 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSlot Filling
Papers and Code
Introducing Semantics into Speech Encoders
Nov 15, 2022



Recent studies find existing self-supervised speech encoders contain primarily acoustic rather than semantic information. As a result, pipelined supervised automatic speech recognition (ASR) to large language model (LLM) systems achieve state-of-the-art results on semantic spoken language tasks by utilizing rich semantic representations from the LLM. These systems come at the cost of labeled audio transcriptions, which is expensive and time-consuming to obtain. We propose a task-agnostic unsupervised way of incorporating semantic information from LLMs into self-supervised speech encoders without labeled audio transcriptions. By introducing semantics, we improve existing speech encoder spoken language understanding performance by over 10\% on intent classification, with modest gains in named entity resolution and slot filling, and spoken question answering FF1 score by over 2\%. Our unsupervised approach achieves similar performance as supervised methods trained on over 100 hours of labeled audio transcripts, demonstrating the feasibility of unsupervised semantic augmentations to existing speech encoders.
A Dynamic Graph Interactive Framework with Label-Semantic Injection for Spoken Language Understanding
Nov 08, 2022Multi-intent detection and slot filling joint models are gaining increasing traction since they are closer to complicated real-world scenarios. However, existing approaches (1) focus on identifying implicit correlations between utterances and one-hot encoded labels in both tasks while ignoring explicit label characteristics; (2) directly incorporate multi-intent information for each token, which could lead to incorrect slot prediction due to the introduction of irrelevant intent. In this paper, we propose a framework termed DGIF, which first leverages the semantic information of labels to give the model additional signals and enriched priors. Then, a multi-grain interactive graph is constructed to model correlations between intents and slots. Specifically, we propose a novel approach to construct the interactive graph based on the injection of label semantics, which can automatically update the graph to better alleviate error propagation. Experimental results show that our framework significantly outperforms existing approaches, obtaining a relative improvement of 13.7% over the previous best model on the MixATIS dataset in overall accuracy.
End-to-end Spoken Language Understanding with Tree-constrained Pointer Generator
Oct 29, 2022End-to-end spoken language understanding (SLU) suffers from the long-tail word problem. This paper exploits contextual biasing, a technique to improve the speech recognition of rare words, in end-to-end SLU systems. Specifically, a tree-constrained pointer generator (TCPGen), a powerful and efficient biasing model component, is studied, which leverages a slot shortlist with corresponding entities to extract biasing lists. Meanwhile, to bias the SLU model output slot distribution, a slot probability biasing (SPB) mechanism is proposed to calculate a slot distribution from TCPGen. Experiments on the SLURP dataset showed consistent SLU-F1 improvements using TCPGen and SPB, especially on unseen entities. On a new split by holding out 5 slot types for the test, TCPGen with SPB achieved zero-shot learning with an SLU-F1 score over 50% compared to baselines which can not deal with it. In addition to slot filling, the intent classification accuracy was also improved.
