 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePp YOLO
Papers and Code
Video text tracking for dense and small text based on pp-yoloe-r and sort algorithm
Mar 31, 2023


Although end-to-end video text spotting methods based on Transformer can model long-range dependencies and simplify the train process, it will lead to large computation cost with the increase of the frame size in the input video. Therefore, considering the resolution of ICDAR 2023 DSText is 1080 * 1920 and slicing the video frame into several areas will destroy the spatial correlation of text, we divided the small and dense text spotting into two tasks, text detection and tracking. For text detection, we adopt the PP-YOLOE-R which is proven effective in small object detection as our detection model. For text detection, we use the sort algorithm for high inference speed. Experiments on DSText dataset demonstrate that our method is competitive on small and dense text spotting.
PP-YOLOE-R: An Efficient Anchor-Free Rotated Object Detector
Nov 04, 2022



Arbitrary-oriented object detection is a fundamental task in visual scenes involving aerial images and scene text. In this report, we present PP-YOLOE-R, an efficient anchor-free rotated object detector based on PP-YOLOE. We introduce a bag of useful tricks in PP-YOLOE-R to improve detection precision with marginal extra parameters and computational cost. As a result, PP-YOLOE-R-l and PP-YOLOE-R-x achieve 78.14 and 78.28 mAP respectively on DOTA 1.0 dataset with single-scale training and testing, which outperform almost all other rotated object detectors. With multi-scale training and testing, PP-YOLOE-R-l and PP-YOLOE-R-x further improve the detection precision to 80.02 and 80.73 mAP. In this case, PP-YOLOE-R-x surpasses all anchor-free methods and demonstrates competitive performance to state-of-the-art anchor-based two-stage models. Further, PP-YOLOE-R is deployment friendly and PP-YOLOE-R-s/m/l/x can reach 69.8/55.1/48.3/37.1 FPS respectively on RTX 2080 Ti with TensorRT and FP16-precision. Source code and pre-trained models are available at https://github.com/PaddlePaddle/PaddleDetection, which is powered by https://github.com/PaddlePaddle/Paddle.
PP-YOLOE: An evolved version of YOLO
Apr 02, 2022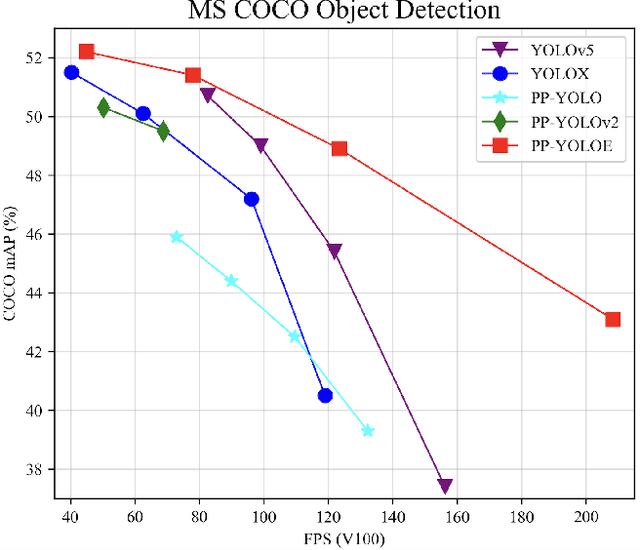

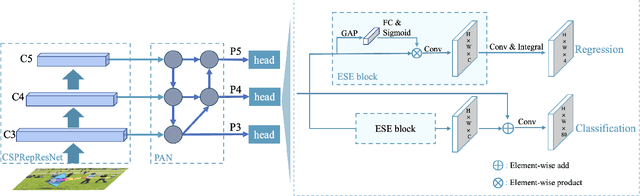

In this report, we present PP-YOLOE, an industrial state-of-the-art object detector with high performance and friendly deployment. We optimize on the basis of the previous PP-YOLOv2, using anchor-free paradigm, more powerful backbone and neck equipped with CSPRepResStage, ET-head and dynamic label assignment algorithm TAL. We provide s/m/l/x models for different practice scenarios. As a result, PP-YOLOE-l achieves 51.4 mAP on COCO test-dev and 78.1 FPS on Tesla V100, yielding a remarkable improvement of (+1.9 AP, +13.35% speed up) and (+1.3 AP, +24.96% speed up), compared to the previous state-of-the-art industrial models PP-YOLOv2 and YOLOX respectively. Further, PP-YOLOE inference speed achieves 149.2 FPS with TensorRT and FP16-precision. We also conduct extensive experiments to verify the effectiveness of our designs. Source code and pre-trained models are available at https://github.com/PaddlePaddle/PaddleDetection.
