 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
GOPro: Generate and Optimize Prompts in CLIP using Self-Supervised Learning
Aug 22, 2023
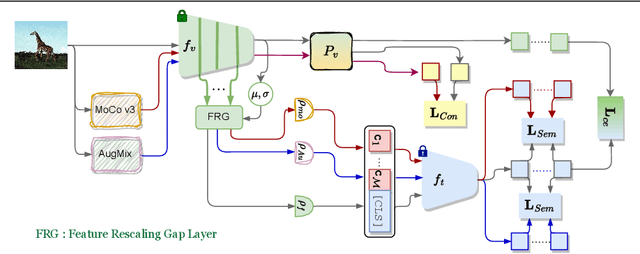
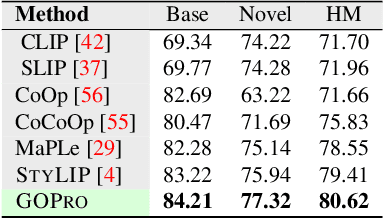
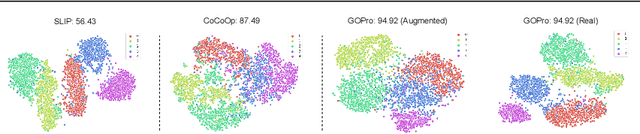
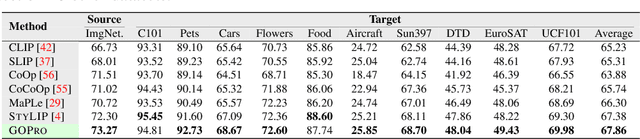
Large-scale foundation models, such as CLIP, have demonstrated remarkable success in visual recognition tasks by embedding images in a semantically rich space. Self-supervised learning (SSL) has also shown promise in improving visual recognition by learning invariant features. However, the combination of CLIP with SSL is found to face challenges due to the multi-task framework that blends CLIP's contrastive loss and SSL's loss, including difficulties with loss weighting and inconsistency among different views of images in CLIP's output space. To overcome these challenges, we propose a prompt learning-based model called GOPro, which is a unified framework that ensures similarity between various augmented views of input images in a shared image-text embedding space, using a pair of learnable image and text projectors atop CLIP, to promote invariance and generalizability. To automatically learn such prompts, we leverage the visual content and style primitives extracted from pre-trained CLIP and adapt them to the target task. In addition to CLIP's cross-domain contrastive loss, we introduce a visual contrastive loss and a novel prompt consistency loss, considering the different views of the images. GOPro is trained end-to-end on all three loss objectives, combining the strengths of CLIP and SSL in a principled manner. Empirical evaluations demonstrate that GOPro outperforms the state-of-the-art prompting techniques on three challenging domain generalization tasks across multiple benchmarks by a significant margin. Our code is available at https://github.com/mainaksingha01/GOPro.
Does Image Anonymization Impact Computer Vision Training?
Jun 08, 2023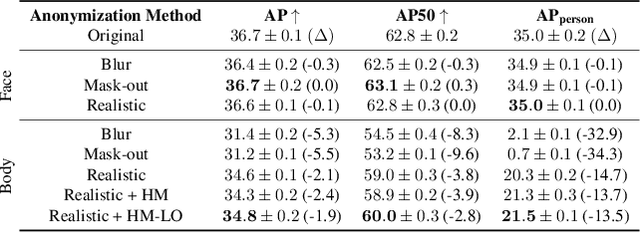

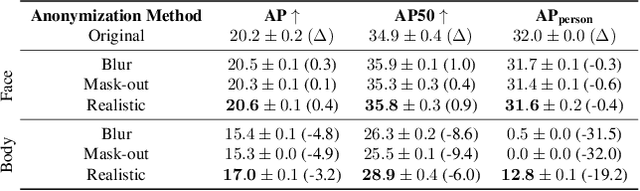

Image anonymization is widely adapted in practice to comply with privacy regulations in many regions. However, anonymization often degrades the quality of the data, reducing its utility for computer vision development. In this paper, we investigate the impact of image anonymization for training computer vision models on key computer vision tasks (detection, instance segmentation, and pose estimation). Specifically, we benchmark the recognition drop on common detection datasets, where we evaluate both traditional and realistic anonymization for faces and full bodies. Our comprehensive experiments reflect that traditional image anonymization substantially impacts final model performance, particularly when anonymizing the full body. Furthermore, we find that realistic anonymization can mitigate this decrease in performance, where our experiments reflect a minimal performance drop for face anonymization. Our study demonstrates that realistic anonymization can enable privacy-preserving computer vision development with minimal performance degradation across a range of important computer vision benchmarks.
