 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image To Image Translation": models, code, and papers
Generating Reliable Pixel-Level Labels for Source Free Domain Adaptation
Jul 03, 2023
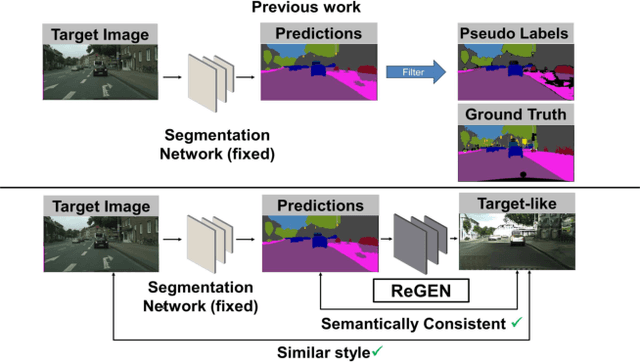

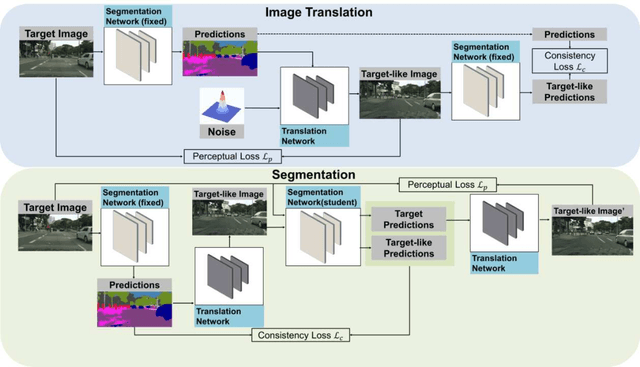
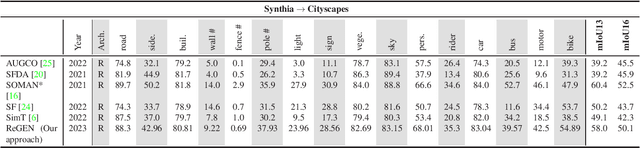
This work addresses the challenging domain adaptation setting in which knowledge from the labelled source domain dataset is available only from the pretrained black-box segmentation model. The pretrained model's predictions for the target domain images are noisy because of the distributional differences between the source domain data and the target domain data. Since the model's predictions serve as pseudo labels during self-training, the noise in the predictions impose an upper bound on model performance. Therefore, we propose a simple yet novel image translation workflow, ReGEN, to address this problem. ReGEN comprises an image-to-image translation network and a segmentation network. Our workflow generates target-like images using the noisy predictions from the original target domain images. These target-like images are semantically consistent with the noisy model predictions and therefore can be used to train the segmentation network. In addition to being semantically consistent with the predictions from the original target domain images, the generated target-like images are also stylistically similar to the target domain images. This allows us to leverage the stylistic differences between the target-like images and the target domain image as an additional source of supervision while training the segmentation model. We evaluate our model with two benchmark domain adaptation settings and demonstrate that our approach performs favourably relative to recent state-of-the-art work. The source code will be made available.
