 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image To Image Translation": models, code, and papers
DGFont++: Robust Deformable Generative Networks for Unsupervised Font Generation
Dec 30, 2022

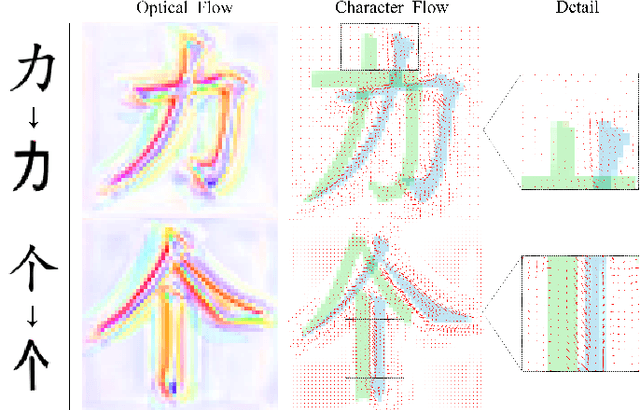


Automatic font generation without human experts is a practical and significant problem, especially for some languages that consist of a large number of characters. Existing methods for font generation are often in supervised learning. They require a large number of paired data, which are labor-intensive and expensive to collect. In contrast, common unsupervised image-to-image translation methods are not applicable to font generation, as they often define style as the set of textures and colors. In this work, we propose a robust deformable generative network for unsupervised font generation (abbreviated as DGFont++). We introduce a feature deformation skip connection (FDSC) to learn local patterns and geometric transformations between fonts. The FDSC predicts pairs of displacement maps and employs the predicted maps to apply deformable convolution to the low-level content feature maps. The outputs of FDSC are fed into a mixer to generate final results. Moreover, we introduce contrastive self-supervised learning to learn a robust style representation for fonts by understanding the similarity and dissimilarities of fonts. To distinguish different styles, we train our model with a multi-task discriminator, which ensures that each style can be discriminated independently. In addition to adversarial loss, another two reconstruction losses are adopted to constrain the domain-invariant characteristics between generated images and content images. Taking advantage of FDSC and the adopted loss functions, our model is able to maintain spatial information and generates high-quality character images in an unsupervised manner. Experiments demonstrate that our model is able to generate character images of higher quality than state-of-the-art methods.
Membership Privacy Protection for Image Translation Models via Adversarial Knowledge Distillation
Mar 10, 2022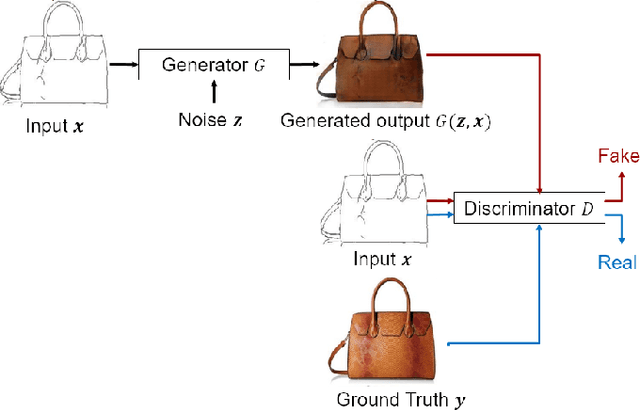
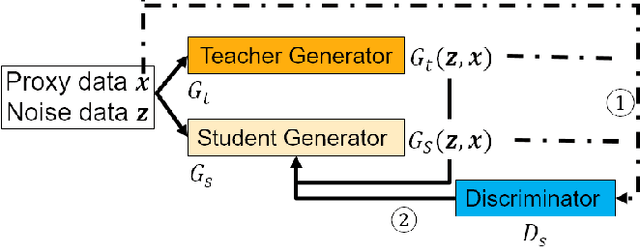
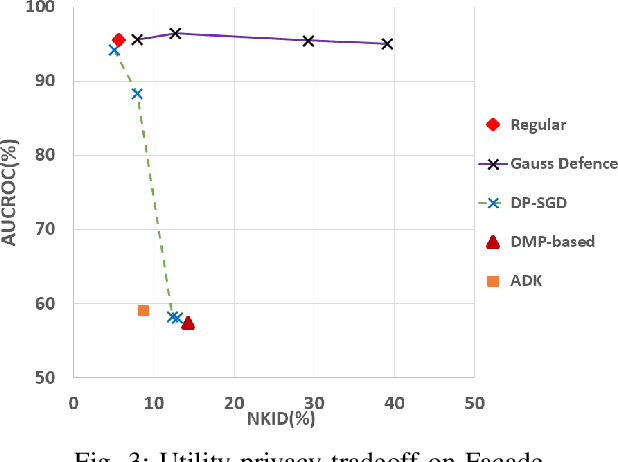
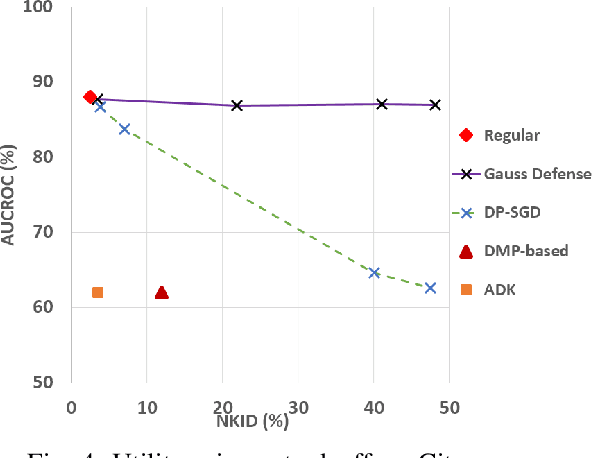