Resource-Efficient Federated Learning for Heterogenous and Resource-Constrained Environments
Aug 25, 2023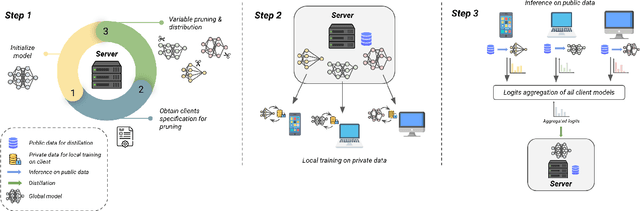
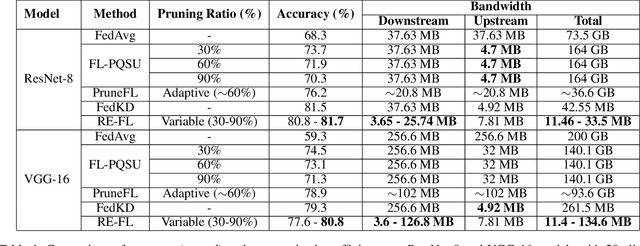
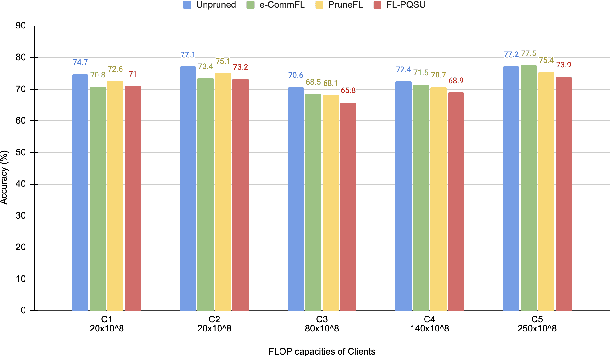
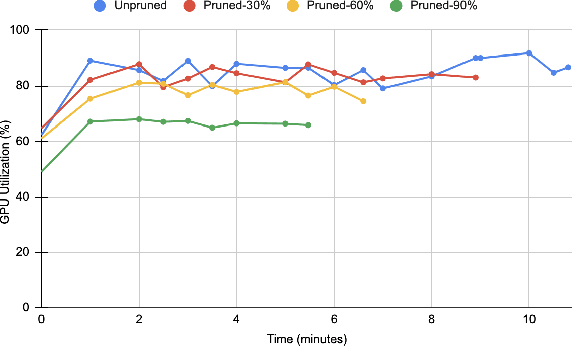
Federated Learning (FL) is a privacy-enforcing sub-domain of machine learning that brings the model to the user's device for training, avoiding the need to share personal data with a central server. While existing works address data heterogeneity, they overlook other challenges in FL, such as device heterogeneity and communication efficiency. In this paper, we propose RE-FL, a novel approach that tackles computational and communication challenges in resource-constrained devices. Our variable pruning technique optimizes resource utilization by adapting pruning to each client's computational capabilities. We also employ knowledge distillation to reduce bandwidth consumption and communication rounds. Experimental results on image classification tasks demonstrate the effectiveness of our approach in resource-constrained environments, maintaining data privacy and performance while accommodating heterogeneous model architectures.