A Semi-Paired Approach For Label-to-Image Translation
Jun 23, 2023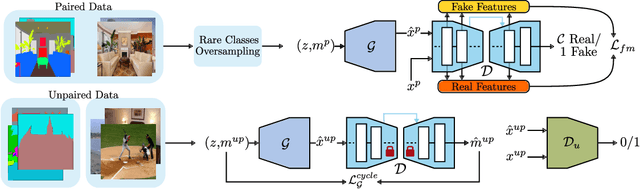
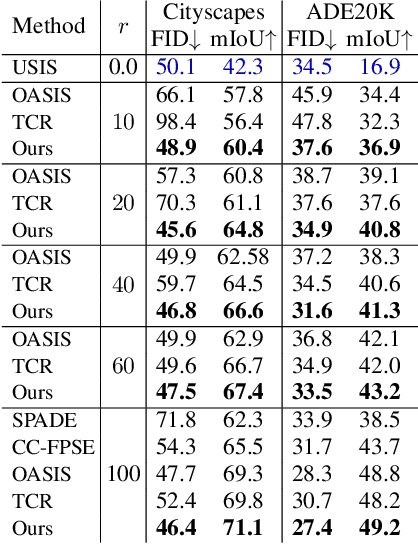

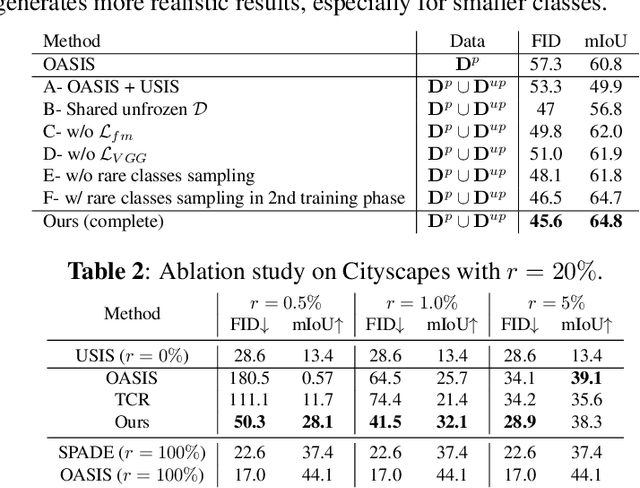
Data efficiency, or the ability to generalize from a few labeled data, remains a major challenge in deep learning. Semi-supervised learning has thrived in traditional recognition tasks alleviating the need for large amounts of labeled data, yet it remains understudied in image-to-image translation (I2I) tasks. In this work, we introduce the first semi-supervised (semi-paired) framework for label-to-image translation, a challenging subtask of I2I which generates photorealistic images from semantic label maps. In the semi-paired setting, the model has access to a small set of paired data and a larger set of unpaired images and labels. Instead of using geometrical transformations as a pretext task like previous works, we leverage an input reconstruction task by exploiting the conditional discriminator on the paired data as a reverse generator. We propose a training algorithm for this shared network, and we present a rare classes sampling algorithm to focus on under-represented classes. Experiments on 3 standard benchmarks show that the proposed model outperforms state-of-the-art unsupervised and semi-supervised approaches, as well as some fully supervised approaches while using a much smaller number of paired samples.
Asymmetric Generative Adversarial Networks for Image-to-Image Translation
Dec 14, 2019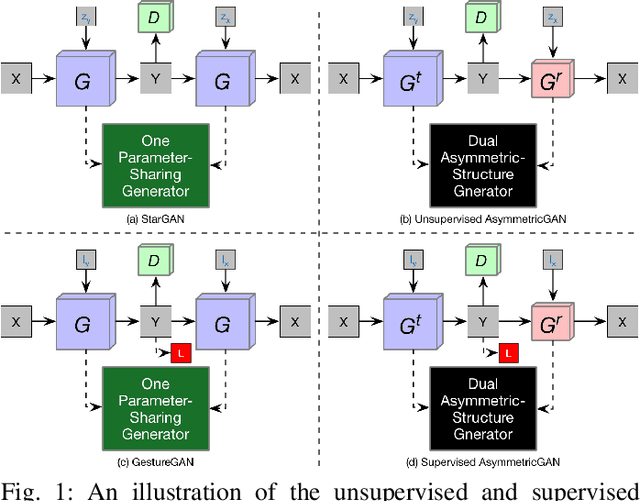

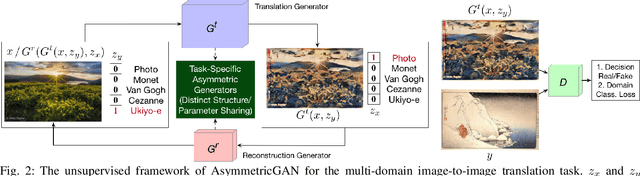

State-of-the-art models for unpaired image-to-image translation with Generative Adversarial Networks (GANs) can learn the mapping from the source domain to the target domain using a cycle-consistency loss. The intuition behind these models is that if we translate from one domain to the other and back again we should arrive at where we started. However, existing methods always adopt a symmetric network architecture to learn both forward and backward cycles. Because of the task complexity and cycle input difference between the source and target image domains, the inequality in bidirectional forward-backward cycle translations is significant and the amount of information between two domains is different. In this paper, we analyze the limitation of the existing symmetric GAN models in asymmetric translation tasks, and propose an AsymmetricGAN model with both translation and reconstruction generators of unequal sizes and different