 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSLM-SS: Speech Language Model for Generative Speech Separation
Jan 27, 2026Speech separation (SS) has advanced significantly with neural network-based methods, showing improved performance on signal-level metrics. However, these methods often struggle to maintain speech intelligibility in the separated signals, which can negatively affect the performance of downstream tasks such as speech recognition. In this work, we propose SLM-SS, a novel approach that applies speech language models to SS, aiming to enhance the intelligibility and coherence of the separated signals. We frame SS as discrete multi-codebook sequence generation, using Encoder-Decoder models to map quantized speech mixtures to target tokens. In addition to the autoregressive modeling strategy, we introduce a non-autoregressive model to improve decoding efficiency for residual tokens. Experimental results on the LibriMix dataset demonstrate that our approach shows significantly better preservation of speech intelligibility, leading to improved linguistic consistency in a variety of downstream tasks compared to existing approaches.
FHSTP@EXIST 2025 Benchmark: Sexism Detection with Transparent Speech Concept Bottleneck Models
Jul 28, 2025Sexism has become widespread on social media and in online conversation. To help address this issue, the fifth Sexism Identification in Social Networks (EXIST) challenge is initiated at CLEF 2025. Among this year's international benchmarks, we concentrate on solving the first task aiming to identify and classify sexism in social media textual posts. In this paper, we describe our solutions and report results for three subtasks: Subtask 1.1 - Sexism Identification in Tweets, Subtask 1.2 - Source Intention in Tweets, and Subtask 1.3 - Sexism Categorization in Tweets. We implement three models to address each subtask which constitute three individual runs: Speech Concept Bottleneck Model (SCBM), Speech Concept Bottleneck Model with Transformer (SCBMT), and a fine-tuned XLM-RoBERTa transformer model. SCBM uses descriptive adjectives as human-interpretable bottleneck concepts. SCBM leverages large language models (LLMs) to encode input texts into a human-interpretable representation of adjectives, then used to train a lightweight classifier for downstream tasks. SCBMT extends SCBM by fusing adjective-based representation with contextual embeddings from transformers to balance interpretability and classification performance. Beyond competitive results, these two models offer fine-grained explanations at both instance (local) and class (global) levels. We also investigate how additional metadata, e.g., annotators' demographic profiles, can be leveraged. For Subtask 1.1, XLM-RoBERTa, fine-tuned on provided data augmented with prior datasets, ranks 6th for English and Spanish and 4th for English in the Soft-Soft evaluation. Our SCBMT achieves 7th for English and Spanish and 6th for Spanish.
"Double vaccinated, 5G boosted!": Learning Attitudes towards COVID-19 Vaccination from Social Media
Jun 27, 2022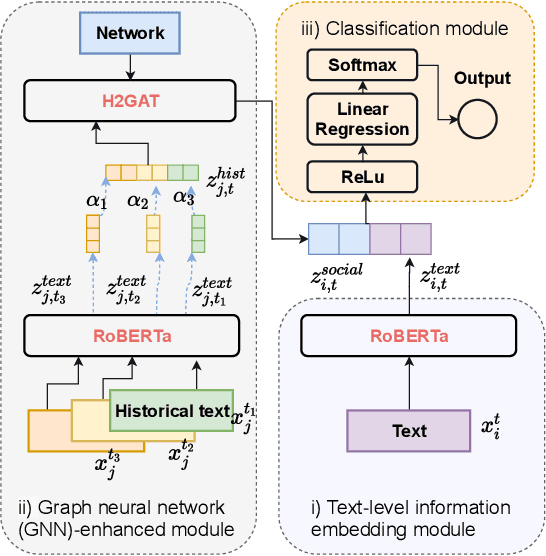

To address the vaccine hesitancy which impairs the efforts of the COVID-19 vaccination campaign, it is imperative to understand public vaccination attitudes and timely grasp their changes. In spite of reliability and trustworthiness, conventional attitude collection based on surveys is time-consuming and expensive, and cannot follow the fast evolution of vaccination attitudes. We leverage the textual posts on social media to extract and track users' vaccination stances in near real time by proposing a deep learning framework. To address the impact of linguistic features such as sarcasm and irony commonly used in vaccine-related discourses, we integrate into the framework the recent posts of a user's social network neighbours to help detect the user's genuine attitude. Based on our annotated dataset from Twitter, the models instantiated from our framework can increase the performance of attitude extraction by up to 23% compared to state-of-the-art text-only models. Using this framework, we successfully validate the feasibility of using social media to track the evolution of vaccination attitudes in real life. We further show one practical use of our framework by validating the possibility to forecast a user's vaccine hesitancy changes with information perceived from social media.
