 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWikibio
Papers and Code
Trust in One Round: Confidence Estimation for Large Language Models via Structural Signals
Feb 01, 2026Large language models (LLMs) are increasingly deployed in domains where errors carry high social, scientific, or safety costs. Yet standard confidence estimators, such as token likelihood, semantic similarity and multi-sample consistency, remain brittle under distribution shift, domain-specialised text, and compute limits. In this work, we present Structural Confidence, a single-pass, model-agnostic framework that enhances output correctness prediction based on multi-scale structural signals derived from a model's final-layer hidden-state trajectory. By combining spectral, local-variation, and global shape descriptors, our method captures internal stability patterns that are missed by probabilities and sentence embeddings. We conduct extensive, cross-domain evaluation across four heterogeneous benchmarks-FEVER (fact verification), SciFact (scientific claims), WikiBio-hallucination (biographical consistency), and TruthfulQA (truthfulness-oriented QA). Our Structural Confidence framework demonstrates strong performance compared with established baselines in terms of AUROC and AUPR. More importantly, unlike sampling-based consistency methods which require multiple stochastic generations and an auxiliary model, our approach uses a single deterministic forward pass, offering a practical basis for efficient, robust post-hoc confidence estimation in socially impactful, resource-constrained LLM applications.
SelfCheckAgent: Zero-Resource Hallucination Detection in Generative Large Language Models
Feb 03, 2025Detecting hallucinations in Large Language Models (LLMs) remains a critical challenge for their reliable deployment in real-world applications. To address this, we introduce SelfCheckAgent, a novel framework integrating three different agents: the Symbolic Agent, the Specialized Detection Agent, and the Contextual Consistency Agent. These agents provide a robust multi-dimensional approach to hallucination detection. Notable results include the Contextual Consistency Agent leveraging Llama 3.1 with Chain-of-Thought (CoT) to achieve outstanding performance on the WikiBio dataset, with NonFactual hallucination detection scoring 93.64%, Factual 70.26%, and Ranking 78.48% respectively. On the AIME dataset, GPT-4o with CoT excels in NonFactual detection with 94.89% but reveals trade-offs in Factual with 30.58% and Ranking with 30.68%, underscoring the complexity of hallucination detection in the complex mathematical domains. The framework also incorporates a triangulation strategy, which increases the strengths of the SelfCheckAgent, yielding significant improvements in real-world hallucination identification. The comparative analysis demonstrates SelfCheckAgent's applicability across diverse domains, positioning it as a crucial advancement for trustworthy LLMs. These findings highlight the potentiality of consistency-driven methodologies in detecting hallucinations in LLMs.
gTBLS: Generating Tables from Text by Conditional Question Answering
Mar 21, 2024



Distilling large, unstructured text into a structured, condensed form such as tables is an open research problem. One of the primary challenges in automatically generating tables is ensuring their syntactic validity. Prior approaches address this challenge by including additional parameters in the Transformer's attention mechanism to attend to specific rows and column headers. In contrast to this single-stage method, this paper presents a two-stage approach called Generative Tables (gTBLS). The first stage infers table structure (row and column headers) from the text. The second stage formulates questions using these headers and fine-tunes a causal language model to answer them. Furthermore, the gTBLS approach is amenable to the utilization of pre-trained Large Language Models in a zero-shot configuration, presenting a solution for table generation in situations where fine-tuning is not feasible. gTBLS improves prior approaches by up to 10% in BERTScore on the table construction task and up to 20% on the table content generation task of the E2E, WikiTableText, WikiBio, and RotoWire datasets.
