 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image To Image Translation": models, code, and papers
Generative Diffusion Models on Graphs: Methods and Applications
Feb 06, 2023

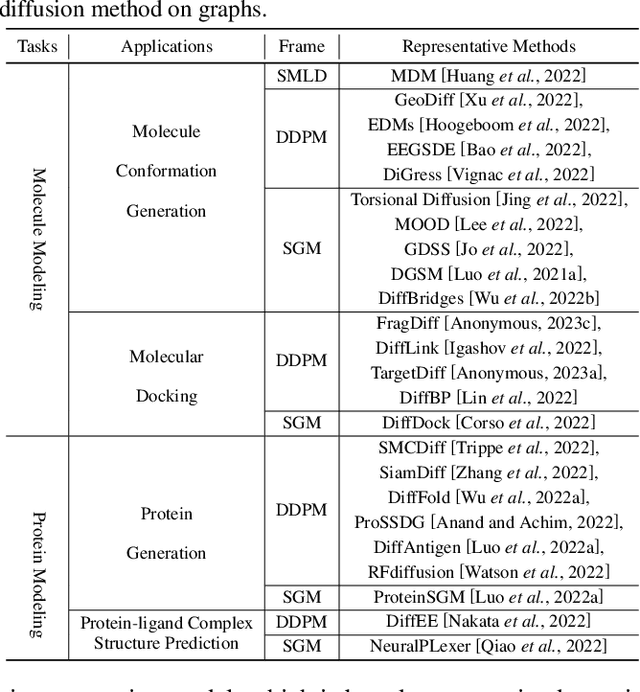
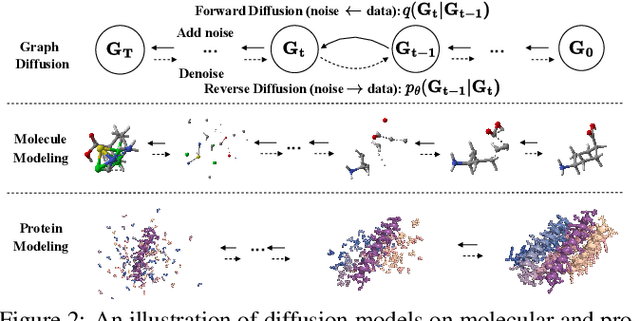
Diffusion models, as a novel generative paradigm, have achieved remarkable success in various image generation tasks such as image inpainting, image-to-text translation, and video generation. Graph generation is a crucial computational task on graphs with numerous real-world applications. It aims to learn the distribution of given graphs and then generate new graphs. Given the great success of diffusion models in image generation, increasing efforts have been made to leverage these techniques to advance graph generation in recent years. In this paper, we first provide a comprehensive overview of generative diffusion models on graphs, In particular, we review representative algorithms for three variants of graph diffusion models, i.e., Score Matching with Langevin Dynamics (SMLD), Denoising Diffusion Probabilistic Model (DDPM), and Score-based Generative Model (SGM). Then, we summarize the major applications of generative diffusion models on graphs with a specific focus on molecule and protein modeling. Finally, we discuss promising directions in generative diffusion models on graph-structured data.
Unifying Diffusion Models' Latent Space, with Applications to CycleDiffusion and Guidance
Oct 11, 2022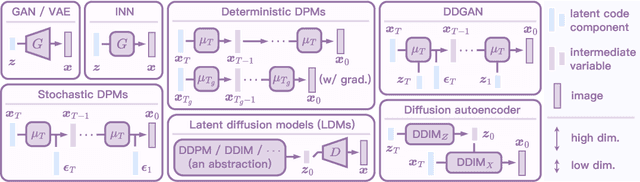



Diffusion models have achieved unprecedented performance in generative modeling. The commonly-adopted formulation of the latent code of diffusion models is a sequence of gradually denoised samples, as opposed to the simpler (e.g., Gaussian) latent space of GANs, VAEs, and normalizing flows. This paper provides an alternative, Gaussian formulation of the latent space of various diffusion models, as well as an invertible DPM-Encoder that maps images into the latent space. While our formulation is purely based on the definition of diffusion models, we demonstrate several intriguing consequences. (1) Empirically, we observe that a common latent space emerges from two diffusion models trained independently on related domains. In light of this finding, we propose CycleDiffusion, which uses DPM-Encoder for unpaired image-to-image translation. Furthermore, applying CycleDiffusion to text-to-image diffusion models, we show that large-scale text-to-image diffusion models can be used as zero-shot image-to-image editors. (2) One can guide pre-trained diffusion models and GANs by controlling the latent codes in a unified, plug-and-play formulation based on energy-based models. Using the CLIP model and a face recognition model as guidance, we demonstrate that diffusion models have better coverage of low-density sub-populations and individuals than GANs.