In Defense of Kalman Filtering for Polyp Tracking from Colonoscopy Videos
Jan 27, 2022
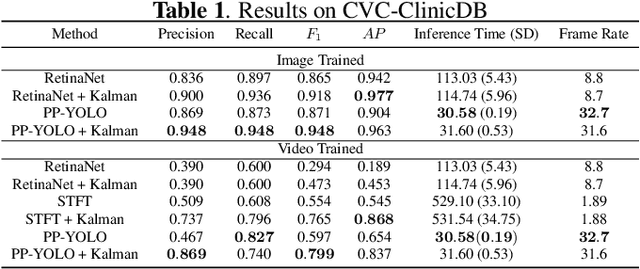
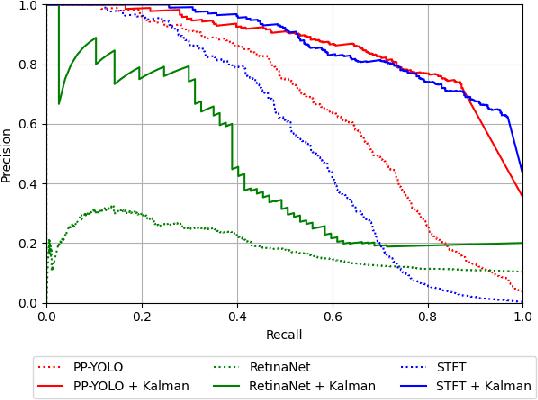
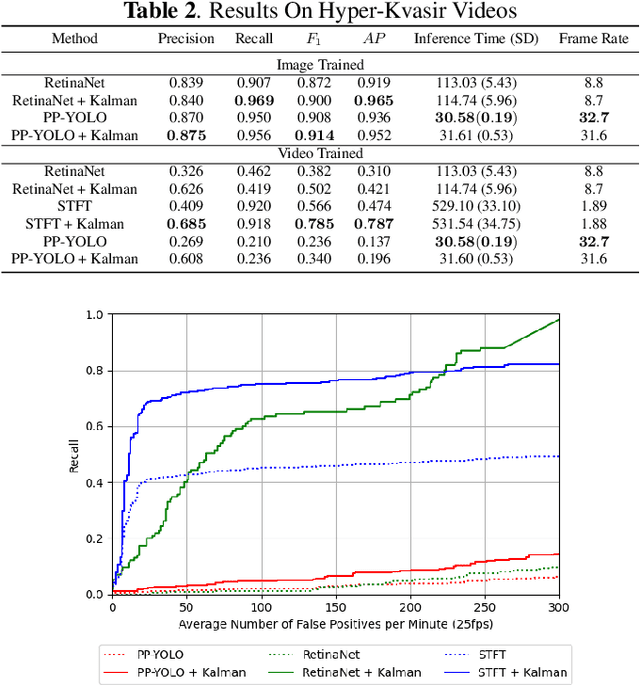
Real-time and robust automatic detection of polyps from colonoscopy videos are essential tasks to help improve the performance of doctors during this exam. The current focus of the field is on the development of accurate but inefficient detectors that will not enable a real-time application. We advocate that the field should instead focus on the development of simple and efficient detectors that an be combined with effective trackers to allow the implementation of real-time polyp detectors. In this paper, we propose a Kalman filtering tracker that can work together with powerful, but efficient detectors, enabling the implementation of real-time polyp detectors. In particular, we show that the combination of our Kalman filtering with the detector PP-YOLO shows state-of-the-art (SOTA) detection accuracy and real-time processing. More specifically, our approach has SOTA results on the CVC-ClinicDB dataset, with a recall of 0.740, precision of 0.869, $F_1$ score of 0.799, an average precision (AP) of 0.837, and can run in real time (i.e., 30 frames per second). We also evaluate our method on a subset of the Hyper-Kvasir annotated by our clinical collaborators, resulting in SOTA results, with a recall of 0.956, precision of 0.875, $F_1$ score of 0.914, AP of 0.952, and can run in real time.