Wikibio: a Semantic Resource for the Intersectional Analysis of Biographical Events
Jun 15, 2023Biographical event detection is a relevant task for the exploration and comparison of the ways in which people's lives are told and represented. In this sense, it may support several applications in digital humanities and in works aimed at exploring bias about minoritized groups. Despite that, there are no corpora and models specifically designed for this task. In this paper we fill this gap by presenting a new corpus annotated for biographical event detection. The corpus, which includes 20 Wikipedia biographies, was compared with five existing corpora to train a model for the biographical event detection task. The model was able to detect all mentions of the target-entity in a biography with an F-score of 0.808 and the entity-related events with an F-score of 0.859. Finally, the model was used for performing an analysis of biases about women and non-Western people in Wikipedia biographies.
SelfCheckGPT: Zero-Resource Black-Box Hallucination Detection for Generative Large Language Models
Mar 15, 2023



Generative Large Language Models (LLMs) such as GPT-3 are capable of generating highly fluent responses to a wide variety of user prompts. However, LLMs are known to hallucinate facts and make non-factual statements which can undermine trust in their output. Existing fact-checking approaches either require access to token-level output probability distribution (which may not be available for systems such as ChatGPT) or external databases that are interfaced via separate, often complex, modules. In this work, we propose "SelfCheckGPT", a simple sampling-based approach that can be used to fact-check black-box models in a zero-resource fashion, i.e. without an external database. SelfCheckGPT leverages the simple idea that if a LLM has knowledge of a given concept, sampled responses are likely to be similar and contain consistent facts. However, for hallucinated facts, stochastically sampled responses are likely to diverge and contradict one another. We investigate this approach by using GPT-3 to generate passages about individuals from the WikiBio dataset, and manually annotate the factuality of the generated passages. We demonstrate that SelfCheckGPT can: i) detect non-factual and factual sentences; and ii) rank passages in terms of factuality. We compare our approach to several existing baselines and show that in sentence hallucination detection, our approach has AUC-PR scores comparable to grey-box methods, while SelfCheckGPT is best at passage factuality assessment.
Nearest Neighbor Non-autoregressive Text Generation
Aug 26, 2022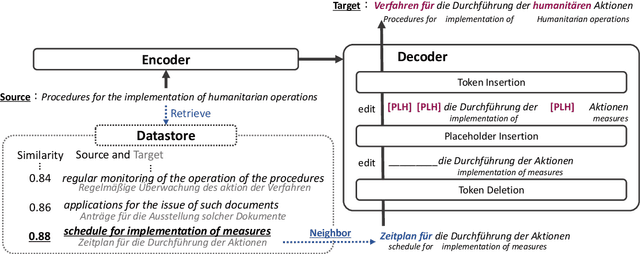
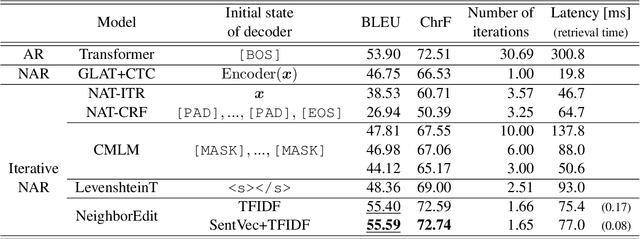

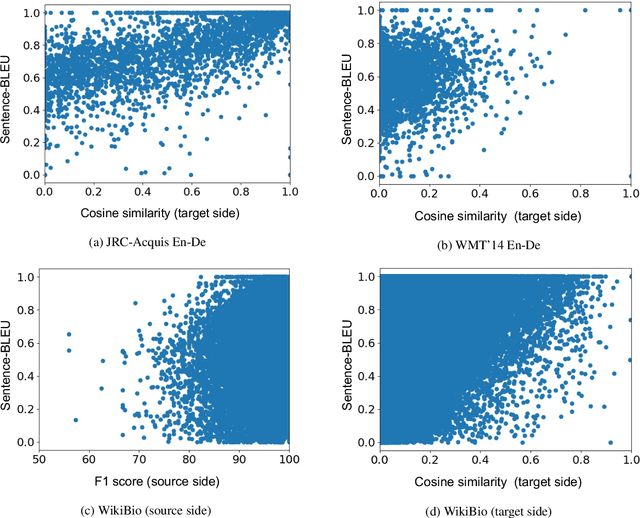
Non-autoregressive (NAR) models can generate sentences with less computation than autoregressive models but sacrifice generation quality. Previous studies addressed this issue through iterative decoding. This study proposes using nearest neighbors as the initial state of an NAR decoder and editing them iteratively. We present a novel training strategy to learn the edit operations on neighbors to improve NAR text generation. Experimental results show that the proposed method (NeighborEdit) achieves higher translation quality (1.69 points higher than the vanilla Transformer) with fewer decoding iterations (one-eighteenth fewer iterations) on the JRC-Acquis En-De dataset, the common benchmark dataset for machine translation using nearest neighbors. We also confirm the effectiveness of the proposed method on a data-to-text task (WikiBio). In addition, the proposed method outperforms an NAR baseline on the WMT'14 En-De dataset. We also report analysis on neighbor examples used in the proposed method.