Image-to-image translation models are shown to be vulnerable to the Membership Inference Attack (MIA), in which the adversary's goal is to identify whether a sample is used to train the model or not. With daily increasing applications based on image-to-image translation models, it is crucial to protect the privacy of these models against MIAs. We propose adversarial knowledge distillation (AKD) as a defense method against MIAs for image-to-image translation models. The proposed method protects the privacy of the training samples by improving the generalizability of the model. We conduct experiments on the image-to-image translation models and show that AKD achieves the state-of-the-art utility-privacy tradeoff by reducing the attack performance up to 38.9% compared with the regular training model at the cost of a slight drop in the quality of the generated output images. The experimental results also indicate that the models trained by AKD generalize better than the regular training models. Furthermore, compared with existing defense methods, the results show that at the same privacy protection level, image translation models trained by AKD generate outputs with higher quality; while at the same quality of outputs, AKD enhances the privacy protection over 30%.
StyleDomain: Analysis of StyleSpace for Domain Adaptation of StyleGAN
Dec 20, 2022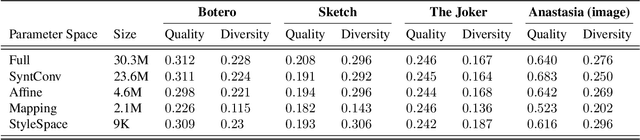
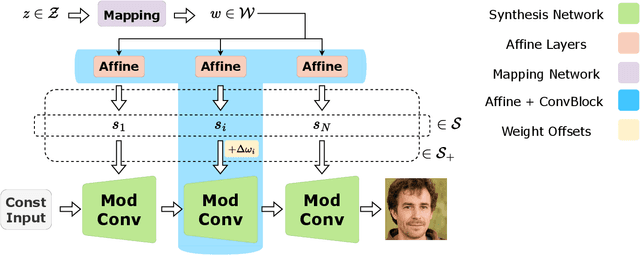
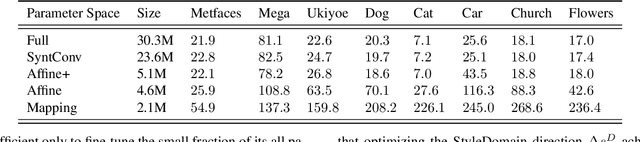

Domain adaptation of GANs is a problem of fine-tuning the state-of-the-art GAN models (e.g. StyleGAN) pretrained on a large dataset to a specific domain with few samples (e.g. painting faces, sketches, etc.). While there are a great number of methods that tackle this problem in different ways there are still many important questions that remain unanswered. In this paper, we provide a systematic and in-depth analysis of the domain adaptation problem of GANs, focusing on the StyleGAN model. First, we perform a detailed exploration of the most important parts of StyleGAN that are responsible for adapting the generator to a new domain depending on the similarity between the source and target domains. In particular, we show that affine layers of StyleGAN can be sufficient for fine-tuning to similar domains. Second, inspired by these findings, we investigate StyleSpace to utilize it for domain adaptation. We show that there exist directions in the StyleSpace that can adapt StyleGAN to new domains. Further, we examine these directions and discover their many surprising properties. Finally, we leverage our analysis and findings to deliver practical improvements and applications in such standard tasks as image-to-image translation and cross-domain morphing.
