 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgemusic generation
Music generation is the task of generating music or music-like sounds from a model or algorithm.
Papers and Code
Automatic Music Mixing using a Generative Model of Effect Embeddings
Nov 11, 2025Music mixing involves combining individual tracks into a cohesive mixture, a task characterized by subjectivity where multiple valid solutions exist for the same input. Existing automatic mixing systems treat this task as a deterministic regression problem, thus ignoring this multiplicity of solutions. Here we introduce MEGAMI (Multitrack Embedding Generative Auto MIxing), a generative framework that models the conditional distribution of professional mixes given unprocessed tracks. MEGAMI uses a track-agnostic effects processor conditioned on per-track generated embeddings, handles arbitrary unlabeled tracks through a permutation-equivariant architecture, and enables training on both dry and wet recordings via domain adaptation. Our objective evaluation using distributional metrics shows consistent improvements over existing methods, while listening tests indicate performances approaching human-level quality across diverse musical genres.
Memo2496: Expert-Annotated Dataset and Dual-View Adaptive Framework for Music Emotion Recognition
Dec 17, 2025
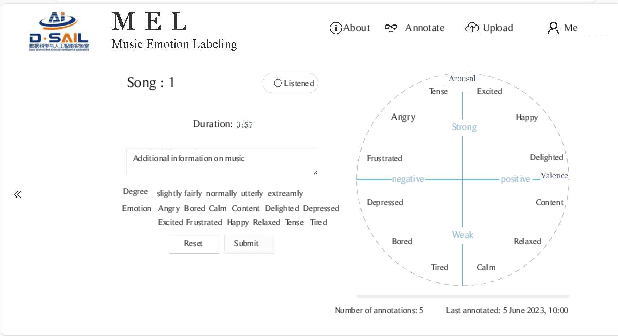
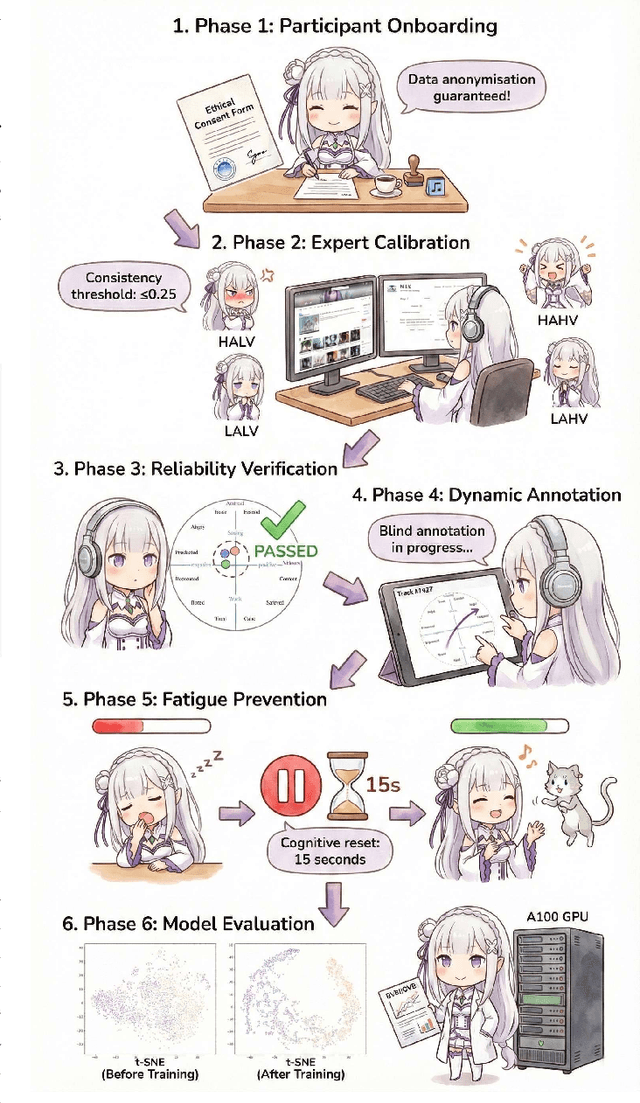
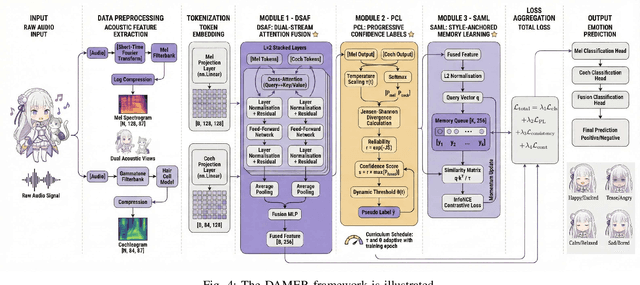
Music Emotion Recogniser (MER) research faces challenges due to limited high-quality annotated datasets and difficulties in addressing cross-track feature drift. This work presents two primary contributions to address these issues. Memo2496, a large-scale dataset, offers 2496 instrumental music tracks with continuous valence arousal labels, annotated by 30 certified music specialists. Annotation quality is ensured through calibration with extreme emotion exemplars and a consistency threshold of 0.25, measured by Euclidean distance in the valence arousal space. Furthermore, the Dual-view Adaptive Music Emotion Recogniser (DAMER) is introduced. DAMER integrates three synergistic modules: Dual Stream Attention Fusion (DSAF) facilitates token-level bidirectional interaction between Mel spectrograms and cochleagrams via cross attention mechanisms; Progressive Confidence Labelling (PCL) generates reliable pseudo labels employing curriculum-based temperature scheduling and consistency quantification using Jensen Shannon divergence; and Style Anchored Memory Learning (SAML) maintains a contrastive memory queue to mitigate cross-track feature drift. Extensive experiments on the Memo2496, 1000songs, and PMEmo datasets demonstrate DAMER's state-of-the-art performance, improving arousal dimension accuracy by 3.43%, 2.25%, and 0.17%, respectively. Ablation studies and visualisation analyses validate each module's contribution. Both the dataset and source code are publicly available.
VABench: A Comprehensive Benchmark for Audio-Video Generation