PP-YOLOv2: A Practical Object Detector
Apr 21, 2021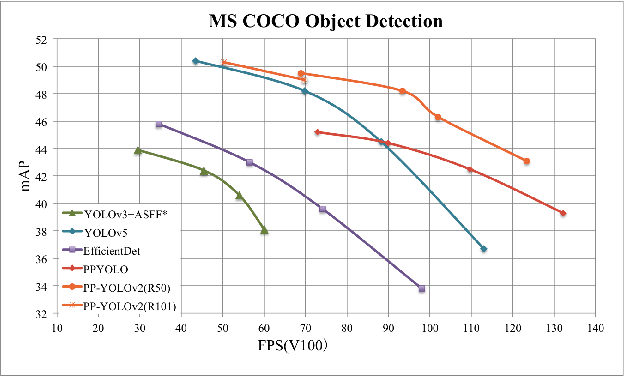

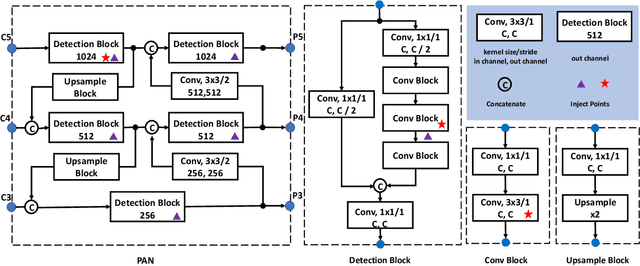
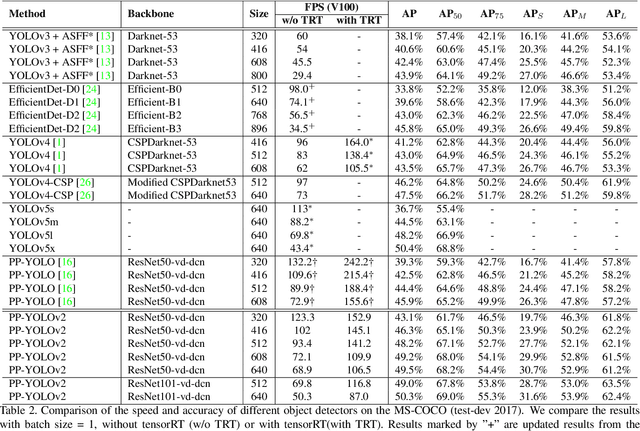
Being effective and efficient is essential to an object detector for practical use. To meet these two concerns, we comprehensively evaluate a collection of existing refinements to improve the performance of PP-YOLO while almost keep the infer time unchanged. This paper will analyze a collection of refinements and empirically evaluate their impact on the final model performance through incremental ablation study. Things we tried that didn't work will also be discussed. By combining multiple effective refinements, we boost PP-YOLO's performance from 45.9% mAP to 49.5% mAP on COCO2017 test-dev. Since a significant margin of performance has been made, we present PP-YOLOv2. In terms of speed, PP-YOLOv2 runs in 68.9FPS at 640x640 input size. Paddle inference engine with TensorRT, FP16-precision, and batch size = 1 further improves PP-YOLOv2's infer speed, which achieves 106.5 FPS. Such a performance surpasses existing object detectors with roughly the same amount of parameters (i.e., YOLOv4-CSP, YOLOv5l). Besides, PP-YOLOv2 with ResNet101 achieves 50.3% mAP on COCO2017 test-dev. Source code is at https://github.com/PaddlePaddle/PaddleDetection.
Image-Adaptive YOLO for Object Detection in Adverse Weather Conditions
Dec 15, 2021

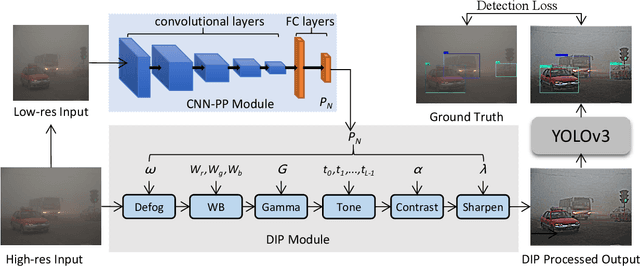
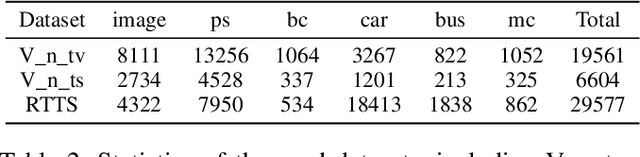
Though deep learning-based object detection methods have achieved promising results on the conventional datasets, it is still challenging to locate objects from the low-quality images captured in adverse weather conditions. The existing methods either have difficulties in balancing the tasks of image enhancement and object detection, or often ignore the latent information beneficial for detection. To alleviate this problem, we propose a novel Image-Adaptive YOLO (IA-YOLO) framework, where each image can be adaptively enhanced for better detection performance. Specifically, a differentiable image processing (DIP) module is presented to take into account the adverse weather conditions for YOLO detector, whose parameters are predicted by a small convolutional neural net-work (CNN-PP). We learn CNN-PP and YOLOv3 jointly in an end-to-end fashion, which ensures that CNN-PP can learn an appropriate DIP to enhance the image for detection in a weakly supervised manner. Our proposed IA-YOLO approach can adaptively process images in both normal and adverse weather conditions. The experimental results are very encouraging, demonstrating the effectiveness of our proposed IA-YOLO method in both foggy and low-light scenarios.
