 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Does a Deep Neural Network Look at Lexical Stress?
Aug 10, 2025Despite their success in speech processing, neural networks often operate as black boxes, prompting the question: what informs their decisions, and how can we interpret them? This work examines this issue in the context of lexical stress. A dataset of English disyllabic words was automatically constructed from read and spontaneous speech. Several Convolutional Neural Network (CNN) architectures were trained to predict stress position from a spectrographic representation of disyllabic words lacking minimal stress pairs (e.g., initial stress WAllet, final stress exTEND), achieving up to 92% accuracy on held-out test data. Layerwise Relevance Propagation (LRP), a technique for CNN interpretability analysis, revealed that predictions for held-out minimal pairs (PROtest vs. proTEST ) were most strongly influenced by information in stressed versus unstressed syllables, particularly the spectral properties of stressed vowels. However, the classifiers also attended to information throughout the word. A feature-specific relevance analysis is proposed, and its results suggest that our best-performing classifier is strongly influenced by the stressed vowel's first and second formants, with some evidence that its pitch and third formant also contribute. These results reveal deep learning's ability to acquire distributed cues to stress from naturally occurring data, extending traditional phonetic work based around highly controlled stimuli.
Keyword Spotting with Hyper-Matched Filters for Small Footprint Devices
Aug 06, 2025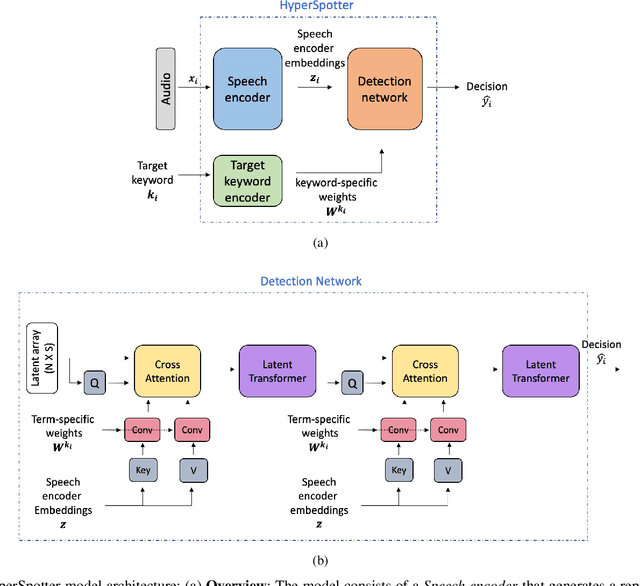
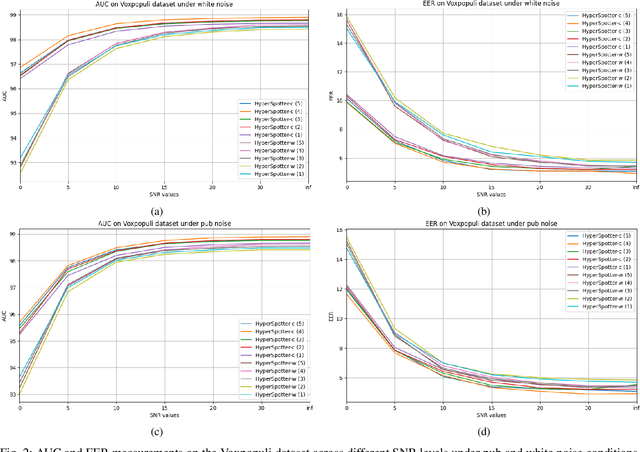
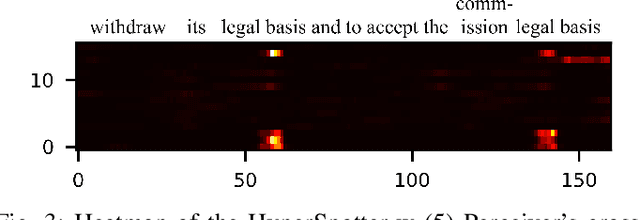
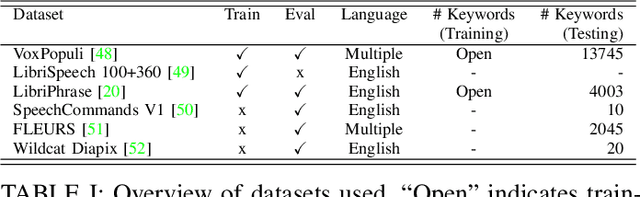
Open-vocabulary keyword spotting (KWS) refers to the task of detecting words or terms within speech recordings, regardless of whether they were included in the training data. This paper introduces an open-vocabulary keyword spotting model with state-of-the-art detection accuracy for small-footprint devices. The model is composed of a speech encoder, a target keyword encoder, and a detection network. The speech