Distribution-Aligned Diffusion for Human Mesh Recovery
Aug 25, 2023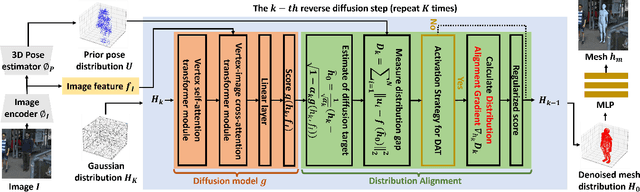
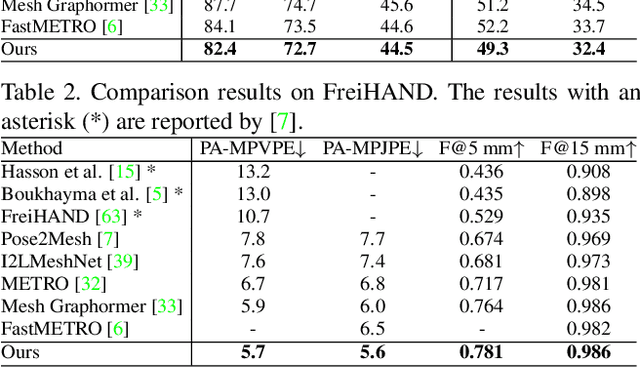

Recovering a 3D human mesh from a single RGB image is a challenging task due to depth ambiguity and self-occlusion, resulting in a high degree of uncertainty. Meanwhile, diffusion models have recently seen much success in generating high-quality outputs by progressively denoising noisy inputs. Inspired by their capability, we explore a diffusion-based approach for human mesh recovery, and propose a Human Mesh Diffusion (HMDiff) framework which frames mesh recovery as a reverse diffusion process. We also propose a Distribution Alignment Technique (DAT) that injects input-specific distribution information into the diffusion process, and provides useful prior knowledge to simplify the mesh recovery task. Our method achieves state-of-the-art performance on three widely used datasets. Project page: https://gongjia0208.github.io/HMDiff/.
An investigation into the impact of deep learning model choice on sex and race bias in cardiac MR segmentation
Aug 25, 2023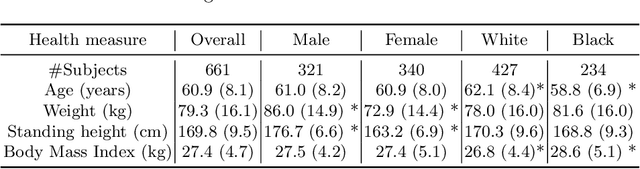
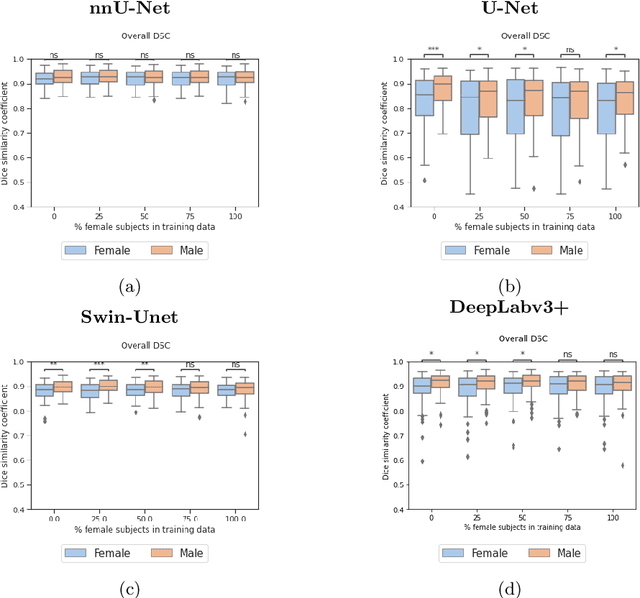
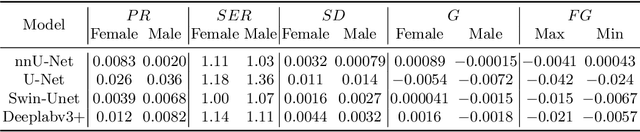
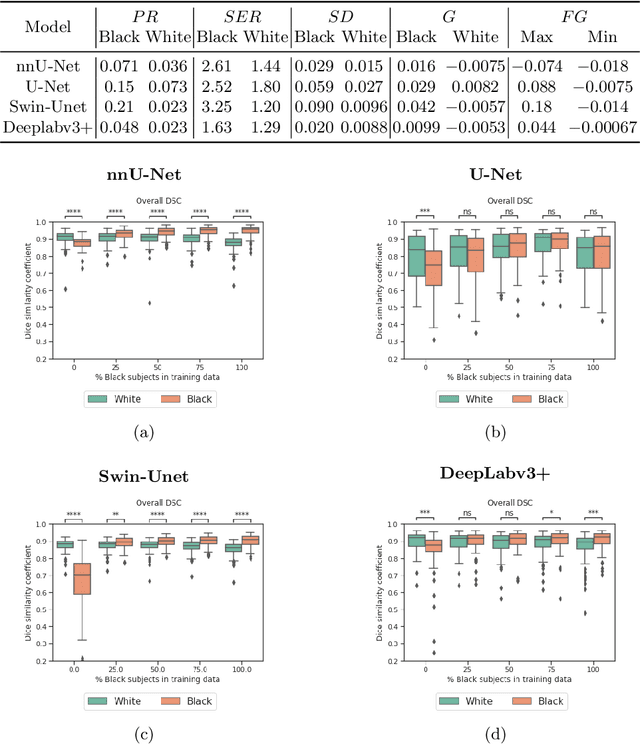
In medical imaging, artificial intelligence (AI) is increasingly being used to automate routine tasks. However, these algorithms can exhibit and exacerbate biases which lead to disparate performances between protected groups. We investigate the impact of model choice on how imbalances in subject sex and race in training datasets affect AI-based cine cardiac magnetic resonance image segmentation. We evaluate three convolutional neural network-based models and one vision transformer model. We find significant sex bias in three of the four models and racial bias in all of the models. However, the severity and nature of the bias varies between the models, highlighting the importance of model choice when attempting to train fair AI-based segmentation models for medical imaging tasks.
