 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistilling Linearized Behavior for Effective Task Arithmetic
May 18, 2026Task vector composition has emerged as a promising paradigm for editing pre-trained models, enabling model merging through addition and unlearning through subtraction. Fine-tuning in the tangent space of a pre-trained model (linear fine-tuning) has proven effective, as it produces task vectors that are naturally disentangled and resistant to interference. However, linearized models suffer from limited expressivity during training and incur higher computational costs at inference time, which restrict their practical applicability. In this work, we bridge the gap between linear and standard non-linear fine-tuning. We show that linearity with respect to weight perturbations, a property defined in parameter space, can be enforced through constraints in activation space during training. Concretely, we distill hidden representations from a curvature-regularized linearized teacher into a non-linear student trained via conventional fine-tuning. We find that the resulting model inherits key properties of linearized models for task arithmetic, enabling effective composition of task vectors and achieving strong performance across vision and language benchmarks without incurring any inference-time overhead.
Zero-Shot Synthetic-to-Real Handwritten Text Recognition via Task Analogies
Apr 08, 2026Handwritten Text Recognition (HTR) models trained on synthetic handwriting often struggle to generalize to real text, and existing adaptation methods still require real samples from the target domain. In this work, we tackle the fully zero-shot synthetic-to-real generalization setting, where no real data from the target language is available. Our approach learns how model parameters change when moving from synthetic to real handwriting in one or more source languages and transfers this learned correction to new target languages. When using multiple sources, we rely on linguistic similarity to weigh their contrubition when combining them. Experiments across five languages and six architectures show consistent improvements over synthetic-only baselines and reveal that the transferred corrections benefit even languages unrelated to the sources.
ABRA: Teleporting Fine-Tuned Knowledge Across Domains for Open-Vocabulary Object Detection
Mar 12, 2026Although recent Open-Vocabulary Object Detection architectures, such as Grounding DINO, demonstrate strong zero-shot capabilities, their performance degrades significantly under domain shifts. Moreover, many domains of practical interest, such as nighttime or foggy scenes, lack large annotated datasets, preventing direct fine-tuning. In this paper, we introduce Aligned Basis Relocation for Adaptation(ABRA), a method that transfers class-specific detection knowledge from a labeled source domain to a target domain where no training images containing these classes are accessible. ABRA formulates this adaptation as a geometric transport problem in the weight space of a pretrained detector, aligning source and target domain experts to transport class-specific knowledge. Extensive experiments across challenging domain shifts demonstrate that ABRA successfully teleports class-level specialization under multiple adverse conditions. Our code will be made public upon acceptance.
Dataless Weight Disentanglement in Task Arithmetic via Kronecker-Factored Approximate Curvature
Feb 19, 2026Task Arithmetic yields a modular, scalable way to adapt foundation models. Combining multiple task vectors, however, can lead to cross-task interference, causing representation drift and degraded performance. Representation drift regularization provides a natural remedy to disentangle task vectors; however, existing approaches typically require external task data, conflicting with modularity and data availability constraints (e.g., privacy requirements). We propose a dataless approach by framing regularization against representation drift as a curvature matrix approximation problem. This allows us to leverage well-established techniques; in particular, we adopt Kronecker-Factored Approximate Curvature and obtain a practical regularizer that achieves state-of-the-art results in task addition and negation. Our method has constant complexity in the number of tasks and promotes robustness to task vector rescaling, eliminating the need for held-out tuning.
Transporting Task Vectors across Different Architectures without Training
Feb 13, 2026Adapting large pre-trained models to downstream tasks often produces task-specific parameter updates that are expensive to relearn for every model variant. While recent work has shown that such updates can be transferred between models with identical architectures, transferring them across models of different widths remains largely unexplored. In this work, we introduce Theseus, a training-free method for transporting task-specific updates across heterogeneous models. Rather than matching parameters directly, we characterize a task update by the functional effect it induces on intermediate representations. We formalize task-vector transport as a functional matching problem on observed activations and show that, after aligning representation spaces via orthogonal Procrustes analysis, it admits a stable closed-form solution that preserves the geometry of the update. We evaluate Theseus on vision and language models across different widths, showing consistent improvements over strong baselines without additional training or backpropagation. Our results show that task updates can be meaningfully transferred across architectures when task identity is defined functionally rather than parametrically.