Few-Shot Table-to-Text Generation with Prefix-Controlled Generator
Aug 23, 2022
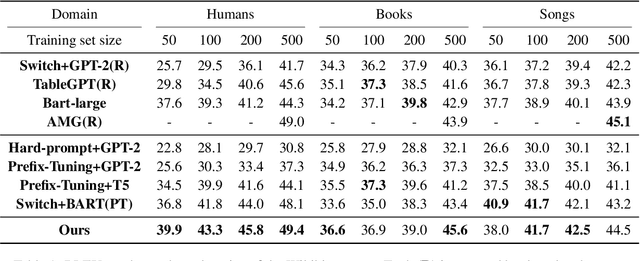
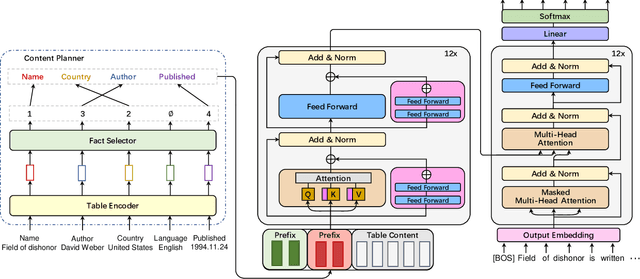
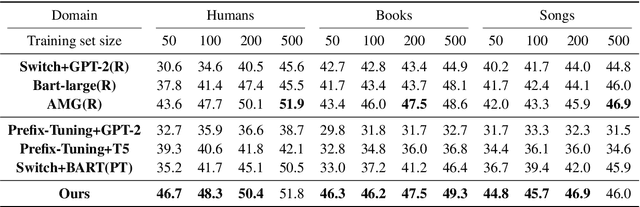
Neural table-to-text generation approaches are data-hungry, limiting their adaptation for low-resource real-world applications. Previous works mostly resort to Pre-trained Language Models (PLMs) to generate fluent summaries of a table. However, they often contain hallucinated contents due to the uncontrolled nature of PLMs. Moreover, the topological differences between tables and sequences are rarely studied. Last but not least, fine-tuning on PLMs with a handful of instances may lead to over-fitting and catastrophic forgetting. To alleviate these problems, we propose a prompt-based approach, Prefix-Controlled Generator (i.e., PCG), for few-shot table-to-text generation. We prepend a task-specific prefix for a PLM to make the table structure better fit the pre-trained input. In addition, we generate an input-specific prefix to control the factual contents and word order of the generated text. Both automatic and human evaluations on different domains (humans, books and songs) of the Wikibio dataset show substantial improvements over baseline approaches.