parameter-sharing strategy to adapt to the asymmetric need in both unsupervised and supervised image-to-image translation tasks. Moreover, the training stage of existing methods has the common problem of model collapse that degrades the quality of the generated images, thus we explore different optimization losses for better training of AsymmetricGAN, and thus make image-to-image translation with higher consistency and better stability. Extensive experiments on both supervised and unsupervised generative tasks with several publicly available datasets demonstrate that the proposed AsymmetricGAN achieves superior model capacity and better generation performance compared with existing GAN models. To the best of our knowledge, we are the first to investigate the asymmetric GAN framework on both unsupervised and supervised image-to-image translation tasks. The source code, data and trained models are available at https://github.com/Ha0Tang/AsymmetricGAN.
Panoptic-based Object Style-Align for Image-to-Image Translation
Dec 03, 2021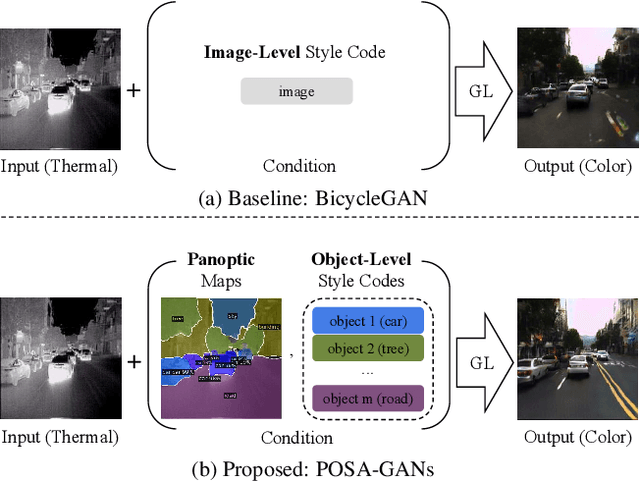

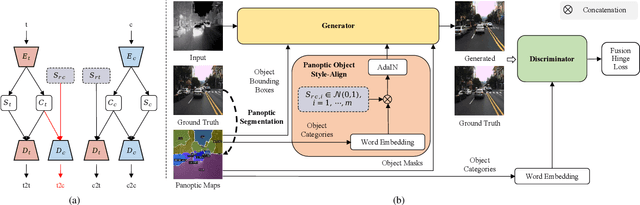
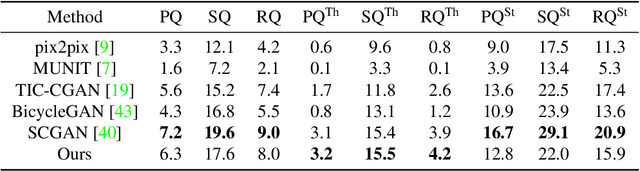
Despite remarkable recent progress in image translation, the complex scene with multiple discrepant objects remains a challenging problem. Because the translated images have low fidelity and tiny objects in fewer details and obtain unsatisfactory performance in object recognition. Without the thorough object perception (i.e., bounding boxes, categories, and masks) of the image as prior knowledge, the style transformation of each object will be difficult to track in the image translation process. We propose panoptic-based object style-align generative adversarial networks (POSA-GANs) for image-to-image translation together with a compact panoptic segmentation dataset. The panoptic segmentation model is utilized to extract panoptic-level perception (i.e., overlap-removed foreground object instances and background semantic regions in the image). This is utilized to guide the alignment between the object content codes of the input domain image and object style codes sampled from the style space of the target domain. The style-aligned object representations are further transformed to obtain precise boundaries layout for higher fidelity object generation. The proposed method was systematically compared with different competing methods and obtained significant improvement on both image quality and object recognition performance for translated images.
