 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Potential of Copernicus Satellites for Disaster Response: Retrieving Building Damage from Sentinel-1 and Sentinel-2
Nov 07, 2025


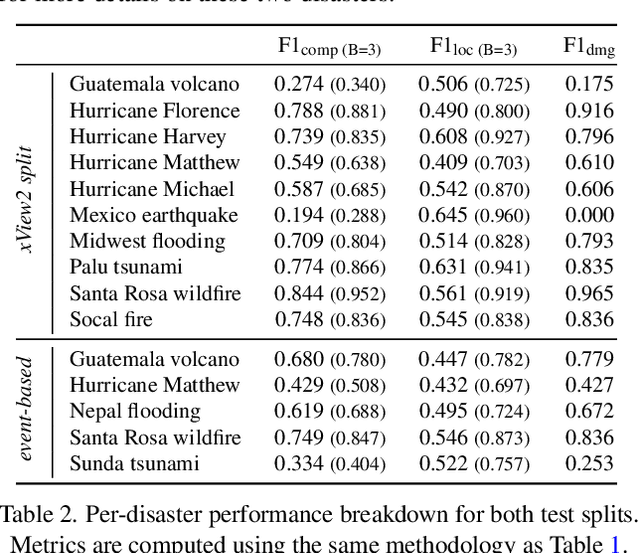
Natural disasters demand rapid damage assessment to guide humanitarian response. Here, we investigate whether medium-resolution Earth observation images from the Copernicus program can support building damage assessment, complementing very-high resolution imagery with often limited availability. We introduce xBD-S12, a dataset of 10,315 pre- and post-disaster image pairs from both Sentinel-1 and Sentinel-2, spatially and temporally aligned with the established xBD benchmark. In a series of experiments, we demonstrate that building damage can be detected and mapped rather well in many disaster scenarios, despite the moderate 10$\,$m ground sampling distance. We also find that, for damage mapping at that resolution, architectural sophistication does not seem to bring much advantage: more complex model architectures tend to struggle with generalization to unseen disasters, and geospatial foundation models bring little practical benefit. Our results suggest that Copernicus images are a viable data source for rapid, wide-area damage assessment and could play an important role alongside VHR imagery. We release the xBD-S12 dataset, code, and trained models to support further research.
Video Depth without Video Models
Nov 28, 2024



Video depth estimation lifts monocular video clips to 3D by inferring dense depth at every frame. Recent advances in single-image depth estimation, brought about by the rise of large foundation models and the use of synthetic training data, have fueled a renewed interest in video depth. However, naively applying a single-image depth estimator to every frame of a video disregards temporal continuity, which not only leads to flickering but may also break when camera motion causes sudden changes in depth range. An obvious and principled solution would be to build on top of video foundation models, but these come with their own limitations; including expensive training and inference, imperfect 3D consistency, and stitching routines for the fixed-length (short) outputs. We take a step back and demonstrate how to turn a single-image latent diffusion model (LDM) into a state-of-the-art video depth estimator. Our model, which we call RollingDepth, has two main ingredients: (i) a multi-frame depth estimator that is derived from a single-image LDM and maps very short video snippets (typically frame triplets) to depth snippets. (ii) a robust, optimization-based registration algorithm that optimally assembles depth snippets sampled at various different frame rates back into a consistent video. RollingDepth is able to efficiently handle long videos with hundreds of frames and delivers more accurate depth videos than both dedicated video depth estimators and high-performing single-frame models. Project page: rollingdepth.github.io.
AGBD: A Global-scale Biomass Dataset
Jun 07, 2024



Accurate estimates of Above Ground Biomass (AGB) are essential in addressing two of humanity's biggest challenges, climate change and biodiversity loss. Existing datasets for AGB estimation from satellite imagery are limited. Either they focus on specific, local regions at high resolution, or they offer global coverage at low resolution. There is a need for a machine learning-ready, globally representative, high-resolution benchmark. Our findings indicate significant variability in biomass estimates across different vegetation types, emphasizing the necessity for a dataset that accurately captures global diversity. To address these gaps, we introduce a comprehensive new dataset that is globally distributed, covers a range of vegetation types, and spans several years. This dataset combines AGB reference data from the GEDI mission with data from Sentinel-2 and PALSAR-2 imagery. Additionally, it includes pre-processed high-level features such as a dense canopy height map, an elevation map, and a land-cover classification map. We also produce a dense, high-resolution (10m) map of AGB predictions for the entire area covered by the dataset. Rigorously tested, our dataset is accompanied by several benchmark models and is publicly available. It can be easily accessed using a single line of code, offering a solid basis for efforts towards global AGB estimation. The GitHub repository github.com/ghjuliasialelli/AGBD serves as a one-stop shop for all code and data.
An Open-Source Tool for Mapping War Destruction at Scale in Ukraine using Sentinel-1 Time Series
Jun 04, 2024



