 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoom Layout Estimation
Room-layout estimation is the process of estimating the layout of a room from images or videos.
Papers and Code
SceneSmith: Agentic Generation of Simulation-Ready Indoor Scenes
Feb 09, 2026Simulation has become a key tool for training and evaluating home robots at scale, yet existing environments fail to capture the diversity and physical complexity of real indoor spaces. Current scene synthesis methods produce sparsely furnished rooms that lack the dense clutter, articulated furniture, and physical properties essential for robotic manipulation. We introduce SceneSmith, a hierarchical agentic framework that generates simulation-ready indoor environments from natural language prompts. SceneSmith constructs scenes through successive stages$\unicode{x2013}$from architectural layout to furniture placement to small object population$\unicode{x2013}$each implemented as an interaction among VLM agents: designer, critic, and orchestrator. The framework tightly integrates asset generation through text-to-3D synthesis for static objects, dataset retrieval for articulated objects, and physical property estimation. SceneSmith generates 3-6x more objects than prior methods, with <2% inter-object collisions and 96% of objects remaining stable under physics simulation. In a user study with 205 participants, it achieves 92% average realism and 91% average prompt faithfulness win rates against baselines. We further demonstrate that these environments can be used in an end-to-end pipeline for automatic robot policy evaluation.
A Modular Framework for Single-View 3D Reconstruction of Indoor Environments
Dec 17, 2025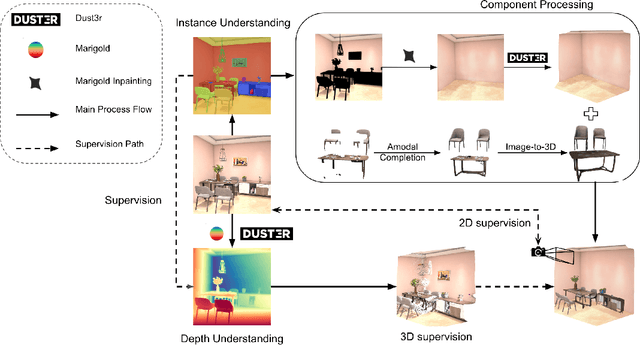

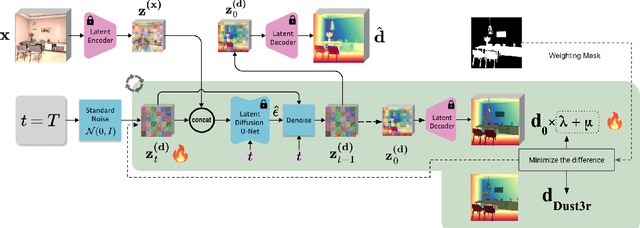
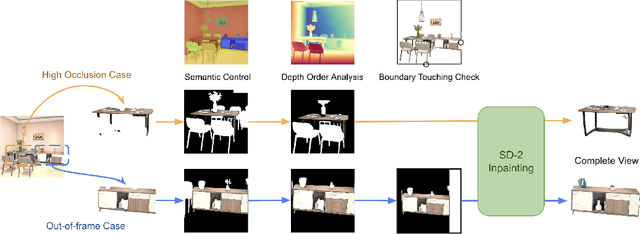
We propose a modular framework for single-view indoor scene 3D reconstruction, where several core modules are powered by diffusion techniques. Traditional approaches for this task often struggle with the complex instance shapes and occlusions inherent in indoor environments. They frequently overshoot by attempting to predict 3D shapes directly from incomplete 2D images, which results in limited reconstruction quality. We aim to overcome this limitation by splitting the process into two steps: first, we employ diffusion-based techniques to predict the complete views of the room background and occluded indoor instances, then transform them into 3D. Our modular framework makes contributions to this field through the following components: an amodal completion module for restoring the full view of occluded instances, an inpainting model specifically trained to predict room layouts, a hybrid depth estimation technique that balances overall geometric accuracy with fine detail expressiveness, and a view-space alignment method that exploits both 2D and 3D cues to ensure precise placement of instances within the scene. This approach effectively reconstructs both foreground instances and the room background from a single image. Extensive experiments on the 3D-Front dataset demonstrate that our method outperforms current state-of-the-art (SOTA) approaches in terms of both visual quality and reconstruction accuracy. The framework holds promising potential for applications in interior design, real estate, and augmented reality.
An End-to-End Room Geometry Constrained Depth Estimation Framework for Indoor Panorama Images
Oct 09, 2025Predicting spherical pixel depth from monocular $360^{\circ}$ indoor panoramas is critical for many vision applications. However, existing methods focus on pixel-level accuracy, causing oversmoothed room corners and noise sensitivity. In this paper, we propose a depth estimation framework based on room geometry constraints, which extracts room geometry information through layout prediction and integrates those information into the depth estimation process through background segmentation mechanism. At the model level, our framework comprises a shared feature encoder followed by task-specific decoders for layout estimation, depth estimation, and background segmentation. The shared encoder extracts multi-scale features, which are subsequently processed by individual decoders to generate initial predictions: a depth map, a room layout map, and a background segmentation map. Furthermore, our framework incorporates two strategies: a room geometry-based background depth resolving strategy and a background-segmentation-guided fusion mechanism. The proposed room-geometry-based background depth resolving strategy leverages the room layout and the depth decoder's output to generate the corresponding background depth map. Then, a background-segmentation-guided fusion strategy derives fusion weights for the background and coarse depth maps from the segmentation decoder's predictions. Extensive experimental results on the Stanford2D3D, Matterport3D and Structured3D datasets show that our proposed methods can achieve significantly superior performance than current open-source methods. Our code is available at https://github.com/emiyaning/RGCNet.