CAMNet: Leveraging Cooperative Awareness Messages for Vehicle Trajectory Prediction
Oct 14, 2025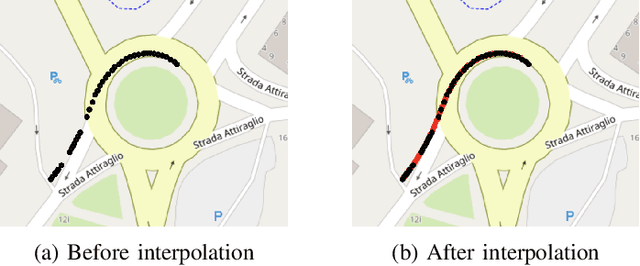
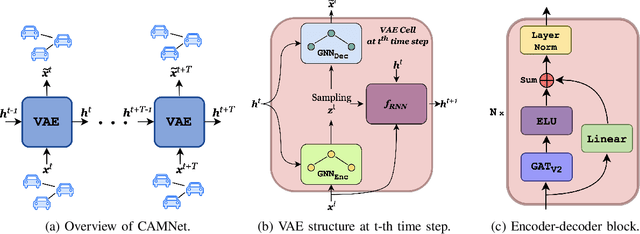
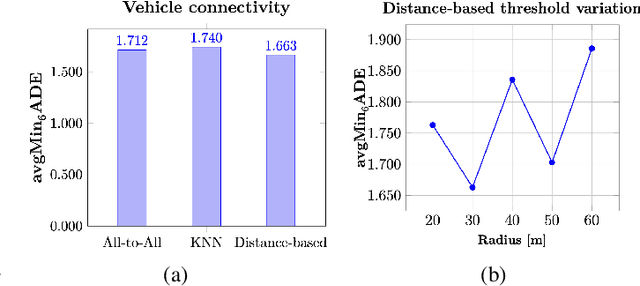
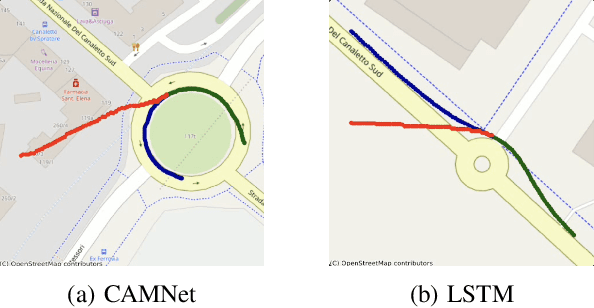
Autonomous driving remains a challenging task, particularly due to safety concerns. Modern vehicles are typically equipped with expensive sensors such as LiDAR, cameras, and radars to reduce the risk of accidents. However, these sensors face inherent limitations: their field of view and line of sight can be obstructed by other vehicles, thereby reducing situational awareness. In this context, vehicle-to-vehicle communication plays a crucial role, as it enables cars to share information and remain aware of each other even when sensors are occluded. One way to achieve this is through the use of Cooperative Awareness Messages (CAMs). In this paper, we investigate the use of CAM data for vehicle trajectory prediction. Specifically, we design and train a neural network, Cooperative Awareness Message-based Graph Neural Network (CAMNet), on a widely used motion forecasting dataset. We then evaluate the model on a second dataset that we created from scratch using Cooperative Awareness Messages, in order to assess whether this type of data can be effectively exploited. Our approach demonstrates promising results, showing that CAMs can indeed support vehicle trajectory prediction. At the same time, we discuss several limitations of the approach, which highlight opportunities for future research.
