 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
DiffHuman: Probabilistic Photorealistic 3D Reconstruction of Humans
Mar 30, 2024
We present DiffHuman, a probabilistic method for photorealistic 3D human reconstruction from a single RGB image. Despite the ill-posed nature of this problem, most methods are deterministic and output a single solution, often resulting in a lack of geometric detail and blurriness in unseen or uncertain regions. In contrast, DiffHuman predicts a probability distribution over 3D reconstructions conditioned on an input 2D image, which allows us to sample multiple detailed 3D avatars that are consistent with the image. DiffHuman is implemented as a conditional diffusion model that denoises pixel-aligned 2D observations of an underlying 3D shape representation. During inference, we may sample 3D avatars by iteratively denoising 2D renders of the predicted 3D representation. Furthermore, we introduce a generator neural network that approximates rendering with considerably reduced runtime (55x speed up), resulting in a novel dual-branch diffusion framework. Our experiments show that DiffHuman can produce diverse and detailed reconstructions for the parts of the person that are unseen or uncertain in the input image, while remaining competitive with the state-of-the-art when reconstructing visible surfaces.
BiTT: Bi-directional Texture Reconstruction of Interacting Two Hands from a Single Image
Mar 21, 2024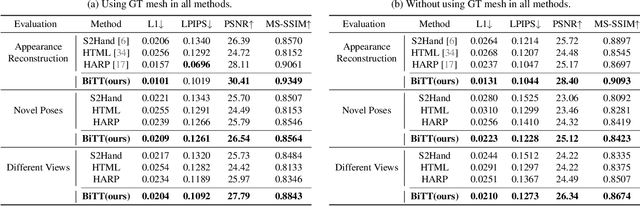
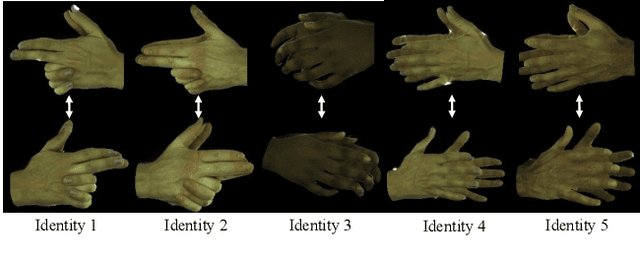
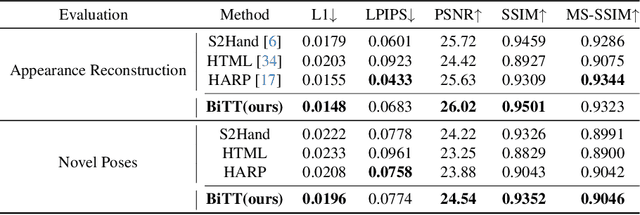
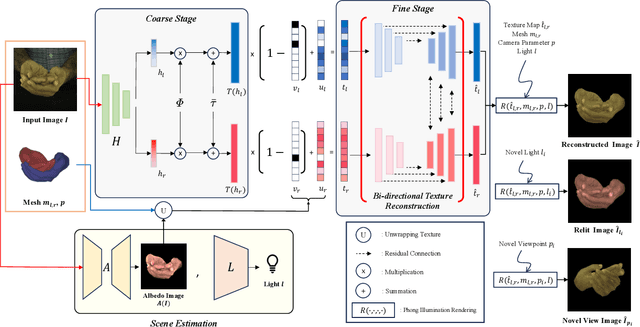
Creating personalized hand avatars is important to offer a realistic experience to users on AR / VR platforms. While most prior studies focused on reconstructing 3D hand shapes, some recent work has tackled the reconstruction of hand textures on top of shapes. However, these methods are often limited to capturing pixels on the visible side of a hand, requiring diverse views of the hand in a video or multiple images as input. In this paper, we propose a novel method, BiTT(Bi-directional Texture reconstruction of Two hands), which is the first end-to-end trainable method for relightable, pose-free texture reconstruction of two interacting hands taking only a single RGB image, by three novel components: 1) bi-directional (left $\leftrightarrow$ right) texture reconstruction using the texture symmetry of left / right hands, 2) utilizing a texture parametric model for hand texture recovery, and 3) the overall coarse-to-fine stage pipeline for reconstructing personalized texture of two interacting hands. BiTT first estimates the scene light condition and albedo image from an input image, then reconstructs the texture of both hands through the texture parametric model and bi-directional texture reconstructor. In experiments using InterHand2.6M and RGB2Hands datasets, our method significantly outperforms state-of-the-art hand texture reconstruction methods quantitatively and qualitatively. The code is available at https://github.com/yunminjin2/BiTT
