 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEta-WavLM: Efficient Speaker Identity Removal in Self-Supervised Speech Representations Using a Simple Linear Equation
May 25, 2025Self-supervised learning (SSL) has reduced the reliance on expensive labeling in speech technologies by learning meaningful representations from unannotated data. Since most SSL-based downstream tasks prioritize content information in speech, ideal representations should disentangle content from unwanted variations like speaker characteristics in the SSL representations. However, removing speaker information often degrades other speech components, and existing methods either fail to fully disentangle speaker identity or require resource-intensive models. In this paper, we propose a novel disentanglement method that linearly decomposes SSL representations into speaker-specific and speaker-independent components, effectively generating speaker disentangled representations. Comprehensive experiments show that our approach achieves speaker independence and as such, when applied to content-driven tasks such as voice conversion, our representations yield significant improvements over state-of-the-art methods.
Enhancing Polyglot Voices by Leveraging Cross-Lingual Fine-Tuning in Any-to-One Voice Conversion
Sep 25, 2024The creation of artificial polyglot voices remains a challenging task, despite considerable progress in recent years. This paper investigates self-supervised learning for voice conversion to create native-sounding polyglot voices. We introduce a novel cross-lingual any-to-one voice conversion system that is able to preserve the source accent without the need for multilingual data from the target speaker. In addition, we show a novel cross-lingual fine-tuning strategy that further improves the accent and reduces the training data requirements. Objective and subjective evaluations with English, Spanish, French and Mandarin Chinese confirm that our approach improves on state-of-the-art methods, enhancing the speech intelligibility and overall quality of the converted speech, especially in cross-lingual scenarios. Audio samples are available at https://giuseppe-ruggiero.github.io/a2o-vc-demo/
Voice Cloning: a Multi-Speaker Text-to-Speech Synthesis Approach based on Transfer Learning
Feb 10, 2021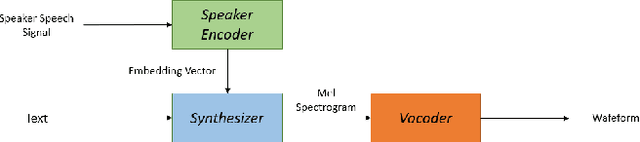
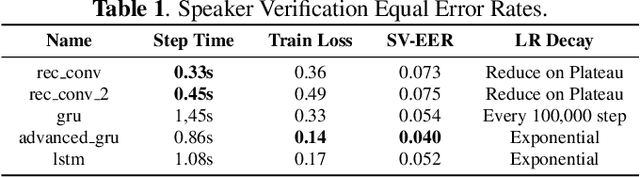
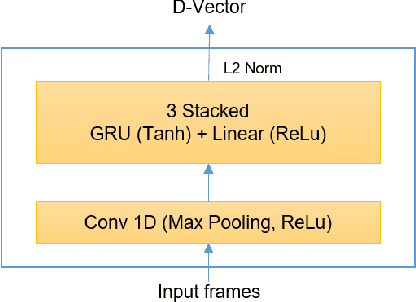
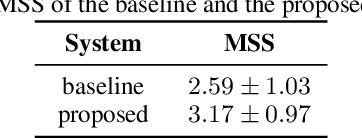
Deep learning models are becoming predominant in many fields of machine learning. Text-to-Speech (TTS), the process of synthesizing artificial speech from text, is no exception. To this end, a deep neural network is usually trained using a corpus of several hours of recorded speech from a single speaker. Trying to produce the voice of a speaker other than the one learned is expensive and requires large effort since it is necessary to record a new dataset and retrain the model. This is the main reason why the TTS models are usually single speaker. The proposed approach has the goal to overcome these limitations trying to obtain a system which is able to model a multi-speaker acoustic space. This allows the generation of speech audio similar to the voice of different target speakers, even if they were not observed during the training phase.