Access to detailed war impact assessments is crucial for humanitarian organizations to effectively assist populations most affected by armed conflicts. However, maintaining a comprehensive understanding of the situation on the ground is challenging, especially in conflicts that cover vast territories and extend over long periods. This study presents a scalable and transferable method for estimating war-induced damage to buildings. We first train a machine learning model to output pixel-wise probability of destruction from Synthetic Aperture Radar (SAR) satellite image time series, leveraging existing, manual damage assessments as ground truth and cloud-based geospatial analysis tools for large-scale inference. We further post-process these assessments using open building footprints to obtain a final damage estimate per building. We introduce an accessible, open-source tool that allows users to adjust the confidence interval based on their specific requirements and use cases. Our approach enables humanitarian organizations and other actors to rapidly screen large geographic regions for war impacts. We provide two publicly accessible dashboards: a Ukraine Damage Explorer to dynamically view our pre-computed estimates, and a Rapid Damage Mapping Tool to easily run our method and produce custom maps.
Automated forest inventory: analysis of high-density airborne LiDAR point clouds with 3D deep learning
Dec 22, 2023



Detailed forest inventories are critical for sustainable and flexible management of forest resources, to conserve various ecosystem services. Modern airborne laser scanners deliver high-density point clouds with great potential for fine-scale forest inventory and analysis, but automatically partitioning those point clouds into meaningful entities like individual trees or tree components remains a challenge. The present study aims to fill this gap and introduces a deep learning framework that is able to perform such a segmentation across diverse forest types and geographic regions. From the segmented data, we then derive relevant biophysical parameters of individual trees as well as stands. The system has been tested on FOR-Instance, a dataset of point clouds that have been acquired in five different countries using surveying drones. The segmentation back-end achieves over 85% F-score for individual trees, respectively over 73% mean IoU across five semantic categories: ground, low vegetation, stems, live branches and dead branches. Building on the segmentation results our pipeline then densely calculates biophysical features of each individual tree (height, crown diameter, crown volume, DBH, and location) and properties per stand (digital terrain model and stand density). Especially crown-related features are in most cases retrieved with high accuracy, whereas the estimates for DBH and location are less reliable, due to the airborne scanning setup.
Towards accurate instance segmentation in large-scale LiDAR point clouds
Jul 06, 2023



Panoptic segmentation is the combination of semantic and instance segmentation: assign the points in a 3D point cloud to semantic categories and partition them into distinct object instances. It has many obvious applications for outdoor scene understanding, from city mapping to forest management. Existing methods struggle to segment nearby instances of the same semantic category, like adjacent pieces of street furniture or neighbouring trees, which limits their usability for inventory- or management-type applications that rely on object instances. This study explores the steps of the panoptic segmentation pipeline concerned with clustering points into object instances, with the goal to alleviate that bottleneck. We find that a carefully designed clustering strategy, which leverages multiple types of learned point embeddings, significantly improves instance segmentation. Experiments on the NPM3D urban mobile mapping dataset and the FOR-instance forest dataset demonstrate the effectiveness and versatility of the proposed strategy.
A Review of Panoptic Segmentation for Mobile Mapping Point Clouds
Apr 27, 2023



3D point cloud panoptic segmentation is the combined task to (i) assign each point to a semantic class and (ii) separate the points in each class into object instances. Recently there has been an increased interest in such comprehensive 3D scene understanding, building on the rapid advances of semantic segmentation due to the advent of deep 3D neural networks. Yet, to date there is very little work about panoptic segmentation of outdoor mobile-mapping data, and no systematic comparisons. The present paper tries to close that gap. It reviews the building blocks needed to assemble a panoptic segmentation pipeline and the related literature. Moreover, a modular pipeline is set up to perform comprehensive, systematic experiments to assess the state of panoptic segmentation in the context of street mapping. As a byproduct, we also provide the first public dataset for that task, by extending the NPM3D dataset to include instance labels.
BiasBed -- Rigorous Texture Bias Evaluation
Dec 01, 2022



The well-documented presence of texture bias in modern convolutional neural networks has led to a plethora of algorithms that promote an emphasis on shape cues, often to support generalization to new domains. Yet, common datasets, benchmarks and general model selection strategies are missing, and there is no agreed, rigorous evaluation protocol. In this paper, we investigate difficulties and limitations when training networks with reduced texture bias. In particular, we also show that proper evaluation and meaningful comparisons between methods are not trivial. We introduce BiasBed, a testbed for texture- and style-biased training, including multiple datasets and a range of existing algorithms. It comes with an extensive evaluation protocol that includes rigorous hypothesis testing to gauge the significance of the results, despite the considerable training instability of some style bias methods. Our extensive experiments, shed new light on the need for careful, statistically founded evaluation protocols for style bias (and beyond). E.g., we find that some algorithms proposed in the literature do not significantly mitigate the impact of style bias at all. With the release of BiasBed, we hope to foster a common understanding of consistent and meaningful comparisons, and consequently faster progress towards learning methods free of texture bias. Code is available at https://github.com/D1noFuzi/BiasBed
Tetrahedral Diffusion Models for 3D Shape Generation
Nov 23, 2022



