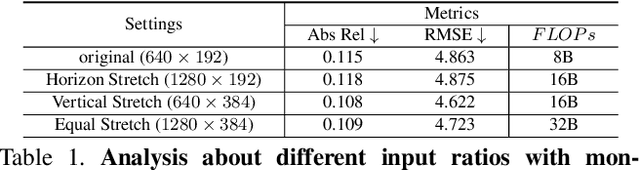
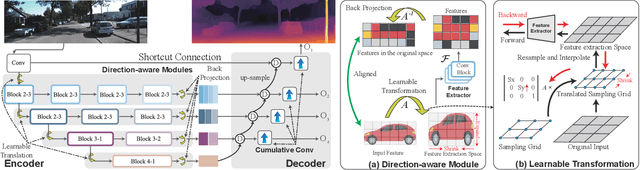
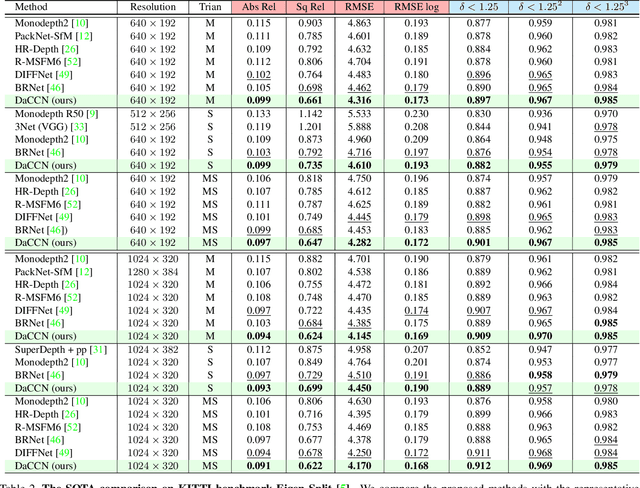
Monocular depth estimation is known as an ill-posed task in which objects in a 2D image usually do not contain sufficient information to predict their depth. Thus, it acts differently from other tasks (e.g., classification and segmentation) in many ways. In this paper, we find that self-supervised monocular depth estimation shows a direction sensitivity and environmental dependency in the feature representation. But the current backbones borrowed from other tasks pay less attention to handling different types of environmental information, limiting the overall depth accuracy. To bridge this gap, we propose a new Direction-aware Cumulative Convolution Network (DaCCN), which improves the depth feature representation in two aspects. First, we propose a direction-aware module, which can learn to adjust the feature extraction in each direction, facilitating the encoding of different types of information. Secondly, we design a new cumulative convolution to improve the efficiency for aggregating important environmental information. Experiments show that our method achieves significant improvements on three widely used benchmarks, KITTI, Cityscapes, and Make3D, setting a new state-of-the-art performance on the popular benchmarks with all three types of self-supervision.
Person Re-Identification without Identification via Event Anonymization
Aug 11, 2023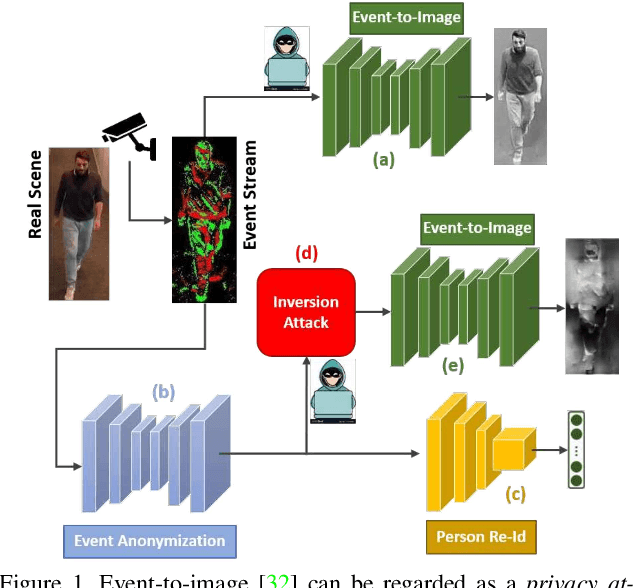


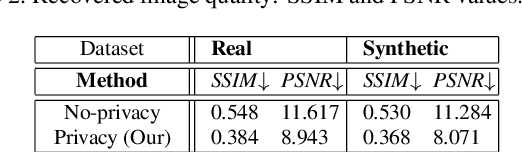
Wide-scale use of visual surveillance in public spaces puts individual privacy at stake while increasing resource consumption (energy, bandwidth, and computation). Neuromorphic vision sensors (event-cameras) have been recently considered a valid solution to the privacy issue because they do not capture detailed RGB visual information of the subjects in the scene. However, recent deep learning architectures have been able to reconstruct images from event cameras with high fidelity, reintroducing a potential threat to privacy for event-based vision applications. In this paper, we aim to anonymize event-streams to protect the identity of human subjects against such image reconstruction attacks. To achieve this, we propose an end-to-end network architecture jointly optimized for the twofold objective of preserving privacy and performing a downstream task such as person ReId. Our network learns to scramble events, enforcing the degradation of images recovered from the privacy attacker. In this work, we also bring to the community the first ever event-based person ReId dataset gathered to evaluate the performance of our approach. We validate our approach with extensive experiments and report results on the synthetic event data simulated from the publicly available SoftBio dataset and our proposed Event-ReId dataset.