HealthyGAN: Learning from Unannotated Medical Images to Detect Anomalies Associated with Human Disease
Sep 05, 2022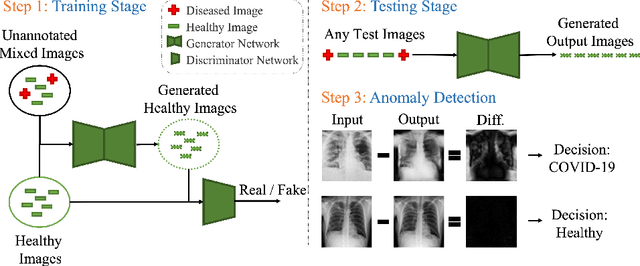
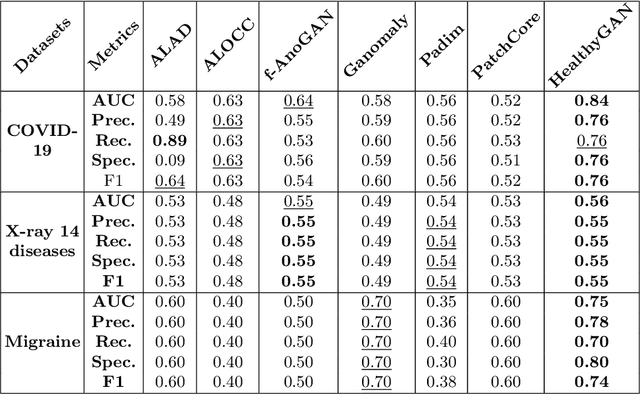
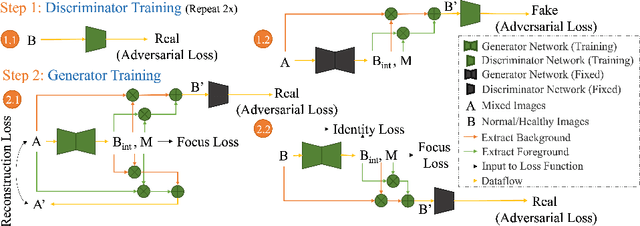
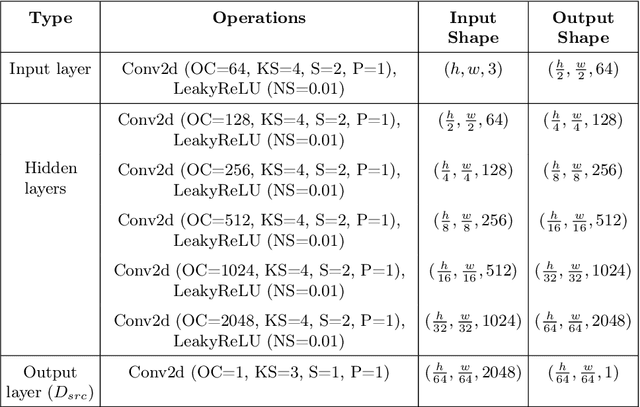
Automated anomaly detection from medical images, such as MRIs and X-rays, can significantly reduce human effort in disease diagnosis. Owing to the complexity of modeling anomalies and the high cost of manual annotation by domain experts (e.g., radiologists), a typical technique in the current medical imaging literature has focused on deriving diagnostic models from healthy subjects only, assuming the model will detect the images from patients as outliers. However, in many real-world scenarios, unannotated datasets with a mix of both healthy and diseased individuals are abundant. Therefore, this paper poses the research question of how to improve unsupervised anomaly detection by utilizing (1) an unannotated set of mixed images, in addition to (2) the set of healthy images as being used in the literature. To answer the question, we propose HealthyGAN, a novel one-directional image-to-image translation method, which learns to translate the images from the mixed dataset to only healthy images. Being one-directional, HealthyGAN relaxes the requirement of cycle consistency of existing unpaired image-to-image translation methods, which is unattainable with mixed unannotated data. Once the translation is learned, we generate a difference map for any given image by subtracting its translated output. Regions of significant responses in the difference map correspond to potential anomalies (if any). Our HealthyGAN outperforms the conventional state-of-the-art methods by significant margins on two publicly available datasets: COVID-19 and NIH ChestX-ray14, and one institutional dataset collected from Mayo Clinic. The implementation is publicly available at https://github.com/mahfuzmohammad/HealthyGAN.
