 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Mono-to-Binaural Speech Synthesis
Dec 11, 2024



We present ZeroBAS, a neural method to synthesize binaural audio from monaural audio recordings and positional information without training on any binaural data. To our knowledge, this is the first published zero-shot neural approach to mono-to-binaural audio synthesis. Specifically, we show that a parameter-free geometric time warping and amplitude scaling based on source location suffices to get an initial binaural synthesis that can be refined by iteratively applying a pretrained denoising vocoder. Furthermore, we find this leads to generalization across room conditions, which we measure by introducing a new dataset, TUT Mono-to-Binaural, to evaluate state-of-the-art monaural-to-binaural synthesis methods on unseen conditions. Our zero-shot method is perceptually on-par with the performance of supervised methods on the standard mono-to-binaural dataset, and even surpasses them on our out-of-distribution TUT Mono-to-Binaural dataset. Our results highlight the potential of pretrained generative audio models and zero-shot learning to unlock robust binaural audio synthesis.
Translatotron 3: Speech to Speech Translation with Monolingual Data
Jun 01, 2023This paper presents Translatotron 3, a novel approach to train a direct speech-to-speech translation model from monolingual speech-text datasets only in a fully unsupervised manner. Translatotron 3 combines masked autoencoder, unsupervised embedding mapping, and back-translation to achieve this goal. Experimental results in speech-to-speech translation tasks between Spanish and English show that Translatotron 3 outperforms a baseline cascade system, reporting 18.14 BLEU points improvement on the synthesized Unpaired-Conversational dataset. In contrast to supervised approaches that necessitate real paired data, which is unavailable, or specialized modeling to replicate para-/non-linguistic information, Translatotron 3 showcases its capability to retain para-/non-linguistic such as pauses, speaking rates, and speaker identity. Audio samples can be found in our website http://google-research.github.io/lingvo-lab/translatotron3
LMs with a Voice: Spoken Language Modeling beyond Speech Tokens
May 24, 2023



We present SPECTRON, a novel approach to adapting pre-trained language models (LMs) to perform speech continuation. By leveraging pre-trained speech encoders, our model generates both text and speech outputs with the entire system being trained end-to-end operating directly on spectrograms. Training the entire model in the spectrogram domain simplifies our speech continuation system versus existing cascade methods which use discrete speech representations. We further show our method surpasses existing spoken language models both in semantic content and speaker preservation while also benefiting from the knowledge transferred from pre-existing models. Audio samples can be found in our website https://michelleramanovich.github.io/spectron/spectron
Zero-Shot Voice Conditioning for Denoising Diffusion TTS Models
Jun 05, 2022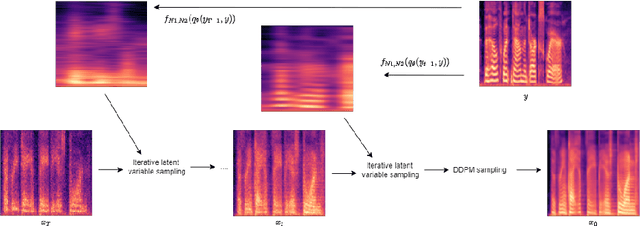
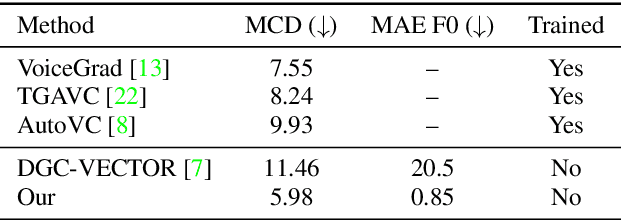
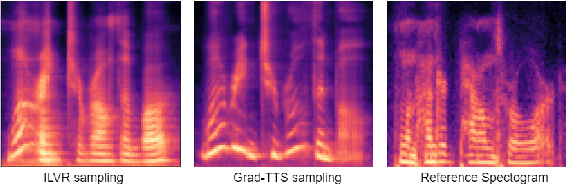
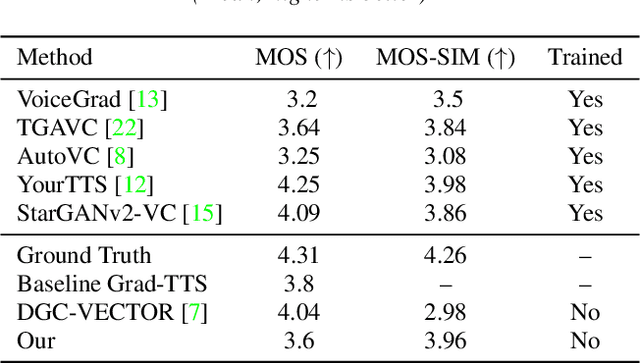
We present a novel way of conditioning a pretrained denoising diffusion speech model to produce speech in the voice of a novel person unseen during training. The method requires a short (~3 seconds) sample from the target person, and generation is steered at inference time, without any training steps. At the heart of the method lies a sampling process that combines the estimation of the denoising model with a low-pass version of the new speaker's sample. The objective and subjective evaluations show that our sampling method can generate a voice similar to that of the target speaker in terms of frequency, with an accuracy comparable to state-of-the-art methods, and without training.