 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpanish Conversational Speech Data
Papers and Code
FHSTP@EXIST 2025 Benchmark: Sexism Detection with Transparent Speech Concept Bottleneck Models
Jul 28, 2025Sexism has become widespread on social media and in online conversation. To help address this issue, the fifth Sexism Identification in Social Networks (EXIST) challenge is initiated at CLEF 2025. Among this year's international benchmarks, we concentrate on solving the first task aiming to identify and classify sexism in social media textual posts. In this paper, we describe our solutions and report results for three subtasks: Subtask 1.1 - Sexism Identification in Tweets, Subtask 1.2 - Source Intention in Tweets, and Subtask 1.3 - Sexism Categorization in Tweets. We implement three models to address each subtask which constitute three individual runs: Speech Concept Bottleneck Model (SCBM), Speech Concept Bottleneck Model with Transformer (SCBMT), and a fine-tuned XLM-RoBERTa transformer model. SCBM uses descriptive adjectives as human-interpretable bottleneck concepts. SCBM leverages large language models (LLMs) to encode input texts into a human-interpretable representation of adjectives, then used to train a lightweight classifier for downstream tasks. SCBMT extends SCBM by fusing adjective-based representation with contextual embeddings from transformers to balance interpretability and classification performance. Beyond competitive results, these two models offer fine-grained explanations at both instance (local) and class (global) levels. We also investigate how additional metadata, e.g., annotators' demographic profiles, can be leveraged. For Subtask 1.1, XLM-RoBERTa, fine-tuned on provided data augmented with prior datasets, ranks 6th for English and Spanish and 4th for English in the Soft-Soft evaluation. Our SCBMT achieves 7th for English and Spanish and 6th for Spanish.
Towards Inclusive ASR: Investigating Voice Conversion for Dysarthric Speech Recognition in Low-Resource Languages
May 20, 2025Automatic speech recognition (ASR) for dysarthric speech remains challenging due to data scarcity, particularly in non-English languages. To address this, we fine-tune a voice conversion model on English dysarthric speech (UASpeech) to encode both speaker characteristics and prosodic distortions, then apply it to convert healthy non-English speech (FLEURS) into non-English dysarthric-like speech. The generated data is then used to fine-tune a multilingual ASR model, Massively Multilingual Speech (MMS), for improved dysarthric speech recognition. Evaluation on PC-GITA (Spanish), EasyCall (Italian), and SSNCE (Tamil) demonstrates that VC with both speaker and prosody conversion significantly outperforms the off-the-shelf MMS performance and conventional augmentation techniques such as speed and tempo perturbation. Objective and subjective analyses of the generated data further confirm that the generated speech simulates dysarthric characteristics.
StandUp4AI: A New Multilingual Dataset for Humor Detection in Stand-up Comedy Videos
May 24, 2025Aiming towards improving current computational models of humor detection, we propose a new multimodal dataset of stand-up comedies, in seven languages: English, French, Spanish, Italian, Portuguese, Hungarian and Czech. Our dataset of more than 330 hours, is at the time of writing the biggest available for this type of task, and the most diverse. The whole dataset is automatically annotated in laughter (from the audience), and the subpart left for model validation is manually annotated. Contrary to contemporary approaches, we do not frame the task of humor detection as a binary sequence classification, but as word-level sequence labeling, in order to take into account all the context of the sequence and to capture the continuous joke tagging mechanism typically occurring in natural conversations. As par with unimodal baselines results, we propose a method for e propose a method to enhance the automatic laughter detection based on Audio Speech Recognition errors. Our code and data are available online: https://tinyurl.com/EMNLPHumourStandUpPublic
Enhancing Multilingual Language Models for Code-Switched Input Data
Mar 11, 2025Code-switching, or alternating between languages within a single conversation, presents challenges for multilingual language models on NLP tasks. This research investigates if pre-training Multilingual BERT (mBERT) on code-switched datasets improves the model's performance on critical NLP tasks such as part of speech tagging, sentiment analysis, named entity recognition, and language identification. We use a dataset of Spanglish tweets for pre-training and evaluate the pre-trained model against a baseline model. Our findings show that our pre-trained mBERT model outperforms or matches the baseline model in the given tasks, with the most significant improvements seen for parts of speech tagging. Additionally, our latent analysis uncovers more homogenous English and Spanish embeddings for language identification tasks, providing insights for future modeling work. This research highlights potential for adapting multilingual LMs for code-switched input data in order for advanced utility in globalized and multilingual contexts. Future work includes extending experiments to other language pairs, incorporating multiform data, and exploring methods for better understanding context-dependent code-switches.