DASH: Visual Analytics for Debiasing Image Classification via User-Driven Synthetic Data Augmentation
Sep 14, 2022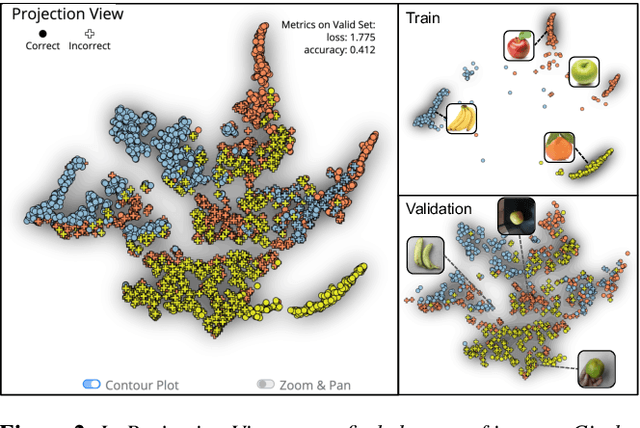
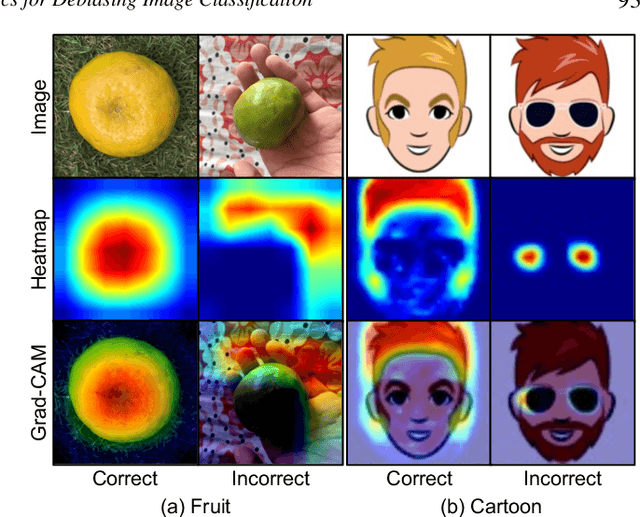
Image classification models often learn to predict a class based on irrelevant co-occurrences between input features and an output class in training data. We call the unwanted correlations "data biases," and the visual features causing data biases "bias factors." It is challenging to identify and mitigate biases automatically without human intervention. Therefore, we conducted a design study to find a human-in-the-loop solution. First, we identified user tasks that capture the bias mitigation process for image classification models with three experts. Then, to support the tasks, we developed a visual analytics system called DASH that allows users to visually identify bias factors, to iteratively generate synthetic images using a state-of-the-art image-to-image translation model, and to supervise the model training process for improving the classification accuracy. Our quantitative evaluation and qualitative study with ten participants demonstrate the usefulness of DASH and provide lessons for future work.
CycleGAN with three different unpaired datasets
Aug 12, 2022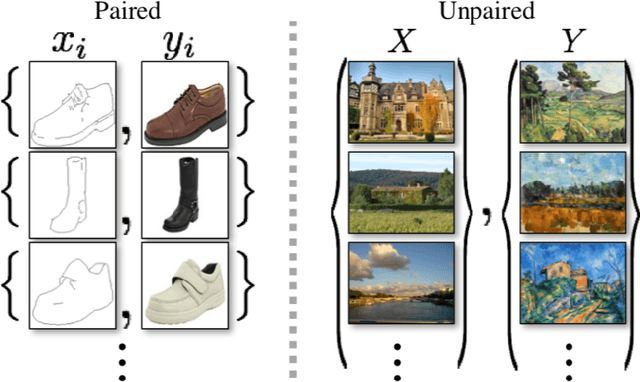


The original publication Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks served as the inspiration for this implementation project. Researchers developed a novel method for doing image-to-image translations using an unpaired dataset in the original study. Despite the fact that the pix2pix models findings are good, the matched dataset is frequently not available. In the absence of paired data, cycleGAN can therefore get over this issue by converting images to images. In order to lessen the difference between the images, they implemented cycle consistency loss.I evaluated CycleGAN with three different datasets, and this paper briefly discusses the findings and conclusions.