Flexible Variable-Rate Image Feature Compression for Edge-Cloud Systems
Mar 30, 2024Feature compression is a promising direction for coding for machines. Existing methods have made substantial progress, but they require designing and training separate neural network models to meet different specifications of compression rate, performance accuracy and computational complexity. In this paper, a flexible variable-rate feature compression method is presented that can operate on a range of rates by introducing a rate control parameter as an input to the neural network model. By compressing different intermediate features of a pre-trained vision task model, the proposed method can scale the encoding complexity without changing the overall size of the model. The proposed method is more flexible than existing baselines, at the same time outperforming them in terms of the three-way trade-off between feature compression rate, vision task accuracy, and encoding complexity. We have made the source code available at https://github.com/adnan-hossain/var_feat_comp.git.
Using Images as Covariates: Measuring Curb Appeal with Deep Learning
Mar 29, 2024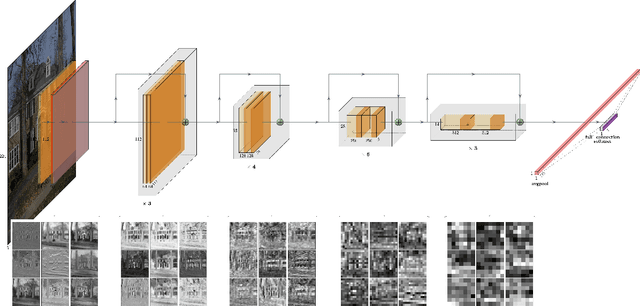
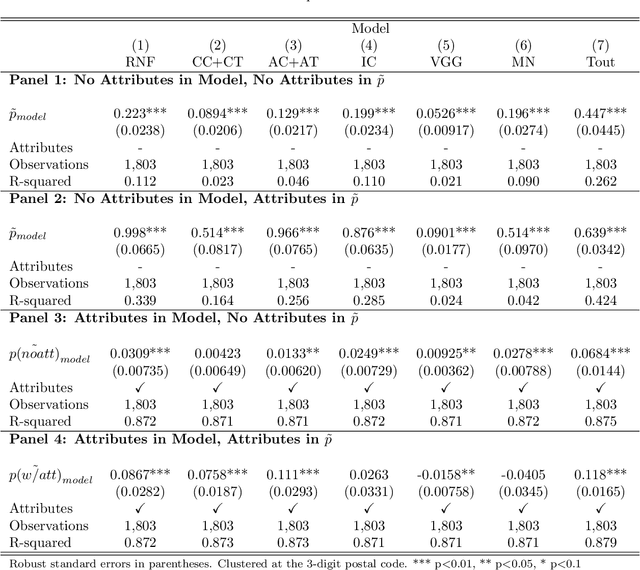

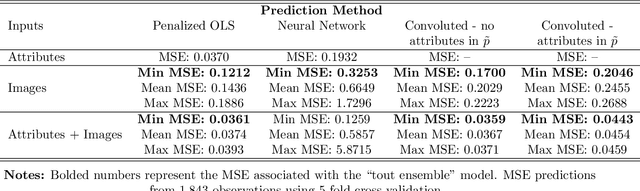
This paper details an innovative methodology to integrate image data into traditional econometric models. Motivated by forecasting sales prices for residential real estate, we harness the power of deep learning to add "information" contained in images as covariates. Specifically, images of homes were categorized and encoded using an ensemble of image classifiers (ResNet-50, VGG16, MobileNet, and Inception V3). Unique features presented within each image were further encoded through panoptic segmentation. Forecasts from a neural network trained on the encoded data results in improved out-of-sample predictive power. We also combine these image-based forecasts with standard hedonic real estate property and location characteristics, resulting in a unified dataset. We show that image-based forecasts increase the accuracy of hedonic forecasts when encoded features are regarded as additional covariates. We also attempt to "explain" which covariates the image-based forecasts are most highly correlated with. The study exemplifies the benefits of interdisciplinary methodologies, merging machine learning and econometrics to harness untapped data sources for more accurate forecasting.