A Fast Attention Network for Joint Intent Detection and Slot Filling on Edge Devices
May 16, 2022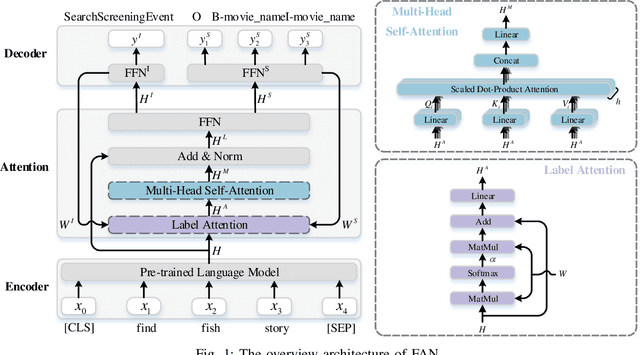
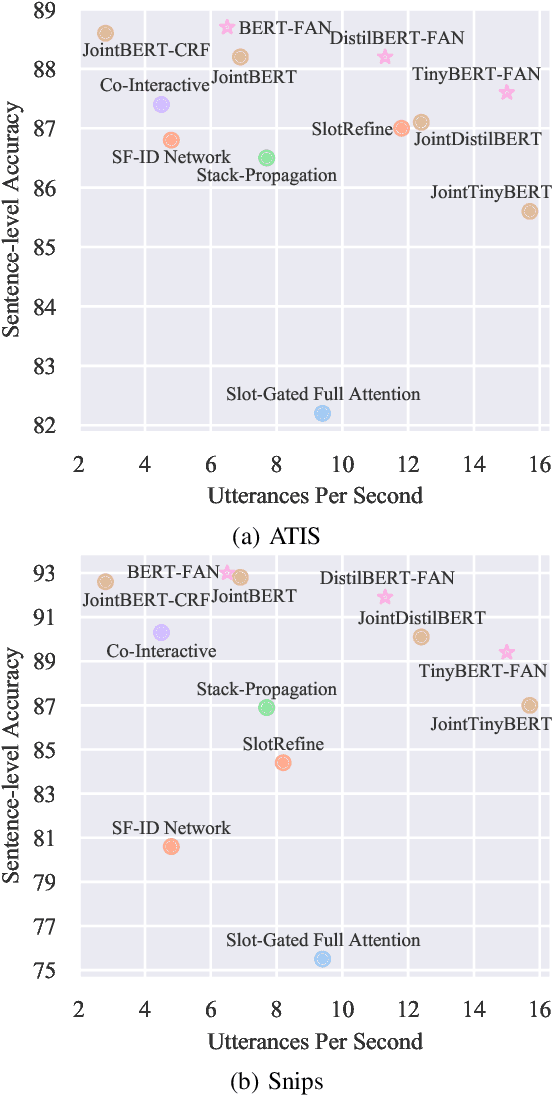
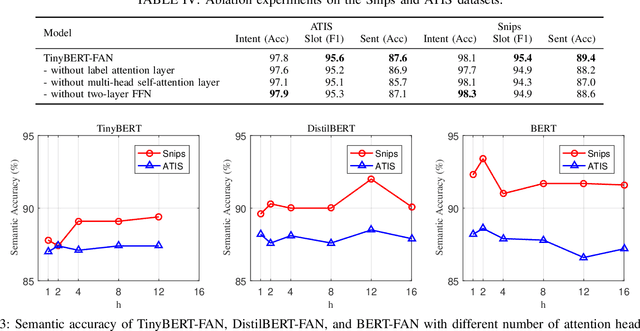
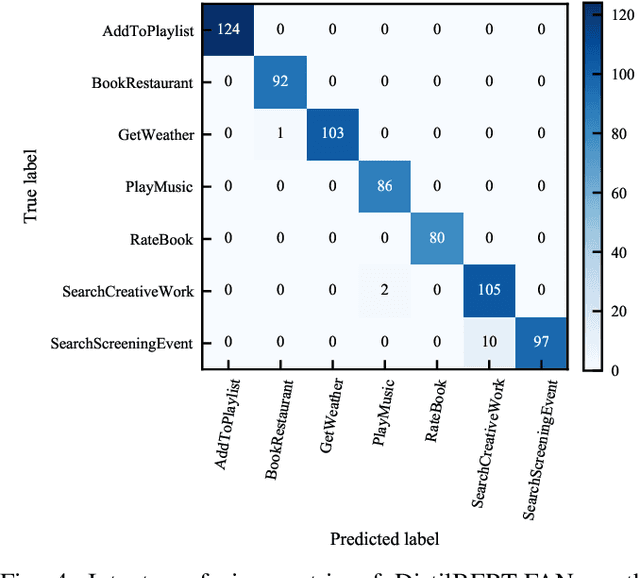
Intent detection and slot filling are two main tasks in natural language understanding and play an essential role in task-oriented dialogue systems. The joint learning of both tasks can improve inference accuracy and is popular in recent works. However, most joint models ignore the inference latency and cannot meet the need to deploy dialogue systems at the edge. In this paper, we propose a Fast Attention Network (FAN) for joint intent detection and slot filling tasks, guaranteeing both accuracy and latency. Specifically, we introduce a clean and parameter-refined attention module to enhance the information exchange between intent and slot, improving semantic accuracy by more than 2%. FAN can be implemented on different encoders and delivers more accurate models at every speed level. Our experiments on the Jetson Nano platform show that FAN inferences fifteen utterances per second with a small accuracy drop, showing its effectiveness and efficiency on edge devices.