Exploring Patch-wise Semantic Relation for Contrastive Learning in Image-to-Image Translation Tasks
Mar 03, 2022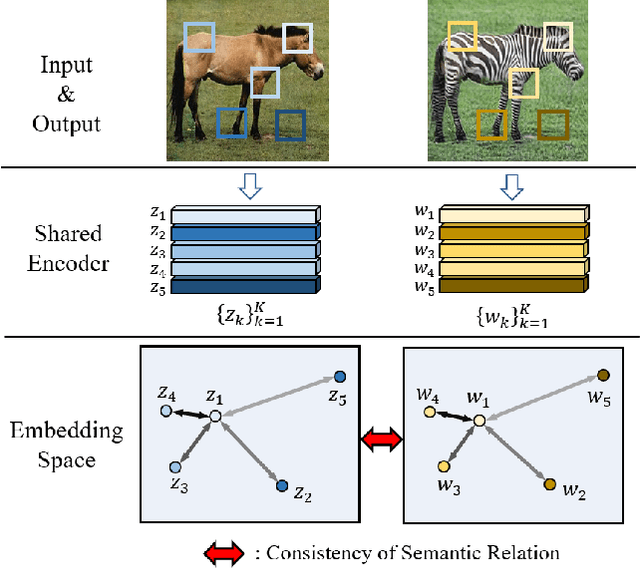
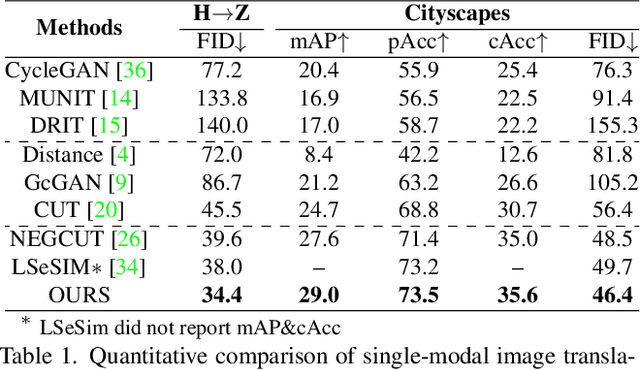
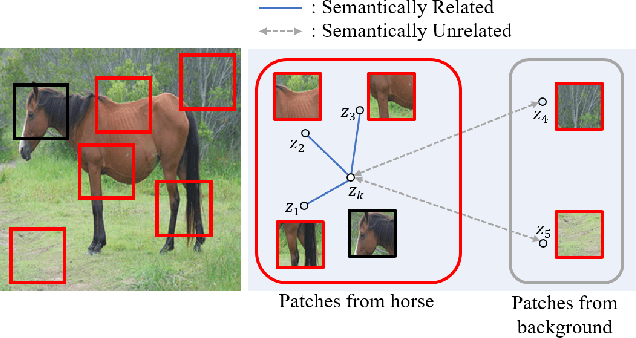
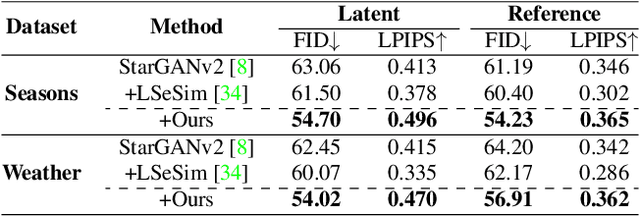
Recently, contrastive learning-based image translation methods have been proposed, which contrasts different spatial locations to enhance the spatial correspondence. However, the methods often ignore the diverse semantic relation within the images. To address this, here we propose a novel semantic relation consistency (SRC) regularization along with the decoupled contrastive learning, which utilize the diverse semantics by focusing on the heterogeneous semantics between the image patches of a single image. To further improve the performance, we present a hard negative mining by exploiting the semantic relation. We verified our method for three tasks: single-modal and multi-modal image translations, and GAN compression task for image translation. Experimental results confirmed the state-of-art performance of our method in all the three tasks.
