 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Machine Vision Method for Correction of Eccentric Error: Based on Adaptive Enhancement Algorithm
Sep 01, 2023
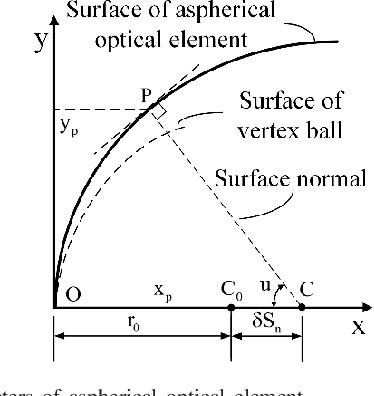

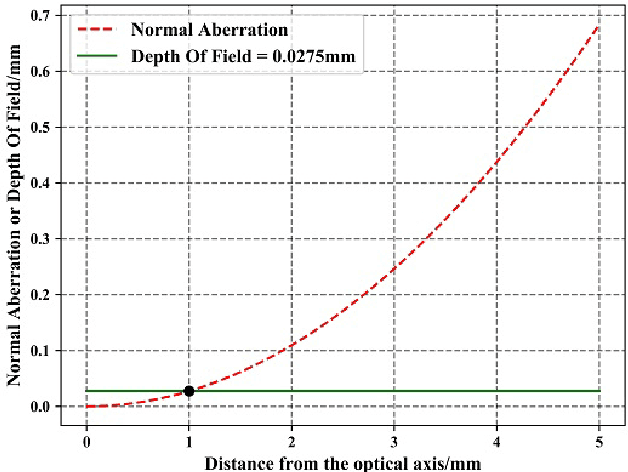

In the procedure of surface defects detection for large-aperture aspherical optical elements, it is of vital significance to adjust the optical axis of the element to be coaxial with the mechanical spin axis accurately. Therefore, a machine vision method for eccentric error correction is proposed in this paper. Focusing on the severe defocus blur of reference crosshair image caused by the imaging characteristic of the aspherical optical element, which may lead to the failure of correction, an Adaptive Enhancement Algorithm (AEA) is proposed to strengthen the crosshair image. AEA is consisted of existed Guided Filter Dark Channel Dehazing Algorithm (GFA) and proposed lightweight Multi-scale Densely Connected Network (MDC-Net). The enhancement effect of GFA is excellent but time-consuming, and the enhancement effect of MDC-Net is slightly inferior but strongly real-time. As AEA will be executed dozens of times during each correction procedure, its real-time performance is very important. Therefore, by setting the empirical threshold of definition evaluation function SMD2, GFA and MDC-Net are respectively applied to highly and slightly blurred crosshair images so as to ensure the enhancement effect while saving as much time as possible. AEA has certain robustness in time-consuming performance, which takes an average time of 0.2721s and 0.0963s to execute GFA and MDC-Net separately on ten 200pixels 200pixels Region of Interest (ROI) images with different degrees of blur. And the eccentricity error can be reduced to within 10um by our method.
Discrete Morphological Neural Networks
Sep 01, 2023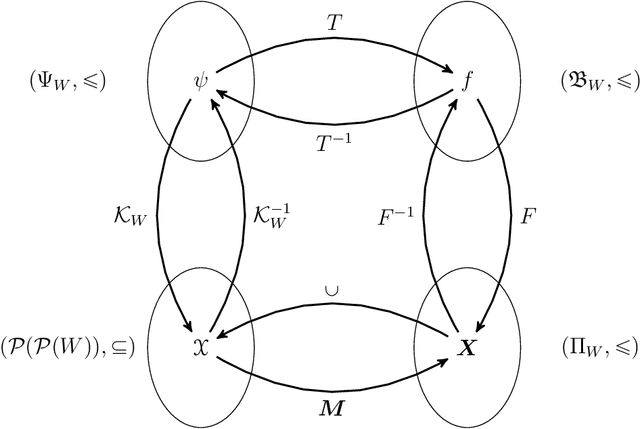