Improving the Numerical Reasoning Skills of Pretrained Language Models
May 13, 2022
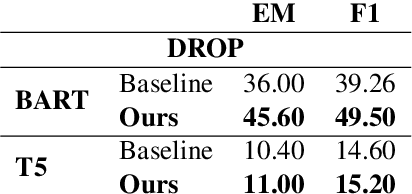
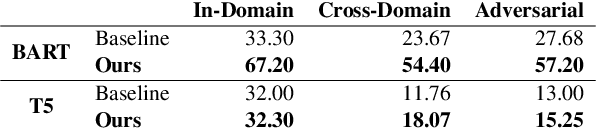
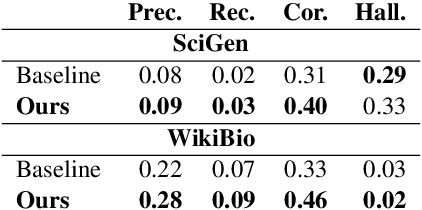
State-of-the-art pretrained language models tend to perform below their capabilities when applied out-of-the-box on tasks that require reasoning over numbers. Recent work sees two main reasons for this: (1) popular tokenisation algorithms are optimized for common words, and therefore have limited expressiveness for numbers, and (2) common pretraining objectives do not target numerical reasoning or understanding numbers at all. Recent approaches usually address them separately and mostly by proposing architectural changes or pretraining models from scratch. In this paper, we propose a new extended pretraining approach called reasoning-aware pretraining to jointly address both shortcomings without requiring architectural changes or pretraining from scratch. Using contrastive learning, our approach incorporates an alternative number representation into an already pretrained model, while improving its numerical reasoning skills by training on a novel pretraining objective called inferable number prediction task. We evaluate our approach on three different tasks that require numerical reasoning, including (a) reading comprehension in the DROP dataset, (b) inference-on-tables in the InfoTabs dataset, and (c) table-to-text generation in WikiBio and SciGen datasets. Our results on DROP and InfoTabs show that our approach improves the accuracy by 9.6 and 33.9 points on these datasets, respectively. Our human evaluation on SciGen and WikiBio shows that our approach improves the factual correctness on all datasets.
IndicNLG Suite: Multilingual Datasets for Diverse NLG Tasks in Indic Languages
Mar 10, 2022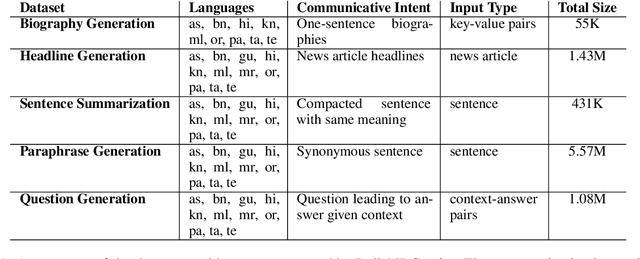
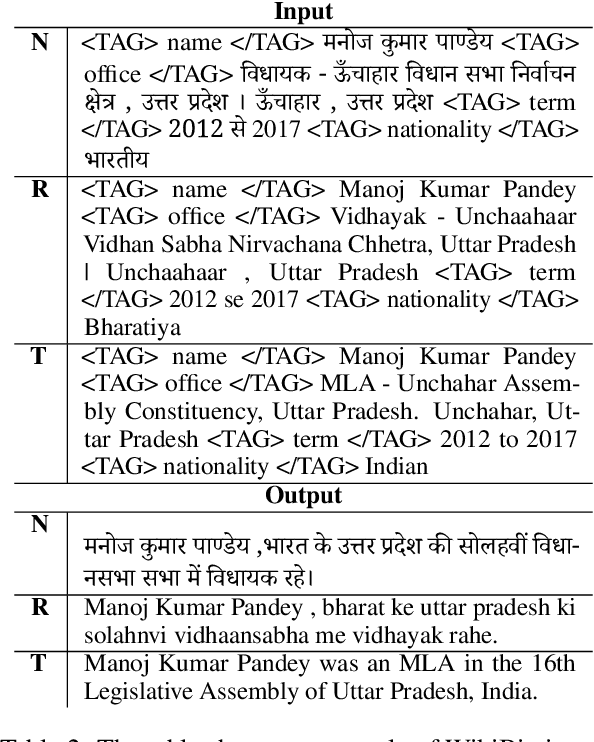
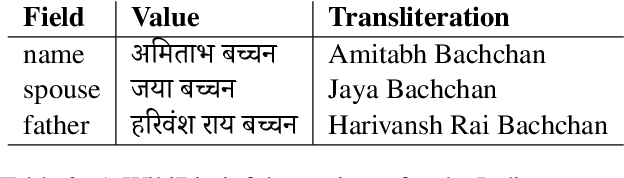
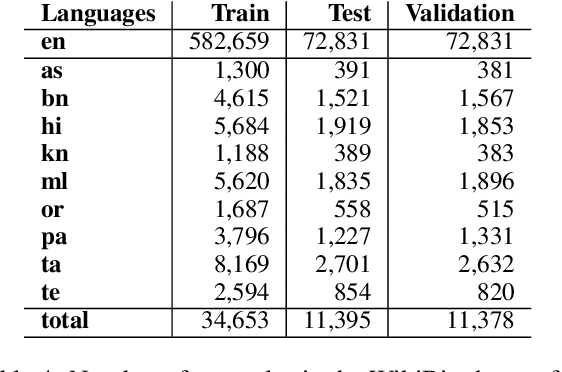