Update Your Transformer to the Latest Release: Re-Basin of Task Vectors
May 28, 2025Foundation models serve as the backbone for numerous specialized models developed through fine-tuning. However, when the underlying pretrained model is updated or retrained (e.g., on larger and more curated datasets), the fine-tuned model becomes obsolete, losing its utility and requiring retraining. This raises the question: is it possible to transfer fine-tuning to a new release of the model? In this work, we investigate how to transfer fine-tuning to a new checkpoint without having to re-train, in a data-free manner. To do so, we draw principles from model re-basin and provide a recipe based on weight permutations to re-base the modifications made to the original base model, often called task vector. In particular, our approach tailors model re-basin for Transformer models, taking into account the challenges of residual connections and multi-head attention layers. Specifically, we propose a two-level method rooted in spectral theory, initially permuting the attention heads and subsequently adjusting parameters within select pairs of heads. Through extensive experiments on visual and textual tasks, we achieve the seamless transfer of fine-tuned knowledge to new pre-trained backbones without relying on a single training step or datapoint. Code is available at https://github.com/aimagelab/TransFusion.
How to Train Your Metamorphic Deep Neural Network
May 07, 2025



Neural Metamorphosis (NeuMeta) is a recent paradigm for generating neural networks of varying width and depth. Based on Implicit Neural Representation (INR), NeuMeta learns a continuous weight manifold, enabling the direct generation of compressed models, including those with configurations not seen during training. While promising, the original formulation of NeuMeta proves effective only for the final layers of the undelying model, limiting its broader applicability. In this work, we propose a training algorithm that extends the capabilities of NeuMeta to enable full-network metamorphosis with minimal accuracy degradation. Our approach follows a structured recipe comprising block-wise incremental training, INR initialization, and strategies for replacing batch normalization. The resulting metamorphic networks maintain competitive accuracy across a wide range of compression ratios, offering a scalable solution for adaptable and efficient deployment of deep models. The code is available at: https://github.com/TSommariva/HTTY_NeuMeta.
DitHub: A Modular Framework for Incremental Open-Vocabulary Object Detection
Mar 12, 2025Open-Vocabulary object detectors can recognize a wide range of categories using simple textual prompts. However, improving their ability to detect rare classes or specialize in certain domains remains a challenge. While most recent methods rely on a single set of model weights for adaptation, we take a different approach by using modular deep learning. We introduce DitHub, a framework designed to create and manage a library of efficient adaptation modules. Inspired by Version Control Systems, DitHub organizes expert modules like branches that can be fetched and merged as needed. This modular approach enables a detailed study of how adaptation modules combine, making it the first method to explore this aspect in Object Detection. Our approach achieves state-of-the-art performance on the ODinW-13 benchmark and ODinW-O, a newly introduced benchmark designed to evaluate how well models adapt when previously seen classes reappear. For more details, visit our project page: https://aimagelab.github.io/DitHub/
Is Multiple Object Tracking a Matter of Specialization?
Nov 01, 2024



End-to-end transformer-based trackers have achieved remarkable performance on most human-related datasets. However, training these trackers in heterogeneous scenarios poses significant challenges, including negative interference - where the model learns conflicting scene-specific parameters - and limited domain generalization, which often necessitates expensive fine-tuning to adapt the models to new domains. In response to these challenges, we introduce Parameter-efficient Scenario-specific Tracking Architecture (PASTA), a novel framework that combines Parameter-Efficient Fine-Tuning (PEFT) and Modular Deep Learning (MDL). Specifically, we define key scenario attributes (e.g, camera-viewpoint, lighting condition) and train specialized PEFT modules for each attribute. These expert modules are combined in parameter space, enabling systematic generalization to new domains without increasing inference time. Extensive experiments on MOTSynth, along with zero-shot evaluations on MOT17 and PersonPath22 demonstrate that a neural tracker built from carefully selected modules surpasses its monolithic counterpart. We release models and code.