encoder is either a tiny Whisper or a tiny Conformer. The target keyword encoder is implemented as a hyper-network that takes the desired keyword as a character string and generates a unique set of weights for a convolutional layer, which can be considered as a keyword-specific matched filter. The detection network uses the matched-filter weights to perform a keyword-specific convolution, which guides the cross-attention mechanism of a Perceiver module in determining whether the target term appears in the recording. The results indicate that our system achieves state-of-the-art detection performance and generalizes effectively to out-of-domain conditions, including second-language (L2) speech. Notably, our smallest model, with just 4.2 million parameters, matches or outperforms models that are several times larger, demonstrating both efficiency and robustness.
DDKtor: Automatic Diadochokinetic Speech Analysis
Jun 29, 2022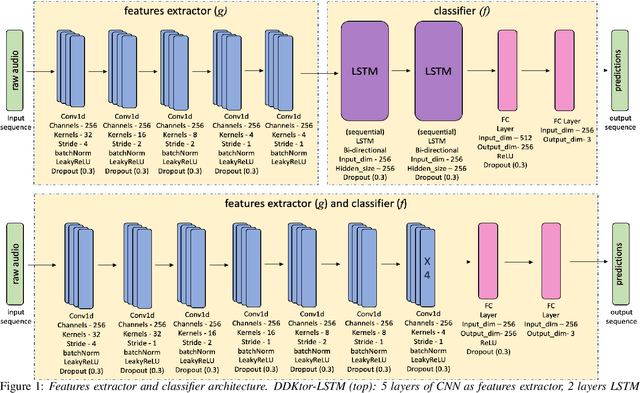
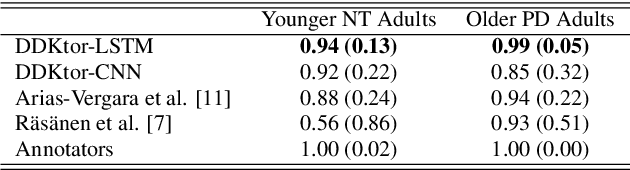
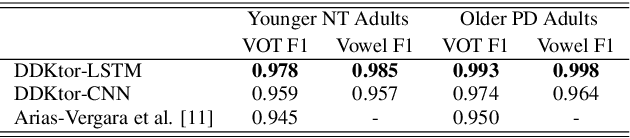
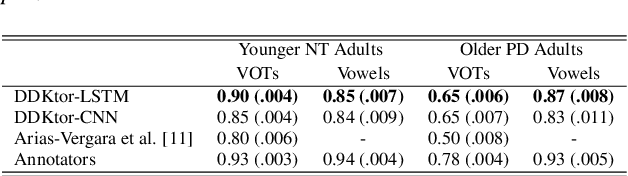
Diadochokinetic speech tasks (DDK), in which participants repeatedly produce syllables, are commonly used as part of the assessment of speech motor impairments. These studies rely on manual analyses that are time-intensive, subjective, and provide only a coarse-grained picture of speech. This paper presents two deep neural network models that automatically segment consonants and vowels from unannotated, untranscribed speech. Both models work on the raw waveform and use convolutional layers for feature extraction. The first model is based on an LSTM classifier followed by fully connected layers, while the second model adds more convolutional layers followed by fully connected layers. These segmentations predicted by the models are used to obtain measures of speech rate and sound duration. Results on a young healthy individuals dataset show that our LSTM model outperforms the current state-of-the-art systems and performs comparably to trained human annotators. Moreover, the LSTM model also presents comparable results to trained human annotators when evaluated on unseen older individuals with Parkinson's Disease dataset.