Room Envelopes: A Synthetic Dataset for Indoor Layout Reconstruction from Images
Nov 06, 2025Modern scene reconstruction methods are able to accurately recover 3D surfaces that are visible in one or more images. However, this leads to incomplete reconstructions, missing all occluded surfaces. While much progress has been made on reconstructing entire objects given partial observations using generative models, the structural elements of a scene, like the walls, floors and ceilings, have received less attention. We argue that these scene elements should be relatively easy to predict, since they are typically planar, repetitive and simple, and so less costly approaches may be suitable. In this work, we present a synthetic dataset -- Room Envelopes -- that facilitates progress on this task by providing a set of RGB images and two associated pointmaps for each image: one capturing the visible surface and one capturing the first surface once fittings and fixtures are removed, that is, the structural layout. As we show, this enables direct supervision for feed-forward monocular geometry estimators that predict both the first visible surface and the first layout surface. This confers an understanding of the scene's extent, as well as the shape and location of its objects.
PixCuboid: Room Layout Estimation from Multi-view Featuremetric Alignment
Aug 06, 2025
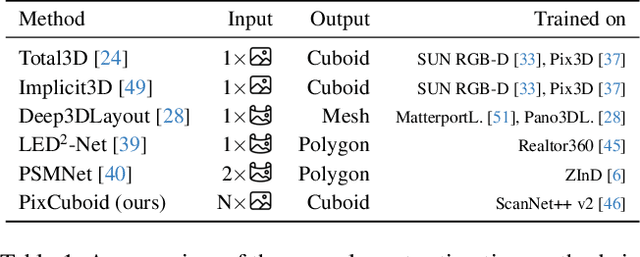
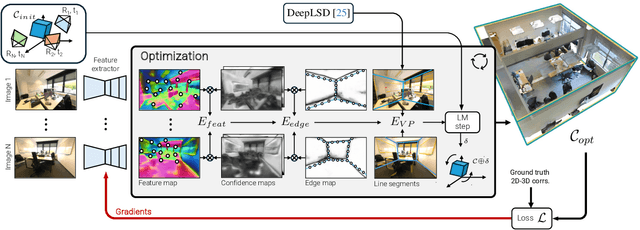
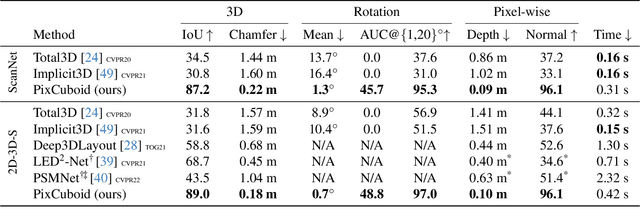
Coarse room layout estimation provides important geometric cues for many downstream tasks. Current state-of-the-art methods are predominantly based on single views and often assume panoramic images. We introduce PixCuboid, an optimization-based approach for cuboid-shaped room layout estimation, which is based on multi-view alignment of dense deep features. By training with the optimization end-to-end, we learn feature maps that yield large convergence basins and smooth loss landscapes in the alignment. This allows us to initialize the room layout using simple heuristics. For the evaluation we propose two new benchmarks based on ScanNet++ and 2D-3D-Semantics, with manually verified ground truth 3D cuboids. In thorough experiments we validate our approach and significantly outperform the competition. Finally, while our network is trained with single cuboids, the flexibility of the optimization-based approach allow us to easily extend to multi-room estimation, e.g. larger apartments or offices. Code and model weights are available at https://github.com/ghanning/PixCuboid.
uLayout: Unified Room Layout Estimation for Perspective and Panoramic Images
Mar 27, 2025We present uLayout, a unified model for estimating room layout geometries from both perspective and panoramic images, whereas traditional solutions require different model designs for each image type. The key idea of our solution is to unify both domains into the equirectangular projection, particularly, allocating perspective images into the most suitable latitude coordinate to effectively exploit both domains seamlessly. To address the Field-of-View (FoV) difference between the input domains, we design uLayout with a shared feature extractor with an extra 1D-Convolution layer to condition each domain input differently. This conditioning allows us to efficiently formulate a column-wise feature regression problem regardless of the FoV input. This simple yet effective approach achieves competitive performance with current state-of-the-art solutions and shows for the first time a single end-to-end model for both domains. Extensive experiments in the real-world datasets, LSUN, Matterport3D, PanoContext, and Stanford 2D-3D evidence the contribution of our approach. Code is available at https://github.com/JonathanLee112/uLayout.