A Novel Framework for Image-to-image Translation and Image Compression
Nov 25, 2021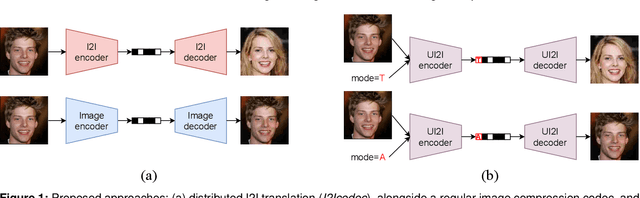
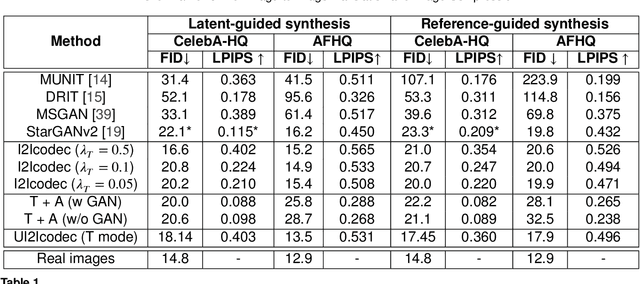
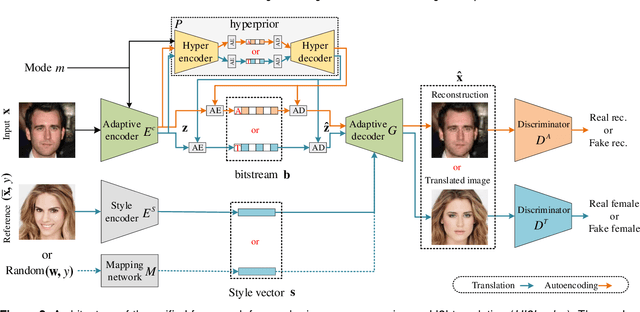

Data-driven paradigms using machine learning are becoming ubiquitous in image processing and communications. In particular, image-to-image (I2I) translation is a generic and widely used approach to image processing problems, such as image synthesis, style transfer, and image restoration. At the same time, neural image compression has emerged as a data-driven alternative to traditional coding approaches in visual communications. In this paper, we study the combination of these two paradigms into a joint I2I compression and translation framework, focusing on multi-domain image synthesis. We first propose distributed I2I translation by integrating quantization and entropy coding into an I2I translation framework (i.e. I2Icodec). In practice, the image compression functionality (i.e. autoencoding) is also desirable, requiring to deploy alongside I2Icodec a regular image codec. Thus, we further propose a unified framework that allows both translation and autoencoding capabilities in a single codec. Adaptive residual blocks conditioned on the translation/compression mode provide flexible adaptation to the desired functionality. The experiments show promising results in both I2I translation and image compression using a single model.