Neurocompositional computing: From the Central Paradox of Cognition to a new generation of AI systems
May 02, 2022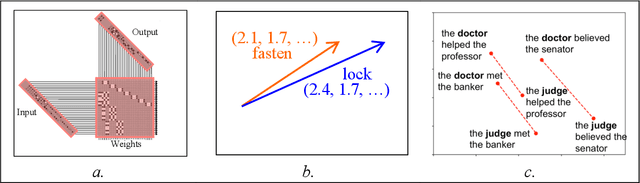
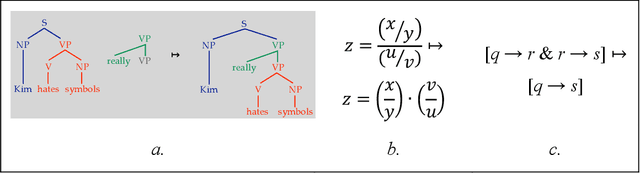
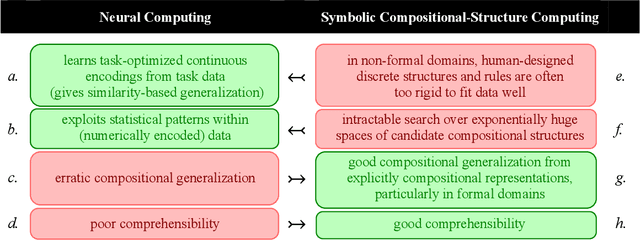
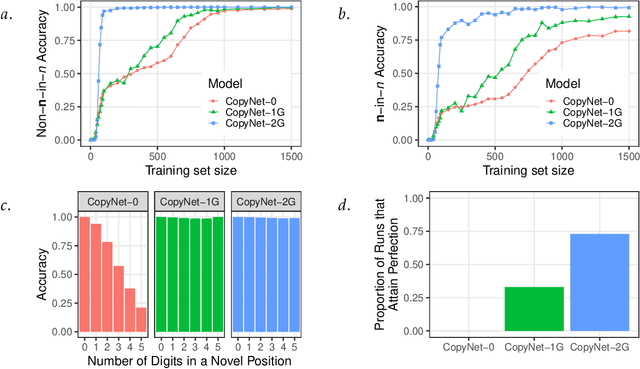
What explains the dramatic progress from 20th-century to 21st-century AI, and how can the remaining limitations of current AI be overcome? The widely accepted narrative attributes this progress to massive increases in the quantity of computational and data resources available to support statistical learning in deep artificial neural networks. We show that an additional crucial factor is the development of a new type of computation. Neurocompositional computing adopts two principles that must be simultaneously respected to enable human-level cognition: the principles of Compositionality and Continuity. These have seemed irreconcilable until the recent mathematical discovery that compositionality can be realized not only through discrete methods of symbolic computing, but also through novel forms of continuous neural computing. The revolutionary recent progress in AI has resulted from the use of limited forms of neurocompositional computing. New, deeper forms of neurocompositional computing create AI systems that are more robust, accurate, and comprehensible.