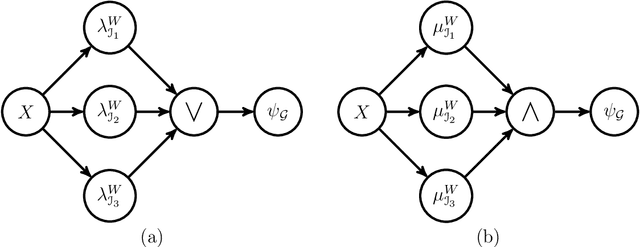
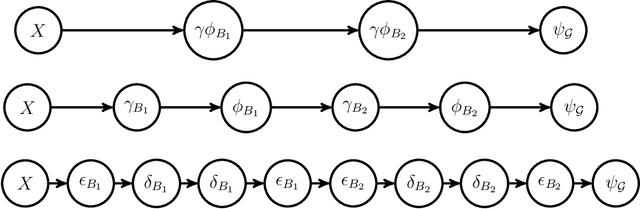
A classical approach to designing binary image operators is Mathematical Morphology (MM). We propose the Discrete Morphological Neural Networks (DMNN) for binary image analysis to represent W-operators and estimate them via machine learning. A DMNN architecture, which is represented by a Morphological Computational Graph, is designed as in the classical heuristic design of morphological operators, in which the designer should combine a set of MM operators and Boolean operations based on prior information and theoretical knowledge. Then, once the architecture is fixed, instead of adjusting its parameters (i.e., structural elements or maximal intervals) by hand, we propose a lattice gradient descent algorithm (LGDA) to train these parameters based on a sample of input and output images under the usual machine learning approach. We also propose a stochastic version of the LGDA that is more efficient, is scalable and can obtain small error in practical problems. The class represented by a DMNN can be quite general or specialized according to expected properties of the target operator, i.e., prior information, and the semantic expressed by algebraic properties of classes of operators is a differential relative to other methods. The main contribution of this paper is the merger of the two main paradigms for designing morphological operators: classical heuristic design and automatic design via machine learning. Thus, conciliating classical heuristic morphological operator design with machine learning. We apply the DMNN to recognize the boundary of digits with noise, and we discuss many topics for future research.
Multi-modal Extreme Classification
Sep 10, 2023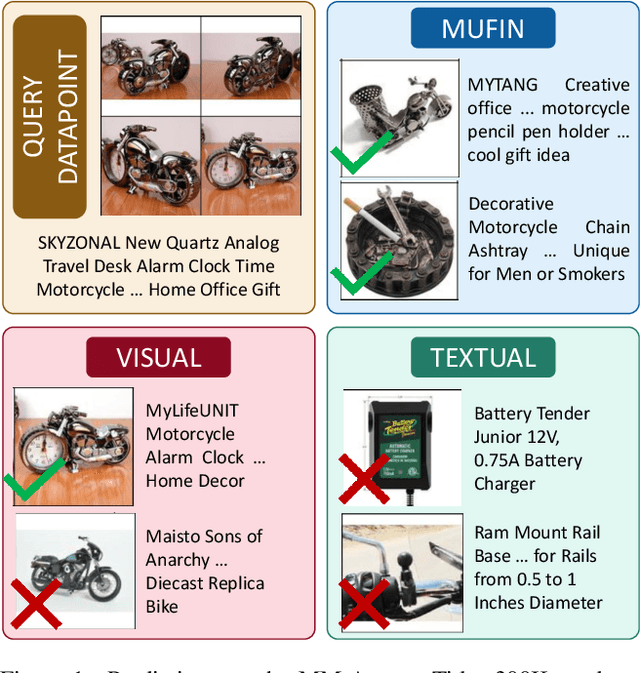

