 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXbd
Papers and Code
From Pixels to Semantics: A Multi-Stage AI Framework for Structural Damage Detection in Satellite Imagery
Mar 24, 2026Rapid and accurate structural damage assessment following natural disasters is critical for effective emergency response and recovery. However, remote sensing imagery often suffers from low spatial resolution, contextual ambiguity, and limited semantic interpretability, reducing the reliability of traditional detection pipelines. In this work, we propose a novel hybrid framework that integrates AI-based super-resolution, deep learning object detection, and Vision-Language Models (VLMs) for comprehensive post-disaster building damage assessment. First, we enhance pre- and post-disaster satellite imagery using a Video Restoration Transformer (VRT) to upscale images from 1024x1024 to 4096x4096 resolution, improving structural detail visibility. Next, a YOLOv11-based detector localizes buildings in pre-disaster imagery, and cropped building regions are analyzed using VLMs to semantically assess structural damage across four severity levels. To ensure robust evaluation in the absence of ground-truth captions, we employ CLIPScore for reference-free semantic alignment and introduce a multi-model VLM-as-a-Jury strategy to reduce individual model bias in safety-critical decision making. Experiments on subsets of the xBD dataset, including the Moore Tornado and Hurricane Matthew events, demonstrate that the proposed framework enhances the semantic interpretation of damaged buildings. In addition, our framework provides helpful recommendations to first responders for recovery based on damage analysis.
Improved MambdaBDA Framework for Robust Building Damage Assessment Across Disaster Domains
Mar 04, 2026Reliable post-disaster building damage assessment (BDA) from satellite imagery is hindered by severe class imbalance, background clutter, and domain shift across disaster types and geographies. In this work, we address these problems and explore ways to improve the MambaBDA, the BDA network of ChangeMamba architecture, one of the most successful BDA models. The approach enhances the MambaBDA with three modular components: (i) Focal Loss to mitigate class imbalance damage classification, (ii) lightweight Attention Gates to suppress irrelevant context, and (iii) a compact Alignment Module to spatially warp pre-event features toward post-event content before decoding. We experiment on multiple satellite imagery datasets, including xBD, Pakistan Flooding, Turkey Earthquake, and Ida Hurricane, and conduct in-domain and crossdataset tests. The proposed modular enhancements yield consistent improvements over the baseline model, with 0.8% to 5% performance gains in-domain, and up to 27% on unseen disasters. This indicates that the proposed enhancements are especially beneficial for the generalization capability of the system.
Building Damage Detection using Satellite Images and Patch-Based Transformer Methods
Feb 08, 2026Rapid building damage assessment is critical for post-disaster response. Damage classification models built on satellite imagery provide a scalable means of obtaining situational awareness. However, label noise and severe class imbalance in satellite data create major challenges. The xBD dataset offers a standardized benchmark for building-level damage across diverse geographic regions. In this study, we evaluate Vision Transformer (ViT) model performance on the xBD dataset, specifically investigating how these models distinguish between types of structural damage when training on noisy, imbalanced data. In this study, we specifically evaluate DINOv2-small and DeiT for multi-class damage classification. We propose a targeted patch-based pre-processing pipeline to isolate structural features and minimize background noise in training. We adopt a frozen-head fine-tuning strategy to keep computational requirements manageable. Model performance is evaluated through accuracy, precision, recall, and macro-averaged F1 scores. We show that small ViT architectures with our novel training method achieves competitive macro-averaged F1 relative to prior CNN baselines for disaster classification.
DisasterInsight: A Multimodal Benchmark for Function-Aware and Grounded Disaster Assessment
Jan 26, 2026Timely interpretation of satellite imagery is critical for disaster response, yet existing vision-language benchmarks for remote sensing largely focus on coarse labels and image-level recognition, overlooking the functional understanding and instruction robustness required in real humanitarian workflows. We introduce DisasterInsight, a multimodal benchmark designed to evaluate vision-language models (VLMs) on realistic disaster analysis tasks. DisasterInsight restructures the xBD dataset into approximately 112K building-centered instances and supports instruction-diverse evaluation across multiple tasks, including building-function classification, damage-level and disaster-type classification, counting, and structured report generation aligned with humanitarian assessment guidelines. To establish domain-adapted baselines, we propose DI-Chat, obtained by fine-tuning existing VLM backbones on disaster-specific instruction data using parameter-efficient Low-Rank Adaptation (LoRA). Extensive experiments on state-of-the-art generic and remote-sensing VLMs reveal substantial performance gaps across tasks, particularly in damage understanding and structured report generation. DI-Chat achieves significant improvements on damage-level and disaster-type classification as well as report generation quality, while building-function classification remains challenging for all evaluated models. DisasterInsight provides a unified benchmark for studying grounded multimodal reasoning in disaster imagery.