Digital twins of physical printing-imaging channel
Oct 28, 2022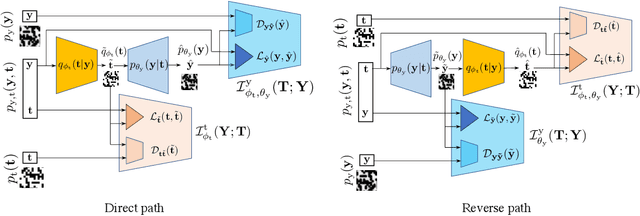
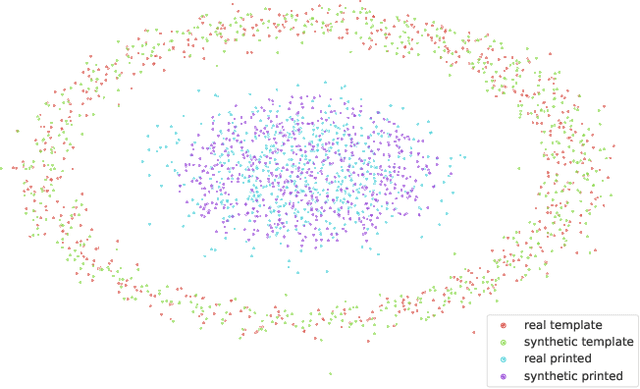
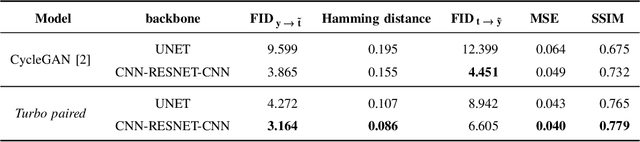
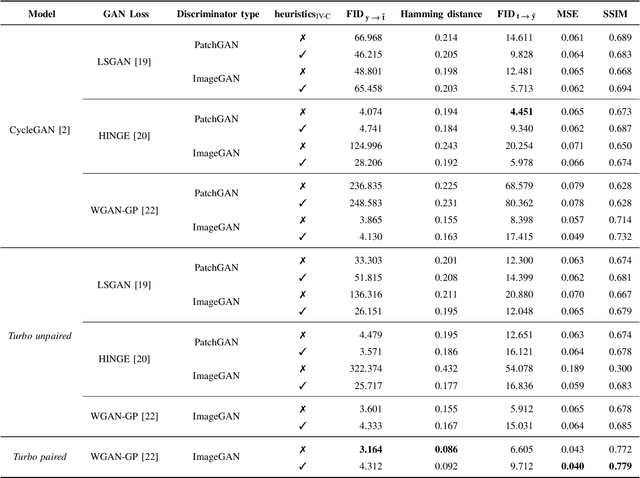
In this paper, we address the problem of modeling a printing-imaging channel built on a machine learning approach a.k.a. digital twin for anti-counterfeiting applications based on copy detection patterns (CDP). The digital twin is formulated on an information-theoretic framework called Turbo that uses variational approximations of mutual information developed for both encoder and decoder in a two-directional information passage. The proposed model generalizes several state-of-the-art architectures such as adversarial autoencoder (AAE), CycleGAN and adversarial latent space autoencoder (ALAE). This model can be applied to any type of printing and imaging and it only requires training data consisting of digital templates or artworks that are sent to a printing device and data acquired by an imaging device. Moreover, these data can be paired, unpaired or hybrid paired-unpaired which makes the proposed architecture very flexible and scalable to many practical setups. We demonstrate the impact of various architectural factors, metrics and discriminators on the overall system performance in the task of generation/prediction of printed CDP from their digital counterparts and vice versa. We also compare the proposed system with several state-of-the-art methods used for image-to-image translation applications.