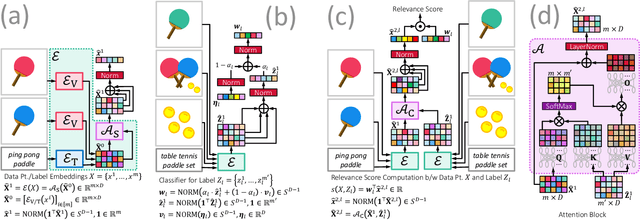
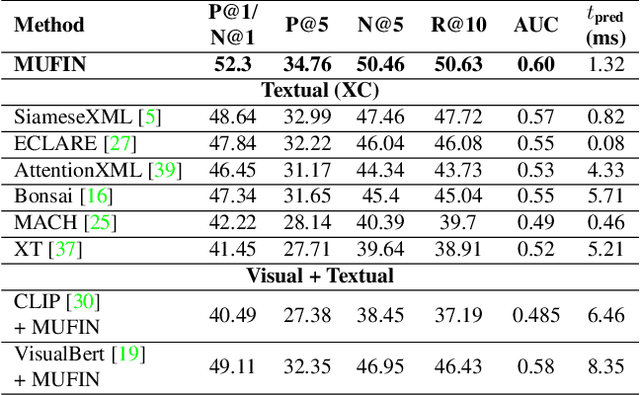
This paper develops the MUFIN technique for extreme classification (XC) tasks with millions of labels where datapoints and labels are endowed with visual and textual descriptors. Applications of MUFIN to product-to-product recommendation and bid query prediction over several millions of products are presented. Contemporary multi-modal methods frequently rely on purely embedding-based methods. On the other hand, XC methods utilize classifier architectures to offer superior accuracies than embedding only methods but mostly focus on text-based categorization tasks. MUFIN bridges this gap by reformulating multi-modal categorization as an XC problem with several millions of labels. This presents the twin challenges of developing multi-modal architectures that can offer embeddings sufficiently expressive to allow accurate categorization over millions of labels; and training and inference routines that scale logarithmically in the number of labels. MUFIN develops an architecture based on cross-modal attention and trains it in a modular fashion using pre-training and positive and negative mining. A novel product-to-product recommendation dataset MM-AmazonTitles-300K containing over 300K products was curated from publicly available amazon.com listings with each product endowed with a title and multiple images. On the all datasets MUFIN offered at least 3% higher accuracy than leading text-based, image-based and multi-modal techniques. Code for MUFIN is available at https://github.com/Extreme-classification/MUFIN
Emotion-Aligned Contrastive Learning Between Images and Music
Aug 24, 2023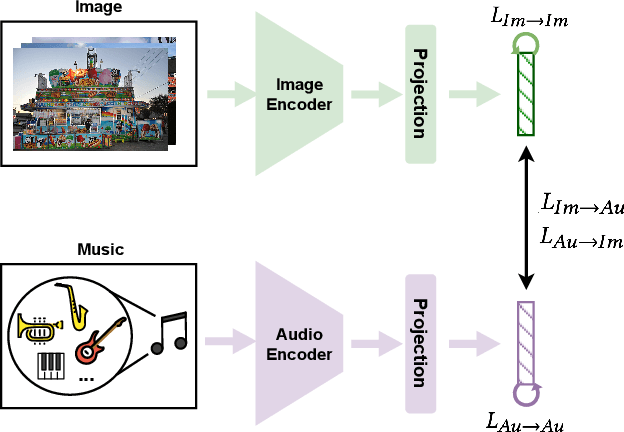



Traditional music search engines rely on retrieval methods that match natural language queries with music metadata. There have been increasing efforts to expand retrieval methods to consider the audio characteristics of music itself, using queries of various modalities including text, video, and speech. Most approaches aim to match general music semantics to the input queries, while only a few focus on affective qualities. We address the task of retrieving emotionally-relevant music from image queries by proposing a framework for learning an affective alignment between images and music audio. Our approach focuses on learning an emotion-aligned joint embedding space between images and music. This joint embedding space is learned via emotion-supervised contrastive learning, using an adapted cross-modal version of the SupCon loss. We directly evaluate the joint embeddings with cross-modal retrieval tasks (image-to-music and music-to-image) based on emotion labels. In addition, we investigate the generalizability of the learned music embeddings with automatic music tagging as a downstream task. Our experiments show that our approach successfully aligns images and music, and that the learned embedding space is effective for cross-modal retrieval applications.
What to Learn: Features, Image Transformations, or Both?
Jun 22, 2023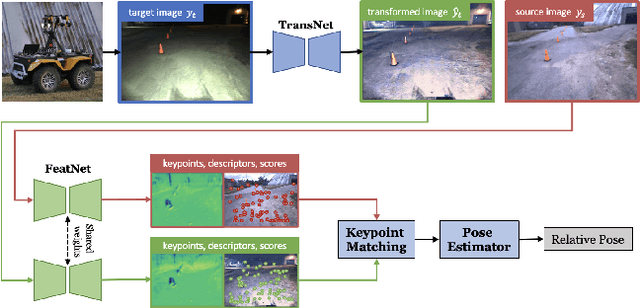
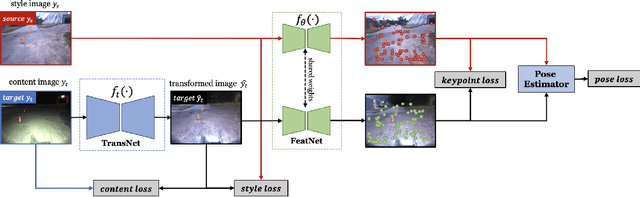