Dr.VOT : Measuring Positive and Negative Voice Onset Time in the Wild
Oct 27, 2019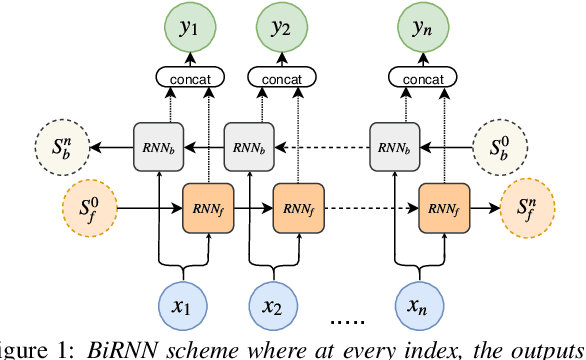
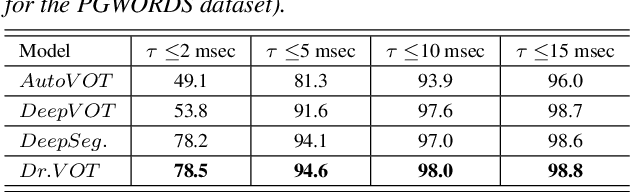
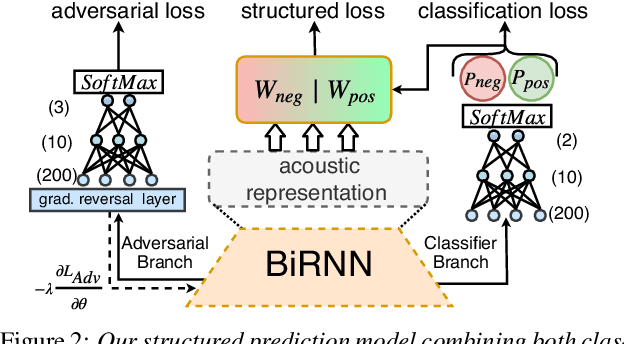
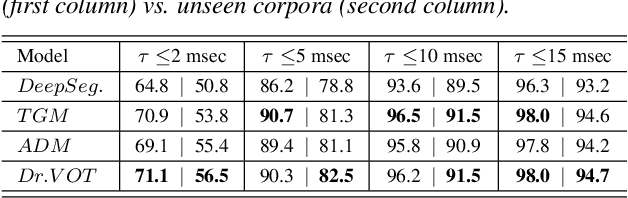
Voice Onset Time (VOT), a key measurement of speech for basic research and applied medical studies, is the time between the onset of a stop burst and the onset of voicing. When the voicing onset precedes burst onset the VOT is negative; if voicing onset follows the burst, it is positive. In this work, we present a deep-learning model for accurate and reliable measurement of VOT in naturalistic speech. The proposed system addresses two critical issues: it can measure positive and negative VOT equally well, and it is trained to be robust to variation across annotations. Our approach is based on the structured prediction framework, where the feature functions are defined to be RNNs. These learn to capture segmental variation in the signal. Results suggest that our method substantially improves over the current state-of-the-art. In contrast to previous work, our Deep and Robust VOT annotator, Dr.VOT, can successfully estimate negative VOTs while maintaining state-of-the-art performance on positive VOTs. This high level of performance generalizes to new corpora without further retraining. Index Terms: structured prediction, multi-task learning, adversarial training, recurrent neural networks, sequence segmentation.
* interspeech 2019
Automatic measurement of vowel duration via structured prediction
Oct 26, 2016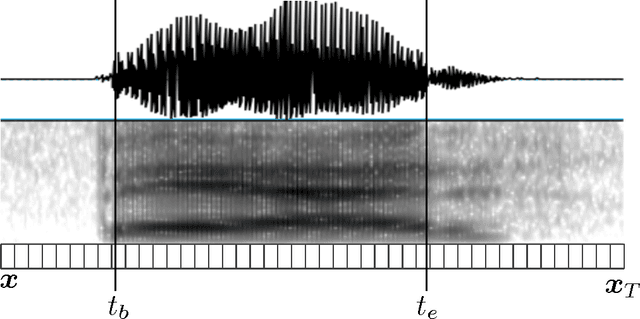
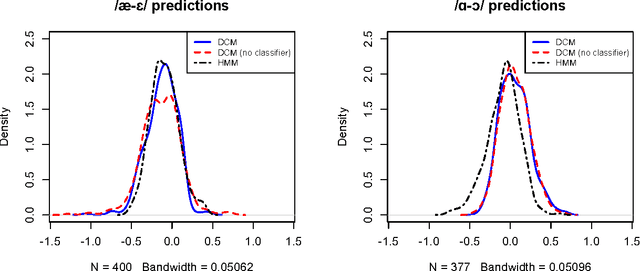

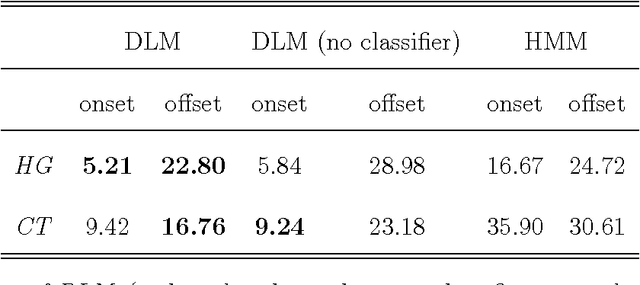
A key barrier to making phonetic studies scalable and replicable is the need to rely on subjective, manual annotation. To help meet this challenge, a machine learning algorithm was developed for automatic measurement of a widely used phonetic measure: vowel duration. Manually-annotated data were used to train a model that takes as input an arbitrary length segment of the acoustic signal containing a single vowel that is preceded and followed by consonants and outputs the duration of the vowel. The model is based on the structured prediction framework. The input signal and a hypothesized set of a vowel's onset and offset are mapped to an abstract vector space by a set of acoustic feature functions. The learning algorithm is trained in this space to minimize the difference in expectations between predicted and manually-measured vowel durations. The trained model can then automatically estimate vowel durations without phonetic or orthographic transcription. Results comparing the model to three sets of manually annotated data suggest it out-performed the current gold standard for duration measurement, an HMM-based forced aligner (which requires orthographic or phonetic transcription as an input).