A Unified Framework for Multi-intent Spoken Language Understanding with prompting
Oct 07, 2022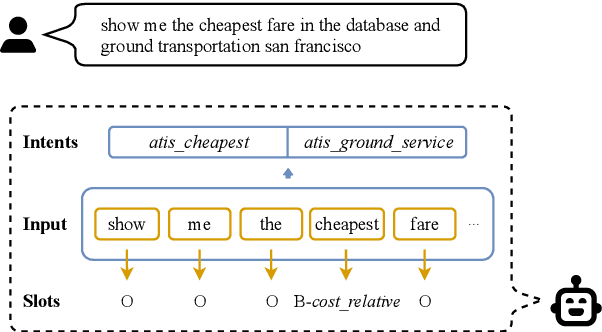
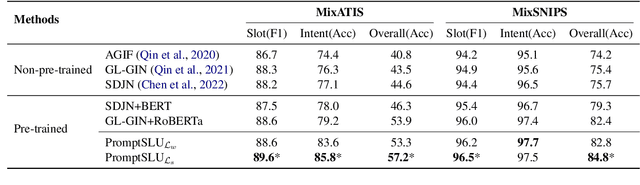
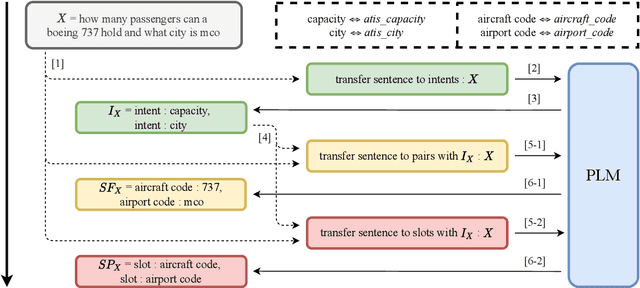
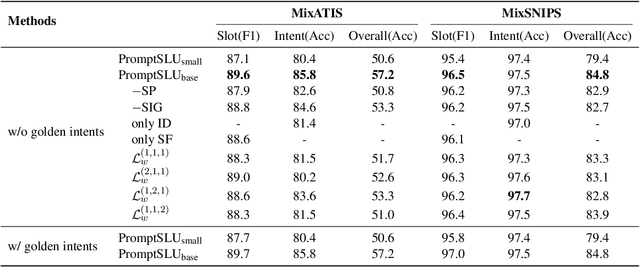
Multi-intent Spoken Language Understanding has great potential for widespread implementation. Jointly modeling Intent Detection and Slot Filling in it provides a channel to exploit the correlation between intents and slots. However, current approaches are apt to formulate these two sub-tasks differently, which leads to two issues: 1) It hinders models from effective extraction of shared features. 2) Pretty complicated structures are involved to enhance expression ability while causing damage to the interpretability of frameworks. In this work, we describe a Prompt-based Spoken Language Understanding (PromptSLU) framework, to intuitively unify two sub-tasks into the same form by offering a common pre-trained Seq2Seq model. In detail, ID and SF are completed by concisely filling the utterance into task-specific prompt templates as input, and sharing output formats of key-value pairs sequence. Furthermore, variable intents are predicted first, then naturally embedded into prompts to guide slot-value pairs inference from a semantic perspective. Finally, we are inspired by prevalent multi-task learning to introduce an auxiliary sub-task, which helps to learn relationships among provided labels. Experiment results show that our framework outperforms several state-of-the-art baselines on two public datasets.