TeCH: Text-guided Reconstruction of Lifelike Clothed Humans
Aug 16, 2023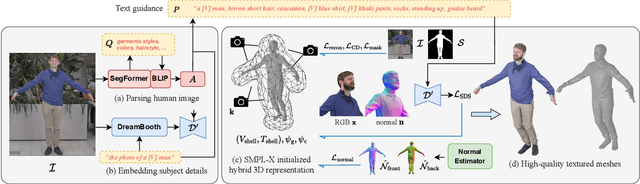

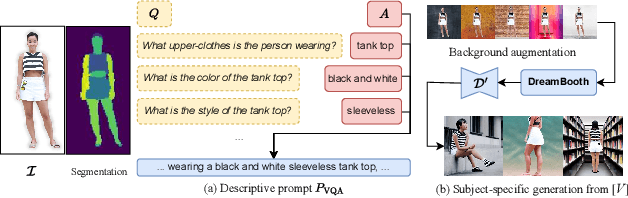
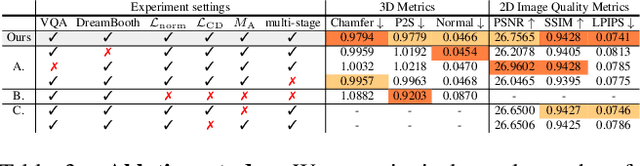
Despite recent research advancements in reconstructing clothed humans from a single image, accurately restoring the "unseen regions" with high-level details remains an unsolved challenge that lacks attention. Existing methods often generate overly smooth back-side surfaces with a blurry texture. But how to effectively capture all visual attributes of an individual from a single image, which are sufficient to reconstruct unseen areas (e.g., the back view)? Motivated by the power of foundation models, TeCH reconstructs the 3D human by leveraging 1) descriptive text prompts (e.g., garments, colors, hairstyles) which are automatically generated via a garment parsing model and Visual Question Answering (VQA), 2) a personalized fine-tuned Text-to-Image diffusion model (T2I) which learns the "indescribable" appearance. To represent high-resolution 3D clothed humans at an affordable cost, we propose a hybrid 3D representation based on DMTet, which consists of an explicit body shape grid and an implicit distance field. Guided by the descriptive prompts + personalized T2I diffusion model, the geometry and texture of the 3D humans are optimized through multi-view Score Distillation Sampling (SDS) and reconstruction losses based on the original observation. TeCH produces high-fidelity 3D clothed humans with consistent & delicate texture, and detailed full-body geometry. Quantitative and qualitative experiments demonstrate that TeCH outperforms the state-of-the-art methods in terms of reconstruction accuracy and rendering quality. The code will be publicly available for research purposes at https://huangyangyi.github.io/tech
