 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTell Me Who Your Students Are: GPT Can Generate Valid Multiple-Choice Questions When Students' (Mis)Understanding Is Hinted
May 09, 2025The primary goal of this study is to develop and evaluate an innovative prompting technique, AnaQuest, for generating multiple-choice questions (MCQs) using a pre-trained large language model. In AnaQuest, the choice items are sentence-level assertions about complex concepts. The technique integrates formative and summative assessments. In the formative phase, students answer open-ended questions for target concepts in free text. For summative assessment, AnaQuest analyzes these responses to generate both correct and incorrect assertions. To evaluate the validity of the generated MCQs, Item Response Theory (IRT) was applied to compare item characteristics between MCQs generated by AnaQuest, a baseline ChatGPT prompt, and human-crafted items. An empirical study found that expert instructors rated MCQs generated by both AI models to be as valid as those created by human instructors. However, IRT-based analysis revealed that AnaQuest-generated questions - particularly those with incorrect assertions (foils) - more closely resembled human-crafted items in terms of difficulty and discrimination than those produced by ChatGPT.
Students' Perceptions and Preferences of Generative Artificial Intelligence Feedback for Programming
Dec 17, 2023The rapid evolution of artificial intelligence (AI), specifically large language models (LLMs), has opened opportunities for various educational applications. This paper explored the feasibility of utilizing ChatGPT, one of the most popular LLMs, for automating feedback for Java programming assignments in an introductory computer science (CS1) class. Specifically, this study focused on three questions: 1) To what extent do students view LLM-generated feedback as formative? 2) How do students see the comparative affordances of feedback prompts that include their code, vs. those that exclude it? 3) What enhancements do students suggest for improving AI-generated feedback? To address these questions, we generated automated feedback using the ChatGPT API for four lab assignments in the CS1 class. The survey results revealed that students perceived the feedback as aligning well with formative feedback guidelines established by Shute. Additionally, students showed a clear preference for feedback generated by including the students' code as part of the LLM prompt, and our thematic study indicated that the preference was mainly attributed to the specificity, clarity, and corrective nature of the feedback. Moreover, this study found that students generally expected specific and corrective feedback with sufficient code examples, but had diverged opinions on the tone of the feedback. This study demonstrated that ChatGPT could generate Java programming assignment feedback that students perceived as formative. It also offered insights into the specific improvements that would make the ChatGPT-generated feedback useful for students.
Assertion Enhanced Few-Shot Learning: Instructive Technique for Large Language Models to Generate Educational Explanations
Dec 05, 2023



Human educators possess an intrinsic ability to anticipate and seek educational explanations from students, which drives them to pose thought-provoking questions when students cannot articulate these explanations independently. We aim to imbue Intelligent Tutoring Systems with this ability using few-shot learning capability of Large Language Models. Our work proposes a novel prompting technique, Assertion Enhanced Few-Shot Learning, to facilitate the generation of accurate, detailed oriented educational explanations. Our central hypothesis is that, in educational domain, few-shot demonstrations are necessary but not a sufficient condition for quality explanation generation. We conducted a study involving 12 in-service teachers, comparing our approach to Traditional Few-Shot Learning. The results show that Assertion Enhanced Few-Shot Learning improves explanation accuracy by 15% and yields higher-quality explanations, as evaluated by teachers. We also conduct a qualitative ablation study to factor the impact of assertions to provide educator-friendly prompting guidelines for generating explanations in their domain of interest.
Entity Aware Syntax Tree Based Data Augmentation for Natural Language Understanding
Sep 06, 2022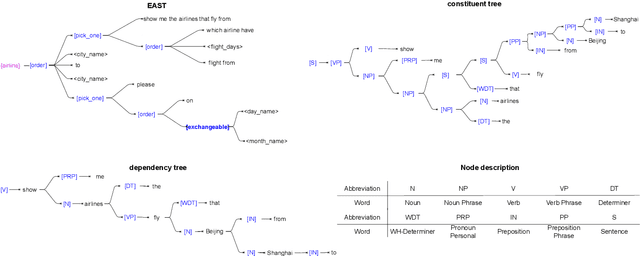

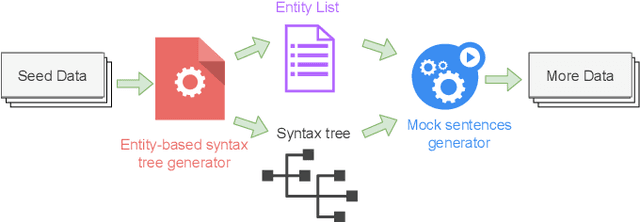
Understanding the intention of the users and recognizing the semantic entities from their sentences, aka natural language understanding (NLU), is the upstream task of many natural language processing tasks. One of the main challenges is to collect a sufficient amount of annotated data to train a model. Existing research about text augmentation does not abundantly consider entity and thus performs badly for NLU tasks. To solve this problem, we propose a novel NLP data augmentation technique, Entity Aware Data Augmentation (EADA), which applies a tree structure, Entity Aware Syntax Tree (EAST), to represent sentences combined with attention on the entity. Our EADA technique automatically constructs an EAST from a small amount of annotated data, and then generates a large number of training instances for intent detection and slot filling. Experimental results on four datasets showed that the proposed technique significantly outperforms the existing data augmentation methods in terms of both accuracy and generalization ability.