 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCORAL: Correspondence Alignment for Improved Virtual Try-On
Feb 19, 2026Existing methods for Virtual Try-On (VTON) often struggle to preserve fine garment details, especially in unpaired settings where accurate person-garment correspondence is required. These methods do not explicitly enforce person-garment alignment and fail to explain how correspondence emerges within Diffusion Transformers (DiTs). In this paper, we first analyze full 3D attention in DiT-based architecture and reveal that the person-garment correspondence critically depends on precise person-garment query-key matching within the full 3D attention. Building on this insight, we then introduce CORrespondence ALignment (CORAL), a DiT-based framework that explicitly aligns query-key matching with robust external correspondences. CORAL integrates two complementary components: a correspondence distillation loss that aligns reliable matches with person-garment attention, and an entropy minimization loss that sharpens the attention distribution. We further propose a VLM-based evaluation protocol to better reflect human preference. CORAL consistently improves over the baseline, enhancing both global shape transfer and local detail preservation. Extensive ablations validate our design choices.
U-GAT-IT: Unsupervised Generative Attentional Networks with Adaptive Layer-Instance Normalization for Image-to-Image Translation
Jul 25, 2019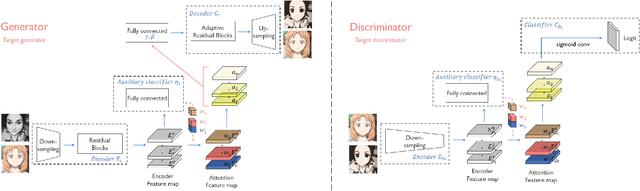
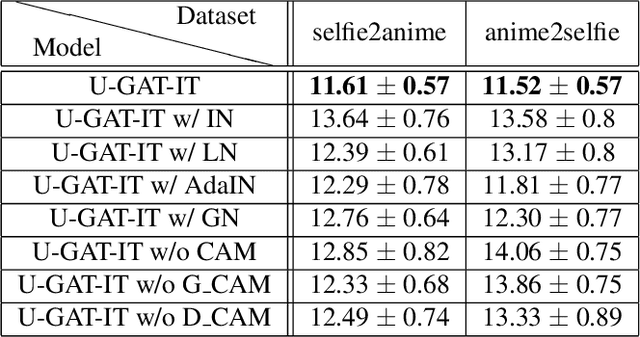

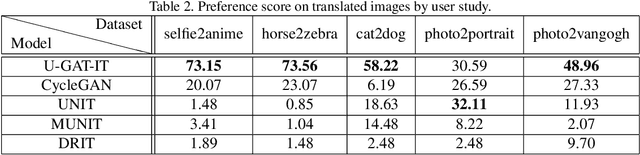
We propose a novel method for unsupervised image-to-image translation, which incorporates a new attention module and a new learnable normalization function in an end-to-end manner. The attention module guides our model to focus on more important regions distinguishing between source and target domains based on the attention map obtained by the auxiliary classifier. Unlike previous attention-based methods which cannot handle the geometric changes between domains, our model can translate both images requiring holistic changes and images requiring large shape changes. Moreover, our new AdaLIN (Adaptive Layer-Instance Normalization) function helps our attention-guided model to flexibly control the amount of change in shape and texture by learned parameters depending on datasets. Experimental results show the superiority of the proposed method compared to the existing state-of-the-art models with a fixed network architecture and hyper-parameters.