Sequence Segmentation Using Joint RNN and Structured Prediction Models
Oct 25, 2016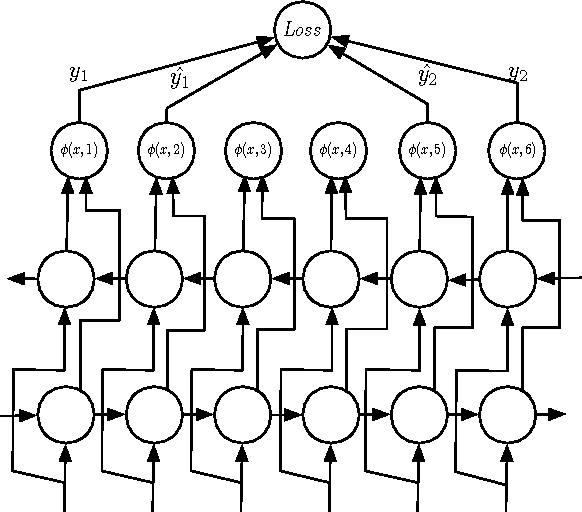
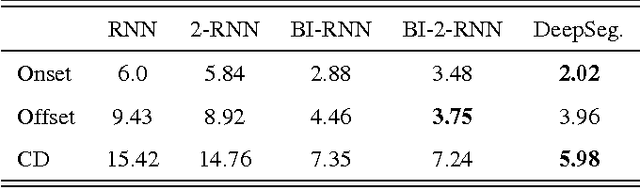
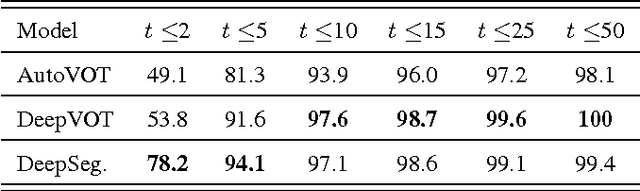
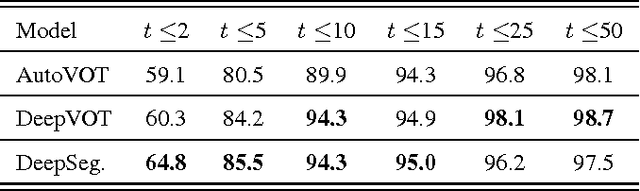
We describe and analyze a simple and effective algorithm for sequence segmentation applied to speech processing tasks. We propose a neural architecture that is composed of two modules trained jointly: a recurrent neural network (RNN) module and a structured prediction model. The RNN outputs are considered as feature functions to the structured model. The overall model is trained with a structured loss function which can be designed to the given segmentation task. We demonstrate the effectiveness of our method by applying it to two simple tasks commonly used in phonetic studies: word segmentation and voice onset time segmentation. Results sug- gest the proposed model is superior to previous methods, ob- taining state-of-the-art results on the tested datasets.