 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging the gap in FER: addressing age bias in deep learning
Jul 10, 2025
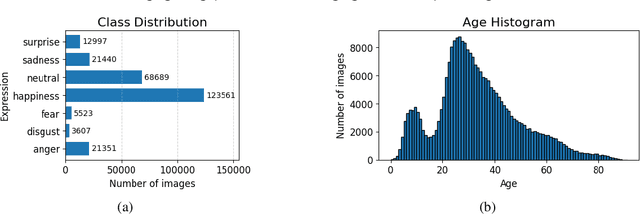
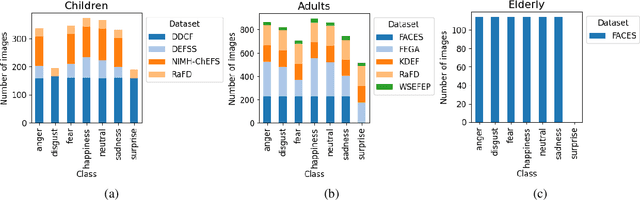
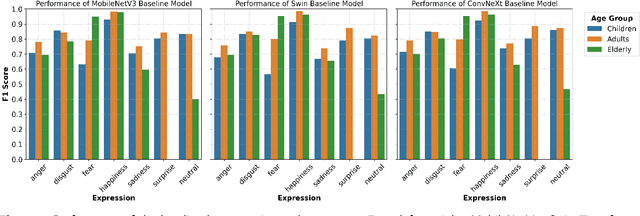
Facial Expression Recognition (FER) systems based on deep learning have achieved impressive performance in recent years. However, these models often exhibit demographic biases, particularly with respect to age, which can compromise their fairness and reliability. In this work, we present a comprehensive study of age-related bias in deep FER models, with a particular focus on the elderly population. We first investigate whether recognition performance varies across age groups, which expressions are most affected, and whether model attention differs depending on age. Using Explainable AI (XAI) techniques, we identify systematic disparities in expression recognition and attention patterns, especially for "neutral", "sadness", and "anger" in elderly individuals. Based on these findings, we propose and evaluate three bias mitigation strategies: Multi-task Learning, Multi-modal Input, and Age-weighted Loss. Our models are trained on a large-scale dataset, AffectNet, with automatically estimated age labels and validated on balanced benchmark datasets that include underrepresented age groups. Results show consistent improvements in recognition accuracy for elderly individuals, particularly for the most error-prone expressions. Saliency heatmap analysis reveals that models trained with age-aware strategies attend to more relevant facial regions for each age group, helping to explain the observed improvements. These findings suggest that age-related bias in FER can be effectively mitigated using simple training modifications, and that even approximate demographic labels can be valuable for promoting fairness in large-scale affective computing systems.
Evaluating Facial Expression Recognition Datasets for Deep Learning: A Benchmark Study with Novel Similarity Metrics
Mar 26, 2025



This study investigates the key characteristics and suitability of widely used Facial Expression Recognition (FER) datasets for training deep learning models. In the field of affective computing, FER is essential for interpreting human emotions, yet the performance of FER systems is highly contingent on the quality and diversity of the underlying datasets. To address this issue, we compiled and analyzed 24 FER datasets, including those targeting specific age groups such as children, adults, and the elderly, and processed them through a comprehensive normalization pipeline. In addition, we enriched the datasets with automatic annotations for age and gender, enabling a more nuanced evaluation of their demographic properties. To further assess dataset efficacy, we introduce three novel metricsLocal, Global, and Paired Similarity, which quantitatively measure dataset difficulty, generalization capability, and cross-dataset transferability. Benchmark experiments using state-of-the-art neural networks reveal that large-scale, automatically collected datasets (e.g., AffectNet, FER2013) tend to generalize better, despite issues with labeling noise and demographic biases, whereas controlled datasets offer higher annotation quality but limited variability. Our findings provide actionable recommendations for dataset selection and design, advancing the development of more robust, fair, and effective FER systems.