Deep Learning-Based Open Source Toolkit for Eosinophil Detection in Pediatric Eosinophilic Esophagitis
Aug 11, 2023Eosinophilic Esophagitis (EoE) is a chronic, immune/antigen-mediated esophageal disease, characterized by symptoms related to esophageal dysfunction and histological evidence of eosinophil-dominant inflammation. Owing to the intricate microscopic representation of EoE in imaging, current methodologies which depend on manual identification are not only labor-intensive but also prone to inaccuracies. In this study, we develop an open-source toolkit, named Open-EoE, to perform end-to-end whole slide image (WSI) level eosinophil (Eos) detection using one line of command via Docker. Specifically, the toolkit supports three state-of-the-art deep learning-based object detection models. Furthermore, Open-EoE further optimizes the performance by implementing an ensemble learning strategy, and enhancing the precision and reliability of our results. The experimental results demonstrated that the Open-EoE toolkit can efficiently detect Eos on a testing set with 289 WSIs. At the widely accepted threshold of >= 15 Eos per high power field (HPF) for diagnosing EoE, the Open-EoE achieved an accuracy of 91%, showing decent consistency with pathologist evaluations. This suggests a promising avenue for integrating machine learning methodologies into the diagnostic process for EoE. The docker and source code has been made publicly available at https://github.com/hrlblab/Open-EoE.
Cyclic-Bootstrap Labeling for Weakly Supervised Object Detection
Aug 11, 2023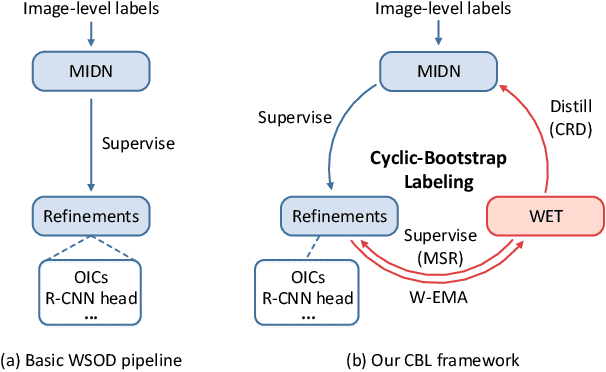

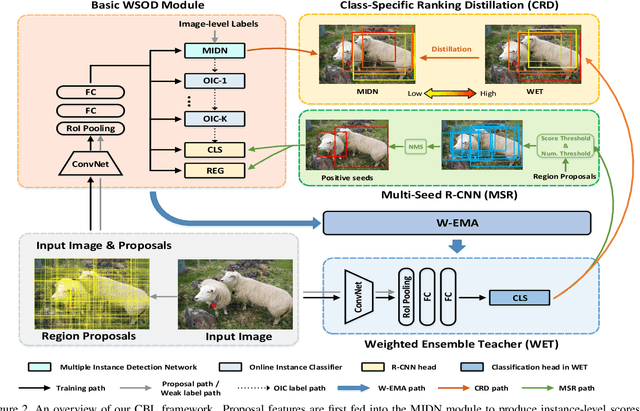
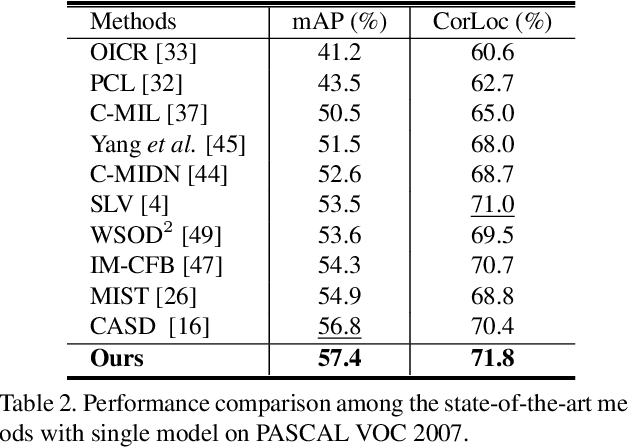
Recent progress in weakly supervised object detection is featured by a combination of multiple instance detection networks (MIDN) and ordinal online refinement. However, with only image-level annotation, MIDN inevitably assigns high scores to some unexpected region proposals when generating pseudo labels. These inaccurate high-scoring region proposals will mislead the training of subsequent refinement modules and thus hamper the detection performance. In this work, we explore how to ameliorate the quality of pseudo-labeling in MIDN. Formally, we devise Cyclic-Bootstrap Labeling (CBL), a novel weakly supervised object detection pipeline, which optimizes MIDN with rank information from a reliable teacher network. Specifically, we obtain this teacher network by introducing a weighted exponential moving average strategy to take advantage of various refinement modules. A novel class-specific ranking distillation algorithm is proposed to leverage the output of weighted ensembled teacher network for distilling MIDN with rank information. As a result, MIDN is guided to assign higher scores to accurate proposals among their neighboring ones, thus benefiting the subsequent pseudo labeling. Extensive experiments on the prevalent PASCAL VOC 2007 \& 2012 and COCO datasets demonstrate the superior performance of our CBL framework. Code will be available at https://github.com/Yinyf0804/WSOD-CBL/.
