 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgeautonomous cars
Autonomous cars are self-driving vehicles that use artificial intelligence (AI) and sensors to navigate and operate without human intervention, using high-resolution cameras and lidars that detect what happens in the car's immediate surroundings. They have the potential to revolutionize transportation by improving safety, efficiency, and accessibility.
Papers and Code
See Less, Drive Better: Generalizable End-to-End Autonomous Driving via Foundation Models Stochastic Patch Selection
Jan 15, 2026Recent advances in end-to-end autonomous driving show that policies trained on patch-aligned features extracted from foundation models generalize better to Out-of-Distribution (OOD). We hypothesize that due to the self-attention mechanism, each patch feature implicitly embeds/contains information from all other patches, represented in a different way and intensity, making these descriptors highly redundant. We quantify redundancy in such (BLIP2) features via PCA and cross-patch similarity: $90$% of variance is captured by $17/64$ principal components, and strong inter-token correlations are pervasive. Training on such overlapping information leads the policy to overfit spurious correlations, hurting OOD robustness. We present Stochastic-Patch-Selection (SPS), a simple yet effective approach for learning policies that are more robust, generalizable, and efficient. For every frame, SPS randomly masks a fraction of patch descriptors, not feeding them to the policy model, while preserving the spatial layout of the remaining patches. Thus, the policy is provided with different stochastic but complete views of the (same) scene: every random subset of patches acts like a different, yet still sensible, coherent projection of the world. The policy thus bases its decisions on features that are invariant to which specific tokens survive. Extensive experiments confirm that across all OOD scenarios, our method outperforms the state of the art (SOTA), achieving a $6.2$% average improvement and up to $20.4$% in closed-loop simulations, while being $2.4\times$ faster. We conduct ablations over masking rates and patch-feature reorganization, training and evaluating 9 systems, with 8 of them surpassing prior SOTA. Finally, we show that the same learned policy transfers to a physical, real-world car without any tuning.
Results of the 2024 CommonRoad Motion Planning Competition for Autonomous Vehicles
Dec 22, 2025



Over the past decade, a wide range of motion planning approaches for autonomous vehicles has been developed to handle increasingly complex traffic scenarios. However, these approaches are rarely compared on standardized benchmarks, limiting the assessment of relative strengths and weaknesses. To address this gap, we present the setup and results of the 4th CommonRoad Motion Planning Competition held in 2024, conducted using the CommonRoad benchmark suite. This annual competition provides an open-source and reproducible framework for benchmarking motion planning algorithms. The benchmark scenarios span highway and urban environments with diverse traffic participants, including passenger cars, buses, and bicycles. Planner performance is evaluated along four dimensions: efficiency, safety, comfort, and compliance with selected traffic rules. This report introduces the competition format and provides a comparison of representative high-performing planners from the 2023 and 2024 editions.
MindWatcher: Toward Smarter Multimodal Tool-Integrated Reasoning
Dec 29, 2025Traditional workflow-based agents exhibit limited intelligence when addressing real-world problems requiring tool invocation. Tool-integrated reasoning (TIR) agents capable of autonomous reasoning and tool invocation are rapidly emerging as a powerful approach for complex decision-making tasks involving multi-step interactions with external environments. In this work, we introduce MindWatcher, a TIR agent integrating interleaved thinking and multimodal chain-of-thought (CoT) reasoning. MindWatcher can autonomously decide whether and how to invoke diverse tools and coordinate their use, without relying on human prompts or workflows. The interleaved thinking paradigm enables the model to switch between thinking and tool calling at any intermediate stage, while its multimodal CoT capability allows manipulation of images during reasoning to yield more precise search results. We implement automated data auditing and evaluation pipelines, complemented by manually curated high-quality datasets for training, and we construct a benchmark, called MindWatcher-Evaluate Bench (MWE-Bench), to evaluate its performance. MindWatcher is equipped with a comprehensive suite of auxiliary reasoning tools, enabling it to address broad-domain multimodal problems. A large-scale, high-quality local image retrieval database, covering eight categories including cars, animals, and plants, endows model with robust object recognition despite its small size. Finally, we design a more efficient training infrastructure for MindWatcher, enhancing training speed and hardware utilization. Experiments not only demonstrate that MindWatcher matches or exceeds the performance of larger or more recent models through superior tool invocation, but also uncover critical insights for agent training, such as the genetic inheritance phenomenon in agentic RL.
