 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgefacial recognition
Facial recognition is an AI-based technique for identifying or confirming an individual's identity using their face. It maps facial features from an image or video and then compares the information with a collection of known faces to find a match.
Papers and Code
Facial Expression Recognition with YOLOv11 and YOLOv12: A Comparative Study
Nov 14, 2025



Facial Expression Recognition remains a challenging task, especially in unconstrained, real-world environments. This study investigates the performance of two lightweight models, YOLOv11n and YOLOv12n, which are the nano variants of the latest official YOLO series, within a unified detection and classification framework for FER. Two benchmark classification datasets, FER2013 and KDEF, are converted into object detection format and model performance is evaluated using mAP 0.5, precision, recall, and confusion matrices. Results show that YOLOv12n achieves the highest overall performance on the clean KDEF dataset with a mAP 0.5 of 95.6, and also outperforms YOLOv11n on the FER2013 dataset in terms of mAP 63.8, reflecting stronger sensitivity to varied expressions. In contrast, YOLOv11n demonstrates higher precision 65.2 on FER2013, indicating fewer false positives and better reliability in noisy, real-world conditions. On FER2013, both models show more confusion between visually similar expressions, while clearer class separation is observed on the cleaner KDEF dataset. These findings underscore the trade-off between sensitivity and precision, illustrating how lightweight YOLO models can effectively balance performance and efficiency. The results demonstrate adaptability across both controlled and real-world conditions, establishing these models as strong candidates for real-time, resource-constrained emotion-aware AI applications.
CLIP-FTI: Fine-Grained Face Template Inversion via CLIP-Driven Attribute Conditioning
Dec 17, 2025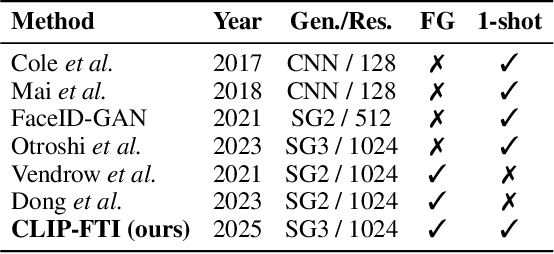
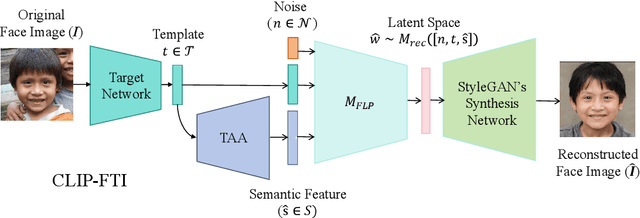
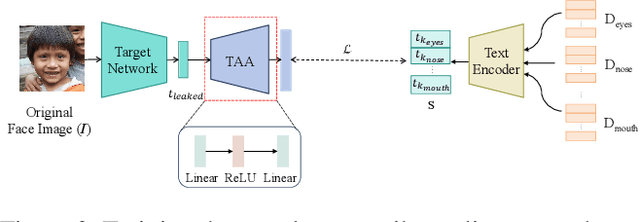
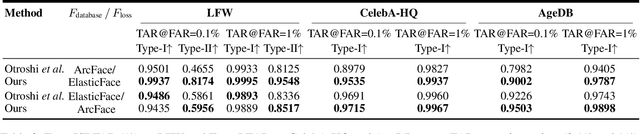
Face recognition systems store face templates for efficient matching. Once leaked, these templates pose a threat: inverting them can yield photorealistic surrogates that compromise privacy and enable impersonation. Although existing research has achieved relatively realistic face template inversion, the reconstructed facial images exhibit over-smoothed facial-part attributes (eyes, nose, mouth) and limited transferability. To address this problem, we present CLIP-FTI, a CLIP-driven fine-grained attribute conditioning framework for face template inversion. Our core idea is to use the CLIP model to obtain the semantic embeddings of facial features, in order to realize the reconstruction of specific facial feature attributes. Specifically, facial feature attribute embeddings extracted from CLIP are fused with the leaked template via a cross-modal feature interaction network and projected into the intermediate latent space of a pretrained StyleGAN. The StyleGAN generator then synthesizes face images with the same identity as the templates but with more fine-grained facial feature attributes. Experiments across multiple face recognition backbones and datasets show that our reconstructions (i) achieve higher identification accuracy and attribute similarity, (ii) recover sharper component-level attribute semantics, and (iii) improve cross-model attack transferability compared to prior reconstruction attacks. To the best of our knowledge, ours is the first method to use additional information besides the face template attack to realize face template inversion and obtains SOTA results.