Detecting and Preventing Hallucinations in Large Vision Language Models
Aug 11, 2023
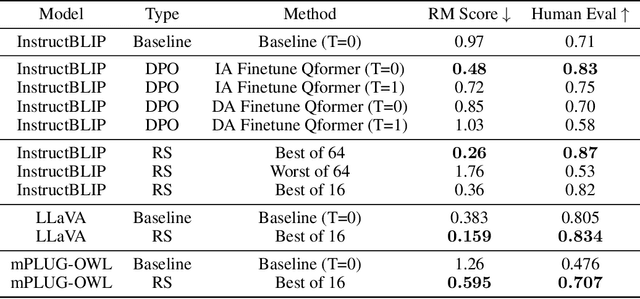
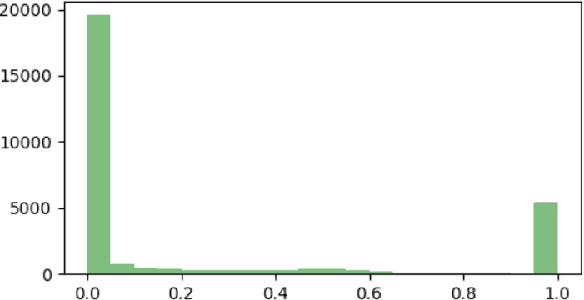
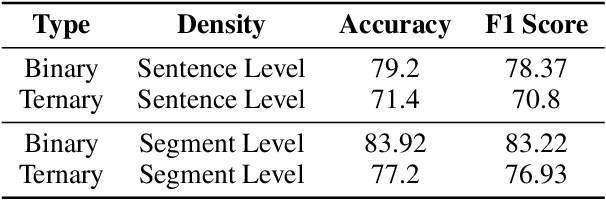
Instruction tuned Large Vision Language Models (LVLMs) have made significant advancements in generalizing across a diverse set of multimodal tasks, especially for Visual Question Answering (VQA). However, generating detailed responses that are visually grounded is still a challenging task for these models. We find that even the current state-of-the-art LVLMs (InstructBLIP) still contain a staggering 30 percent of hallucinatory text in the form of non-existent objects, unfaithful descriptions, and inaccurate relationships. To address this, we introduce M-HalDetect, a {M}ultimodal {Hal}lucination {Detect}ion Dataset that can be used to train and benchmark models for hallucination detection and prevention. M-HalDetect consists of 16k fine-grained labels on VQA examples, making it the first comprehensive multi-modal hallucination detection dataset for detailed image descriptions. Unlike previous work that only consider object hallucination, we additionally annotate both entity descriptions and relationships that are unfaithful. To demonstrate the potential of this dataset for preference alignment, we propose fine-grained Direct Preference Optimization, as well as train fine-grained multi-modal reward models and evaluate their effectiveness with best-of-n rejection sampling. We perform human evaluation on both DPO and rejection sampling, and find that they reduce hallucination rates by 41% and 55% respectively, a significant improvement over the baseline.