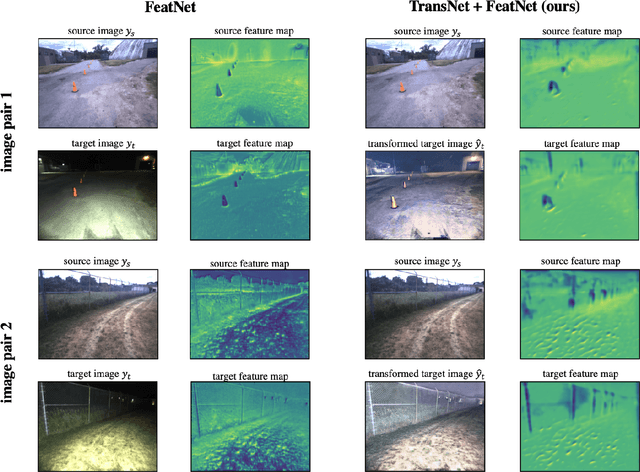
Long-term visual localization is an essential problem in robotics and computer vision, but remains challenging due to the environmental appearance changes caused by lighting and seasons. While many existing works have attempted to solve it by directly learning invariant sparse keypoints and descriptors to match scenes, these approaches still struggle with adverse appearance changes. Recent developments in image transformations such as neural style transfer have emerged as an alternative to address such appearance gaps. In this work, we propose to combine an image transformation network and a feature-learning network to improve long-term localization performance. Given night-to-day image pairs, the image transformation network transforms the night images into day-like conditions prior to feature matching; the feature network learns to detect keypoint locations with their associated descriptor values, which can be passed to a classical pose estimator to compute the relative poses. We conducted various experiments to examine the effectiveness of combining style transfer and feature learning and its training strategy, showing that such a combination greatly improves long-term localization performance.
Selective Scene Text Removal
Sep 01, 2023

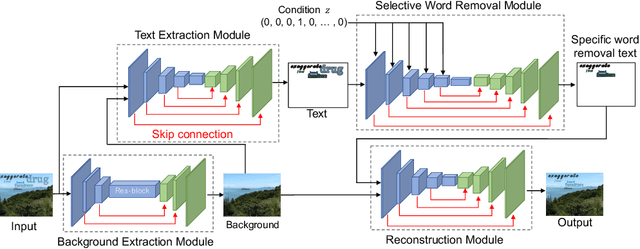

Scene text removal (STR) is the image transformation task to remove text regions in scene images. The conventional STR methods remove all scene text. This means that the existing methods cannot select text to be removed. In this paper, we propose a novel task setting named selective scene text removal (SSTR) that removes only target words specified by the user. Although SSTR is a more complex task than STR, the proposed multi-module structure enables efficient training for SSTR. Experimental results show that the proposed method can remove target words as expected.
NaturalInversion: Data-Free Image Synthesis Improving Real-World Consistency
Jun 29, 2023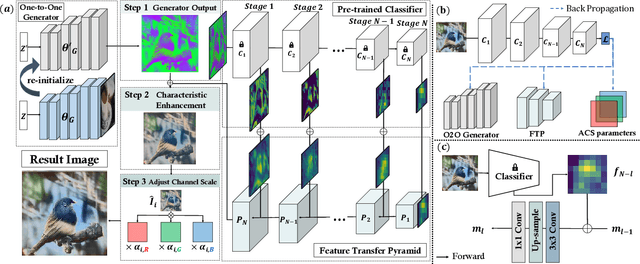
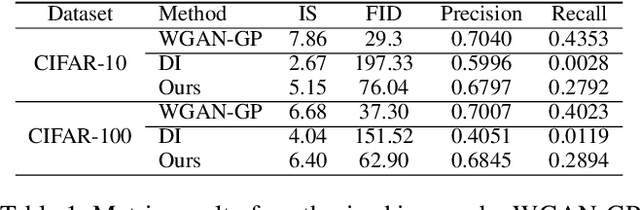