Unpaired Image-to-Image Translation using Adversarial Consistency Loss
Mar 10, 2020

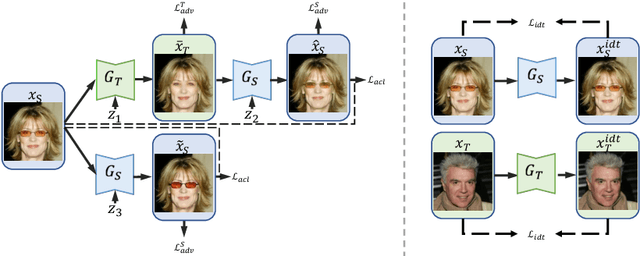
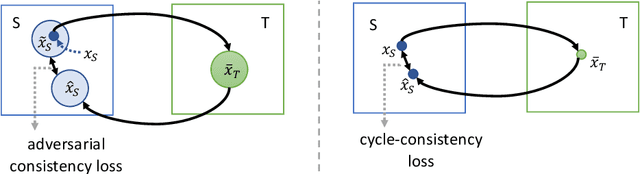
Unpaired image-to-image translation is a class of vision problems whose goal is to find the mapping between different image domains using unpaired training data. Cycle-consistency loss is a widely used constraint for such problems. However, due to the strict pixel-level constraint, it cannot perform geometric changes, remove large objects, or ignore irrelevant texture. In this paper, we propose a novel adversarial-consistency loss for image-to-image translation. This loss does not require the translated image to be translated back to be a specific source image but can encourage the translated images to retain important features of the source images and overcome the drawbacks of cycle-consistency loss noted above. Our method achieves state-of-the-art results on three challenging tasks: glasses removal, male-to-female translation, and selfie-to-anime translation.
Unsupervised Image-to-Image Translation Networks
Jul 23, 2018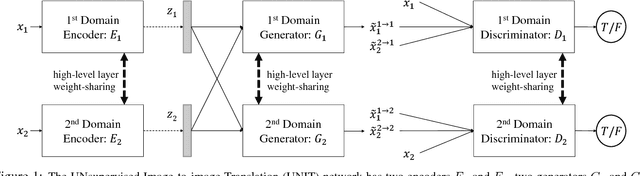


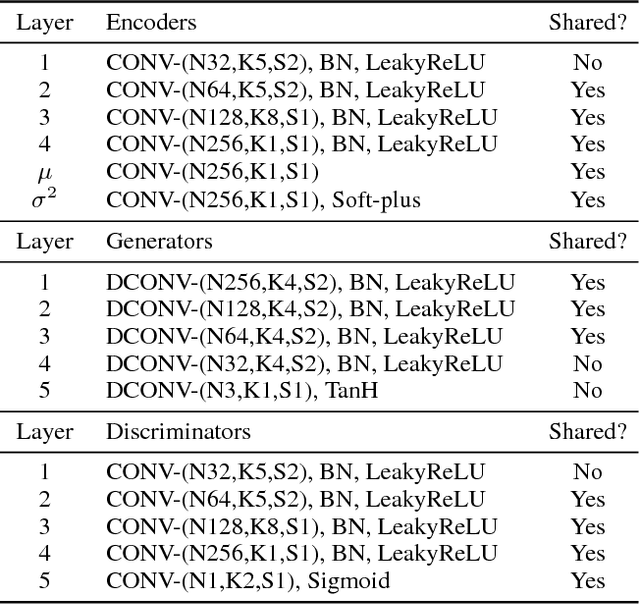
Unsupervised image-to-image translation aims at learning a joint distribution of images in different domains by using images from the marginal distributions in individual domains. Since there exists an infinite set of joint distributions that can arrive the given marginal distributions, one could infer nothing about the joint distribution from the marginal distributions without additional assumptions. To address the problem, we make a shared-latent space assumption and propose an unsupervised image-to-image translation framework based on Coupled GANs. We compare the proposed framework with competing approaches and present high quality image translation results on various challenging unsupervised image translation tasks, including street scene image translation, animal image translation, and face image translation. We also apply the proposed framework to domain adaptation and achieve state-of-the-art performance on benchmark datasets. Code and additional results are available in https://github.com/mingyuliutw/unit .
