 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmall Footprint Keyword Spotting
Papers and Code
Keyword Spotting with Hyper-Matched Filters for Small Footprint Devices
Aug 06, 2025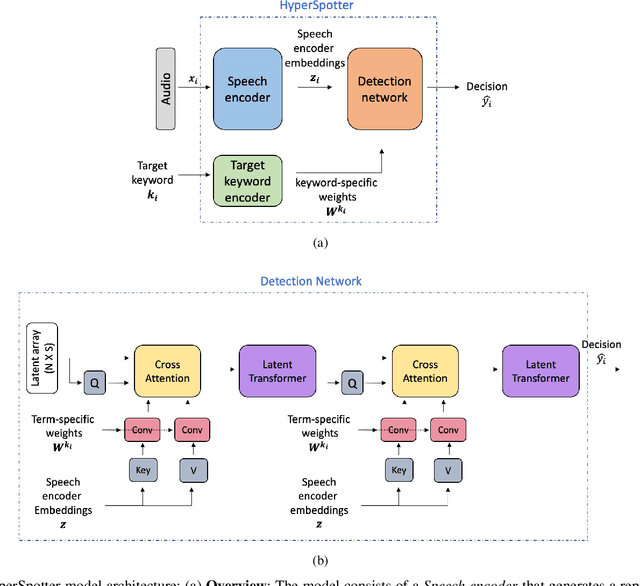
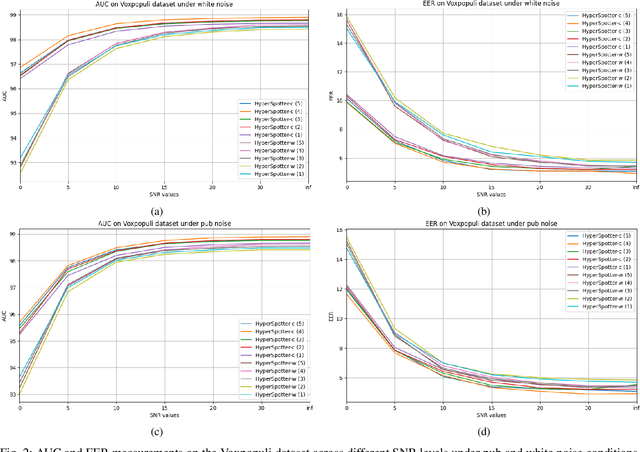
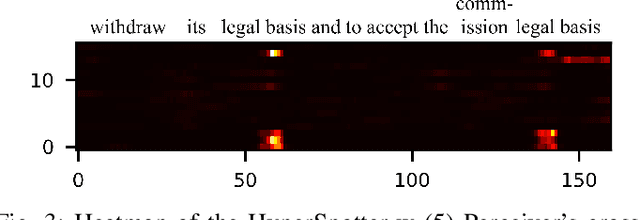
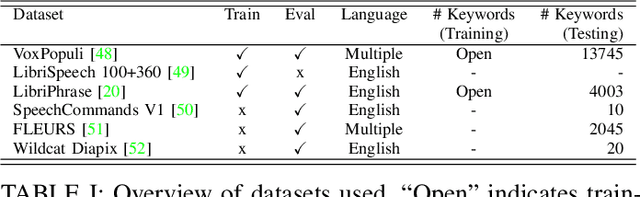
Open-vocabulary keyword spotting (KWS) refers to the task of detecting words or terms within speech recordings, regardless of whether they were included in the training data. This paper introduces an open-vocabulary keyword spotting model with state-of-the-art detection accuracy for small-footprint devices. The model is composed of a speech encoder, a target keyword encoder, and a detection network. The speech encoder is either a tiny Whisper or a tiny Conformer. The target keyword encoder is implemented as a hyper-network that takes the desired keyword as a character string and generates a unique set of weights for a convolutional layer, which can be considered as a keyword-specific matched filter. The detection network uses the matched-filter weights to perform a keyword-specific convolution, which guides the cross-attention mechanism of a Perceiver module in determining whether the target term appears in the recording. The results indicate that our system achieves state-of-the-art detection performance and generalizes effectively to out-of-domain conditions, including second-language (L2) speech. Notably, our smallest model, with just 4.2 million parameters, matches or outperforms models that are several times larger, demonstrating both efficiency and robustness.
Advances in Small-Footprint Keyword Spotting: A Comprehensive Review of Efficient Models and Algorithms
Jun 12, 2025