Dec 10, 2025Recent advances in video generation have been remarkable, enabling models to produce visually compelling videos with synchronized audio. While existing video generation benchmarks provide comprehensive metrics for visual quality, they lack convincing evaluations for audio-video generation, especially for models aiming to generate synchronized audio-video outputs. To address this gap, we introduce VABench, a comprehensive and multi-dimensional benchmark framework designed to systematically evaluate the capabilities of synchronous audio-video generation. VABench encompasses three primary task types: text-to-audio-video (T2AV), image-to-audio-video (I2AV), and stereo audio-video generation. It further establishes two major evaluation modules covering 15 dimensions. These dimensions specifically assess pairwise similarities (text-video, text-audio, video-audio), audio-video synchronization, lip-speech consistency, and carefully curated audio and video question-answering (QA) pairs, among others. Furthermore, VABench covers seven major content categories: animals, human sounds, music, environmental sounds, synchronous physical sounds, complex scenes, and virtual worlds. We provide a systematic analysis and visualization of the evaluation results, aiming to establish a new standard for assessing video generation models with synchronous audio capabilities and to promote the comprehensive advancement of the field.
MusRec: Zero-Shot Text-to-Music Editing via Rectified Flow and Diffusion Transformers
Nov 06, 2025



Music editing has emerged as an important and practical area of artificial intelligence, with applications ranging from video game and film music production to personalizing existing tracks according to user preferences. However, existing models face significant limitations, such as being restricted to editing synthesized music generated by their own models, requiring highly precise prompts, or necessitating task-specific retraining, thus lacking true zero-shot capability. Leveraging recent advances in rectified flow and diffusion transformers, we introduce MusRec, the first zero-shot text-to-music editing model capable of performing diverse editing tasks on real-world music efficiently and effectively. Experimental results demonstrate that our approach outperforms existing methods in preserving musical content, structural consistency, and editing fidelity, establishing a strong foundation for controllable music editing in real-world scenarios.
Who Gets Heard? Rethinking Fairness in AI for Music Systems
Nov 08, 2025In recent years, the music research community has examined risks of AI models for music, with generative AI models in particular, raised concerns about copyright, deepfakes, and transparency. In our work, we raise concerns about cultural and genre biases in AI for music systems (music-AI systems) which affect stakeholders including creators, distributors, and listeners shaping representation in AI for music. These biases can misrepresent marginalized traditions, especially from the Global South, producing inauthentic outputs (e.g., distorted ragas) that reduces creators' trust on these systems. Such harms risk reinforcing biases, limiting creativity, and contributing to cultural erasure. To address this, we offer recommendations at dataset, model and interface level in music-AI systems.