Entity Aware Syntax Tree Based Data Augmentation for Natural Language Understanding
Sep 06, 2022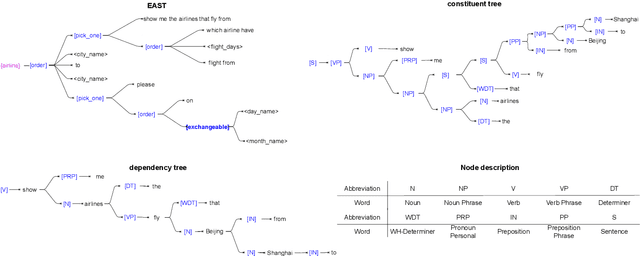

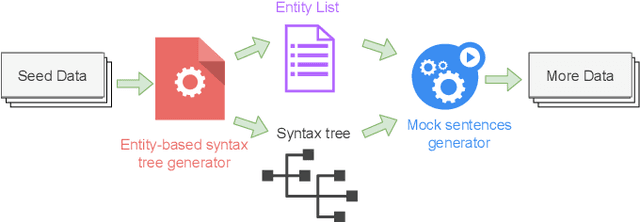
Understanding the intention of the users and recognizing the semantic entities from their sentences, aka natural language understanding (NLU), is the upstream task of many natural language processing tasks. One of the main challenges is to collect a sufficient amount of annotated data to train a model. Existing research about text augmentation does not abundantly consider entity and thus performs badly for NLU tasks. To solve this problem, we propose a novel NLP data augmentation technique, Entity Aware Data Augmentation (EADA), which applies a tree structure, Entity Aware Syntax Tree (EAST), to represent sentences combined with attention on the entity. Our EADA technique automatically constructs an EAST from a small amount of annotated data, and then generates a large number of training instances for intent detection and slot filling. Experimental results on four datasets showed that the proposed technique significantly outperforms the existing data augmentation methods in terms of both accuracy and generalization ability.
Bi-directional Joint Neural Networks for Intent Classification and Slot Filling
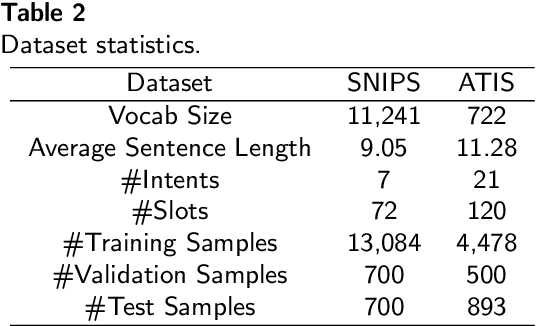
Feb 26, 2022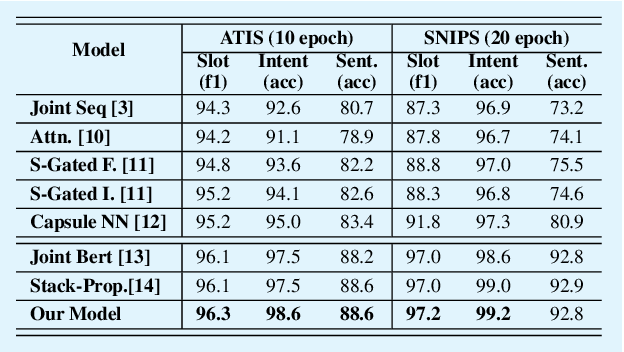
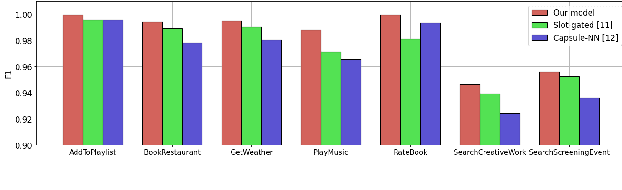
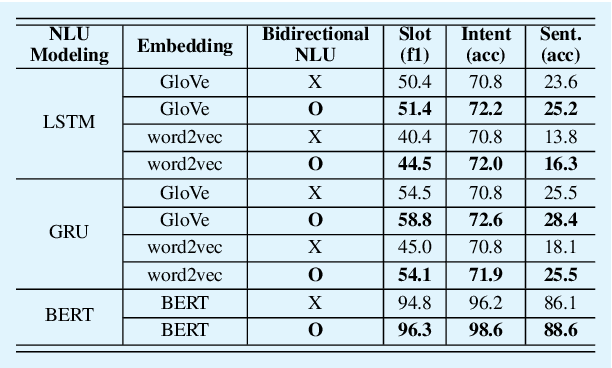