Emotion Recognition in Signers
Dec 17, 2025Recognition of signers' emotions suffers from one theoretical challenge and one practical challenge, namely, the overlap between grammatical and affective facial expressions and the scarcity of data for model training. This paper addresses these two challenges in a cross-lingual setting using our eJSL dataset, a new benchmark dataset for emotion recognition in Japanese Sign Language signers, and BOBSL, a large British Sign Language dataset with subtitles. In eJSL, two signers expressed 78 distinct utterances with each of seven different emotional states, resulting in 1,092 video clips. We empirically demonstrate that 1) textual emotion recognition in spoken language mitigates data scarcity in sign language, 2) temporal segment selection has a significant impact, and 3) incorporating hand motion enhances emotion recognition in signers. Finally we establish a stronger baseline than spoken language LLMs.
OmniMER: Indonesian Multimodal Emotion Recognition via Auxiliary-Enhanced LLM Adaptation
Dec 22, 2025Indonesian, spoken by over 200 million people, remains underserved in multimodal emotion recognition research despite its dominant presence on Southeast Asian social media platforms. We introduce IndoMER, the first multimodal emotion recognition benchmark for Indonesian, comprising 1,944 video segments from 203 speakers with temporally aligned text, audio, and visual annotations across seven emotion categories. The dataset exhibits realistic challenges including cross-modal inconsistency and long-tailed class distributions shaped by Indonesian cultural communication norms. To address these challenges, we propose OmniMER, a multimodal adaptation framework built upon Qwen2.5-Omni that enhances emotion recognition through three auxiliary modality-specific perception tasks: emotion keyword extraction for text, facial expression analysis for video, and prosody analysis for audio. These auxiliary tasks help the model identify emotion-relevant cues in each modality before fusion, reducing reliance on spurious correlations in low-resource settings. Experiments on IndoMER show that OmniMER achieves 0.582 Macro-F1 on sentiment classification and 0.454 on emotion recognition, outperforming the base model by 7.6 and 22.1 absolute points respectively. Cross-lingual evaluation on the Chinese CH-SIMS dataset further demonstrates the generalizability of the proposed framework. The dataset and code are publicly available. https://github.com/yanxm01/INDOMER
Multi-Track Multimodal Learning on iMiGUE: Micro-Gesture and Emotion Recognition
Dec 29, 2025Micro-gesture recognition and behavior-based emotion prediction are both highly challenging tasks that require modeling subtle, fine-grained human behaviors, primarily leveraging video and skeletal pose data. In this work, we present two multimodal frameworks designed to tackle both problems on the iMiGUE dataset. For micro-gesture classification, we explore the complementary strengths of RGB and 3D pose-based representations to capture nuanced spatio-temporal patterns. To comprehensively represent gestures, video, and skeletal embeddings are extracted using MViTv2-S and 2s-AGCN, respectively. Then, they are integrated through a Cross-Modal Token Fusion module to combine spatial and pose information. For emotion recognition, our framework extends to behavior-based emotion prediction, a binary classification task identifying emotional states based on visual cues. We leverage facial and contextual embeddings extracted using SwinFace and MViTv2-S models and fuse them through an InterFusion module designed to capture emotional expressions and body gestures. Experiments conducted on the iMiGUE dataset, within the scope of the MiGA 2025 Challenge, demonstrate the robust performance and accuracy of our method in the behavior-based emotion prediction task, where our approach secured 2nd place.
Transformer-Driven Multimodal Fusion for Explainable Suspiciousness Estimation in Visual Surveillance
Dec 10, 2025Suspiciousness estimation is critical for proactive threat detection and ensuring public safety in complex environments. This work introduces a large-scale annotated dataset, USE50k, along with a computationally efficient vision-based framework for real-time suspiciousness analysis. The USE50k dataset contains 65,500 images captured from diverse and uncontrolled environments, such as airports, railway stations, restaurants, parks, and other public areas, covering a broad spectrum of cues including weapons, fire, crowd density, abnormal facial expressions, and unusual body postures. Building on this dataset, we present DeepUSEvision, a lightweight and modular system integrating three key components, i.e., a Suspicious Object Detector based on an enhanced YOLOv12 architecture, dual Deep Convolutional Neural Networks (DCNN-I and DCNN-II) for facial expression and body-language recognition using image and landmark features, and a transformer-based Discriminator Network that adaptively fuses multimodal outputs to yield an interpretable suspiciousness score. Extensive experiments confirm the superior accuracy, robustness, and interpretability of the proposed framework compared to state-of-the-art approaches. Collectively, the USE50k dataset and the DeepUSEvision framework establish a strong and scalable foundation for intelligent surveillance and real-time risk assessment in safety-critical applications.