The Potential of Copernicus Satellites for Disaster Response: Retrieving Building Damage from Sentinel-1 and Sentinel-2
Nov 07, 2025


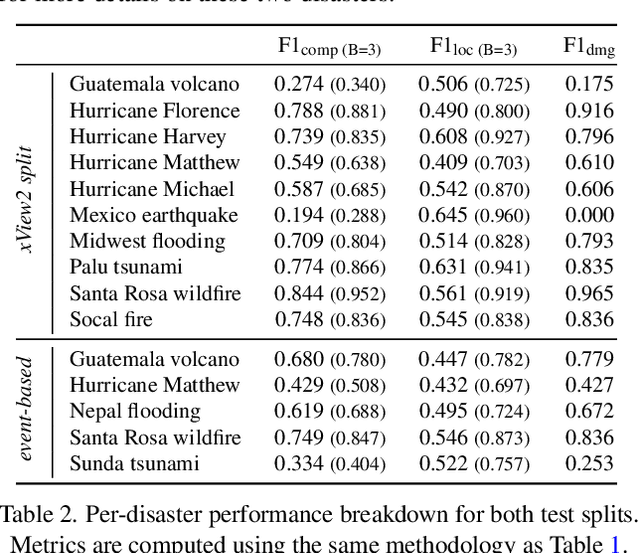
Natural disasters demand rapid damage assessment to guide humanitarian response. Here, we investigate whether medium-resolution Earth observation images from the Copernicus program can support building damage assessment, complementing very-high resolution imagery with often limited availability. We introduce xBD-S12, a dataset of 10,315 pre- and post-disaster image pairs from both Sentinel-1 and Sentinel-2, spatially and temporally aligned with the established xBD benchmark. In a series of experiments, we demonstrate that building damage can be detected and mapped rather well in many disaster scenarios, despite the moderate 10$\,$m ground sampling distance. We also find that, for damage mapping at that resolution, architectural sophistication does not seem to bring much advantage: more complex model architectures tend to struggle with generalization to unseen disasters, and geospatial foundation models bring little practical benefit. Our results suggest that Copernicus images are a viable data source for rapid, wide-area damage assessment and could play an important role alongside VHR imagery. We release the xBD-S12 dataset, code, and trained models to support further research.
Structural Damage Detection Using AI Super Resolution and Visual Language Model
Aug 23, 2025Natural disasters pose significant challenges to timely and accurate damage assessment due to their sudden onset and the extensive areas they affect. Traditional assessment methods are often labor-intensive, costly, and hazardous to personnel, making them impractical for rapid response, especially in resource-limited settings. This study proposes a novel, cost-effective framework that leverages aerial drone footage, an advanced AI-based video super-resolution model, Video Restoration Transformer (VRT), and Gemma3:27b, a 27 billion parameter Visual Language Model (VLM). This integrated system is designed to improve low-resolution disaster footage, identify structural damage, and classify buildings into four damage categories, ranging from no/slight damage to total destruction, along with associated risk levels. The methodology was validated using pre- and post-event drone imagery from the 2023 Turkey earthquakes (courtesy of The Guardian) and satellite data from the 2013 Moore Tornado (xBD dataset). The framework achieved a classification accuracy of 84.5%, demonstrating its ability to provide highly accurate results. Furthermore, the system's accessibility allows non-technical users to perform preliminary analyses, thereby improving the responsiveness and efficiency of disaster management efforts.
Distribution Shifts at Scale: Out-of-distribution Detection in Earth Observation
Dec 18, 2024Training robust deep learning models is critical in Earth Observation, where globally deployed models often face distribution shifts that degrade performance, especially in low-data regions. Out-of-distribution (OOD) detection addresses this challenge by identifying inputs that differ from in-distribution (ID) data. However, existing methods either assume access to OOD data or compromise primary task performance, making them unsuitable for real-world deployment. We propose TARDIS, a post-hoc OOD detection method for scalable geospatial deployments. The core novelty lies in generating surrogate labels by integrating information from ID data and unknown distributions, enabling OOD detection at scale. Our method takes a pre-trained model, ID data, and WILD samples, disentangling the latter into surrogate ID and surrogate OOD labels based on internal activations, and fits a binary classifier as an OOD detector. We validate TARDIS on EuroSAT and xBD datasets, across 17 experimental setups covering covariate and semantic shifts, showing that it performs close to the theoretical upper bound in assigning surrogate ID and OOD samples in 13 cases. To demonstrate scalability, we deploy TARDIS on the Fields of the World dataset, offering actionable insights into pre-trained model behavior for large-scale deployments. The code is publicly available at https://github.com/microsoft/geospatial-ood-detection.
