 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWildfire Spread Scenarios: Increasing Sample Diversity of Segmentation Diffusion Models with Training-Free Methods
Mar 20, 2026Predicting future states in uncertain environments, such as wildfire spread, medical diagnosis, or autonomous driving, requires models that can consider multiple plausible outcomes. While diffusion models can effectively learn such multi-modal distributions, naively sampling from these models is computationally inefficient, potentially requiring hundreds of samples to find low-probability modes that may still be operationally relevant. In this work, we address the challenge of sample-efficient ambiguous segmentation by evaluating several training-free sampling methods that encourage diverse predictions. We adapt two techniques, particle guidance and SPELL, originally designed for the generation of diverse natural images, to discrete segmentation tasks, and additionally propose a simple clustering-based technique. We validate these approaches on the LIDC medical dataset, a modified version of the Cityscapes dataset, and MMFire, a new simulation-based wildfire spread dataset introduced in this paper. Compared to naive sampling, these approaches increase the HM IoU* metric by up to 7.5% on MMFire and 16.4% on Cityscapes, demonstrating that training-free methods can be used to efficiently increase the sample diversity of segmentation diffusion models with little cost to image quality and runtime. Code and dataset: https://github.com/SebastianGer/wildfire-spread-scenarios
* Accepted at NLDL 2026. This version contains small corrections compared to the initial publication, see appendix for details
Deterministic Mode Proposals: An Efficient Alternative to Generative Sampling for Ambiguous Segmentation
Mar 20, 2026Many segmentation tasks, such as medical image segmentation or future state prediction, are inherently ambiguous, meaning that multiple predictions are equally correct. Current methods typically rely on generative models to capture this uncertainty. However, identifying the underlying modes of the distribution with these methods is computationally expensive, requiring large numbers of samples and post-hoc clustering. In this paper, we shift the focus from stochastic sampling to the direct generation of likely outcomes. We introduce mode proposal models, a deterministic framework that efficiently produces a fixed-size set of proposal masks in a single forward pass. To handle superfluous proposals, we adapt a confidence mechanism, traditionally used in object detection, to the high-dimensional space of segmentation masks. Our approach significantly reduces inference time while achieving higher ground-truth coverage than existing generative models. Furthermore, we demonstrate that our model can be trained without knowing the full distribution of outcomes, making it applicable to real-world datasets. Finally, we show that by decomposing the velocity field of a pre-trained flow model, we can efficiently estimate prior mode probabilities for our proposals.
Unconditional Human Motion and Shape Generation via Balanced Score-Based Diffusion
Oct 14, 2025Recent work has explored a range of model families for human motion generation, including Variational Autoencoders (VAEs), Generative Adversarial Networks (GANs), and diffusion-based models. Despite their differences, many methods rely on over-parameterized input features and auxiliary losses to improve empirical results. These strategies should not be strictly necessary for diffusion models to match the human motion distribution. We show that on par with state-of-the-art results in unconditional human motion generation are achievable with a score-based diffusion model using only careful feature-space normalization and analytically derived weightings for the standard L2 score-matching loss, while generating both motion and shape directly, thereby avoiding slow post hoc shape recovery from joints. We build the method step by step, with a clear theoretical motivation for each component, and provide targeted ablations demonstrating the effectiveness of each proposed addition in isolation.
A simple, strong baseline for building damage detection on the xBD dataset
Jan 30, 2024We construct a strong baseline method for building damage detection by starting with the highly-engineered winning solution of the xView2 competition, and gradually stripping away components. This way, we obtain a much simpler method, while retaining adequate performance. We expect the simplified solution to be more widely and easily applicable. This expectation is based on the reduced complexity, as well as the fact that we choose hyperparameters based on simple heuristics, that transfer to other datasets. We then re-arrange the xView2 dataset splits such that the test locations are not seen during training, contrary to the competition setup. In this setting, we find that both the complex and the simplified model fail to generalize to unseen locations. Analyzing the dataset indicates that this failure to generalize is not only a model-based problem, but that the difficulty might also be influenced by the unequal class distributions between events. Code, including the baseline model, is available under https://github.com/PaulBorneP/Xview2_Strong_Baseline
Probabilistic 3d regression with projected huber distribution
Mar 09, 2023Estimating probability distributions which describe where an object is likely to be from camera data is a task with many applications. In this work we describe properties which we argue such methods should conform to. We also design a method which conform to these properties. In our experiments we show that our method produces uncertainties which correlate well with empirical errors. We also show that the mode of the predicted distribution outperform our regression baselines. The code for our implementation is available online.