Small-Footprint Keyword Spotting (SF-KWS) has gained popularity in today's landscape of smart voice-activated devices, smartphones, and Internet of Things (IoT) applications. This surge is attributed to the advancements in Deep Learning, enabling the identification of predefined words or keywords from a continuous stream of words. To implement the SF-KWS model on edge devices with low power and limited memory in real-world scenarios, a efficient Tiny Machine Learning (TinyML) framework is essential. In this study, we explore seven distinct categories of techniques namely, Model Architecture, Learning Techniques, Model Compression, Attention Awareness Architecture, Feature Optimization, Neural Network Search, and Hybrid Approaches, which are suitable for developing an SF-KWS system. This comprehensive overview will serve as a valuable resource for those looking to understand, utilize, or contribute to the field of SF-KWS. The analysis conducted in this work enables the identification of numerous potential research directions, encompassing insights from automatic speech recognition research and those specifically pertinent to the realm of spoken SF-KWS.
AnalyticKWS: Towards Exemplar-Free Analytic Class Incremental Learning for Small-footprint Keyword Spotting
May 17, 2025Keyword spotting (KWS) offers a vital mechanism to identify spoken commands in voice-enabled systems, where user demands often shift, requiring models to learn new keywords continually over time. However, a major problem is catastrophic forgetting, where models lose their ability to recognize earlier keywords. Although several continual learning methods have proven their usefulness for reducing forgetting, most existing approaches depend on storing and revisiting old data to combat catastrophic forgetting. Though effective, these methods face two practical challenges: 1) privacy risks from keeping user data and 2) large memory and time consumption that limit deployment on small devices. To address these issues, we propose an exemplar-free Analytic Continual Learning (AnalyticKWS) method that updates model parameters without revisiting earlier data. Inspired by efficient learning principles, AnalyticKWS computes a closed-form analytical solution for model updates and requires only a single epoch of adaptation for incoming keywords. AnalyticKWS demands fewer computational resources by avoiding gradient-based updates and does not store old data. By eliminating the need for back-propagation during incremental learning, the model remains lightweight and efficient. As a result, AnalyticKWS meets the challenges mentioned earlier and suits resource-limited settings well. Extensive experiments on various datasets and settings show that AnalyticKWS consistently outperforms existing continual learning methods.
AdaKWS: Towards Robust Keyword Spotting with Test-Time Adaptation
May 20, 2025Spoken keyword spotting (KWS) aims to identify keywords in audio for wide applications, especially on edge devices. Current small-footprint KWS systems focus on efficient model designs. However, their inference performance can decline in unseen environments or noisy backgrounds. Test-time adaptation (TTA) helps models adapt to test samples without needing the original training data. In this study, we present AdaKWS, the first TTA method for robust KWS to the best of our knowledge. Specifically, 1) We initially optimize the model's confidence by selecting reliable samples based on prediction entropy minimization and adjusting the normalization statistics in each batch. 2) We introduce pseudo-keyword consistency (PKC) to identify critical, reliable features without overfitting to noise. Our experiments show that AdaKWS outperforms other methods across various conditions, including Gaussian noise and real-scenario noises. The code will be released in due course.
NTC-KWS: Noise-aware CTC for Robust Keyword Spotting
Dec 17, 2024



In recent years, there has been a growing interest in designing small-footprint yet effective Connectionist Temporal Classification based keyword spotting (CTC-KWS) systems. They are typically deployed on low-resource computing platforms, where limitations on model size and computational capacity create bottlenecks under complicated acoustic scenarios. Such constraints often result in overfitting and confusion between keywords and background noise, leading to high false alarms. To address these issues, we propose a noise-aware CTC-based KWS (NTC-KWS) framework designed to enhance model robustness in noisy environments, particularly under extremely low signal-to-noise ratios. Our approach introduces two additional noise-modeling wildcard arcs into the training and decoding processes based on weighted finite state transducer (WFST) graphs: self-loop arcs to address noise insertion errors and bypass arcs to handle masking and interference caused by excessive noise. Experiments on clean and noisy Hey Snips show that NTC-KWS outperforms state-of-the-art (SOTA) end-to-end systems and CTC-KWS baselines across various acoustic conditions, with particularly strong performance in low SNR scenarios.
Disentangled Training with Adversarial Examples For Robust Small-footprint Keyword Spotting
Aug 23, 2024