Benchmarking Attention Mechanisms and Consistency Regularization Semi-Supervised Learning for Post-Flood Building Damage Assessment in Satellite Images
Dec 04, 2024



Post-flood building damage assessment is critical for rapid response and post-disaster reconstruction planning. Current research fails to consider the distinct requirements of disaster assessment (DA) from change detection (CD) in neural network design. This paper focuses on two key differences: 1) building change features in DA satellite images are more subtle than in CD; 2) DA datasets face more severe data scarcity and label imbalance. To address these issues, in terms of model architecture, the research explores the benchmark performance of attention mechanisms in post-flood DA tasks and introduces Simple Prior Attention UNet (SPAUNet) to enhance the model's ability to recognize subtle changes, in terms of semi-supervised learning (SSL) strategies, the paper constructs four different combinations of image-level label category reference distributions for consistent training. Experimental results on flood events of xBD dataset show that SPAUNet performs exceptionally well in supervised learning experiments, achieving a recall of 79.10\% and an F1 score of 71.32\% for damaged classification, outperforming CD methods. The results indicate the necessity of DA task-oriented model design. SSL experiments demonstrate the positive impact of image-level consistency regularization on the model. Using pseudo-labels to form the reference distribution for consistency training yields the best results, proving the potential of using the category distribution of a large amount of unlabeled data for SSL. This paper clarifies the differences between DA and CD tasks. It preliminarily explores model design strategies utilizing prior attention mechanisms and image-level consistency regularization, establishing new post-flood DA task benchmark methods.
Robust Disaster Assessment from Aerial Imagery Using Text-to-Image Synthetic Data
May 22, 2024We present a simple and efficient method to leverage emerging text-to-image generative models in creating large-scale synthetic supervision for the task of damage assessment from aerial images. While significant recent advances have resulted in improved techniques for damage assessment using aerial or satellite imagery, they still suffer from poor robustness to domains where manual labeled data is unavailable, directly impacting post-disaster humanitarian assistance in such under-resourced geographies. Our contribution towards improving domain robustness in this scenario is two-fold. Firstly, we leverage the text-guided mask-based image editing capabilities of generative models and build an efficient and easily scalable pipeline to generate thousands of post-disaster images from low-resource domains. Secondly, we propose a simple two-stage training approach to train robust models while using manual supervision from different source domains along with the generated synthetic target domain data. We validate the strength of our proposed framework under cross-geography domain transfer setting from xBD and SKAI images in both single-source and multi-source settings, achieving significant improvements over a source-only baseline in each case.
ChangeMamba: Remote Sensing Change Detection with Spatio-Temporal State Space Model
Apr 14, 2024



Convolutional neural networks (CNN) and Transformers have made impressive progress in the field of remote sensing change detection (CD). However, both architectures have inherent shortcomings. Recently, the Mamba architecture, based on state space models, has shown remarkable performance in a series of natural language processing tasks, which can effectively compensate for the shortcomings of the above two architectures. In this paper, we explore for the first time the potential of the Mamba architecture for remote sensing CD tasks. We tailor the corresponding frameworks, called MambaBCD, MambaSCD, and MambaBDA, for binary change detection (BCD), semantic change detection (SCD), and building damage assessment (BDA), respectively. All three frameworks adopt the cutting-edge Visual Mamba architecture as the encoder, which allows full learning of global spatial contextual information from the input images. For the change decoder, which is available in all three architectures, we propose three spatio-temporal relationship modeling mechanisms, which can be naturally combined with the Mamba architecture and fully utilize its attribute to achieve spatio-temporal interaction of multi-temporal features, thereby obtaining accurate change information. On five benchmark datasets, our proposed frameworks outperform current CNN- and Transformer-based approaches without using any complex training strategies or tricks, fully demonstrating the potential of the Mamba architecture in CD tasks. Specifically, we obtained 83.11%, 88.39% and 94.19% F1 scores on the three BCD datasets SYSU, LEVIR-CD+, and WHU-CD; on the SCD dataset SECOND, we obtained 24.11% SeK; and on the BDA dataset xBD, we obtained 81.41% overall F1 score. Further experiments show that our architecture is quite robust to degraded data. The source code will be available in https://github.com/ChenHongruixuan/MambaCD