 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Cross-Modal Knowledge Distillation: A Disentanglement Approach for RGBD Semantic Segmentation
May 30, 2025Multi-modal RGB and Depth (RGBD) data are predominant in many domains such as robotics, autonomous driving and remote sensing. The combination of these multi-modal data enhances environmental perception by providing 3D spatial context, which is absent in standard RGB images. Although RGBD multi-modal data can be available to train computer vision models, accessing all sensor modalities during the inference stage may be infeasible due to sensor failures or resource constraints, leading to a mismatch between data modalities available during training and inference. Traditional Cross-Modal Knowledge Distillation (CMKD) frameworks, developed to address this task, are typically based on a teacher/student paradigm, where a multi-modal teacher distills knowledge into a single-modality student model. However, these approaches face challenges in teacher architecture choices and distillation process selection, thus limiting their adoption in real-world scenarios. To overcome these issues, we introduce CroDiNo-KD (Cross-Modal Disentanglement: a New Outlook on Knowledge Distillation), a novel cross-modal knowledge distillation framework for RGBD semantic segmentation. Our approach simultaneously learns single-modality RGB and Depth models by exploiting disentanglement representation, contrastive learning and decoupled data augmentation with the aim to structure the internal manifolds of neural network models through interaction and collaboration. We evaluated CroDiNo-KD on three RGBD datasets across diverse domains, considering recent CMKD frameworks as competitors. Our findings illustrate the quality of CroDiNo-KD, and they suggest reconsidering the conventional teacher/student paradigm to distill information from multi-modal data to single-modality neural networks.
Eta-WavLM: Efficient Speaker Identity Removal in Self-Supervised Speech Representations Using a Simple Linear Equation
May 25, 2025Self-supervised learning (SSL) has reduced the reliance on expensive labeling in speech technologies by learning meaningful representations from unannotated data. Since most SSL-based downstream tasks prioritize content information in speech, ideal representations should disentangle content from unwanted variations like speaker characteristics in the SSL representations. However, removing speaker information often degrades other speech components, and existing methods either fail to fully disentangle speaker identity or require resource-intensive models. In this paper, we propose a novel disentanglement method that linearly decomposes SSL representations into speaker-specific and speaker-independent components, effectively generating speaker disentangled representations. Comprehensive experiments show that our approach achieves speaker independence and as such, when applied to content-driven tasks such as voice conversion, our representations yield significant improvements over state-of-the-art methods.
Enhancing Polyglot Voices by Leveraging Cross-Lingual Fine-Tuning in Any-to-One Voice Conversion
Sep 25, 2024The creation of artificial polyglot voices remains a challenging task, despite considerable progress in recent years. This paper investigates self-supervised learning for voice conversion to create native-sounding polyglot voices. We introduce a novel cross-lingual any-to-one voice conversion system that is able to preserve the source accent without the need for multilingual data from the target speaker. In addition, we show a novel cross-lingual fine-tuning strategy that further improves the accent and reduces the training data requirements. Objective and subjective evaluations with English, Spanish, French and Mandarin Chinese confirm that our approach improves on state-of-the-art methods, enhancing the speech intelligibility and overall quality of the converted speech, especially in cross-lingual scenarios. Audio samples are available at https://giuseppe-ruggiero.github.io/a2o-vc-demo/
Towards a multimodal framework for remote sensing image change retrieval and captioning
Jun 19, 2024



Recently, there has been increasing interest in multimodal applications that integrate text with other modalities, such as images, audio and video, to facilitate natural language interactions with multimodal AI systems. While applications involving standard modalities have been extensively explored, there is still a lack of investigation into specific data modalities such as remote sensing (RS) data. Despite the numerous potential applications of RS data, including environmental protection, disaster monitoring and land planning, available solutions are predominantly focused on specific tasks like classification, captioning and retrieval. These solutions often overlook the unique characteristics of RS data, such as its capability to systematically provide information on the same geographical areas over time. This ability enables continuous monitoring of changes in the underlying landscape. To address this gap, we propose a novel foundation model for bi-temporal RS image pairs, in the context of change detection analysis, leveraging Contrastive Learning and the LEVIR-CC dataset for both captioning and text-image retrieval. By jointly training a contrastive encoder and captioning decoder, our model add text-image retrieval capabilities, in the context of bi-temporal change detection, while maintaining captioning performances that are comparable to the state of the art. We release the source code and pretrained weights at: https://github.com/rogerferrod/RSICRC.
EcoVerse: An Annotated Twitter Dataset for Eco-Relevance Classification, Environmental Impact Analysis, and Stance Detection
Apr 08, 2024