Deep Learning-Based Facial Expression Recognition for the Elderly: A Systematic Review
Feb 04, 2025



The rapid aging of the global population has highlighted the need for technologies to support elderly, particularly in healthcare and emotional well-being. Facial expression recognition (FER) systems offer a non-invasive means of monitoring emotional states, with applications in assisted living, mental health support, and personalized care. This study presents a systematic review of deep learning-based FER systems, focusing on their applications for the elderly population. Following a rigorous methodology, we analyzed 31 studies published over the last decade, addressing challenges such as the scarcity of elderly-specific datasets, class imbalances, and the impact of age-related facial expression differences. Our findings show that convolutional neural networks remain dominant in FER, and especially lightweight versions for resource-constrained environments. However, existing datasets often lack diversity in age representation, and real-world deployment remains limited. Additionally, privacy concerns and the need for explainable artificial intelligence emerged as key barriers to adoption. This review underscores the importance of developing age-inclusive datasets, integrating multimodal solutions, and adopting XAI techniques to enhance system usability, reliability, and trustworthiness. We conclude by offering recommendations for future research to bridge the gap between academic progress and real-world implementation in elderly care.
Evaluating the Feasibility of Standard Facial Expression Recognition in Individuals with Moderate to Severe Intellectual Disabilities
Jan 22, 2024



Recent research has underscored the increasing preference of users for human-like interactions with machines. Consequently, facial expression recognition has gained significance as a means of imparting social robots with the capacity to discern the emotional states of users. In this investigation, we assess the suitability of deep learning approaches, known for their remarkable performance in this domain, for recognizing facial expressions in individuals with intellectual disabilities, which has not been yet studied in the literature, to the best of our knowledge. To address this objective, we train a set of twelve distinct convolutional neural networks in different approaches, including an ensemble of datasets without individuals with intellectual disabilities and a dataset featuring such individuals. Our examination of the outcomes achieved by the various models under distinct training conditions, coupled with a comprehensive analysis of critical facial regions during expression recognition facilitated by explainable artificial intelligence techniques, revealed significant distinctions in facial expressions between individuals with and without intellectual disabilities, as well as among individuals with intellectual disabilities. Remarkably, our findings demonstrate the feasibility of facial expression recognition within this population through tailored user-specific training methodologies, which enable the models to effectively address the unique expressions of each user.
Local Agnostic Video Explanations: a Study on the Applicability of Removal-Based Explanations to Video
Jan 22, 2024



Explainable artificial intelligence techniques are becoming increasingly important with the rise of deep learning applications in various domains. These techniques aim to provide a better understanding of complex "black box" models and enhance user trust while maintaining high learning performance. While many studies have focused on explaining deep learning models in computer vision for image input, video explanations remain relatively unexplored due to the temporal dimension's complexity. In this paper, we present a unified framework for local agnostic explanations in the video domain. Our contributions include: (1) Extending a fine-grained explanation framework tailored for computer vision data, (2) Adapting six existing explanation techniques to work on video data by incorporating temporal information and enabling local explanations, and (3) Conducting an evaluation and comparison of the adapted explanation methods using different models and datasets. We discuss the possibilities and choices involved in the removal-based explanation process for visual data. The adaptation of six explanation methods for video is explained, with comparisons to existing approaches. We evaluate the performance of the methods using automated metrics and user-based evaluation, showing that 3D RISE, 3D LIME, and 3D Kernel SHAP outperform other methods. By decomposing the explanation process into manageable steps, we facilitate the study of each choice's impact and allow for further refinement of explanation methods to suit specific datasets and models.
Deep Learning for Computer Vision based Activity Recognition and Fall Detection of the Elderly: a Systematic Review
Jan 22, 2024As the percentage of elderly people in developed countries increases worldwide, the healthcare of this collective is a worrying matter, especially if it includes the preservation of their autonomy. In this direction, many studies are being published on Ambient Assisted Living (AAL) systems, which help to reduce the preoccupations raised by the independent living of the elderly. In this study, a systematic review of the literature is presented on fall detection and Human Activity Recognition (HAR) for the elderly, as the two main tasks to solve to guarantee the safety of elderly people living alone. To address the current tendency to perform these two tasks, the review focuses on the use of Deep Learning (DL) based approaches on computer vision data. In addition, different collections of data like DL models, datasets or hardware (e.g. depth or thermal cameras) are gathered from the reviewed studies and provided for reference in future studies. Strengths and weaknesses of existing approaches are also discussed and, based on them, our recommendations for future works are provided.