Contrastive pretraining for semantic segmentation is robust to noisy positive pairs
Nov 24, 2022



Domain-specific variants of contrastive learning can construct positive pairs from two distinct images, as opposed to augmenting the same image twice. Unlike in traditional contrastive methods, this can result in positive pairs not matching perfectly. Similar to false negative pairs, this could impede model performance. Surprisingly, we find that downstream semantic segmentation is either robust to the noisy pairs or even benefits from them. The experiments are conducted on the remote sensing dataset xBD, and a synthetic segmentation dataset, on which we have full control over the noise parameters. As a result, practitioners should be able to use such domain-specific contrastive methods without having to filter their positive pairs beforehand.
Are All Linear Regions Created Equal?
Feb 23, 2022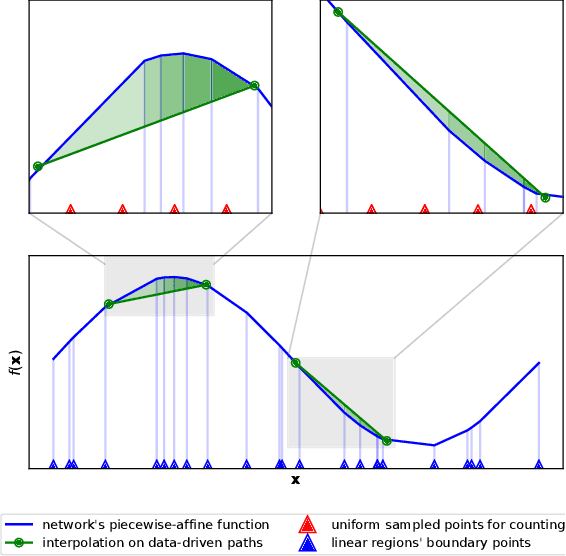
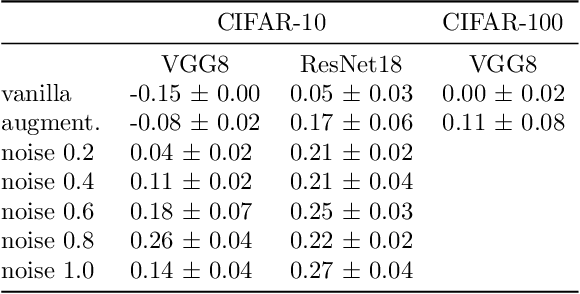
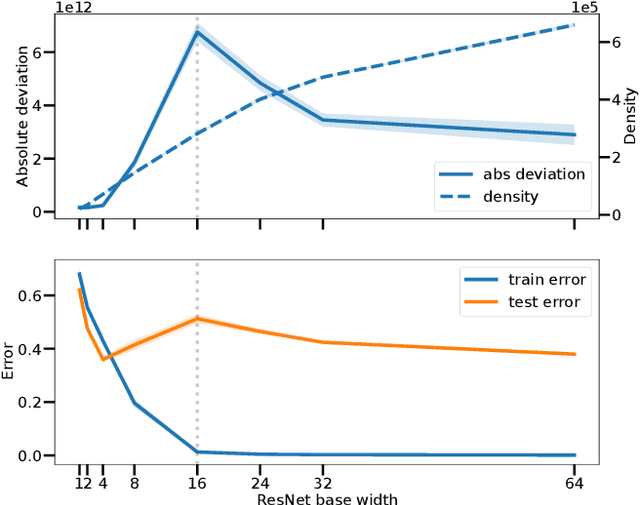
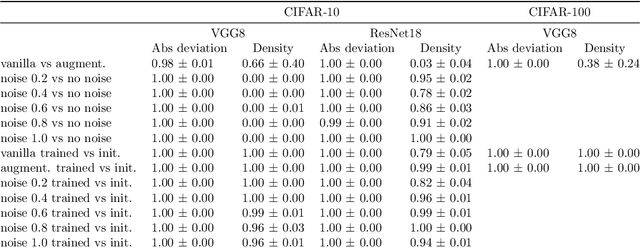
The number of linear regions has been studied as a proxy of complexity for ReLU networks. However, the empirical success of network compression techniques like pruning and knowledge distillation, suggest that in the overparameterized setting, linear regions density might fail to capture the effective nonlinearity. In this work, we propose an efficient algorithm for discovering linear regions and use it to investigate the effectiveness of density in capturing the nonlinearity of trained VGGs and ResNets on CIFAR-10 and CIFAR-100. We contrast the results with a more principled nonlinearity measure based on function variation, highlighting the shortcomings of linear regions density. Furthermore, interestingly, our measure of nonlinearity clearly correlates with model-wise deep double descent, connecting reduced test error with reduced nonlinearity, and increased local similarity of linear regions.