Intent classification and slot filling are two critical tasks for natural language understanding. Traditionally the two tasks proceeded independently. However, more recently joint models for intent classification and slot filling have achieved state-of-the-art performance, and have proved that there exists a strong relationship between the two tasks. In this paper, we propose a bi-directional joint model for intent classification and slot filling, which includes a multi-stage hierarchical process via BERT and bi-directional joint natural language understanding mechanisms, including intent2slot and slot2intent, to obtain mutual performance enhancement between intent classification and slot filling. The evaluations show that our model achieves state-of-the-art results on intent classification accuracy, slot filling F1, and significantly improves sentence-level semantic frame accuracy when applied to publicly available benchmark datasets, ATIS (88.6%) and SNIPS (92.8%).
A Unified Generative Framework based on Prompt Learning for Various Information Extraction Tasks
Sep 23, 2022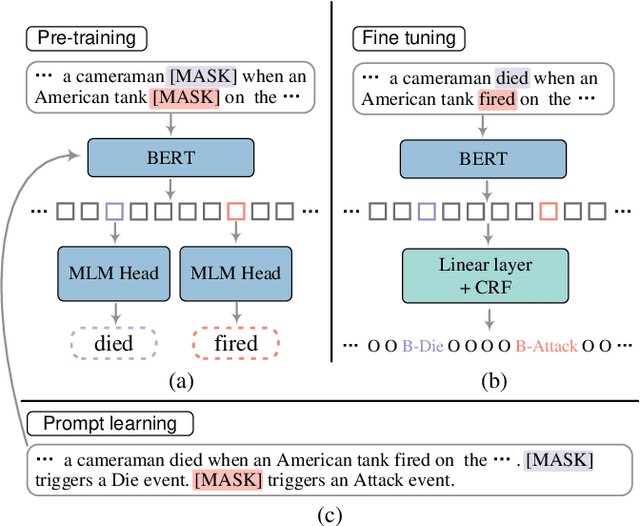
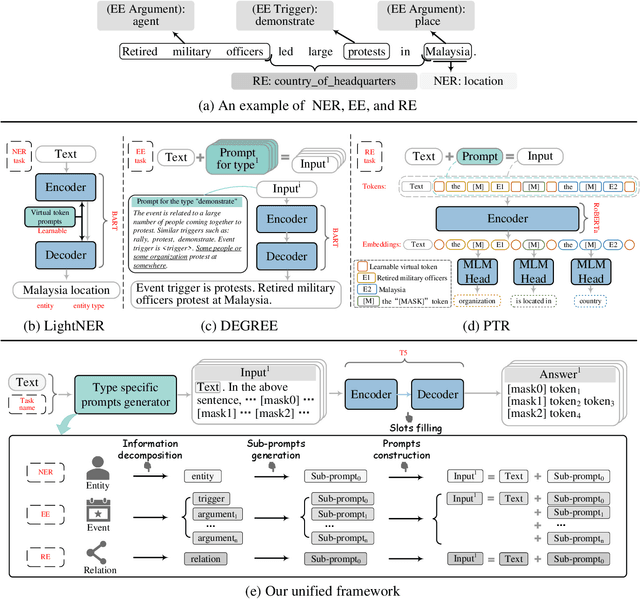
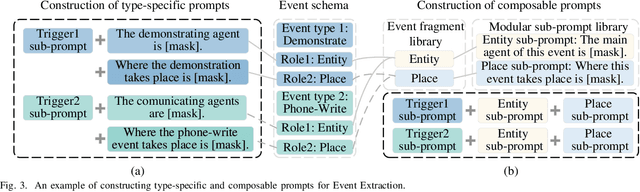
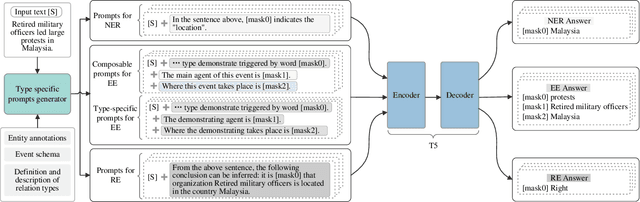
Prompt learning is an effective paradigm that bridges gaps between the pre-training tasks and the corresponding downstream applications. Approaches based on this paradigm have achieved great transcendent results in various applications. However, it still needs to be answered how to design a unified framework based on the prompt learning paradigm for various information extraction tasks. In this paper, we propose a novel composable prompt-based generative framework, which could be applied to a wide range of tasks in the field of Information Extraction. Specifically, we reformulate information extraction tasks into the form of filling slots in pre-designed