In this paper, we present the IndicNLG suite, a collection of datasets for benchmarking Natural Language Generation (NLG) for 11 Indic languages. We focus on five diverse tasks, namely, biography generation using Wikipedia infoboxes (WikiBio), news headline generation, sentence summarization, question generation and paraphrase generation. We describe the process of creating the datasets and present statistics of the dataset, following which we train and report a variety of strong monolingual and multilingual baselines that leverage pre-trained sequence-to-sequence models and analyze the results to understand the challenges involved in Indic language NLG. To the best of our knowledge, this is the first NLG dataset for Indic languages and also the largest multilingual NLG dataset. Our methods can also be easily applied to modest-resource languages with reasonable monolingual and parallel corpora, as well as corpora containing structured data like Wikipedia. We hope this dataset spurs research in NLG on diverse languages and tasks, particularly for Indic languages. The datasets and models are publicly available at https://indicnlp.ai4bharat.org/indicnlg-suite.
Search and Learn: Improving Semantic Coverage for Data-to-Text Generation
Dec 06, 2021
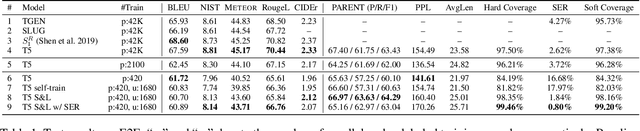
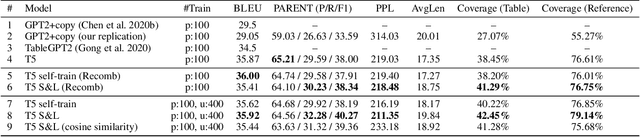

Data-to-text generation systems aim to generate text descriptions based on input data (often represented in the tabular form). A typical system uses huge training samples for learning the correspondence between tables and texts. However, large training sets are expensive to obtain, limiting the applicability of these approaches in real-world scenarios. In this work, we focus on few-shot data-to-text generation. We observe that, while fine-tuned pretrained language models may generate plausible sentences, they suffer from the low semantic coverage problem in the few-shot setting. In other words, important input slots tend to be missing in the generated text. To this end, we propose a search-and-learning approach that leverages pretrained language models but inserts the missing slots to improve the semantic coverage. We further fine-tune our system based on the search results to smooth out the search noise, yielding better-quality text and improving inference efficiency to a large extent. Experiments show that our model achieves high performance on E2E and WikiBio datasets. Especially, we cover 98.35% of input slots on E2E, largely alleviating the low coverage problem.