Dynamic Neural Portraits
Nov 25, 2022
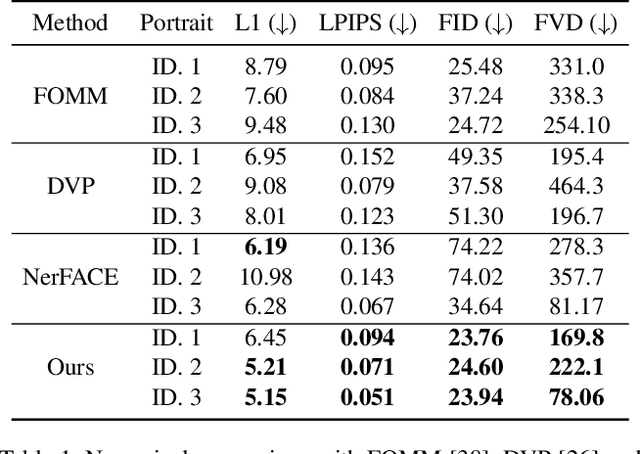
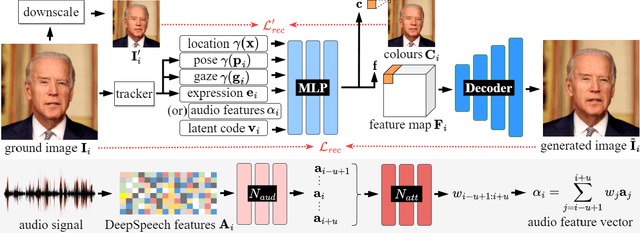
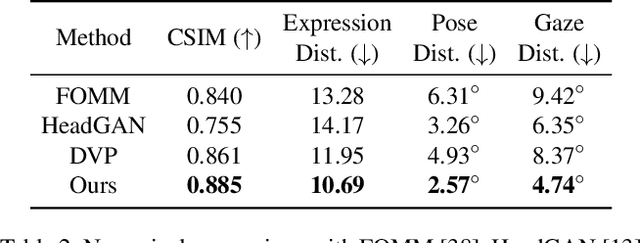
We present Dynamic Neural Portraits, a novel approach to the problem of full-head reenactment. Our method generates photo-realistic video portraits by explicitly controlling head pose, facial expressions and eye gaze. Our proposed architecture is different from existing methods that rely on GAN-based image-to-image translation networks for transforming renderings of 3D faces into photo-realistic images. Instead, we build our system upon a 2D coordinate-based MLP with controllable dynamics. Our intuition to adopt a 2D-based representation, as opposed to recent 3D NeRF-like systems, stems from the fact that video portraits are captured by monocular stationary cameras, therefore, only a single viewpoint of the scene is available. Primarily, we condition our generative model on expression blendshapes, nonetheless, we show that our system can be successfully driven by audio features as well. Our experiments demonstrate that the proposed method is 270 times faster than recent NeRF-based reenactment methods, with our networks achieving speeds of 24 fps for resolutions up to 1024 x 1024, while outperforming prior works in terms of visual quality.