Redesigning Out-of-Distribution Detection on 3D Medical Images
Aug 07, 2023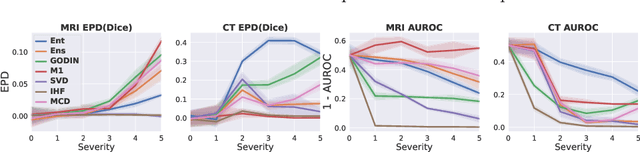
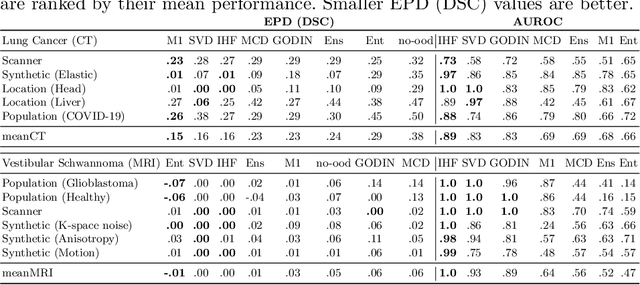

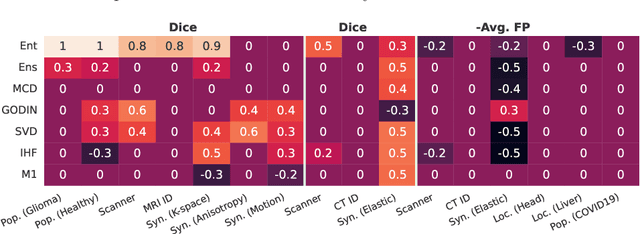
Detecting out-of-distribution (OOD) samples for trusted medical image segmentation remains a significant challenge. The critical issue here is the lack of a strict definition of abnormal data, which often results in artificial problem settings without measurable clinical impact. In this paper, we redesign the OOD detection problem according to the specifics of volumetric medical imaging and related downstream tasks (e.g., segmentation). We propose using the downstream model's performance as a pseudometric between images to define abnormal samples. This approach enables us to weigh different samples based on their performance impact without an explicit ID/OOD distinction. We incorporate this weighting in a new metric called Expected Performance Drop (EPD). EPD is our core contribution to the new problem design, allowing us to rank methods based on their clinical impact. We demonstrate the effectiveness of EPD-based evaluation in 11 CT and MRI OOD detection challenges.
Convolutions Die Hard: Open-Vocabulary Segmentation with Single Frozen Convolutional CLIP
Aug 04, 2023
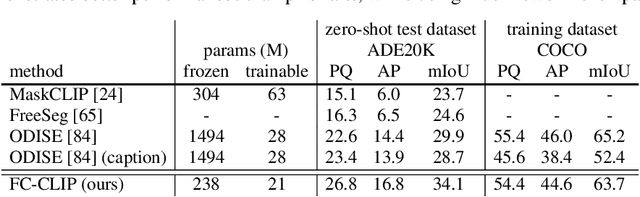
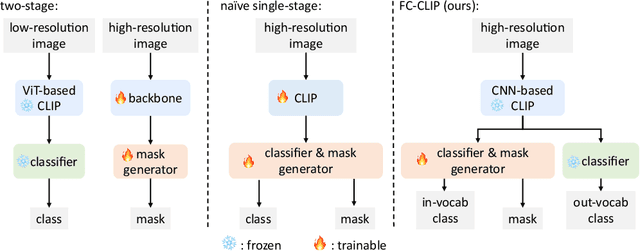

Open-vocabulary segmentation is a challenging task requiring segmenting and recognizing objects from an open set of categories. One way to address this challenge is to leverage multi-modal models, such as CLIP, to provide image and text features in a shared embedding space, which bridges the gap between closed-vocabulary and open-vocabulary recognition. Hence, existing methods often adopt a two-stage framework to tackle the problem, where the inputs first go through a mask generator and then through the CLIP model along with the predicted masks. This process involves extracting features from images multiple times, which can be ineffective and inefficient. By contrast, we propose to build everything into a single-stage framework using a shared Frozen Convolutional CLIP backbone, which not only significantly simplifies the current two-stage pipeline, but also remarkably yields a better accuracy-cost trade-off. The proposed FC-CLIP, benefits from the following observations: the frozen CLIP backbone maintains the ability of open-vocabulary classification and can also serve as a strong mask generator, and the convolutional CLIP generalizes well to a larger input resolution than the one used during contrastive image-text pretraining. When training on COCO panoptic data only and testing in a zero-shot manner, FC-CLIP achieve 26.8 PQ, 16.8 AP, and 34.1 mIoU on ADE20K, 18.2 PQ, 27.9 mIoU on Mapillary Vistas, 44.0 PQ, 26.8 AP, 56.2 mIoU on Cityscapes, outperforming the prior art by +4.2 PQ, +2.4 AP, +4.2 mIoU on ADE20K, +4.0 PQ on Mapillary Vistas and +20.1 PQ on Cityscapes, respectively. Additionally, the training and testing time of FC-CLIP is 7.5x and 6.6x significantly faster than the same prior art, while using 5.9x fewer parameters. FC-CLIP also sets a new state-of-the-art performance across various open-vocabulary semantic segmentation datasets. Code at https://github.com/bytedance/fc-clip