Learning to Distill Global Representation for Sparse-View CT
Aug 16, 2023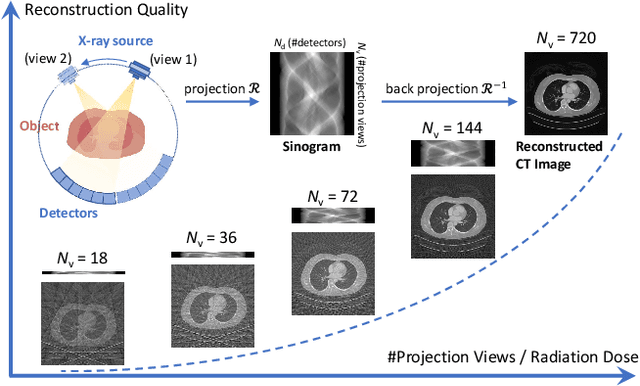
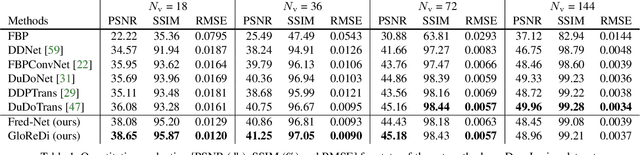
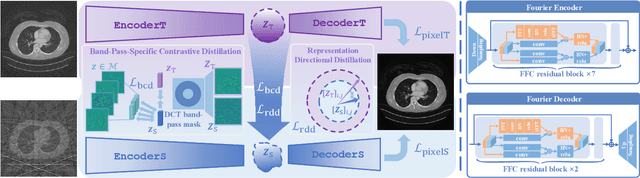
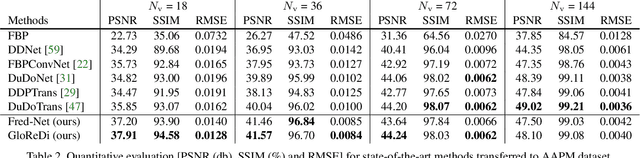
Sparse-view computed tomography (CT) -- using a small number of projections for tomographic reconstruction -- enables much lower radiation dose to patients and accelerated data acquisition. The reconstructed images, however, suffer from strong artifacts, greatly limiting their diagnostic value. Current trends for sparse-view CT turn to the raw data for better information recovery. The resultant dual-domain methods, nonetheless, suffer from secondary artifacts, especially in ultra-sparse view scenarios, and their generalization to other scanners/protocols is greatly limited. A crucial question arises: have the image post-processing methods reached the limit? Our answer is not yet. In this paper, we stick to image post-processing methods due to great flexibility and propose global representation (GloRe) distillation framework for sparse-view CT, termed GloReDi. First, we propose to learn GloRe with Fourier convolution, so each element in GloRe has an image-wide receptive field. Second, unlike methods that only use the full-view images for supervision, we propose to distill GloRe from intermediate-view reconstructed images that are readily available but not explored in previous literature. The success of GloRe distillation is attributed to two key components: representation directional distillation to align the GloRe directions, and band-pass-specific contrastive distillation to gain clinically important details. Extensive experiments demonstrate the superiority of the proposed GloReDi over the state-of-the-art methods, including dual-domain ones. The source code is available at https://github.com/longzilicart/GloReDi.