PP-YOLO: An Effective and Efficient Implementation of Object Detector
Aug 03, 2020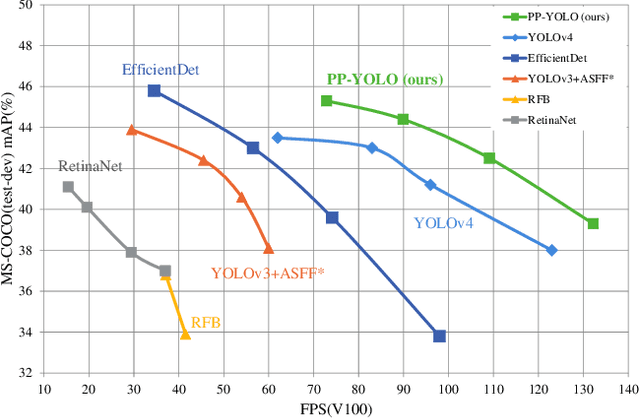
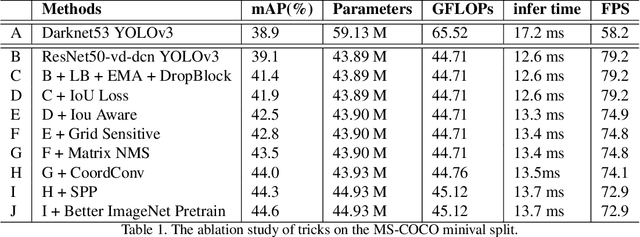
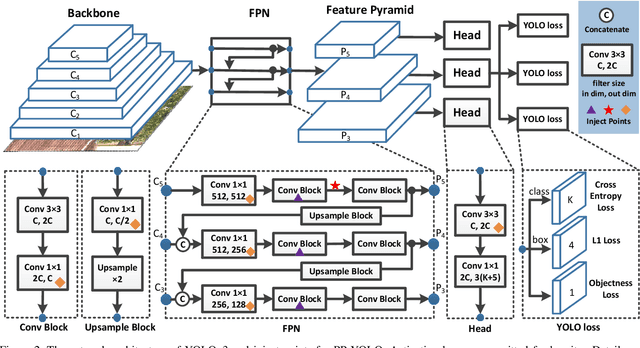
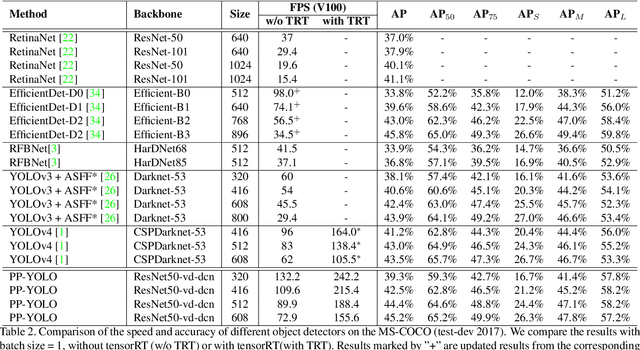
Object detection is one of the most important areas in computer vision, which plays a key role in various practical scenarios. Due to limitation of hardware, it is often necessary to sacrifice accuracy to ensure the infer speed of the detector in practice. Therefore, the balance between effectiveness and efficiency of object detector must be considered. The goal of this paper is to implement an object detector with relatively balanced effectiveness and efficiency that can be directly applied in actual application scenarios, rather than propose a novel detection model. Considering that YOLOv3 has been widely used in practice, we develop a new object detector based on YOLOv3. We mainly try to combine various existing tricks that almost not increase the number of model parameters and FLOPs, to achieve the goal of improving the accuracy of detector as much as possible while ensuring that the speed is almost unchanged. Since all experiments in this paper are conducted based on PaddlePaddle, we call it PP-YOLO. By combining multiple tricks, PP-YOLO can achieve a better balance between effectiveness (45.2% mAP) and efficiency (72.9 FPS), surpassing the existing state-of-the-art detectors such as EfficientDet and YOLOv4.Source code is at https://github.com/PaddlePaddle/PaddleDetection.