Probabilistic Regression with Huber Distributions
Nov 19, 2021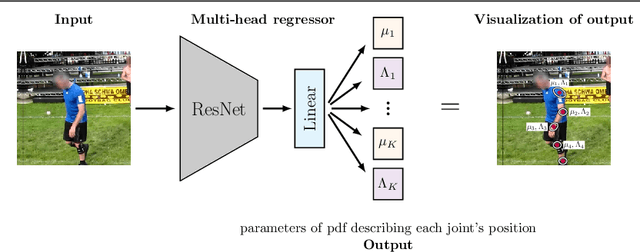
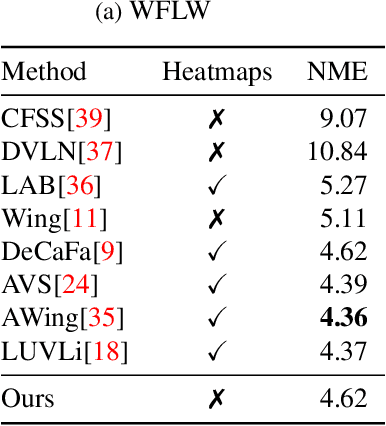
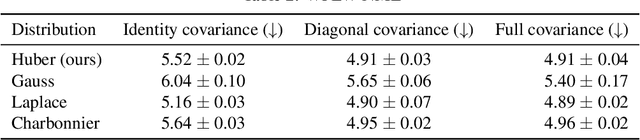

In this paper we describe a probabilistic method for estimating the position of an object along with its covariance matrix using neural networks. Our method is designed to be robust to outliers, have bounded gradients with respect to the network outputs, among other desirable properties. To achieve this we introduce a novel probability distribution inspired by the Huber loss. We also introduce a new way to parameterize positive definite matrices to ensure invariance to the choice of orientation for the coordinate system we regress over. We evaluate our method on popular body pose and facial landmark datasets and get performance on par or exceeding the performance of non-heatmap methods. Our code is available at github.com/Davmo049/Public_prob_regression_with_huber_distributions
Large-Scale Zero-Shot Image Classification from Rich and Diverse Textual Descriptions
Mar 17, 2021


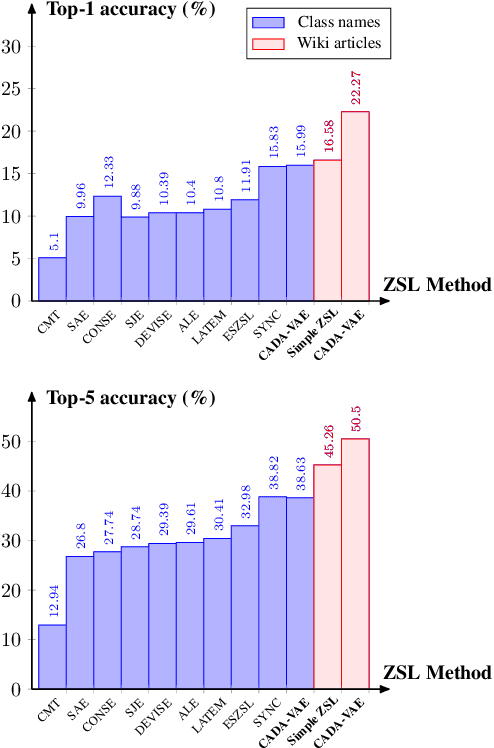
We study the impact of using rich and diverse textual descriptions of classes for zero-shot learning (ZSL) on ImageNet. We create a new dataset ImageNet-Wiki that matches each ImageNet class to its corresponding Wikipedia article. We show that merely employing these Wikipedia articles as class descriptions yields much higher ZSL performance than prior works. Even a simple model using this type of auxiliary data outperforms state-of-the-art models that rely on