Your Image is My Video: Reshaping the Receptive Field via Image-To-Video Differentiable AutoAugmentation and Fusion
Mar 22, 2024The landscape of deep learning research is moving towards innovative strategies to harness the true potential of data. Traditionally, emphasis has been on scaling model architectures, resulting in large and complex neural networks, which can be difficult to train with limited computational resources. However, independently of the model size, data quality (i.e. amount and variability) is still a major factor that affects model generalization. In this work, we propose a novel technique to exploit available data through the use of automatic data augmentation for the tasks of image classification and semantic segmentation. We introduce the first Differentiable Augmentation Search method (DAS) to generate variations of images that can be processed as videos. Compared to previous approaches, DAS is extremely fast and flexible, allowing the search on very large search spaces in less than a GPU day. Our intuition is that the increased receptive field in the temporal dimension provided by DAS could lead to benefits also to the spatial receptive field. More specifically, we leverage DAS to guide the reshaping of the spatial receptive field by selecting task-dependant transformations. As a result, compared to standard augmentation alternatives, we improve in terms of accuracy on ImageNet, Cifar10, Cifar100, Tiny-ImageNet, Pascal-VOC-2012 and CityScapes datasets when plugging-in our DAS over different light-weight video backbones.
CIRP: Cross-Item Relational Pre-training for Multimodal Product Bundling
Apr 02, 2024Product bundling has been a prevailing marketing strategy that is beneficial in the online shopping scenario. Effective product bundling methods depend on high-quality item representations, which need to capture both the individual items' semantics and cross-item relations. However, previous item representation learning methods, either feature fusion or graph learning, suffer from inadequate cross-modal alignment and struggle to capture the cross-item relations for cold-start items. Multimodal pre-train models could be the potential solutions given their promising performance on various multimodal downstream tasks. However, the cross-item relations have been under-explored in the current multimodal pre-train models. To bridge this gap, we propose a novel and simple framework Cross-Item Relational Pre-training (CIRP) for item representation learning in product bundling. Specifically, we employ a multimodal encoder to generate image and text representations. Then we leverage both the cross-item contrastive loss (CIC) and individual item's image-text contrastive loss (ITC) as the pre-train objectives. Our method seeks to integrate cross-item relation modeling capability into the multimodal encoder, while preserving the in-depth aligned multimodal semantics. Therefore, even for cold-start items that have no relations, their representations are still relation-aware. Furthermore, to eliminate the potential noise and reduce the computational cost, we harness a relation pruning module to remove the noisy and redundant relations. We apply the item representations extracted by CIRP to the product bundling model ItemKNN, and experiments on three e-commerce datasets demonstrate that CIRP outperforms various leading representation learning methods.