A keyword spotting (KWS) engine that is continuously running on device is exposed to various speech signals that are usually unseen before. It is a challenging problem to build a small-footprint and high-performing KWS model with robustness under different acoustic environments. In this paper, we explore how to effectively apply adversarial examples to improve KWS robustness. We propose datasource-aware disentangled learning with adversarial examples to reduce the mismatch between the original and adversarial data as well as the mismatch across original training datasources. The KWS model architecture is based on depth-wise separable convolution and a simple attention module. Experimental results demonstrate that the proposed learning strategy improves false reject rate by $40.31%$ at $1%$ false accept rate on the internal dataset, compared to the strongest baseline without using adversarial examples. Our best-performing system achieves $98.06%$ accuracy on the Google Speech Commands V1 dataset.
Frequency & Channel Attention Network for Small Footprint Noisy Spoken Keyword Spotting
Jul 29, 2024



In this paper, we aim to improve the robustness of Keyword Spotting (KWS) systems in noisy environments while keeping a small memory footprint. We propose a new convolutional neural network (CNN) called FCA-Net, which combines mixer unit-based feature interaction with a two-dimensional convolution-based attention module. First, we introduce and compare lightweight attention methods to enhance noise robustness in CNN. Then, we propose an attention module that creates fine-grained attention weights to capture channel and frequency-specific information, boosting the model's ability to handle noisy conditions. By combining the mixer unit-based feature interaction with the attention module, we enhance performance. Additionally, we use a curriculum-based multi-condition training strategy. Our experiments show that our system outperforms current state-of-the-art solutions for small-footprint KWS in noisy environments, making it reliable for real-world use.
Improving Small Footprint Few-shot Keyword Spotting with Supervision on Auxiliary Data
Aug 31, 2023



Few-shot keyword spotting (FS-KWS) models usually require large-scale annotated datasets to generalize to unseen target keywords. However, existing KWS datasets are limited in scale and gathering keyword-like labeled data is costly undertaking. To mitigate this issue, we propose a framework that uses easily collectible, unlabeled reading speech data as an auxiliary source. Self-supervised learning has been widely adopted for learning representations from unlabeled data; however, it is known to be suitable for large models with enough capacity and is not practical for training a small footprint FS-KWS model. Instead, we automatically annotate and filter the data to construct a keyword-like dataset, LibriWord, enabling supervision on auxiliary data. We then adopt multi-task learning that helps the model to enhance the representation power from out-of-domain auxiliary data. Our method notably improves the performance over competitive methods in the FS-KWS benchmark.
DCCRN-KWS: an audio bias based model for noise robust small-footprint keyword spotting
May 23, 2023



Real-world complex acoustic environments especially the ones with a low signal-to-noise ratio (SNR) will bring tremendous challenges to a keyword spotting (KWS) system. Inspired by the recent advances of neural speech enhancement and context bias in speech recognition, we propose a robust audio context bias based DCCRN-KWS model to address this challenge. We form the whole architecture as a multi-task learning framework for both denosing and keyword spotting, where the DCCRN encoder is connected with the KWS model. Helped with the denoising task, we further introduce an audio context bias module to leverage the real keyword samples and bias the network to better iscriminate keywords in noisy conditions. Feature merge and complex context linear modules are also introduced to strength such discrimination and to effectively leverage contextual information respectively. Experiments on the internal challenging dataset and the HIMIYA public dataset show that our DCCRN-KWS system is superior in performance, while ablation study demonstrates the good design of the whole model.
Small-footprint slimmable networks for keyword spotting
Apr 21, 2023



In this work, we present Slimmable Neural Networks applied to the problem of small-footprint keyword spotting. We show that slimmable neural networks allow us to create super-nets from Convolutioanl Neural Networks and Transformers, from which sub-networks of different sizes can be extracted. We demonstrate the usefulness of these models on in-house Alexa data and Google Speech Commands, and focus our efforts on models for the on-device use case, limiting ourselves to less than 250k parameters. We show that slimmable models can match (and in some cases, outperform) models trained from scratch. Slimmable neural networks are therefore a class of models particularly useful when the same functionality is to be replicated at different memory and compute budgets, with different accuracy requirements.