 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForcingDAS: Unified and Robust Data Assimilation via Diffusion Forcing
May 14, 2026Data assimilation (DA) estimates the state of an evolving dynamical system from noisy, partial observations, and is widely used in scientific simulation as well as weather and climate science. In practice, filtering methods rely on frame-to-frame transition models. However, these models are fragile when observations are non-Markovian (when they form only a partial slice of a higher-dimensional latent state as in real-world weather data): they tend to accumulate errors over long horizons. At the same time, learned DA methods typically commit to a single regime, either filtering (nowcasting, real-time forecasting) or smoothing (retrospective reanalysis), which splits what should be a shared prior across application-specific pipelines. To address both issues, we introduce ForcingDAS, a unified and robust DA framework. Built on Diffusion Forcing with an independent noise level assigned to each frame, ForcingDAS learns a joint-trajectory prior instead of frame-to-frame transitions. This allows it to capture long-horizon temporal dependencies and reduce error accumulation. In addition, the same trained model spans the full filtering to smoothing spectrum at inference time. Specifically, nowcasting, fixed-lag smoothing, and batch reanalysis are selected through the inference schedule alone, without retraining. We evaluate ForcingDAS on 2D Navier-Stokes vorticity, precipitation nowcasting, and global atmospheric state estimation. Across all settings, a single model is competitive with or outperforms both learned and classical baselines that are specialized for individual regimes, with the largest gains observed on real-world weather benchmarks.
LoREnc: Low-Rank Encryption for Securing Foundation Models and LoRA Adapters
May 13, 2026Foundation models and low-rank adapters enable efficient on-device generative AI but raise risks such as intellectual property leakage and model recovery attacks. Existing defenses are often impractical because they require retraining or access to the original dataset. We propose LoREnc, a training-free framework that secures both FMs and adapters via spectral truncation and compensation. LoREnc suppresses dominant low-rank components of FM weights, compensates for the missing information in authorized adapters, and further applies orthogonal reparameterization to obscure structural fingerprints of the protected adapter. Unauthorized users produce structurally collapsed outputs, while authorized users recover exact performance. Experiments demonstrate that LoREnc provides strong protection against model recovery with under 1% computational overhead.
Patch-wise Graph Contrastive Learning for Image Translation
Dec 13, 2023



Recently, patch-wise contrastive learning is drawing attention for the image translation by exploring the semantic correspondence between the input and output images. To further explore the patch-wise topology for high-level semantic understanding, here we exploit the graph neural network to capture the topology-aware features. Specifically, we construct the graph based on the patch-wise similarity from a pretrained encoder, whose adjacency matrix is shared to enhance the consistency of patch-wise relation between the input and the output. Then, we obtain the node feature from the graph neural network, and enhance the correspondence between the nodes by increasing mutual information using the contrastive loss. In order to capture the hierarchical semantic structure, we further propose the graph pooling. Experimental results demonstrate the state-of-art results for the image translation thanks to the semantic encoding by the constructed graphs.