Steering Autoregressive Music Generation with Recursive Feature Machines
Oct 21, 2025Controllable music generation remains a significant challenge, with existing methods often requiring model retraining or introducing audible artifacts. We introduce MusicRFM, a framework that adapts Recursive Feature Machines (RFMs) to enable fine-grained, interpretable control over frozen, pre-trained music models by directly steering their internal activations. RFMs analyze a model's internal gradients to produce interpretable "concept directions", or specific axes in the activation space that correspond to musical attributes like notes or chords. We first train lightweight RFM probes to discover these directions within MusicGen's hidden states; then, during inference, we inject them back into the model to guide the generation process in real-time without per-step optimization. We present advanced mechanisms for this control, including dynamic, time-varying schedules and methods for the simultaneous enforcement of multiple musical properties. Our method successfully navigates the trade-off between control and generation quality: we can increase the accuracy of generating a target musical note from 0.23 to 0.82, while text prompt adherence remains within approximately 0.02 of the unsteered baseline, demonstrating effective control with minimal impact on prompt fidelity. We release code to encourage further exploration on RFMs in the music domain.
Learning Robot Manipulation from Audio World Models
Dec 09, 2025

World models have demonstrated impressive performance on robotic learning tasks. Many such tasks inherently demand multimodal reasoning; for example, filling a bottle with water will lead to visual information alone being ambiguous or incomplete, thereby requiring reasoning over the temporal evolution of audio, accounting for its underlying physical properties and pitch patterns. In this paper, we propose a generative latent flow matching model to anticipate future audio observations, enabling the system to reason about long-term consequences when integrated into a robot policy. We demonstrate the superior capabilities of our system through two manipulation tasks that require perceiving in-the-wild audio or music signals, compared to methods without future lookahead. We further emphasize that successful robot action learning for these tasks relies not merely on multi-modal input, but critically on the accurate prediction of future audio states that embody intrinsic rhythmic patterns.
Attribution-by-design: Ensuring Inference-Time Provenance in Generative Music Systems
Oct 09, 2025



The rise of AI-generated music is diluting royalty pools and revealing structural flaws in existing remuneration frameworks, challenging the well-established artist compensation systems in the music industry. Existing compensation solutions, such as piecemeal licensing agreements, lack scalability and technical rigour, while current data attribution mechanisms provide only uncertain estimates and are rarely implemented in practice. This paper introduces a framework for a generative music infrastructure centred on direct attribution, transparent royalty distribution, and granular control for artists and rights' holders. We distinguish ontologically between the training set and the inference set, which allows us to propose two complementary forms of attribution: training-time attribution and inference-time attribution. We here favour inference-time attribution, as it enables direct, verifiable compensation whenever an artist's catalogue is used to condition a generated output. Besides, users benefit from the ability to condition generations on specific songs and receive transparent information about attribution and permitted usage. Our approach offers an ethical and practical solution to the pressing need for robust compensation mechanisms in the era of AI-generated music, ensuring that provenance and fairness are embedded at the core of generative systems.
Twenty-Five Years of MIR Research: Achievements, Practices, Evaluations, and Future Challenges
Nov 10, 2025In this paper, we trace the evolution of Music Information Retrieval (MIR) over the past 25 years. While MIR gathers all kinds of research related to music informatics, a large part of it focuses on signal processing techniques for music data, fostering a close relationship with the IEEE Audio and Acoustic Signal Processing Technical Commitee. In this paper, we reflect the main research achievements of MIR along the three EDICS related to music analysis, processing and generation. We then review a set of successful practices that fuel the rapid development of MIR research. One practice is the annual research benchmark, the Music Information Retrieval Evaluation eXchange, where participants compete on a set of research tasks. Another practice is the pursuit of reproducible and open research. The active engagement with industry research and products is another key factor for achieving large societal impacts and motivating younger generations of students to join the field. Last but not the least, the commitment to diversity, equity and inclusion ensures MIR to be a vibrant and open community where various ideas, methodologies, and career pathways collide. We finish by providing future challenges MIR will have to face.
Bias beyond Borders: Global Inequalities in AI-Generated Music
Oct 02, 2025While recent years have seen remarkable progress in music generation models, research on their biases across countries, languages, cultures, and musical genres remains underexplored. This gap is compounded by the lack of datasets and benchmarks that capture the global diversity of music. To address these challenges, we introduce GlobalDISCO, a large-scale dataset consisting of 73k music tracks generated by state-of-the-art commercial generative music models, along with paired links to 93k reference tracks in LAION-DISCO-12M. The dataset spans 147 languages and includes musical style prompts extracted from MusicBrainz and Wikipedia. The dataset is globally balanced, representing musical styles from artists across 79 countries and five continents. Our evaluation reveals large disparities in music quality and alignment with reference music between high-resource and low-resource regions. Furthermore, we find marked differences in model performance between mainstream and geographically niche genres, including cases where models generate music for regional genres that more closely align with the distribution of mainstream styles.