Unposed Sparse Views Room Layout Reconstruction in the Age of Pretrain Model
Feb 24, 2025Room layout estimation from multiple-perspective images is poorly investigated due to the complexities that emerge from multi-view geometry, which requires muti-step solutions such as camera intrinsic and extrinsic estimation, image matching, and triangulation. However, in 3D reconstruction, the advancement of recent 3D foundation models such as DUSt3R has shifted the paradigm from the traditional multi-step structure-from-motion process to an end-to-end single-step approach. To this end, we introduce Plane-DUSt3R}, a novel method for multi-view room layout estimation leveraging the 3D foundation model DUSt3R. Plane-DUSt3R incorporates the DUSt3R framework and fine-tunes on a room layout dataset (Structure3D) with a modified objective to estimate structural planes. By generating uniform and parsimonious results, Plane-DUSt3R enables room layout estimation with only a single post-processing step and 2D detection results. Unlike previous methods that rely on single-perspective or panorama image, Plane-DUSt3R extends the setting to handle multiple-perspective images. Moreover, it offers a streamlined, end-to-end solution that simplifies the process and reduces error accumulation. Experimental results demonstrate that Plane-DUSt3R not only outperforms state-of-the-art methods on the synthetic dataset but also proves robust and effective on in the wild data with different image styles such as cartoon.
SpatialLM: Training Large Language Models for Structured Indoor Modeling
Jun 09, 2025



SpatialLM is a large language model designed to process 3D point cloud data and generate structured 3D scene understanding outputs. These outputs include architectural elements like walls, doors, windows, and oriented object boxes with their semantic categories. Unlike previous methods which exploit task-specific network designs, our model adheres to the standard multimodal LLM architecture and is fine-tuned directly from open-source LLMs. To train SpatialLM, we collect a large-scale, high-quality synthetic dataset consisting of the point clouds of 12,328 indoor scenes (54,778 rooms) with ground-truth 3D annotations, and conduct a careful study on various modeling and training decisions. On public benchmarks, our model gives state-of-the-art performance in layout estimation and competitive results in 3D object detection. With that, we show a feasible path for enhancing the spatial understanding capabilities of modern LLMs for applications in augmented reality, embodied robotics, and more.
Indoor Light and Heat Estimation from a Single Panorama
Feb 10, 2025
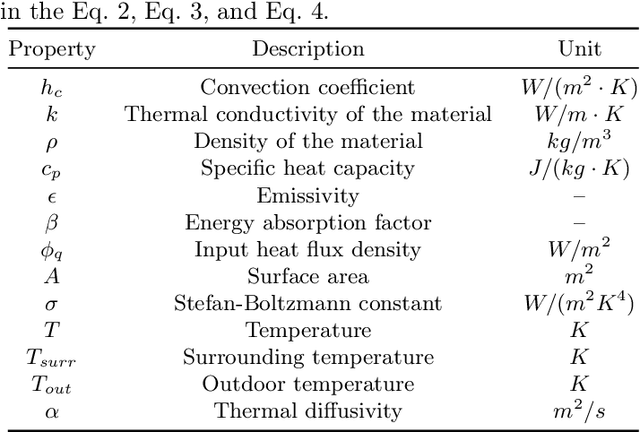
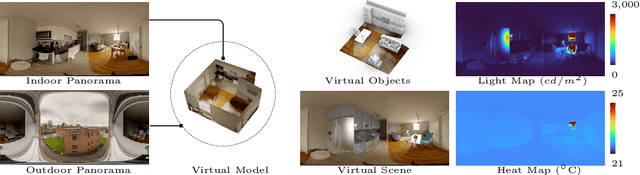

This paper presents a novel application for directly estimating indoor light and heat maps from captured indoor-outdoor High Dynamic Range (HDR) panoramas. In our image-based rendering method, the indoor panorama is used to estimate the 3D room layout, while the corresponding outdoor panorama serves as an environment map to infer spatially-varying light and material properties. We establish a connection between indoor light transport and heat transport and implement transient heat simulation to generate indoor heat panoramas. The sensitivity analysis of various thermal parameters is conducted, and the resulting heat maps are compared with the images captured by the thermal camera in real-world scenarios. This digital application enables automatic indoor light and heat estimation without manual inputs and cumbersome field measurements.
Self-training Room Layout Estimation via Geometry-aware Ray-casting
Jul 21, 2024



In this paper, we introduce a novel geometry-aware self-training framework for room layout estimation models on unseen scenes with unlabeled data. Our approach utilizes a ray-casting formulation to aggregate multiple estimates from different viewing positions, enabling the computation of reliable pseudo-labels for self-training. In particular, our ray-casting approach enforces multi-view consistency along all ray directions and prioritizes spatial proximity to the camera view for geometry reasoning. As a result, our geometry-aware pseudo-labels effectively handle complex room geometries and occluded walls without relying on assumptions such as Manhattan World or planar room walls. Evaluation on publicly available datasets, including synthetic and real-world scenarios, demonstrates significant improvements in current state-of-the-art layout models without using any human annotation.