Aesthetics as Structural Harm: Algorithmic Lookism Across Text-to-Image Generation and Classification
Jan 15, 2026This paper examines algorithmic lookism-the systematic preferential treatment based on physical appearance-in text-to-image (T2I) generative AI and a downstream gender classification task. Through the analysis of 26,400 synthetic faces created with Stable Diffusion 2.1 and 3.5 Medium, we demonstrate how generative AI models systematically associate facial attractiveness with positive attributes and vice-versa, mirroring socially constructed biases rather than evidence-based correlations. Furthermore, we find significant gender bias in three gender classification algorithms depending on the attributes of the input faces. Our findings reveal three critical harms: (1) the systematic encoding of attractiveness-positive attribute associations in T2I models; (2) gender disparities in classification systems, where women's faces, particularly those generated with negative attributes, suffer substantially higher misclassification rates than men's; and (3) intensifying aesthetic constraints in newer models through age homogenization, gendered exposure patterns, and geographic reductionism. These convergent patterns reveal algorithmic lookism as systematic infrastructure operating across AI vision systems, compounding existing inequalities through both representation and recognition. Disclaimer: This work includes visual and textual content that reflects stereotypical associations between physical appearance and socially constructed attributes, including gender, race, and traits associated with social desirability. Any such associations found in this study emerge from the biases embedded in generative AI systems-not from empirical truths or the authors' views.
Evaluation of Generative Models for Emotional 3D Animation Generation in VR
Dec 18, 2025Social interactions incorporate nonverbal signals to convey emotions alongside speech, including facial expressions and body gestures. Generative models have demonstrated promising results in creating full-body nonverbal animations synchronized with speech; however, evaluations using statistical metrics in 2D settings fail to fully capture user-perceived emotions, limiting our understanding of model effectiveness. To address this, we evaluate emotional 3D animation generative models within a Virtual Reality (VR) environment, emphasizing user-centric metrics emotional arousal realism, naturalness, enjoyment, diversity, and interaction quality in a real-time human-agent interaction scenario. Through a user study (N=48), we examine perceived emotional quality for three state of the art speech-driven 3D animation methods across two emotions happiness (high arousal) and neutral (mid arousal). Additionally, we compare these generative models against real human expressions obtained via a reconstruction-based method to assess both their strengths and limitations and how closely they replicate real human facial and body expressions. Our results demonstrate that methods explicitly modeling emotions lead to higher recognition accuracy compared to those focusing solely on speech-driven synchrony. Users rated the realism and naturalness of happy animations significantly higher than those of neutral animations, highlighting the limitations of current generative models in handling subtle emotional states. Generative models underperformed compared to reconstruction-based methods in facial expression quality, and all methods received relatively low ratings for animation enjoyment and interaction quality, emphasizing the importance of incorporating user-centric evaluations into generative model development. Finally, participants positively recognized animation diversity across all generative models.
USTM: Unified Spatial and Temporal Modeling for Continuous Sign Language Recognition
Dec 15, 2025Continuous sign language recognition (CSLR) requires precise spatio-temporal modeling to accurately recognize sequences of gestures in videos. Existing frameworks often rely on CNN-based spatial backbones combined with temporal convolution or recurrent modules. These techniques fail in capturing fine-grained hand and facial cues and modeling long-range temporal dependencies. To address these limitations, we propose the Unified Spatio-Temporal Modeling (USTM) framework, a spatio-temporal encoder that effectively models complex patterns using a combination of a Swin Transformer backbone enhanced with lightweight temporal adapter with positional embeddings (TAPE). Our framework captures fine-grained spatial features alongside short and long-term temporal context, enabling robust sign language recognition from RGB videos without relying on multi-stream inputs or auxiliary modalities. Extensive experiments on benchmarked datasets including PHOENIX14, PHOENIX14T, and CSL-Daily demonstrate that USTM achieves state-of-the-art performance against RGB-based as well as multi-modal CSLR approaches, while maintaining competitive performance against multi-stream approaches. These results highlight the strength and efficacy of the USTM framework for CSLR. The code is available at https://github.com/gufranSabri/USTM
A Hybrid Deep Learning Framework for Emotion Recognition in Children with Autism During NAO Robot-Mediated Interaction
Dec 13, 2025Understanding emotional responses in children with Autism Spectrum Disorder (ASD) during social interaction remains a critical challenge in both developmental psychology and human-robot interaction. This study presents a novel deep learning pipeline for emotion recognition in autistic children in response to a name-calling event by a humanoid robot (NAO), under controlled experimental settings. The dataset comprises of around 50,000 facial frames extracted from video recordings of 15 children with ASD. A hybrid model combining a fine-tuned ResNet-50-based Convolutional Neural Network (CNN) and a three-layer Graph Convolutional Network (GCN) trained on both visual and geometric features extracted from MediaPipe FaceMesh landmarks. Emotions were probabilistically labeled using a weighted ensemble of two models: DeepFace's and FER, each contributing to soft-label generation across seven emotion classes. Final classification leveraged a fused embedding optimized via Kullback-Leibler divergence. The proposed method demonstrates robust performance in modeling subtle affective responses and offers significant promise for affective profiling of ASD children in clinical and therapeutic human-robot interaction contexts, as the pipeline effectively captures micro emotional cues in neurodivergent children, addressing a major gap in autism-specific HRI research. This work represents the first such large-scale, real-world dataset and pipeline from India on autism-focused emotion analysis using social robotics, contributing an essential foundation for future personalized assistive technologies.