Diffusion Attack: Leveraging Stable Diffusion for Naturalistic Image Attacking
Mar 21, 2024In Virtual Reality (VR), adversarial attack remains a significant security threat. Most deep learning-based methods for physical and digital adversarial attacks focus on enhancing attack performance by crafting adversarial examples that contain large printable distortions that are easy for human observers to identify. However, attackers rarely impose limitations on the naturalness and comfort of the appearance of the generated attack image, resulting in a noticeable and unnatural attack. To address this challenge, we propose a framework to incorporate style transfer to craft adversarial inputs of natural styles that exhibit minimal detectability and maximum natural appearance, while maintaining superior attack capabilities.
Terrain Point Cloud Inpainting via Signal Decomposition
Apr 04, 2024The rapid development of 3D acquisition technology has made it possible to obtain point clouds of real-world terrains. However, due to limitations in sensor acquisition technology or specific requirements, point clouds often contain defects such as holes with missing data. Inpainting algorithms are widely used to patch these holes. However, existing traditional inpainting algorithms rely on precise hole boundaries, which limits their ability to handle cases where the boundaries are not well-defined. On the other hand, learning-based completion methods often prioritize reconstructing the entire point cloud instead of solely focusing on hole filling. Based on the fact that real-world terrain exhibits both global smoothness and rich local detail, we propose a novel representation for terrain point clouds. This representation can help to repair the holes without clear boundaries. Specifically, it decomposes terrains into low-frequency and high-frequency components, which are represented by B-spline surfaces and relative height maps respectively. In this way, the terrain point cloud inpainting problem is transformed into a B-spline surface fitting and 2D image inpainting problem. By solving the two problems, the highly complex and irregular holes on the terrain point clouds can be well-filled, which not only satisfies the global terrain undulation but also exhibits rich geometric details. The experimental results also demonstrate the effectiveness of our method.
How Much Data are Enough? Investigating Dataset Requirements for Patch-Based Brain MRI Segmentation Tasks
Apr 04, 2024Training deep neural networks reliably requires access to large-scale datasets. However, obtaining such datasets can be challenging, especially in the context of neuroimaging analysis tasks, where the cost associated with image acquisition and annotation can be prohibitive. To mitigate both the time and financial costs associated with model development, a clear understanding of the amount of data required to train a satisfactory model is crucial. This paper focuses on an early stage phase of deep learning research, prior to model development, and proposes a strategic framework for estimating the amount of annotated data required to train patch-based segmentation networks. This framework includes the establishment of performance expectations using a novel Minor Boundary Adjustment for Threshold (MinBAT) method, and standardizing patch selection through the ROI-based Expanded Patch Selection (REPS) method. Our experiments demonstrate that tasks involving regions of interest (ROIs) with different sizes or shapes may yield variably acceptable Dice Similarity Coefficient (DSC) scores. By setting an acceptable DSC as the target, the required amount of training data can be estimated and even predicted as data accumulates. This approach could assist researchers and engineers in estimating the cost associated with data collection and annotation when defining a new segmentation task based on deep neural networks, ultimately contributing to their efficient translation to real-world applications.
The Devil is in the Edges: Monocular Depth Estimation with Edge-aware Consistency Fusion
Mar 30, 2024This paper presents a novel monocular depth estimation method, named ECFNet, for estimating high-quality monocular depth with clear edges and valid overall structure from a single RGB image. We make a thorough inquiry about the key factor that affects the edge depth estimation of the MDE networks, and come to a ratiocination that the edge information itself plays a critical role in predicting depth details. Driven by this analysis, we propose to explicitly employ the image edges as input for ECFNet and fuse the initial depths from different sources to produce the final depth. Specifically, ECFNet first uses a hybrid edge detection strategy to get the edge map and edge-highlighted image from the input image, and then leverages a pre-trained MDE network to infer the initial depths of the aforementioned three images. After that, ECFNet utilizes a layered fusion module (LFM) to fuse the initial depth, which will be further updated by a depth consistency module (DCM) to form the final estimation. Extensive experimental results on public datasets and ablation studies indicate that our method achieves state-of-the-art performance. Project page: https://zrealli.github.io/edgedepth.