A Multilingual Dataset of COVID-19 Vaccination Attitudes on Twitter
Jun 27, 2022
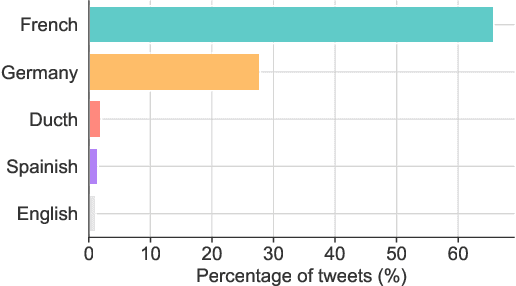
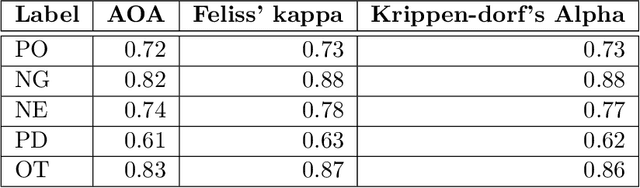
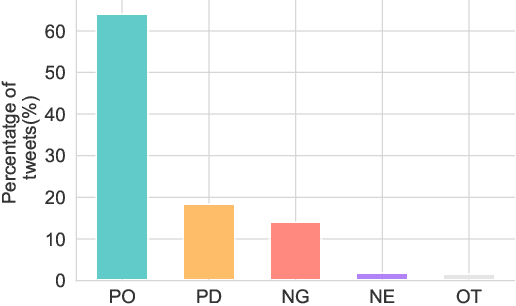
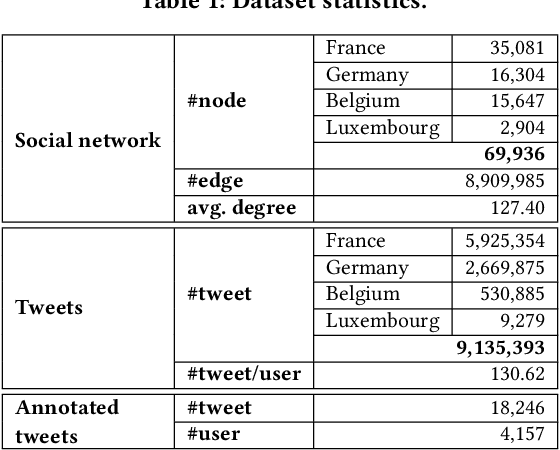
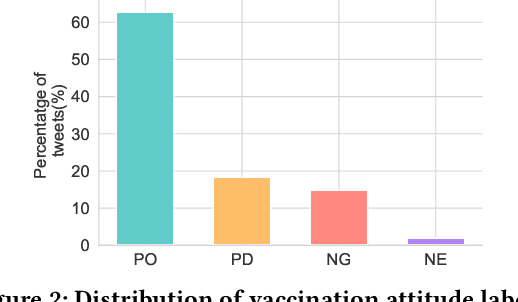
Vaccine hesitancy is considered as one main cause of the stagnant uptake ratio of COVID-19 vaccines in Europe and the US where vaccines are sufficiently supplied. Fast and accurate grasp of public attitudes toward vaccination is critical to address vaccine hesitancy, and social media platforms have proved to be an effective source of public opinions. In this paper, we describe the collection and release of a dataset of tweets related to COVID-19 vaccines. This dataset consists of the IDs of 2,198,090 tweets collected from Western Europe, 17,934 of which are annotated with the originators' vaccination stances. Our annotation will facilitate using and developing data-driven models to extract vaccination attitudes from social media posts and thus further confirm the power of social media in public health surveillance. To lay the groundwork for future research, we not only perform statistical analysis and visualisation of our dataset, but also evaluate and compare the performance of established text-based benchmarks in vaccination stance extraction. We demonstrate one potential use of our data in practice in tracking the temporal changes of public COVID-19 vaccination attitudes.