U-GAT-IT: Unsupervised Generative Attentional Networks with Adaptive Layer-Instance Normalization for Image-to-Image Translation
Jul 25, 2019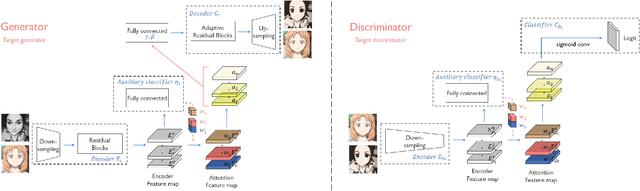
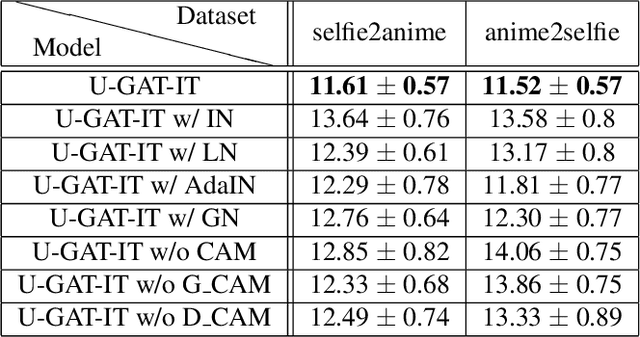

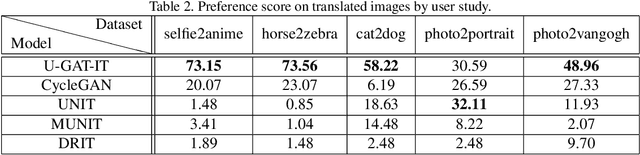
We propose a novel method for unsupervised image-to-image translation, which incorporates a new attention module and a new learnable normalization function in an end-to-end manner. The attention module guides our model to focus on more important regions distinguishing between source and target domains based on the attention map obtained by the auxiliary classifier. Unlike previous attention-based methods which cannot handle the geometric changes between domains, our model can translate both images requiring holistic changes and images requiring large shape changes. Moreover, our new AdaLIN (Adaptive Layer-Instance Normalization) function helps our attention-guided model to flexibly control the amount of change in shape and texture by learned parameters depending on datasets. Experimental results show the superiority of the proposed method compared to the existing state-of-the-art models with a fixed network architecture and hyper-parameters.
PerSign: Personalized Bangladeshi Sign Letters Synthesis
Sep 29, 2022
Bangladeshi Sign Language (BdSL) - like other sign languages - is tough to learn for general people, especially when it comes to expressing letters. In this poster, we propose PerSign, a system that can reproduce a person's image by introducing sign gestures in it. We make this operation personalized, which means the generated image keeps the person's initial image profile - face, skin tone, attire, background - unchanged while altering the hand, palm, and finger positions appropriately. We use an image-to-image translation technique and build a corresponding unique dataset to accomplish the task. We believe the translated image can reduce the communication gap between signers (person who uses sign language) and non-signers without having prior knowledge of BdSL.