type-specific prompts, which consist of one or multiple sub-prompts. A strategy of constructing composable prompts is proposed to enhance the generalization ability to extract events in data-scarce scenarios. Furthermore, to fit this framework, we transform Relation Extraction into the task of determining semantic consistency in prompts. The experimental results demonstrate that our approach surpasses compared baselines on real-world datasets in data-abundant and data-scarce scenarios. Further analysis of the proposed framework is presented, as well as numerical experiments conducted to investigate impact factors of performance on various tasks.
mcBERT: Momentum Contrastive Learning with BERT for Zero-Shot Slot Filling
Mar 24, 2022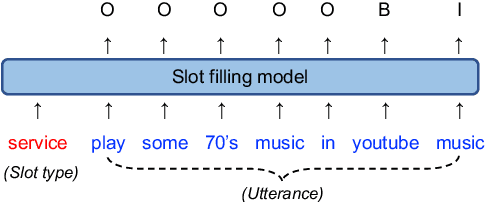
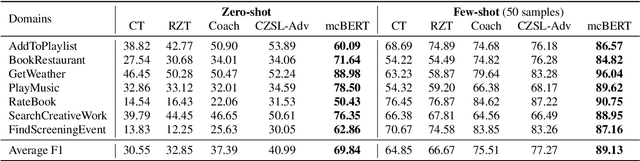
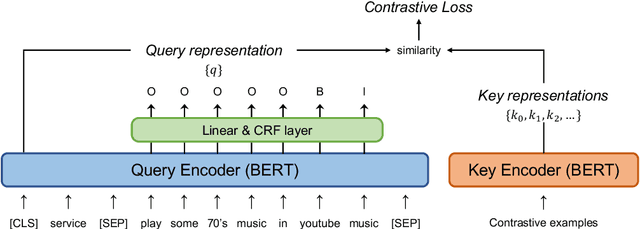
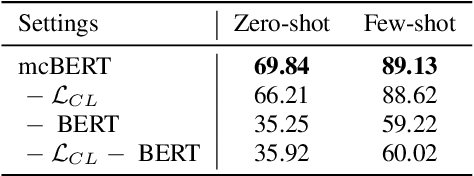
Zero-shot slot filling has received considerable attention to cope with the problem of limited available data for the target domain. One of the important factors in zero-shot learning is to make the model learn generalized and reliable representations. For this purpose, we present mcBERT, which stands for momentum contrastive learning with BERT, to develop a robust zero-shot slot filling model. mcBERT uses BERT to initialize the two encoders, the query encoder and key encoder, and is trained by applying momentum contrastive learning. Our experimental results on the SNIPS benchmark show that mcBERT substantially outperforms the previous models, recording a new state-of-the-art. Besides, we also show that each component composing mcBERT contributes to the performance improvement.