XDGAN: Multi-Modal 3D Shape Generation in 2D Space
Oct 06, 2022

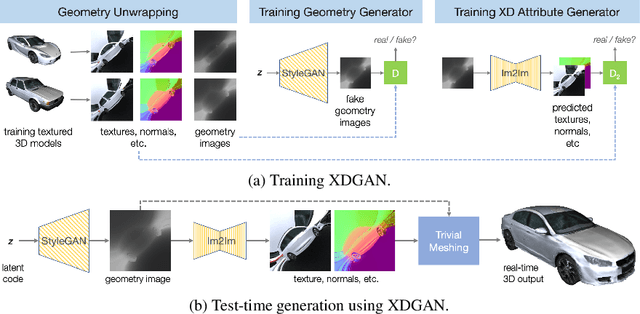
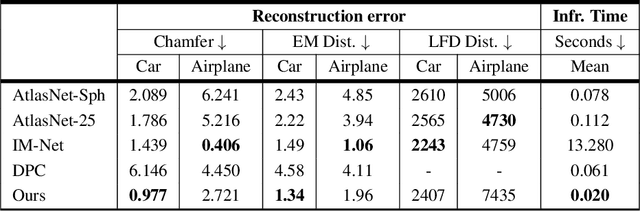
Generative models for 2D images has recently seen tremendous progress in quality, resolution and speed as a result of the efficiency of 2D convolutional architectures. However it is difficult to extend this progress into the 3D domain since most current 3D representations rely on custom network components. This paper addresses a central question: Is it possible to directly leverage 2D image generative models to generate 3D shapes instead? To answer this, we propose XDGAN, an effective and fast method for applying 2D image GAN architectures to the generation of 3D object geometry combined with additional surface attributes, like color textures and normals. Specifically, we propose a novel method to convert 3D shapes into compact 1-channel geometry images and leverage StyleGAN3 and image-to-image translation networks to generate 3D objects in 2D space. The generated geometry images are quick to convert to 3D meshes, enabling real-time 3D object synthesis, visualization and interactive editing. Moreover, the use of standard 2D architectures can help bring more 2D advances into the 3D realm. We show both quantitatively and qualitatively that our method is highly effective at various tasks such as 3D shape generation, single view reconstruction and shape manipulation, while being significantly faster and more flexible compared to recent 3D generative models.
Deceiving Image-to-Image Translation Networks for Autonomous Driving with Adversarial Perturbations
Jan 06, 2020
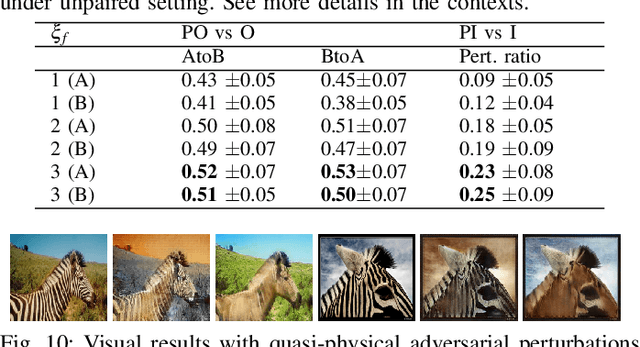
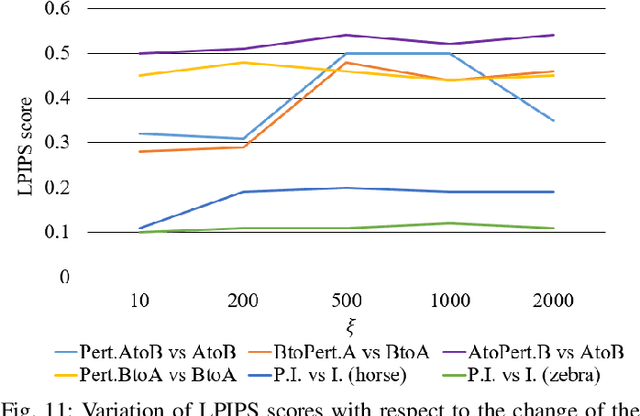
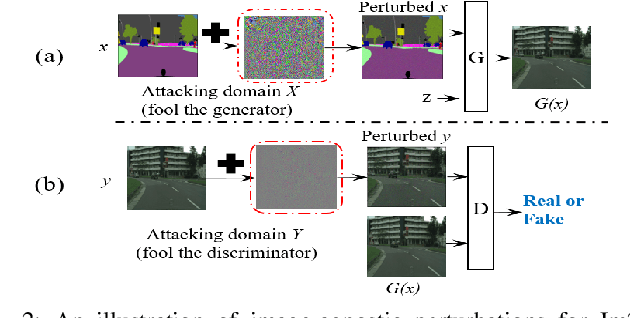
Deep neural networks (DNNs) have achieved impressive performance on handling computer vision problems, however, it has been found that DNNs are vulnerable to adversarial examples. For such reason, adversarial perturbations have been recently studied in several respects. However, most previous works have focused on image classification tasks, and it has never been studied regarding adversarial perturbations on Image-to-image (Im2Im) translation tasks, showing great success in handling paired and/or unpaired mapping problems in the field of autonomous driving and robotics. This paper examines different types of adversarial perturbations that can fool Im2Im frameworks for autonomous driving purpose. We propose both quasi-physical and digital adversarial perturbations that can make Im2Im models yield unexpected results. We then empirically analyze these perturbations and show that they generalize well under both paired for image synthesis and unpaired settings for style transfer. We also validate that there exist some perturbation thresholds over which the Im2Im mapping is disrupted or impossible. The existence of these perturbations reveals that there exist crucial weaknesses in Im2Im models. Lastly, we show that our methods illustrate how perturbations affect the quality of outputs, pioneering the improvement of the robustness of current SOTA networks for autonomous driving.