Unveiling the Human-like Similarities of Automatic Facial Expression Recognition: An Empirical Exploration through Explainable AI
Jan 22, 2024Facial expression recognition is vital for human behavior analysis, and deep learning has enabled models that can outperform humans. However, it is unclear how closely they mimic human processing. This study aims to explore the similarity between deep neural networks and human perception by comparing twelve different networks, including both general object classifiers and FER-specific models. We employ an innovative global explainable AI method to generate heatmaps, revealing crucial facial regions for the twelve networks trained on six facial expressions. We assess these results both quantitatively and qualitatively, comparing them to ground truth masks based on Friesen and Ekman's description and among them. We use Intersection over Union (IoU) and normalized correlation coefficients for comparisons. We generate 72 heatmaps to highlight critical regions for each expression and architecture. Qualitatively, models with pre-trained weights show more similarity in heatmaps compared to those without pre-training. Specifically, eye and nose areas influence certain facial expressions, while the mouth is consistently important across all models and expressions. Quantitatively, we find low average IoU values (avg. 0.2702) across all expressions and architectures. The best-performing architecture averages 0.3269, while the worst-performing one averages 0.2066. Dendrograms, built with the normalized correlation coefficient, reveal two main clusters for most expressions: models with pre-training and models without pre-training. Findings suggest limited alignment between human and AI facial expression recognition, with network architectures influencing the similarity, as similar architectures prioritize similar facial regions.
Assessing Gender Bias in Predictive Algorithms using eXplainable AI
Mar 19, 2022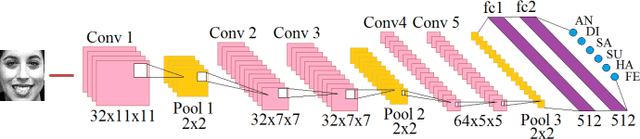
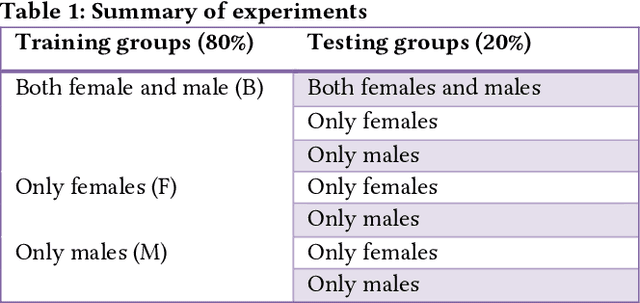
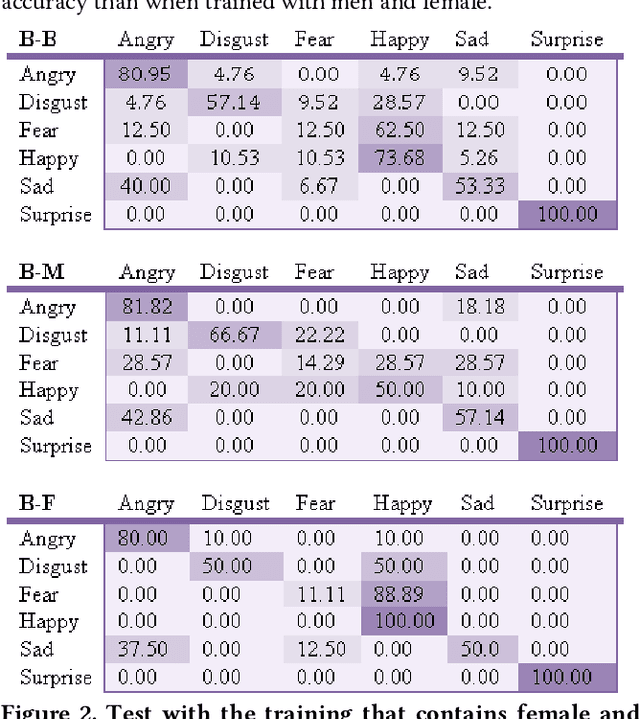
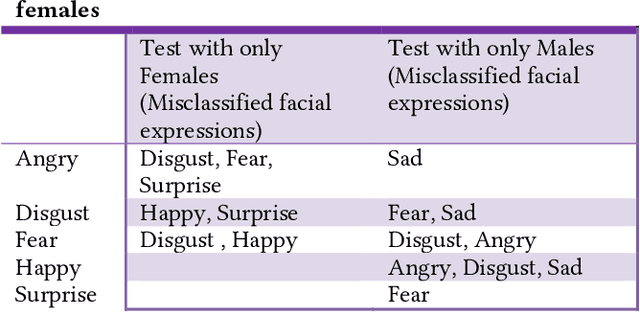
Predictive algorithms have a powerful potential to offer benefits in areas as varied as medicine or education. However, these algorithms and the data they use are built by humans, consequently, they can inherit the bias and prejudices present in humans. The outcomes can systematically repeat errors that create unfair results, which can even lead to situations of discrimination (e.g. gender, social or racial). In order to illustrate how important is to count with a diverse training dataset to avoid bias, we manipulate a well-known facial expression recognition dataset to explore gender bias and discuss its implications.