Not All Image Regions Matter: Masked Vector Quantization for Autoregressive Image Generation
May 23, 2023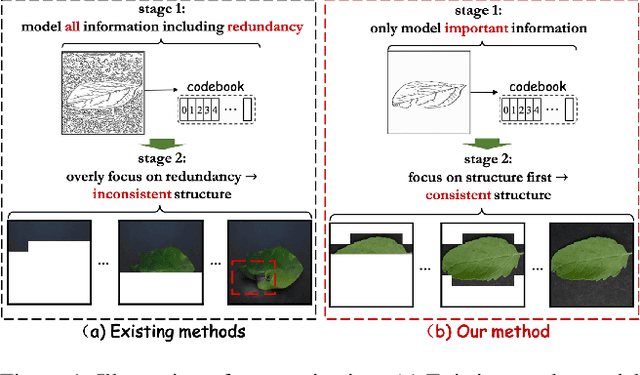
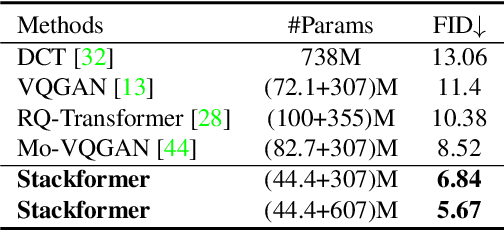
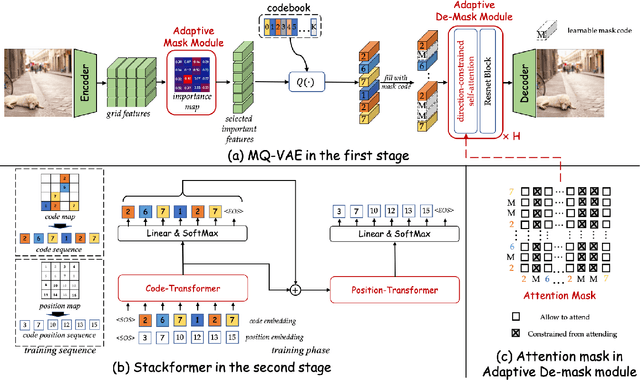
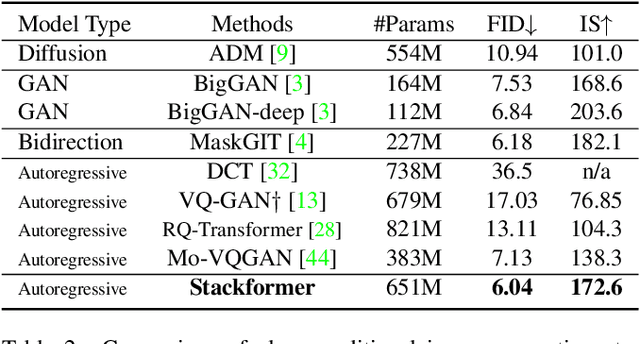
Existing autoregressive models follow the two-stage generation paradigm that first learns a codebook in the latent space for image reconstruction and then completes the image generation autoregressively based on the learned codebook. However, existing codebook learning simply models all local region information of images without distinguishing their different perceptual importance, which brings redundancy in the learned codebook that not only limits the next stage's autoregressive model's ability to model important structure but also results in high training cost and slow generation speed. In this study, we borrow the idea of importance perception from classical image coding theory and propose a novel two-stage framework, which consists of Masked Quantization VAE (MQ-VAE) and Stackformer, to relieve the model from modeling redundancy. Specifically, MQ-VAE incorporates an adaptive mask module for masking redundant region features before quantization and an adaptive de-mask module for recovering the original grid image feature map to faithfully reconstruct the original images after quantization. Then, Stackformer learns to predict the combination of the next code and its position in the feature map. Comprehensive experiments on various image generation validate our effectiveness and efficiency. Code will be released at https://github.com/CrossmodalGroup/MaskedVectorQuantization.