Filtered-Guided Diffusion: Fast Filter Guidance for Black-Box Diffusion Models
Jun 29, 2023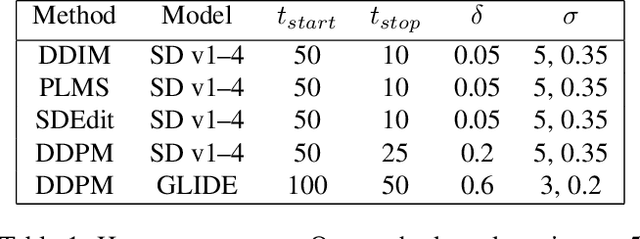


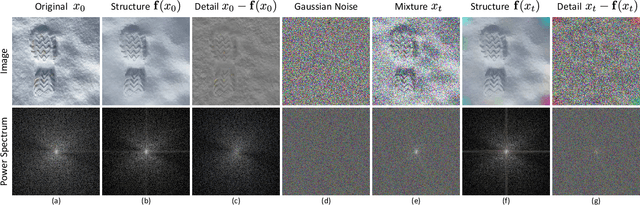
Recent advances in diffusion-based generative models have shown incredible promise for Image-to-Image translation and editing. Most recent work in this space relies on additional training or architecture-specific adjustments to the diffusion process. In this work, we show that much of this low-level control can be achieved without additional training or any access to features of the diffusion model. Our method simply applies a filter to the input of each diffusion step based on the output of the previous step in an adaptive manner. Notably, this approach does not depend on any specific architecture or sampler and can be done without access to internal features of the network, making it easy to combine with other techniques, samplers, and diffusion architectures. Furthermore, it has negligible cost to performance, and allows for more continuous adjustment of guidance strength than other approaches. We show FGD offers a fast and strong baseline that is competitive with recent architecture-dependent approaches. Furthermore, FGD can also be used as a simple add-on to enhance the structural guidance of other state-of-the-art I2I methods. Finally, our derivation of this method helps to understand the impact of self attention, a key component of other recent architecture-specific I2I approaches, in a more architecture-independent way. Project page: https://github.com/jaclyngu/FilteredGuidedDiffusion
Memory-guided Unsupervised Image-to-image Translation
Apr 12, 2021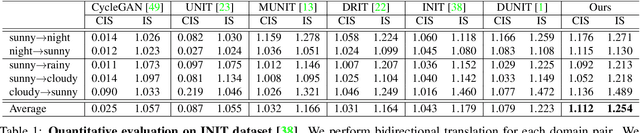
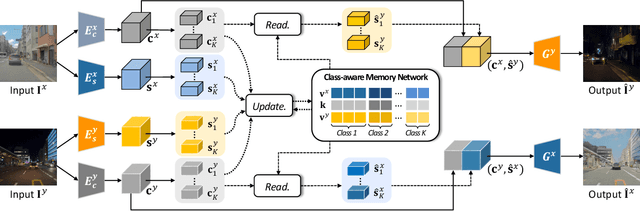
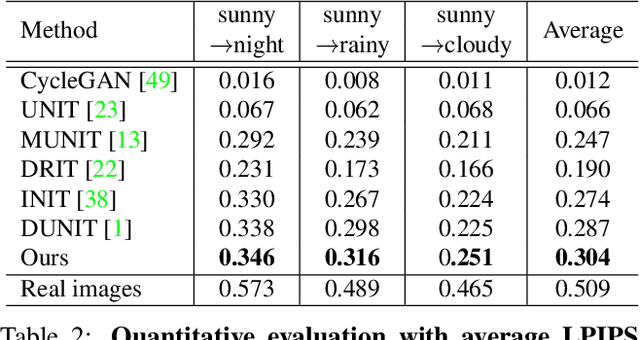
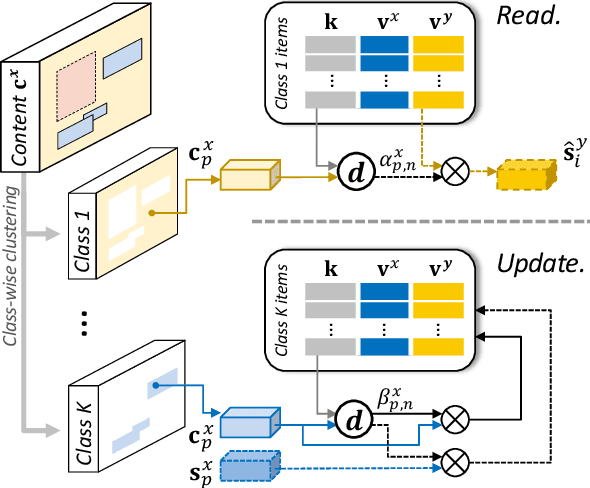