SCPainter: A Unified Framework for Realistic 3D Asset Insertion and Novel View Synthesis
Dec 27, 20253D Asset insertion and novel view synthesis (NVS) are key components for autonomous driving simulation, enhancing the diversity of training data. With better training data that is diverse and covers a wide range of situations, including long-tailed driving scenarios, autonomous driving models can become more robust and safer. This motivates a unified simulation framework that can jointly handle realistic integration of inserted 3D assets and NVS. Recent 3D asset reconstruction methods enable reconstruction of dynamic actors from video, supporting their re-insertion into simulated driving scenes. While the overall structure and appearance can be accurate, it still struggles to capture the realism of 3D assets through lighting or shadows, particularly when inserted into scenes. In parallel, recent advances in NVS methods have demonstrated promising results in synthesizing viewpoints beyond the originally recorded trajectories. However, existing approaches largely treat asset insertion and NVS capabilities in isolation. To allow for interaction with the rest of the scene and to enable more diverse creation of new scenarios for training, realistic 3D asset insertion should be combined with NVS. To address this, we present SCPainter (Street Car Painter), a unified framework which integrates 3D Gaussian Splat (GS) car asset representations and 3D scene point clouds with diffusion-based generation to jointly enable realistic 3D asset insertion and NVS. The 3D GS assets and 3D scene point clouds are projected together into novel views, and these projections are used to condition a diffusion model to generate high quality images. Evaluation on the Waymo Open Dataset demonstrate the capability of our framework to enable 3D asset insertion and NVS, facilitating the creation of diverse and realistic driving data.
Early warning signals for loss of control
Dec 24, 2025Maintaining stability in feedback systems, from aircraft and autonomous robots to biological and physiological systems, relies on monitoring their behavior and continuously adjusting their inputs. Incremental damage can make such control fragile. This tends to go unnoticed until a small perturbation induces instability (i.e. loss of control). Traditional methods in the field of engineering rely on accurate system models to compute a safe set of operating instructions, which become invalid when the, possibly damaged, system diverges from its model. Here we demonstrate that the approach of such a feedback system towards instability can nonetheless be monitored through dynamical indicators of resilience. This holistic system safety monitor does not rely on a system model and is based on the generic phenomenon of critical slowing down, shown to occur in the climate, biology and other complex nonlinear systems approaching criticality. Our findings for engineered devices opens up a wide range of applications involving real-time early warning systems as well as an empirical guidance of resilient system design exploration, or "tinkering". While we demonstrate the validity using drones, the generic nature of the underlying principles suggest that these indicators could apply across a wider class of controlled systems including reactors, aircraft, and self-driving cars.