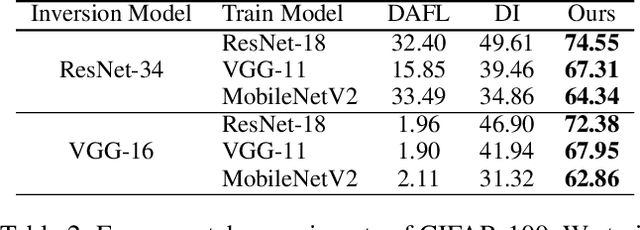
We introduce NaturalInversion, a novel model inversion-based method to synthesize images that agrees well with the original data distribution without using real data. In NaturalInversion, we propose: (1) a Feature Transfer Pyramid which uses enhanced image prior of the original data by combining the multi-scale feature maps extracted from the pre-trained classifier, (2) a one-to-one approach generative model where only one batch of images are synthesized by one generator to bring the non-linearity to optimization and to ease the overall optimizing process, (3) learnable Adaptive Channel Scaling parameters which are end-to-end trained to scale the output image channel to utilize the original image prior further. With our NaturalInversion, we synthesize images from classifiers trained on CIFAR-10/100 and show that our images are more consistent with original data distribution than prior works by visualization and additional analysis. Furthermore, our synthesized images outperform prior works on various applications such as knowledge distillation and pruning, demonstrating the effectiveness of our proposed method.
* Published at AAAI 2022
Contrastive Diffusion Model with Auxiliary Guidance for Coarse-to-Fine PET Reconstruction
Aug 20, 2023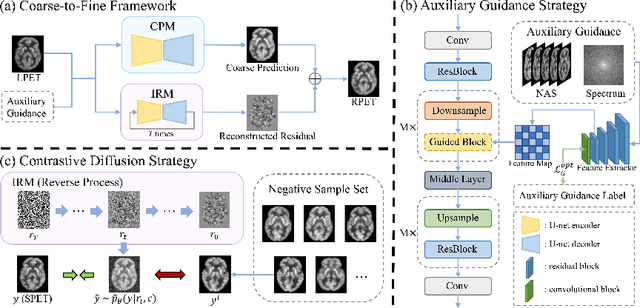
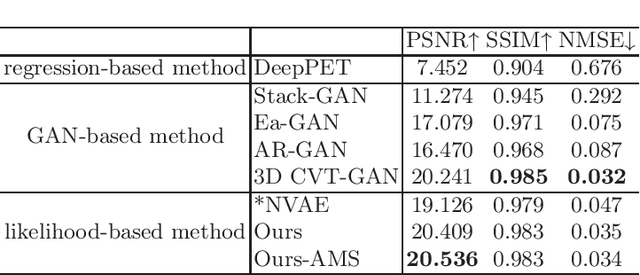
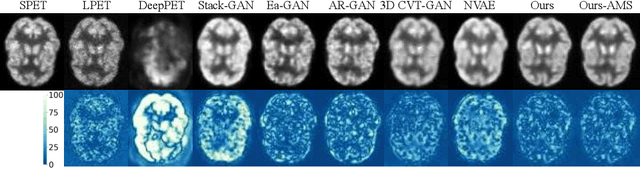
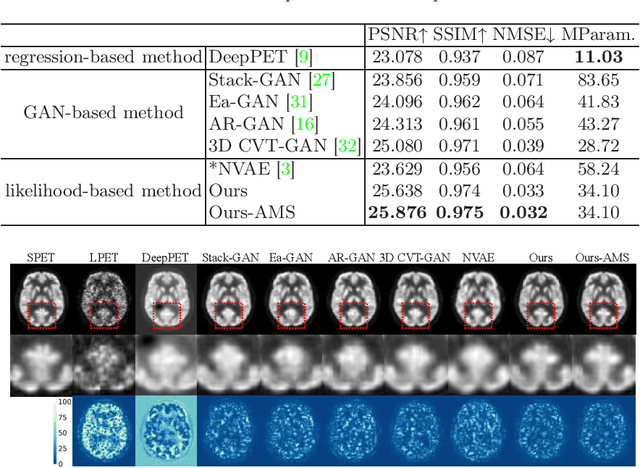
To obtain high-quality positron emission tomography (PET) scans while reducing radiation exposure to the human body, various approaches have been proposed to reconstruct standard-dose PET (SPET) images from low-dose PET (LPET) images. One widely adopted technique is the generative adversarial networks (GANs), yet recently, diffusion probabilistic models (DPMs) have emerged as a compelling alternative due to their improved sample quality and higher log-likelihood scores compared to GANs. Despite this, DPMs suffer from two major drawbacks in real clinical settings, i.e., the computationally expensive sampling process and the insufficient preservation of correspondence between the conditioning LPET image and the reconstructed PET (RPET) image. To address the above limitations, this paper presents a coarse-to-fine PET reconstruction framework that consists of a coarse prediction module (CPM) and an iterative refinement module (IRM). The CPM generates a coarse PET image via a deterministic process, and the IRM samples the residual iteratively. By delegating most of the computational overhead to the CPM, the overall sampling speed of our method can be significantly improved. Furthermore, two additional strategies, i.e., an auxiliary guidance strategy and a contrastive diffusion strategy, are proposed and integrated into the reconstruction process, which can enhance the correspondence between the LPET image and the RPET image, further improving clinical reliability. Extensive experiments on two human brain PET datasets demonstrate that our method outperforms the state-of-the-art PET reconstruction methods. The source code is available at \url{https://github.com/Show-han/PET-Reconstruction}.
Let Segment Anything Help Image Dehaze
Jun 28, 2023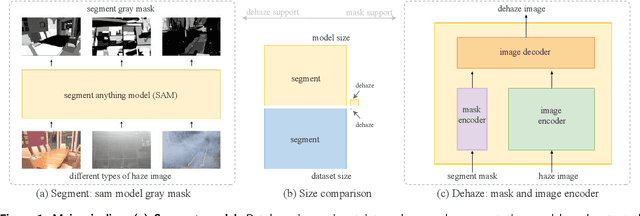
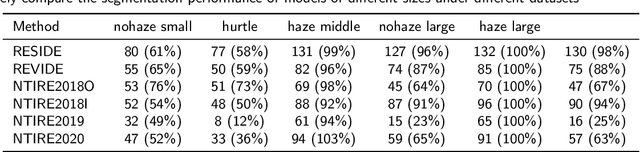