We present a novel unsupervised framework for instance-level image-to-image translation. Although recent advances have been made by incorporating additional object annotations, existing methods often fail to handle images with multiple disparate objects. The main cause is that, during inference, they apply a global style to the whole image and do not consider the large style discrepancy between instance and background, or within instances. To address this problem, we propose a class-aware memory network that explicitly reasons about local style variations. A key-values memory structure, with a set of read/update operations, is introduced to record class-wise style variations and access them without requiring an object detector at the test time. The key stores a domain-agnostic content representation for allocating memory items, while the values encode domain-specific style representations. We also present a feature contrastive loss to boost the discriminative power of memory items. We show that by incorporating our memory, we can transfer class-aware and accurate style representations across domains. Experimental results demonstrate that our model outperforms recent instance-level methods and achieves state-of-the-art performance.
Few-Shot Unsupervised Image-to-Image Translation
May 05, 2019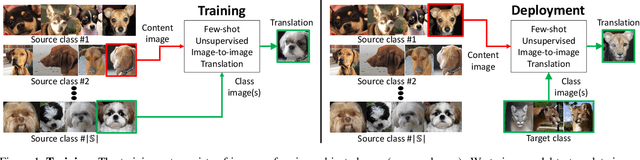
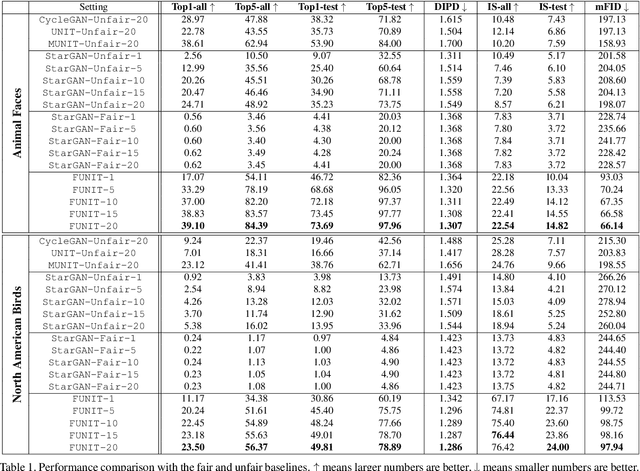


Unsupervised image-to-image translation methods learn to map images in a given class to an analogous image in a different class, drawing on unstructured (non-registered) datasets of images. While remarkably successful, current methods require access to many images in both source and destination classes at training time. We argue this greatly limits their use. Drawing inspiration from the human capability of picking up the essence of a novel object from a small number of examples and generalizing from there, we seek a few-shot, unsupervised image-to-image translation algorithm that works on previously unseen target classes that are specified, at test time, only by a few example images. Our model achieves this few-shot generation capability by coupling an adversarial training scheme with a novel network design. Through extensive experimental validation and comparisons to several baseline methods on benchmark datasets, we verify the effectiveness of the proposed framework. Code will be available at https://nvlabs.github.io/FUNIT .