Online Slip Detection and Friction Coefficient Estimation for Autonomous Racing
Sep 18, 2025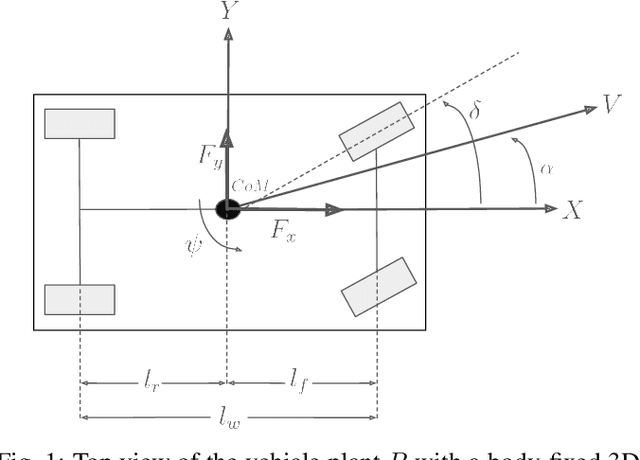
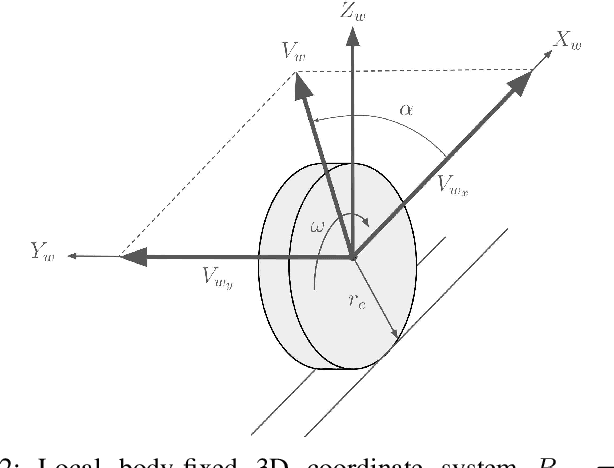
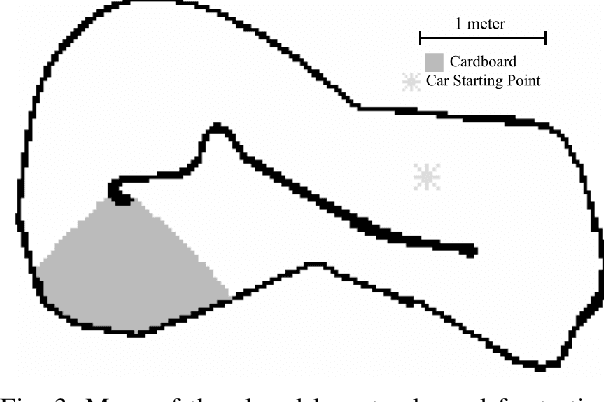
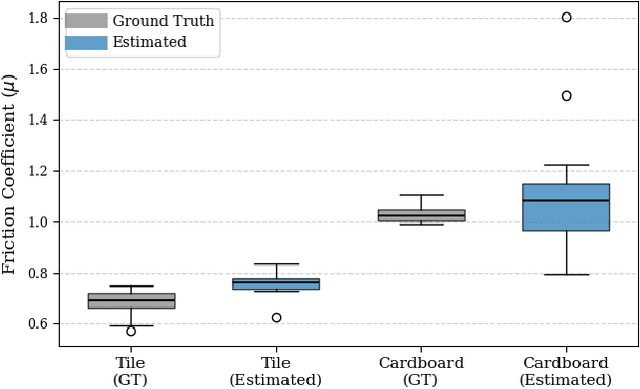
Accurate knowledge of the tire-road friction coefficient (TRFC) is essential for vehicle safety, stability, and performance, especially in autonomous racing, where vehicles often operate at the friction limit. However, TRFC cannot be directly measured with standard sensors, and existing estimation methods either depend on vehicle or tire models with uncertain parameters or require large training datasets. In this paper, we present a lightweight approach for online slip detection and TRFC estimation. Our approach relies solely on IMU and LiDAR measurements and the control actions, without special dynamical or tire models, parameter identification, or training data. Slip events are detected in real time by comparing commanded and measured motions, and the TRFC is then estimated directly from observed accelerations under no-slip conditions. Experiments with a 1:10-scale autonomous racing car across different friction levels demonstrate that the proposed approach achieves accurate and consistent slip detections and friction coefficients, with results closely matching ground-truth measurements. These findings highlight the potential of our simple, deployable, and computationally efficient approach for real-time slip monitoring and friction coefficient estimation in autonomous driving.
