 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePanoramic Image Database
Papers and Code
SHREC 2025: Retrieval of Optimal Objects for Multi-modal Enhanced Language and Spatial Assistance (ROOMELSA)
Aug 12, 2025Recent 3D retrieval systems are typically designed for simple, controlled scenarios, such as identifying an object from a cropped image or a brief description. However, real-world scenarios are more complex, often requiring the recognition of an object in a cluttered scene based on a vague, free-form description. To this end, we present ROOMELSA, a new benchmark designed to evaluate a system's ability to interpret natural language. Specifically, ROOMELSA attends to a specific region within a panoramic room image and accurately retrieves the corresponding 3D model from a large database. In addition, ROOMELSA includes over 1,600 apartment scenes, nearly 5,200 rooms, and more than 44,000 targeted queries. Empirically, while coarse object retrieval is largely solved, only one top-performing model consistently ranked the correct match first across nearly all test cases. Notably, a lightweight CLIP-based model also performed well, although it struggled with subtle variations in materials, part structures, and contextual cues, resulting in occasional errors. These findings highlight the importance of tightly integrating visual and language understanding. By bridging the gap between scene-level grounding and fine-grained 3D retrieval, ROOMELSA establishes a new benchmark for advancing robust, real-world 3D recognition systems.
Computational Analysis of Degradation Modeling in Blind Panoramic Image Quality Assessment
Mar 05, 2025



Blind panoramic image quality assessment (BPIQA) has recently brought new challenge to the visual quality community, due to the complex interaction between immersive content and human behavior. Although many efforts have been made to advance BPIQA from both conducting psychophysical experiments and designing performance-driven objective algorithms, \textit{limited content} and \textit{few samples} in those closed sets inevitably would result in shaky conclusions, thereby hindering the development of BPIQA, we refer to it as the \textit{easy-database} issue. In this paper, we present a sufficient computational analysis of degradation modeling in BPIQA to thoroughly explore the \textit{easy-database issue}, where we carefully design three types of experiments via investigating the gap between BPIQA and blind image quality assessment (BIQA), the necessity of specific design in BPIQA models, and the generalization ability of BPIQA models. From extensive experiments, we find that easy databases narrow the gap between the performance of BPIQA and BIQA models, which is unconducive to the development of BPIQA. And the easy databases make the BPIQA models be closed to saturation, therefore the effectiveness of the associated specific designs can not be well verified. Besides, the BPIQA models trained on our recently proposed databases with complicated degradation show better generalization ability. Thus, we believe that much more efforts are highly desired to put into BPIQA from both subjective viewpoint and objective viewpoint.
Cross-Modal Visual Relocalization in Prior LiDAR Maps Utilizing Intensity Textures
Dec 02, 2024



Cross-modal localization has drawn increasing attention in recent years, while the visual relocalization in prior LiDAR maps is less studied. Related methods usually suffer from inconsistency between the 2D texture and 3D geometry, neglecting the intensity features in the LiDAR point cloud. In this paper, we propose a cross-modal visual relocalization system in prior LiDAR maps utilizing intensity textures, which consists of three main modules: map projection, coarse retrieval, and fine relocalization. In the map projection module, we construct the database of intensity channel map images leveraging the dense characteristic of panoramic projection. The coarse retrieval module retrieves the top-K most similar map images to the query image from the database, and retains the top-K' results by covisibility clustering. The fine relocalization module applies a two-stage 2D-3D association and a covisibility inlier selection method to obtain robust correspondences for 6DoF pose estimation. The experimental results on our self-collected datasets demonstrate the effectiveness in both place recognition and pose estimation tasks.
Statewide Visual Geolocalization in the Wild
Sep 25, 2024This work presents a method that is able to predict the geolocation of a street-view photo taken in the wild within a state-sized search region by matching against a database of aerial reference imagery. We partition the search region into geographical cells and train a model to map cells and corresponding photos into a joint embedding space that is used to perform retrieval at test time. The model utilizes aerial images for each cell at multiple levels-of-detail to provide sufficient information about the surrounding scene. We propose a novel layout of the search region with consistent cell resolutions that allows scaling to large geographical regions. Experiments demonstrate that the method successfully localizes 60.6% of all non-panoramic street-view photos uploaded to the crowd-sourcing platform Mapillary in the state of Massachusetts to within 50m of their ground-truth location. Source code is available at https://github.com/fferflo/statewide-visual-geolocalization.