What can we learn about a generated image corrupting its latent representation?
Oct 12, 2022Generative adversarial networks (GANs) offer an effective solution to the image-to-image translation problem, thereby allowing for new possibilities in medical imaging. They can translate images from one imaging modality to another at a low cost. For unpaired datasets, they rely mostly on cycle loss. Despite its effectiveness in learning the underlying data distribution, it can lead to a discrepancy between input and output data. The purpose of this work is to investigate the hypothesis that we can predict image quality based on its latent representation in the GANs bottleneck. We achieve this by corrupting the latent representation with noise and generating multiple outputs. The degree of differences between them is interpreted as the strength of the representation: the more robust the latent representation, the fewer changes in the output image the corruption causes. Our results demonstrate that our proposed method has the ability to i) predict uncertain parts of synthesized images, and ii) identify samples that may not be reliable for downstream tasks, e.g., liver segmentation task.
CoMoGAN: continuous model-guided image-to-image translation
Apr 08, 2021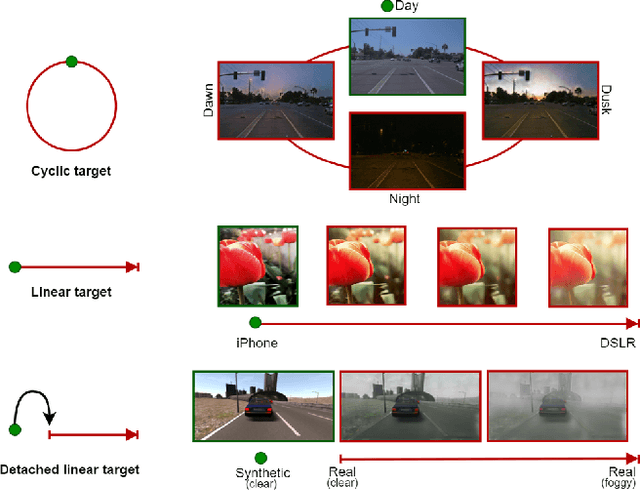

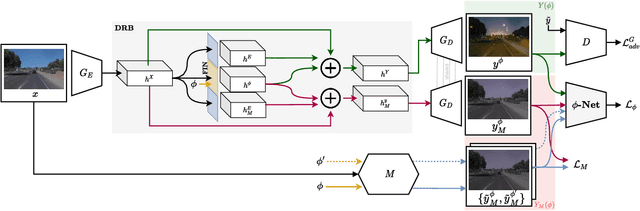
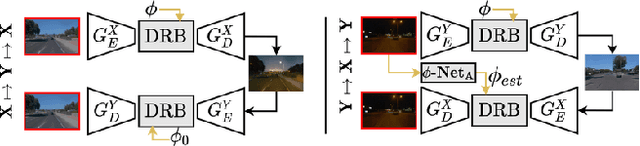
CoMoGAN is a continuous GAN relying on the unsupervised reorganization of the target data on a functional manifold. To that matter, we introduce a new Functional Instance Normalization layer and residual mechanism, which together disentangle image content from position on target manifold. We rely on naive physics-inspired models to guide the training while allowing private model/translations features. CoMoGAN can be used with any GAN backbone and allows new types of image translation, such as cyclic image translation like timelapse generation, or detached linear translation. On all datasets, it outperforms the literature. Our code is available at http://github.com/cv-rits/CoMoGAN .