 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePixCuboid: Room Layout Estimation from Multi-view Featuremetric Alignment
Aug 06, 2025
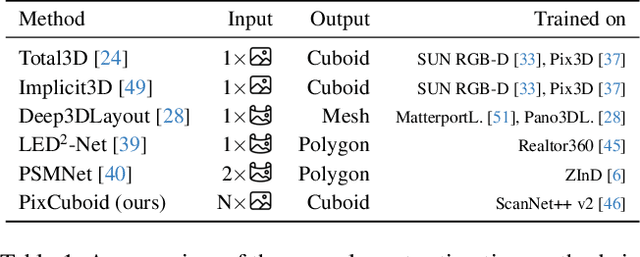
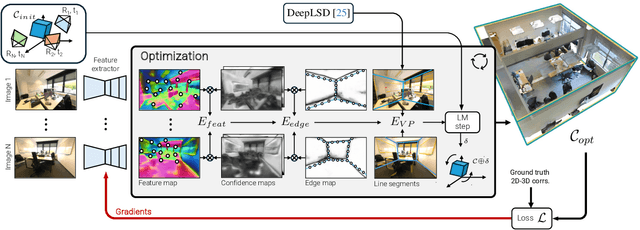
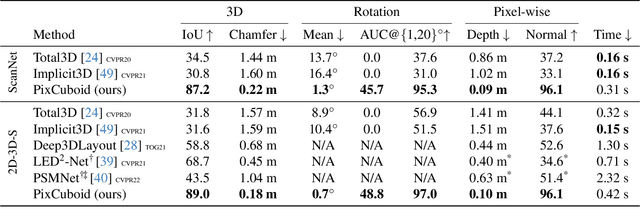
Coarse room layout estimation provides important geometric cues for many downstream tasks. Current state-of-the-art methods are predominantly based on single views and often assume panoramic images. We introduce PixCuboid, an optimization-based approach for cuboid-shaped room layout estimation, which is based on multi-view alignment of dense deep features. By training with the optimization end-to-end, we learn feature maps that yield large convergence basins and smooth loss landscapes in the alignment. This allows us to initialize the room layout using simple heuristics. For the evaluation we propose two new benchmarks based on ScanNet++ and 2D-3D-Semantics, with manually verified ground truth 3D cuboids. In thorough experiments we validate our approach and significantly outperform the competition. Finally, while our network is trained with single cuboids, the flexibility of the optimization-based approach allow us to easily extend to multi-room estimation, e.g. larger apartments or offices. Code and model weights are available at https://github.com/ghanning/PixCuboid.
Visual Re-Ranking with Non-Visual Side Information
Apr 15, 2025The standard approach for visual place recognition is to use global image descriptors to retrieve the most similar database images for a given query image. The results can then be further improved with re-ranking methods that re-order the top scoring images. However, existing methods focus on re-ranking based on the same image descriptors that were used for the initial retrieval, which we argue provides limited additional signal. In this work we propose Generalized Contextual Similarity Aggregation (GCSA), which is a graph neural network-based re-ranking method that, in addition to the visual descriptors, can leverage other types of available side information. This can for example be other sensor data (such as signal strength of nearby WiFi or BlueTooth endpoints) or geometric properties such as camera poses for database images. In many applications this information is already present or can be acquired with low effort. Our architecture leverages the concept of affinity vectors to allow for a shared encoding of the heterogeneous multi-modal input. Two large-scale datasets, covering both outdoor and indoor localization scenarios, are utilized for training and evaluation. In experiments we show significant improvement not only on image retrieval metrics, but also for the downstream visual localization task.