PanoVPR: Towards Unified Perspective-to-Equirectangular Visual Place Recognition via Sliding Windows across the Panoramic View
Mar 24, 2023



Visual place recognition has received increasing attention in recent years as a key technology in autonomous driving and robotics. The current mainstream approaches use either the perspective view retrieval perspective view (P2P) paradigm or the equirectangular image retrieval equirectangular image (E2E) paradigm. However, a natural and practical idea is that users only have consumer-grade pinhole cameras to obtain query perspective images and retrieve them in panoramic database images from map providers. To this end, we propose PanoVPR, a sliding-window-based perspective-to-equirectangular (P2E) visual place recognition framework, which eliminates feature truncation caused by hard cropping by sliding windows over the whole equirectangular image and computing and comparing feature descriptors between windows. In addition, this unified framework allows for directly transferring the network structure used in perspective-to-perspective (P2P) methods without modification. To facilitate training and evaluation, we derive the pitts250k-P2E dataset from the pitts250k and achieve promising results, and we also establish a P2E dataset in a real-world scenario by a mobile robot platform, which we refer to YQ360. Code and datasets will be made available at https://github.com/zafirshi/PanoVPR.
Cross-View Image Sequence Geo-localization
Nov 02, 2022Cross-view geo-localization aims to estimate the GPS location of a query ground-view image by matching it to images from a reference database of geo-tagged aerial images. To address this challenging problem, recent approaches use panoramic ground-view images to increase the range of visibility. Although appealing, panoramic images are not readily available compared to the videos of limited Field-Of-View (FOV) images. In this paper, we present the first cross-view geo-localization method that works on a sequence of limited FOV images. Our model is trained end-to-end to capture the temporal structure that lies within the frames using the attention-based temporal feature aggregation module. To robustly tackle different sequences length and GPS noises during inference, we propose to use a sequential dropout scheme to simulate variant length sequences. To evaluate the proposed approach in realistic settings, we present a new large-scale dataset containing ground-view sequences along with the corresponding aerial-view images. Extensive experiments and comparisons demonstrate the superiority of the proposed approach compared to several competitive baselines.
Semantic Pose Verification for Outdoor Visual Localization with Self-supervised Contrastive Learning
Mar 31, 2022
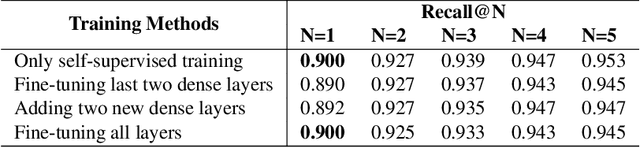
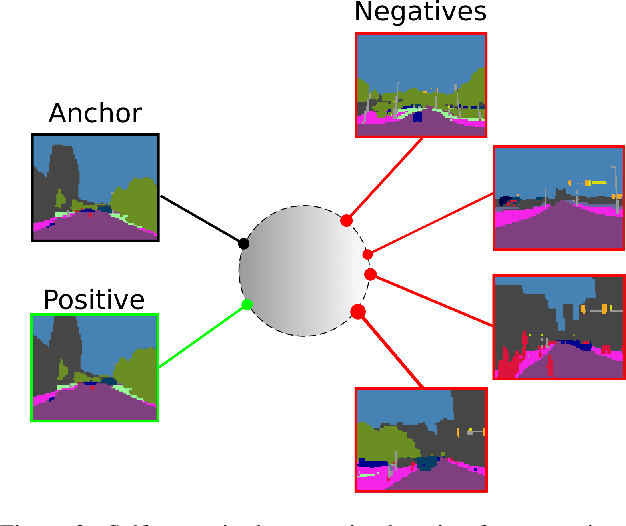
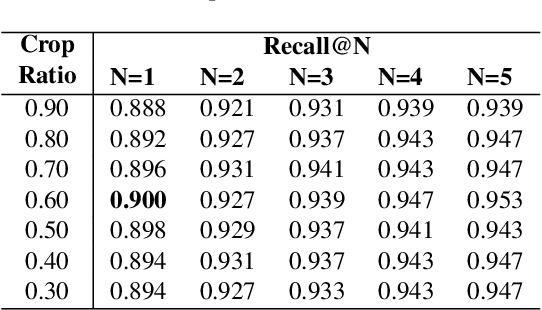
Any city-scale visual localization system has to overcome long-term appearance changes, such as varying illumination conditions or seasonal changes between query and database images. Since semantic content is more robust to such changes, we exploit semantic information to improve visual localization. In our scenario, the database consists of gnomonic views generated from panoramic images (e.g. Google Street View) and query images are collected with a standard field-of-view camera at a different time. To improve localization, we check the semantic similarity between query and database images, which is not trivial since the position and viewpoint of the cameras do not exactly match. To learn similarity, we propose training a CNN in a self-supervised fashion with contrastive learning on a dataset of semantically segmented images. With experiments we showed that this semantic similarity estimation approach works better than measuring the similarity at pixel-level. Finally, we used the semantic similarity scores to verify the retrievals obtained by a state-of-the-art visual localization method and observed that contrastive learning-based pose verification increases top-1 recall value to 0.90 which corresponds to a 2% improvement.