Anthropogenic ecological crisis constitutes a significant challenge that all within the academy must urgently face, including the Natural Language Processing (NLP) community. While recent years have seen increasing work revolving around climate-centric discourse, crucial environmental and ecological topics outside of climate change remain largely unaddressed, despite their prominent importance. Mainstream NLP tasks, such as sentiment analysis, dominate the scene, but there remains an untouched space in the literature involving the analysis of environmental impacts of certain events and practices. To address this gap, this paper presents EcoVerse, an annotated English Twitter dataset of 3,023 tweets spanning a wide spectrum of environmental topics. We propose a three-level annotation scheme designed for Eco-Relevance Classification, Stance Detection, and introducing an original approach for Environmental Impact Analysis. We detail the data collection, filtering, and labeling process that led to the creation of the dataset. Remarkable Inter-Annotator Agreement indicates that the annotation scheme produces consistent annotations of high quality. Subsequent classification experiments using BERT-based models, including ClimateBERT, are presented. These yield encouraging results, while also indicating room for a model specifically tailored for environmental texts. The dataset is made freely available to stimulate further research.
Combining Contrastive Learning and Knowledge Graph Embeddings to develop medical word embeddings for the Italian language
Nov 09, 2022



Word embeddings play a significant role in today's Natural Language Processing tasks and applications. While pre-trained models may be directly employed and integrated into existing pipelines, they are often fine-tuned to better fit with specific languages or domains. In this paper, we attempt to improve available embeddings in the uncovered niche of the Italian medical domain through the combination of Contrastive Learning (CL) and Knowledge Graph Embedding (KGE). The main objective is to improve the accuracy of semantic similarity between medical terms, which is also used as an evaluation task. Since the Italian language lacks medical texts and controlled vocabularies, we have developed a specific solution by combining preexisting CL methods (multi-similarity loss, contextualization, dynamic sampling) and the integration of KGEs, creating a new variant of the loss. Although without having outperformed the state-of-the-art, represented by multilingual models, the obtained results are encouraging, providing a significant leap in performance compared to the starting model, while using a significantly lower amount of data.
Voice Cloning: a Multi-Speaker Text-to-Speech Synthesis Approach based on Transfer Learning
Feb 10, 2021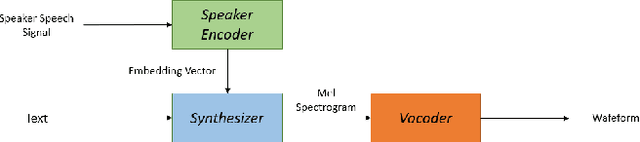
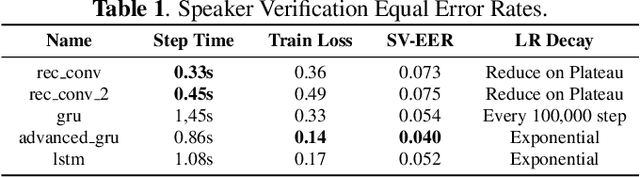
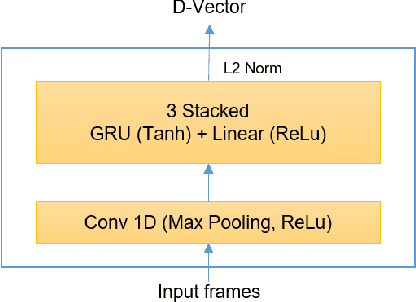
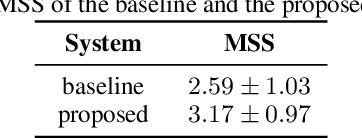
Deep learning models are becoming predominant in many fields of machine learning. Text-to-Speech (TTS), the process of synthesizing artificial speech from text, is no exception. To this end, a deep neural network is usually trained using a corpus of several hours of recorded speech from a single speaker. Trying to produce the voice of a speaker other than the one learned is expensive and requires large effort since it is necessary to record a new dataset and retrain the model. This is the main reason why the TTS models are usually single speaker. The proposed approach has the goal to overcome these limitations trying to obtain a system which is able to model a multi-speaker acoustic space. This allows the generation of speech audio similar to the voice of different target speakers, even if they were not observed during the training phase.
A Bimodal Network Approach to Model Topic Dynamics
Sep 27, 2017
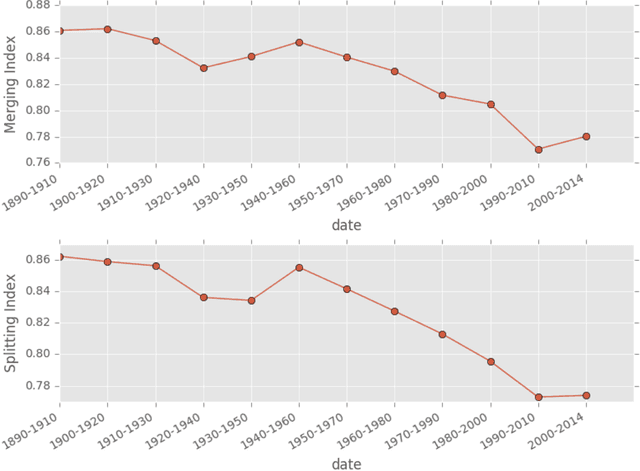
This paper presents an intertemporal bimodal network to analyze the evolution of the semantic content of a scientific field within the framework of topic modeling, namely using the Latent Dirichlet Allocation (LDA). The main contribution is the conceptualization of the topic dynamics and its formalization and codification into an algorithm. To benchmark the effectiveness of this approach, we propose three indexes which track the transformation of topics over time, their rate of birth and death, and the novelty of their content. Applying the LDA, we test the algorithm both on a controlled experiment and on a corpus of several thousands of scientific papers over a period of more than 100 years which account for the history of the economic thought.