Semi-supervised GAN for Bladder Tissue Classification in Multi-Domain Endoscopic Images
Dec 21, 2022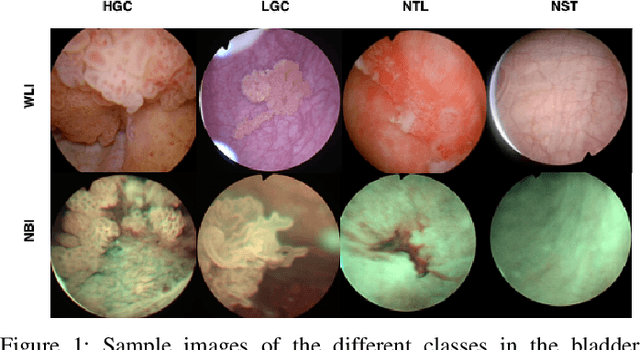
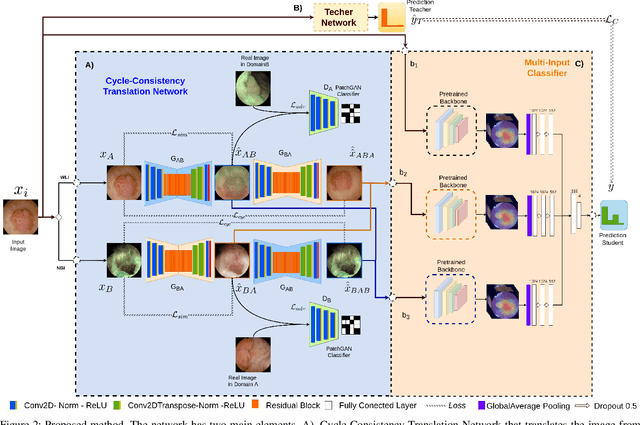
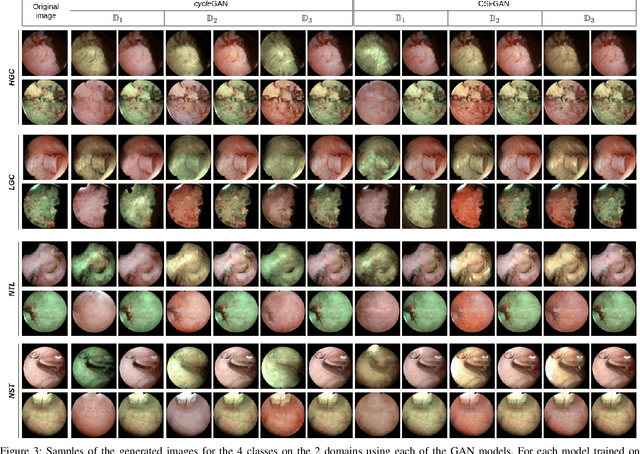
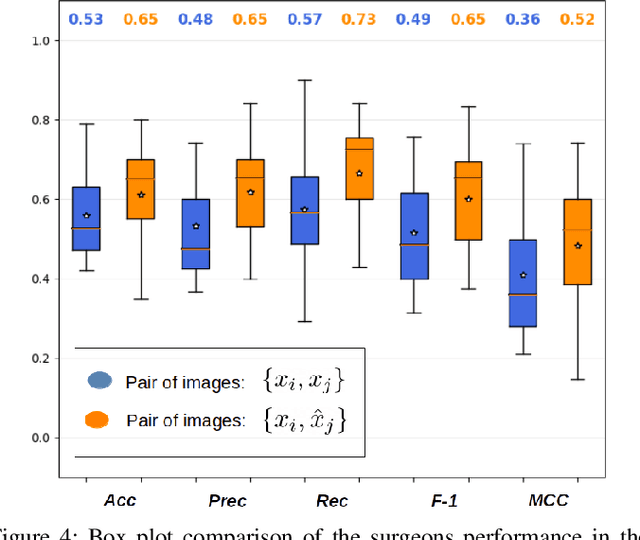
Objective: Accurate visual classification of bladder tissue during Trans-Urethral Resection of Bladder Tumor (TURBT) procedures is essential to improve early cancer diagnosis and treatment. During TURBT interventions, White Light Imaging (WLI) and Narrow Band Imaging (NBI) techniques are used for lesion detection. Each imaging technique provides diverse visual information that allows clinicians to identify and classify cancerous lesions. Computer vision methods that use both imaging techniques could improve endoscopic diagnosis. We address the challenge of tissue classification when annotations are available only in one domain, in our case WLI, and the endoscopic images correspond to an unpaired dataset, i.e. there is no exact equivalent for every image in both NBI and WLI domains. Method: We propose a semi-surprised Generative Adversarial Network (GAN)-based method composed of three main components: a teacher network trained on the labeled WLI data; a cycle-consistency GAN to perform unpaired image-to-image translation, and a multi-input student network. To ensure the quality of the synthetic images generated by the proposed GAN we perform a detailed quantitative, and qualitative analysis with the help of specialists. Conclusion: The overall average classification accuracy, precision, and recall obtained with the proposed method for tissue classification are 0.90, 0.88, and 0.89 respectively, while the same metrics obtained in the unlabeled domain (NBI) are 0.92, 0.64, and 0.94 respectively. The quality of the generated images is reliable enough to deceive specialists. Significance: This study shows the potential of using semi-supervised GAN-based classification to improve bladder tissue classification when annotations are limited in multi-domain data.