Common Ground, Diverse Roots: The Difficulty of Classifying Common Examples in Spanish Varieties
Dec 16, 2024Variations in languages across geographic regions or cultures are crucial to address to avoid biases in NLP systems designed for culturally sensitive tasks, such as hate speech detection or dialog with conversational agents. In languages such as Spanish, where varieties can significantly overlap, many examples can be valid across them, which we refer to as common examples. Ignoring these examples may cause misclassifications, reducing model accuracy and fairness. Therefore, accounting for these common examples is essential to improve the robustness and representativeness of NLP systems trained on such data. In this work, we address this problem in the context of Spanish varieties. We use training dynamics to automatically detect common examples or errors in existing Spanish datasets. We demonstrate the efficacy of using predicted label confidence for our Datamaps \cite{swayamdipta-etal-2020-dataset} implementation for the identification of hard-to-classify examples, especially common examples, enhancing model performance in variety identification tasks. Additionally, we introduce a Cuban Spanish Variety Identification dataset with common examples annotations developed to facilitate more accurate detection of Cuban and Caribbean Spanish varieties. To our knowledge, this is the first dataset focused on identifying the Cuban, or any other Caribbean, Spanish variety.
Enhancing Polyglot Voices by Leveraging Cross-Lingual Fine-Tuning in Any-to-One Voice Conversion
Sep 25, 2024The creation of artificial polyglot voices remains a challenging task, despite considerable progress in recent years. This paper investigates self-supervised learning for voice conversion to create native-sounding polyglot voices. We introduce a novel cross-lingual any-to-one voice conversion system that is able to preserve the source accent without the need for multilingual data from the target speaker. In addition, we show a novel cross-lingual fine-tuning strategy that further improves the accent and reduces the training data requirements. Objective and subjective evaluations with English, Spanish, French and Mandarin Chinese confirm that our approach improves on state-of-the-art methods, enhancing the speech intelligibility and overall quality of the converted speech, especially in cross-lingual scenarios. Audio samples are available at https://giuseppe-ruggiero.github.io/a2o-vc-demo/
Rethinking and Improving Multi-task Learning for End-to-end Speech Translation
Nov 07, 2023



Significant improvements in end-to-end speech translation (ST) have been achieved through the application of multi-task learning. However, the extent to which auxiliary tasks are highly consistent with the ST task, and how much this approach truly helps, have not been thoroughly studied. In this paper, we investigate the consistency between different tasks, considering different times and modules. We find that the textual encoder primarily facilitates cross-modal conversion, but the presence of noise in speech impedes the consistency between text and speech representations. Furthermore, we propose an improved multi-task learning (IMTL) approach for the ST task, which bridges the modal gap by mitigating the difference in length and representation. We conduct experiments on the MuST-C dataset. The results demonstrate that our method attains state-of-the-art results. Moreover, when additional data is used, we achieve the new SOTA result on MuST-C English to Spanish task with 20.8% of the training time required by the current SOTA method.
Translatotron 3: Speech to Speech Translation with Monolingual Data
Jun 01, 2023This paper presents Translatotron 3, a novel approach to train a direct speech-to-speech translation model from monolingual speech-text datasets only in a fully unsupervised manner. Translatotron 3 combines masked autoencoder, unsupervised embedding mapping, and back-translation to achieve this goal. Experimental results in speech-to-speech translation tasks between Spanish and English show that Translatotron 3 outperforms a baseline cascade system, reporting 18.14 BLEU points improvement on the synthesized Unpaired-Conversational dataset. In contrast to supervised approaches that necessitate real paired data, which is unavailable, or specialized modeling to replicate para-/non-linguistic information, Translatotron 3 showcases its capability to retain para-/non-linguistic such as pauses, speaking rates, and speaker identity. Audio samples can be found in our website http://google-research.github.io/lingvo-lab/translatotron3
Towards cross-language prosody transfer for dialog
Jul 09, 2023



Speech-to-speech translation systems today do not adequately support use for dialog purposes. In particular, nuances of speaker intent and stance can be lost due to improper prosody transfer. We present an exploration of what needs to be done to overcome this. First, we developed a data collection protocol in which bilingual speakers re-enact utterances from an earlier conversation in their other language, and used this to collect an English-Spanish corpus, so far comprising 1871 matched utterance pairs. Second, we developed a simple prosodic dissimilarity metric based on Euclidean distance over a broad set of prosodic features. We then used these to investigate cross-language prosodic differences, measure the likely utility of three simple baseline models, and identify phenomena which will require more powerful modeling. Our findings should inform future research on cross-language prosody and the design of speech-to-speech translation systems capable of effective prosody transfer.