Recently, probabilistic denoising diffusion models (DDMs) have greatly advanced the generative power of neural networks. DDMs, inspired by non-equilibrium thermodynamics, have not only been used for 2D image generation, but can also readily be applied to 3D point clouds. However, representing 3D shapes as point clouds has a number of drawbacks, most obvious perhaps that they have no notion of topology or connectivity. Here, we explore an alternative route and introduce tetrahedral diffusion models, an extension of DDMs to tetrahedral partitions of 3D space. The much more structured 3D representation with space-filling tetrahedra makes it possible to guide and regularize the diffusion process and to apply it to colorized assets. To manipulate the proposed representation, we develop tetrahedral convolutions, down- and up-sampling kernels. With those operators, 3D shape generation amounts to learning displacement vectors and signed distance values on the tetrahedral grid. Our experiments confirm that Tetrahedral Diffusion yields plausible, visually pleasing and diverse 3D shapes, is able to handle surface attributes like color, and can be guided at test time to manipulate the resulting shapes.
Statistical learning for change point and anomaly detection in graphs
Nov 10, 2020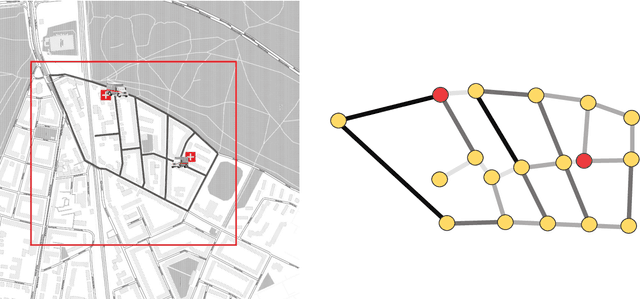
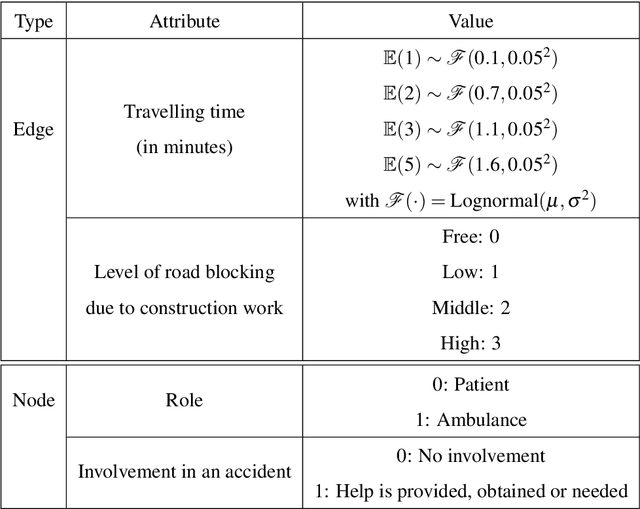
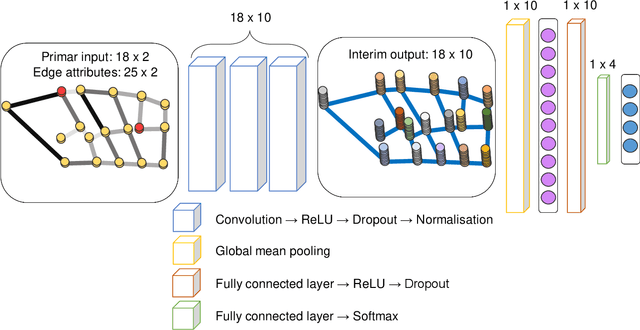
Complex systems which can be represented in the form of static and dynamic graphs arise in different fields, e.g. communication, engineering and industry. One of the interesting problems in analysing dynamic network structures is to monitor changes in their development. Statistical learning, which encompasses both methods based on artificial intelligence and traditional statistics, can be used to progress in this research area. However, the majority of approaches apply only one or the other framework. In this paper, we discuss the possibility of bringing together both disciplines in order to create enhanced network monitoring procedures focussing on the example of combining statistical process control and deep learning algorithms. Together with the presentation of change point and anomaly detection in network data, we propose to monitor the response times of ambulance services, applying jointly the control chart for quantile function values and a graph convolutional network.