Temporal-Distributed Backdoor Attack Against Video Based Action Recognition
Aug 21, 2023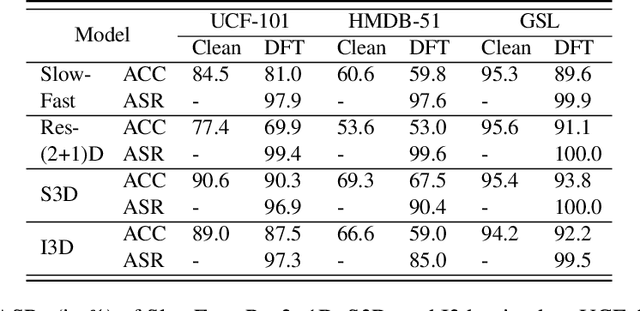

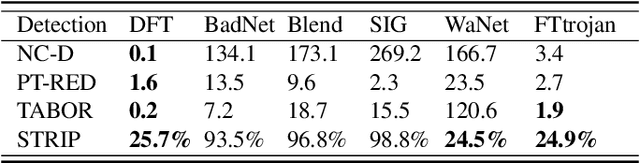
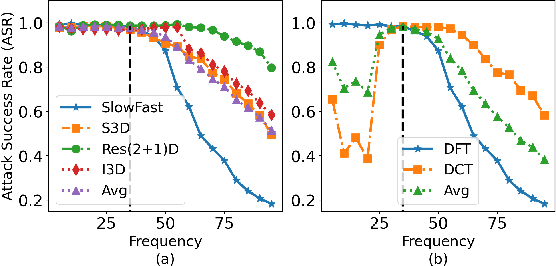
Deep neural networks (DNNs) have achieved tremendous success in various applications including video action recognition, yet remain vulnerable to backdoor attacks (Trojans). The backdoor-compromised model will mis-classify to the target class chosen by the attacker when a test instance (from a non-target class) is embedded with a specific trigger, while maintaining high accuracy on attack-free instances. Although there are extensive studies on backdoor attacks against image data, the susceptibility of video-based systems under backdoor attacks remains largely unexplored. Current studies are direct extensions of approaches proposed for image data, e.g., the triggers are \textbf{independently} embedded within the frames, which tend to be detectable by existing defenses. In this paper, we introduce a \textit{simple} yet \textit{effective} backdoor attack against video data. Our proposed attack, adding perturbations in a transformed domain, plants an \textbf{imperceptible, temporally distributed} trigger across the video frames, and is shown to be resilient to existing defensive strategies. The effectiveness of the proposed attack is demonstrated by extensive experiments with various well-known models on two video recognition benchmarks, UCF101 and HMDB51, and a sign language recognition benchmark, Greek Sign Language (GSL) dataset. We delve into the impact of several influential factors on our proposed attack and identify an intriguing effect termed "collateral damage" through extensive studies.
Approximately Equivariant Graph Networks
Aug 21, 2023

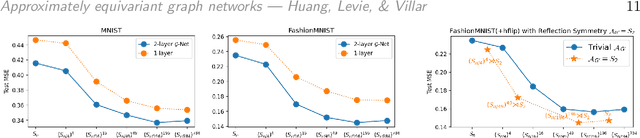

Graph neural networks (GNNs) are commonly described as being permutation equivariant with respect to node relabeling in the graph. This symmetry of GNNs is often compared to the translation equivariance symmetry of Euclidean convolution neural networks (CNNs). However, these two symmetries are fundamentally different: The translation equivariance of CNNs corresponds to symmetries of the fixed domain acting on the image signal (sometimes known as active symmetries), whereas in GNNs any permutation acts on both the graph signals and the graph domain (sometimes described as passive symmetries). In this work, we focus on the active symmetries of GNNs, by considering a learning setting where signals are supported on a fixed graph. In this case, the natural symmetries of GNNs are the automorphisms of the graph. Since real-world graphs tend to be asymmetric, we relax the notion of symmetries by formalizing approximate symmetries via graph coarsening. We present a bias-variance formula that quantifies the tradeoff between the loss in expressivity and the gain in the regularity of the learned estimator, depending on the chosen symmetry group. To illustrate our approach, we conduct extensive experiments on image inpainting, traffic flow prediction, and human pose estimation with different choices of symmetries. We show theoretically and empirically that the best generalization performance can be achieved by choosing a suitably larger group than the graph automorphism group, but smaller than the full permutation group.