LAD: Language Models as Data for Zero-Shot Dialog
Jul 28, 2022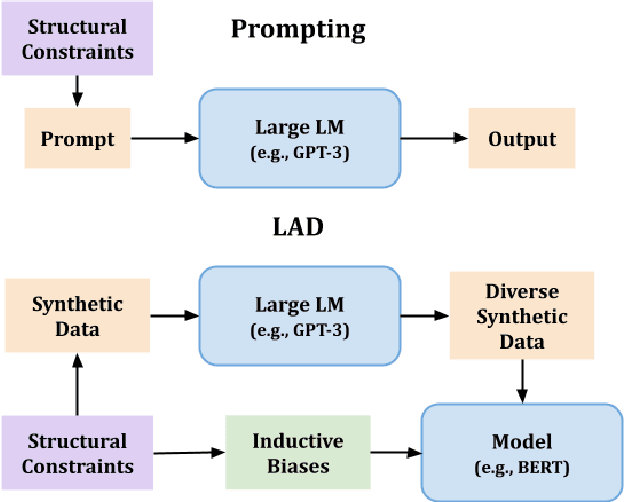
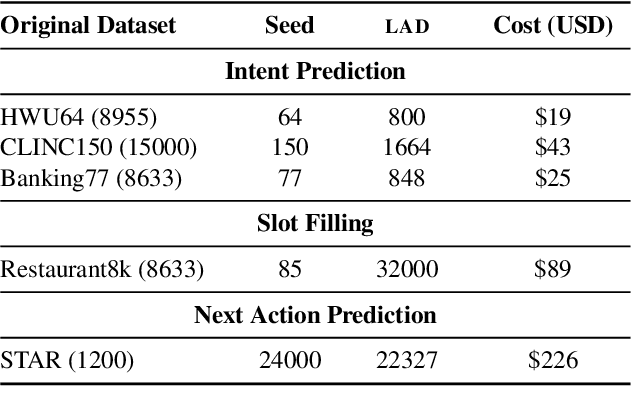
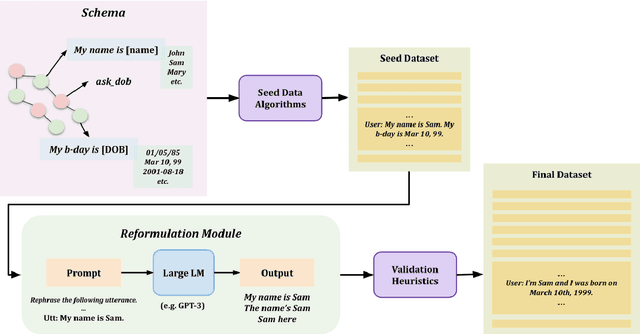

To facilitate zero-shot generalization in taskoriented dialog, this paper proposes Language Models as Data (LAD). LAD is a paradigm for creating diverse and accurate synthetic data which conveys the necessary structural constraints and can be used to train a downstream neural dialog model. LAD leverages GPT-3 to induce linguistic diversity. LAD achieves significant performance gains in zero-shot settings on intent prediction (+15%), slot filling (+31.4 F-1) and next action prediction (+11 F1). Furthermore, an interactive human evaluation shows that training with LAD is competitive with training on human dialogs. LAD is open-sourced, with the code and data available at https://github.com/Shikib/lad.