Assessing the impact of contextual information in hate speech detection
Oct 05, 2022
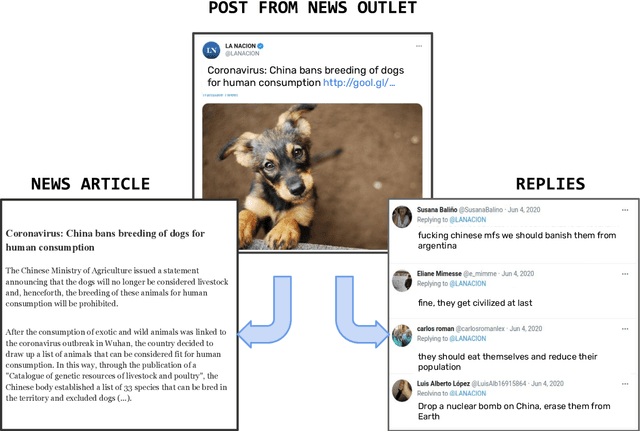
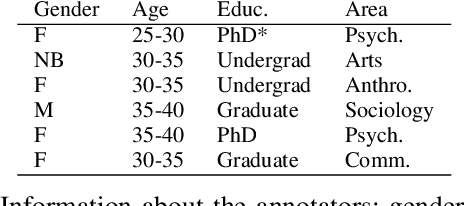
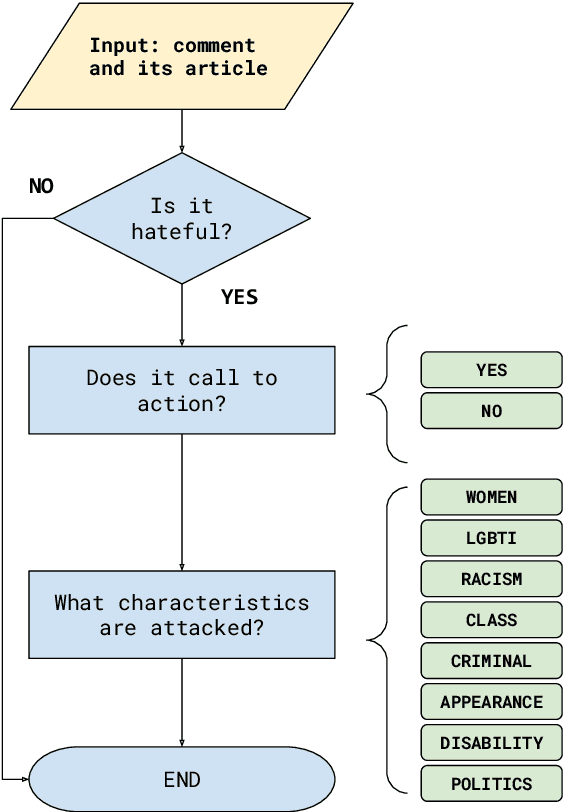
In recent years, hate speech has gained great relevance in social networks and other virtual media because of its intensity and its relationship with violent acts against members of protected groups. Due to the great amount of content generated by users, great effort has been made in the research and development of automatic tools to aid the analysis and moderation of this speech, at least in its most threatening forms. One of the limitations of current approaches to automatic hate speech detection is the lack of context. Most studies and resources are performed on data without context; that is, isolated messages without any type of conversational context or the topic being discussed. This restricts the available information to define if a post on a social network is hateful or not. In this work, we provide a novel corpus for contextualized hate speech detection based on user responses to news posts from media outlets on Twitter. This corpus was collected in the Rioplatense dialectal variety of Spanish and focuses on hate speech associated with the COVID-19 pandemic. Classification experiments using state-of-the-art techniques show evidence that adding contextual information improves hate speech detection performance for two proposed tasks (binary and multi-label prediction). We make our code, models, and corpus available for further research.