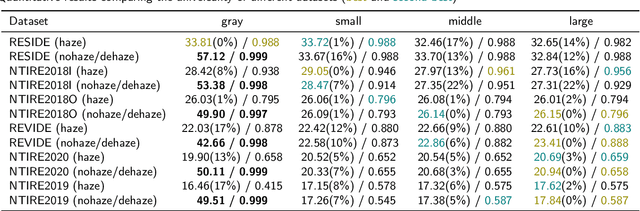
The large language model and high-level vision model have achieved impressive performance improvements with large datasets and model sizes. However, low-level computer vision tasks, such as image dehaze and blur removal, still rely on a small number of datasets and small-sized models, which generally leads to overfitting and local optima. Therefore, we propose a framework to integrate large-model prior into low-level computer vision tasks. Just as with the task of image segmentation, the degradation of haze is also texture-related. So we propose to detect gray-scale coding, network channel expansion, and pre-dehaze structures to integrate large-model prior knowledge into any low-level dehazing network. We demonstrate the effectiveness and applicability of large models in guiding low-level visual tasks through different datasets and algorithms comparison experiments. Finally, we demonstrate the effect of grayscale coding, network channel expansion, and recurrent network structures through ablation experiments. Under the conditions where additional data and training resources are not required, we successfully prove that the integration of large-model prior knowledge will improve the dehaze performance and save training time for low-level visual tasks.
Counting Guidance for High Fidelity Text-to-Image Synthesis
Jun 30, 2023

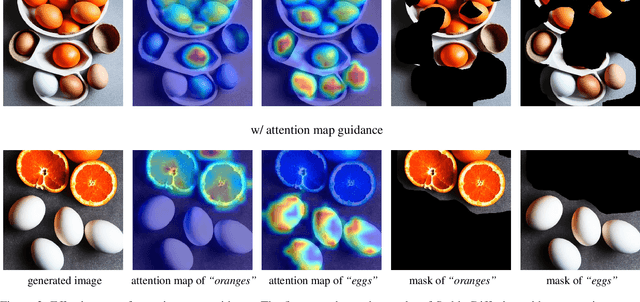

Recently, the quality and performance of text-to-image generation significantly advanced due to the impressive results of diffusion models. However, text-to-image diffusion models still fail to generate high fidelity content with respect to the input prompt. One problem where text-to-diffusion models struggle is generating the exact number of objects specified in the text prompt. E.g. given a prompt "five apples and ten lemons on a table", diffusion-generated images usually contain the wrong number of objects. In this paper, we propose a method to improve diffusion models to focus on producing the correct object count given the input prompt. We adopt a counting network that performs reference-less class-agnostic counting for any given image. We calculate the gradients of the counting network and refine the predicted noise for each step. To handle multiple types of objects in the prompt, we use novel attention map guidance to obtain high-fidelity masks for each object. Finally, we guide the denoising process by the calculated gradients for each object. Through extensive experiments and evaluation, we demonstrate that our proposed guidance method greatly improves the fidelity of diffusion models to object count.