Self-supervised debiasing using low rank regularization
Oct 11, 2022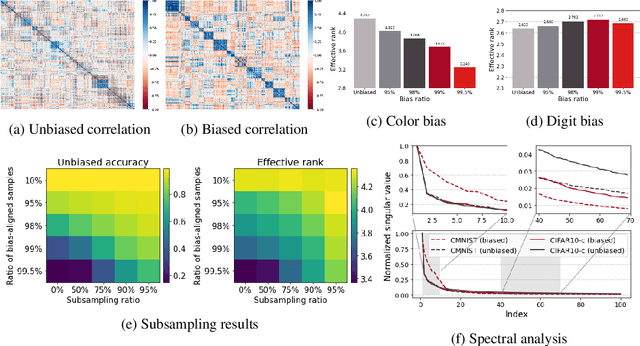

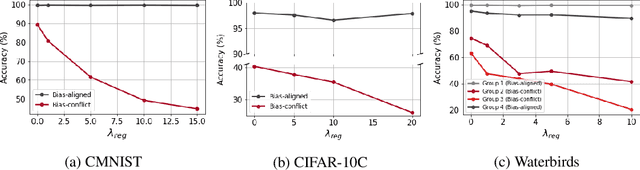
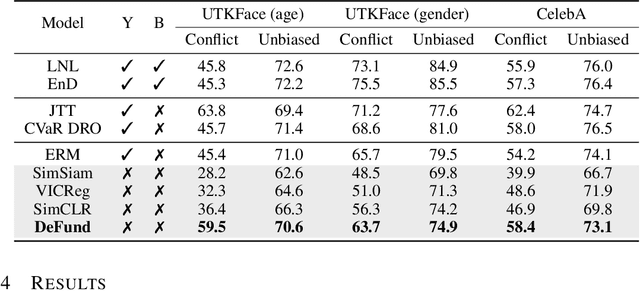
Spurious correlations can cause strong biases in deep neural networks, impairing generalization ability. While most of existing debiasing methods require full supervisions on either spurious attributes or target labels, training a debiased model from a limited amount of both annotations is still an open issue. To overcome such limitations, we first examined an interesting phenomenon by the spectral analysis of latent representations: spuriously correlated, easy-to-learn attributes make neural networks inductively biased towards encoding lower effective rank representations. We also show that a rank regularization can amplify this bias in a way that encourages highly correlated features. Motivated by these observations, we propose a self-supervised debiasing framework that is potentially compatible with unlabeled samples. We first pretrain a biased encoder in a self-supervised manner with the rank regularization, serving as a semantic bottleneck to enforce the encoder to learn the spuriously correlated attributes. This biased encoder is then used to discover and upweight bias-conflicting samples in a downstream task, serving as a boosting to effectively debias the main model. Remarkably, the proposed debiasing framework significantly improves the generalization performance of self-supervised learning baselines and, in some cases, even outperforms state-of-the-art supervised debiasing approaches.
Patch-wise Deep Metric Learning for Unsupervised Low-Dose CT Denoising
Jul 14, 2022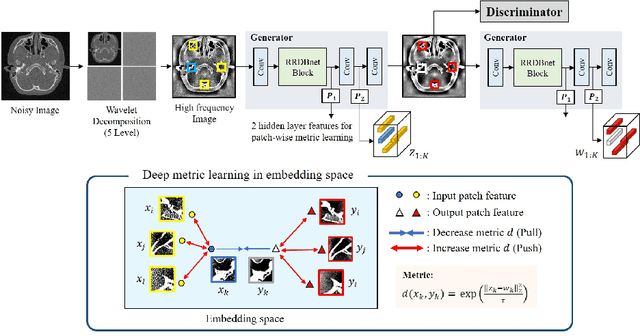

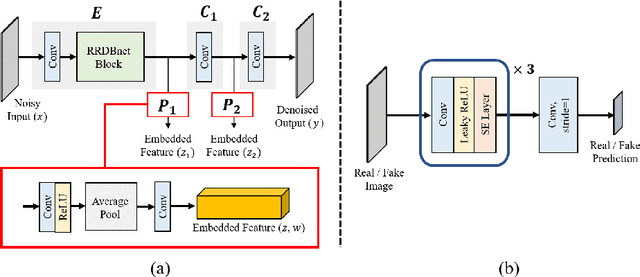
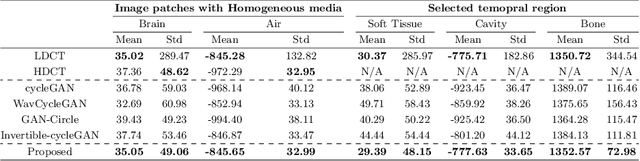
The acquisition conditions for low-dose and high-dose CT images are usually different, so that the shifts in the CT numbers often occur. Accordingly, unsupervised deep learning-based approaches, which learn the target image distribution, often introduce CT number distortions and result in detrimental effects in diagnostic performance. To address this, here we propose a novel unsupervised learning approach for lowdose CT reconstruction using patch-wise deep metric learning. The key idea is to learn embedding space by pulling the positive pairs of image patches which shares the same anatomical structure, and pushing the negative pairs which have same noise level each other. Thereby, the network is trained to suppress the noise level, while retaining the original global CT number distributions even after the image translation. Experimental results confirm that our deep metric learning plays a critical role in producing high quality denoised images without CT number shift.