A Digital Twin Framework for Metamorphic Testing of Autonomous Driving Systems Using Generative Model
Oct 08, 2025Ensuring the safety of self-driving cars remains a major challenge due to the complexity and unpredictability of real-world driving environments. Traditional testing methods face significant limitations, such as the oracle problem, which makes it difficult to determine whether a system's behavior is correct, and the inability to cover the full range of scenarios an autonomous vehicle may encounter. In this paper, we introduce a digital twin-driven metamorphic testing framework that addresses these challenges by creating a virtual replica of the self-driving system and its operating environment. By combining digital twin technology with AI-based image generative models such as Stable Diffusion, our approach enables the systematic generation of realistic and diverse driving scenes. This includes variations in weather, road topology, and environmental features, all while maintaining the core semantics of the original scenario. The digital twin provides a synchronized simulation environment where changes can be tested in a controlled and repeatable manner. Within this environment, we define three metamorphic relations inspired by real-world traffic rules and vehicle behavior. We validate our framework in the Udacity self-driving simulator and demonstrate that it significantly enhances test coverage and effectiveness. Our method achieves the highest true positive rate (0.719), F1 score (0.689), and precision (0.662) compared to baseline approaches. This paper highlights the value of integrating digital twins with AI-powered scenario generation to create a scalable, automated, and high-fidelity testing solution for autonomous vehicle safety.
HyPlan: Hybrid Learning-Assisted Planning Under Uncertainty for Safe Autonomous Driving
Oct 08, 2025We present a novel hybrid learning-assisted planning method, named HyPlan, for solving the collision-free navigation problem for self-driving cars in partially observable traffic environments. HyPlan combines methods for multi-agent behavior prediction, deep reinforcement learning with proximal policy optimization and approximated online POMDP planning with heuristic confidence-based vertical pruning to reduce its execution time without compromising safety of driving. Our experimental performance analysis on the CARLA-CTS2 benchmark of critical traffic scenarios with pedestrians revealed that HyPlan may navigate safer than selected relevant baselines and perform significantly faster than considered alternative online POMDP planners.
MonoCLUE : Object-Aware Clustering Enhances Monocular 3D Object Detection
Nov 11, 2025Monocular 3D object detection offers a cost-effective solution for autonomous driving but suffers from ill-posed depth and limited field of view. These constraints cause a lack of geometric cues and reduced accuracy in occluded or truncated scenes. While recent approaches incorporate additional depth information to address geometric ambiguity, they overlook the visual cues crucial for robust recognition. We propose MonoCLUE, which enhances monocular 3D detection by leveraging both local clustering and generalized scene memory of visual features. First, we perform K-means clustering on visual features to capture distinct object-level appearance parts (e.g., bonnet, car roof), improving detection of partially visible objects. The clustered features are propagated across regions to capture objects with similar appearances. Second, we construct a generalized scene memory by aggregating clustered features across images, providing consistent representations that generalize across scenes. This improves object-level feature consistency, enabling stable detection across varying environments. Lastly, we integrate both local cluster features and generalized scene memory into object queries, guiding attention toward informative regions. Exploiting a unified local clustering and generalized scene memory strategy, MonoCLUE enables robust monocular 3D detection under occlusion and limited visibility, achieving state-of-the-art performance on the KITTI benchmark.
Model-Structured Neural Networks to Control the Steering Dynamics of Autonomous Race Cars
Jul 27, 2025Autonomous racing has gained increasing attention in recent years, as a safe environment to accelerate the development of motion planning and control methods for autonomous driving. Deep learning models, predominantly based on neural networks (NNs), have demonstrated significant potential in modeling the vehicle dynamics and in performing various tasks in autonomous driving. However, their black-box nature is critical in the context of autonomous racing, where safety and robustness demand a thorough understanding of the decision-making algorithms. To address this challenge, this paper proposes MS-NN-steer, a new Model-Structured Neural Network for vehicle steering control, integrating the prior knowledge of the nonlinear vehicle dynamics into the neural architecture. The proposed controller is validated using real-world data from the Abu Dhabi Autonomous Racing League (A2RL) competition, with full-scale autonomous race cars. In comparison with general-purpose NNs, MS-NN-steer is shown to achieve better accuracy and generalization with small training datasets, while being less sensitive to the weights' initialization. Also, MS-NN-steer outperforms the steering controller used by the A2RL winning team. Our implementation is available open-source in a GitHub repository.