Multimodal Image-to-Image Translation via a Single Generative Adversarial Network
Aug 04, 2020
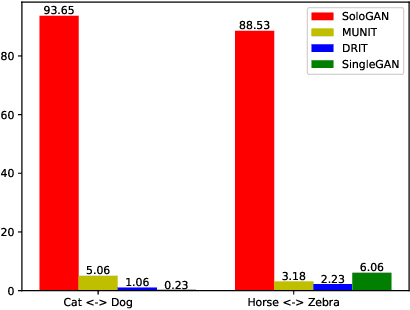


Despite significant advances in image-to-image (I2I) translation with Generative Adversarial Networks (GANs) have been made, it remains challenging to effectively translate an image to a set of diverse images in multiple target domains using a pair of generator and discriminator. Existing multimodal I2I translation methods adopt multiple domain-specific content encoders for different domains, where each domain-specific content encoder is trained with images from the same domain only. Nevertheless, we argue that the content (domain-invariant) features should be learned from images among all the domains. Consequently, each domain-specific content encoder of existing schemes fails to extract the domain-invariant features efficiently. To address this issue, we present a flexible and general SoloGAN model for efficient multimodal I2I translation among multiple domains with unpaired data. In contrast to existing methods, the SoloGAN algorithm uses a single projection discriminator with an additional auxiliary classifier, and shares the encoder and generator for all domains. As such, the SoloGAN model can be trained effectively with images from all domains such that the domain-invariant content representation can be efficiently extracted. Qualitative and quantitative results over a wide range of datasets against several counterparts and variants of the SoloGAN model demonstrate the merits of the method, especially for the challenging I2I translation tasks, i.e., tasks that involve extreme shape variations or need to keep the complex backgrounds unchanged after translations. Furthermore, we demonstrate the contribution of each component using ablation studies.
Towards Pragmatic Semantic Image Synthesis for Urban Scenes
May 16, 2023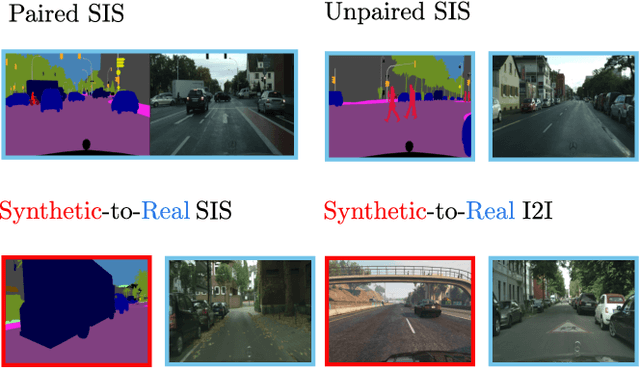

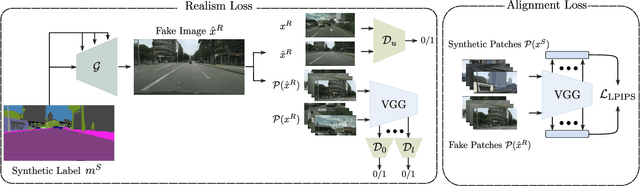

The need for large amounts of training and validation data is a huge concern in scaling AI algorithms for autonomous driving. Semantic Image Synthesis (SIS), or label-to-image translation, promises to address this issue by translating semantic layouts to images, providing a controllable generation of photorealistic data. However, they require a large amount of paired data, incurring extra costs. In this work, we present a new task: given a dataset with synthetic images and labels and a dataset with unlabeled real images, our goal is to learn a model that can generate images with the content of the input mask and the appearance of real images. This new task reframes the well-known unsupervised SIS task in a more practical setting, where we leverage cheaply available synthetic data from a driving simulator to learn how to generate photorealistic images of urban scenes. This stands in contrast to previous works, which assume that labels and images come from the same domain but are unpaired during training. We find that previous unsupervised works underperform on this task, as they do not handle distribution shifts between two different domains. To bypass these problems, we propose a novel framework with two main contributions. First, we leverage the synthetic image as a guide to the content of the generated image by penalizing the difference between their high-level features on a patch level. Second, in contrast to previous works which employ one discriminator that overfits the target domain semantic distribution, we employ a discriminator for the whole image and multiscale discriminators on the image patches. Extensive comparisons on the benchmarks GTA-V $\rightarrow$ Cityscapes and GTA-V $\rightarrow$ Mapillary show the superior performance of the proposed model against state-of-the-art on this task.