Exploring Patch-wise Semantic Relation for Contrastive Learning in Image-to-Image Translation Tasks
Mar 03, 2022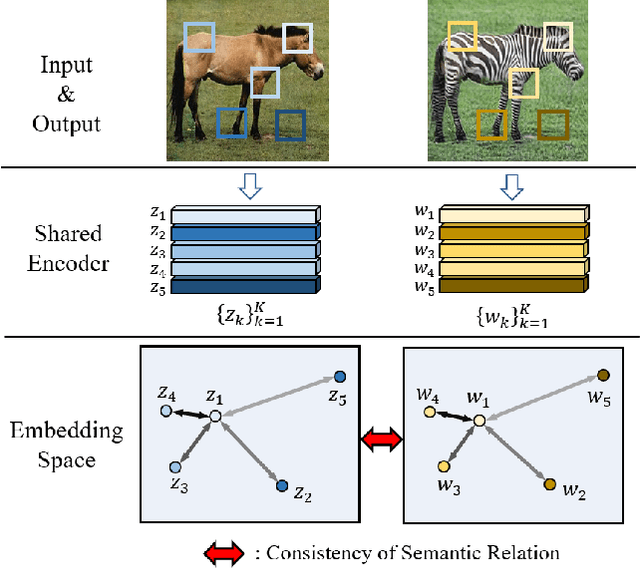
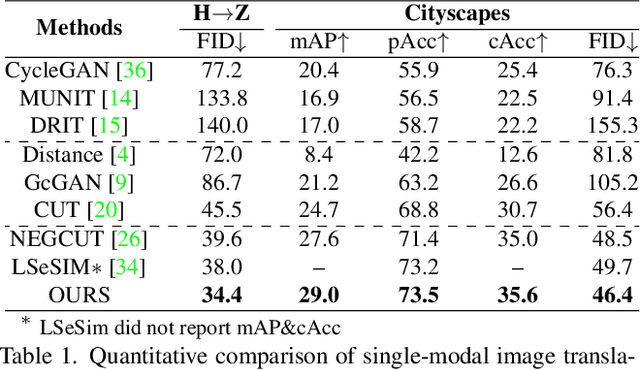
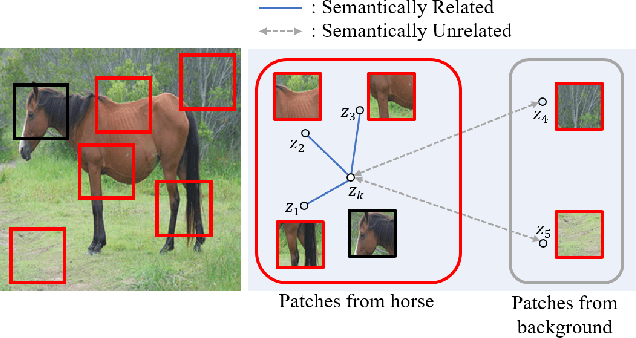
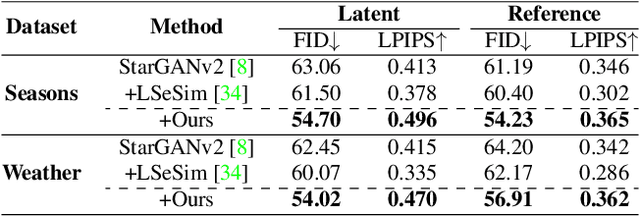
Recently, contrastive learning-based image translation methods have been proposed, which contrasts different spatial locations to enhance the spatial correspondence. However, the methods often ignore the diverse semantic relation within the images. To address this, here we propose a novel semantic relation consistency (SRC) regularization along with the decoupled contrastive learning, which utilize the diverse semantics by focusing on the heterogeneous semantics between the image patches of a single image. To further improve the performance, we present a hard negative mining by exploiting the semantic relation. We verified our method for three tasks: single-modal and multi-modal image translations, and GAN compression task for image translation. Experimental results confirmed the state-of-art performance of our method in all the three tasks.