standard features of word embedding encodings of class names. These results highlight the usefulness and importance of textual descriptions for ZSL, as well as the relative importance of auxiliary data type compared to algorithmic progress. Our experimental results also show that standard zero-shot learning approaches generalize poorly across categories of classes.
Explanation-based Weakly-supervised Learning of Visual Relations with Graph Networks
Jun 16, 2020
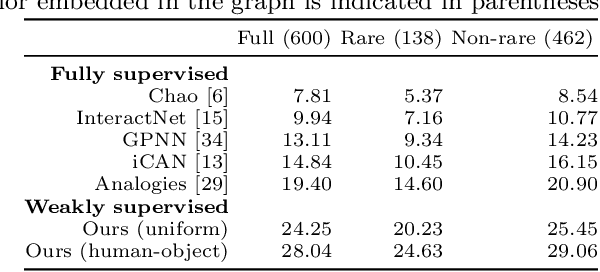
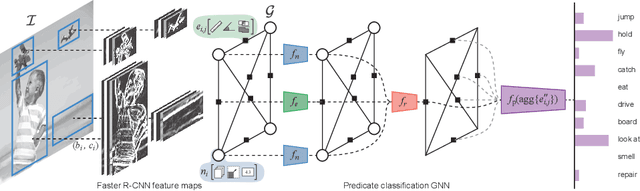
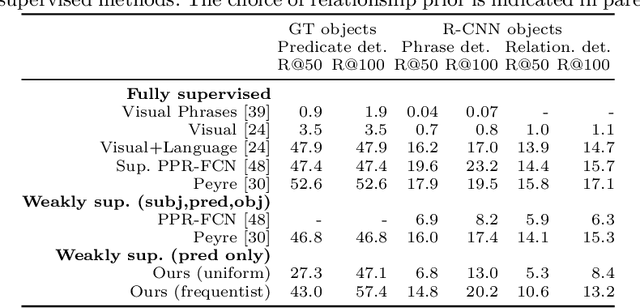
Visual relationship detection is fundamental for holistic image understanding. However, localizing and classifying (subject, predicate, object) triplets constitutes a hard learning objective due to the combinatorial explosion of possible relationships, their long-tail distribution in natural images, and an expensive annotation process. This paper introduces a novel weakly-supervised method for visual relationship detection that relies only on image-level predicate annotations. A graph neural network is trained to classify the predicates in an image from the graph representation of all objects, implicitly encoding an inductive bias for pairwise relationships. We then frame relationship detection as the explanation of such a predicate classifier, i.e. we reconstruct a complete relationship by recovering the subject and the object of a predicted predicate. Using this novel technique and minimal labels, we present comparable results to recent fully-supervised and weakly-supervised methods on three diverse and challenging datasets: HICO-DET for human-object interaction, Visual Relationship Detection for generic object-to-object relationships, and UnRel for unusual relationships.