Self-Supervised Endoscopic Image Key-Points Matching
Aug 24, 2022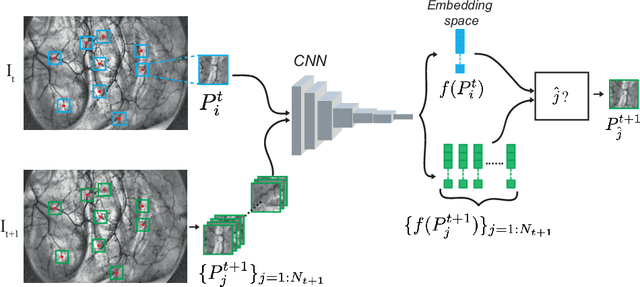
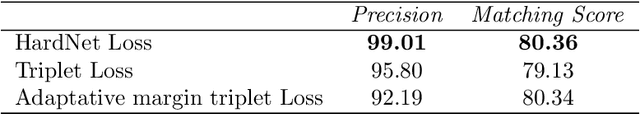
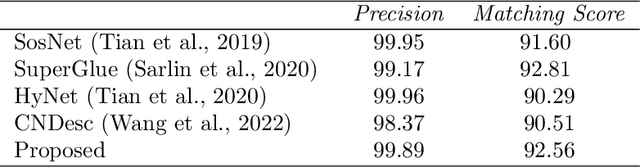
Feature matching and finding correspondences between endoscopic images is a key step in many clinical applications such as patient follow-up and generation of panoramic image from clinical sequences for fast anomalies localization. Nonetheless, due to the high texture variability present in endoscopic images, the development of robust and accurate feature matching becomes a challenging task. Recently, deep learning techniques which deliver learned features extracted via convolutional neural networks (CNNs) have gained traction in a wide range of computer vision tasks. However, they all follow a supervised learning scheme where a large amount of annotated data is required to reach good performances, which is generally not always available for medical data databases. To overcome this limitation related to labeled data scarcity, the self-supervised learning paradigm has recently shown great success in a number of applications. This paper proposes a novel self-supervised approach for endoscopic image matching based on deep learning techniques. When compared to standard hand-crafted local feature descriptors, our method outperformed them in terms of precision and recall. Furthermore, our self-supervised descriptor provides a competitive performance in comparison to a selection of state-of-the-art deep learning based supervised methods in terms of precision and matching score.
Towards Accurate Camera Geopositioning by Image Matching
Mar 13, 2019In this work, we present a camera geopositioning system based on matching a query image against a database with panoramic images. For matching, our system uses memory vectors aggregated from global image descriptors based on convolutional features to facilitate fast searching in the database. To speed up searching, a clustering algorithm is used to balance geographical positioning and computation time. We refine the obtained position from the query image using a new outlier removal algorithm. The matching of the query image is obtained with a recall@5 larger than 90% for panorama-to-panorama matching. We cluster available panoramas from geographically adjacent locations into a single compact representation and observe computational gains of approximately 50% at the cost of only a small (approximately 3%) recall loss. Finally, we present a coordinate estimation algorithm that reduces the median geopositioning error by up to 20%.
Panoramic Annular Localizer: Tackling the Variation Challenges of Outdoor Localization Using Panoramic Annular Images and Active Deep Descriptors
May 14, 2019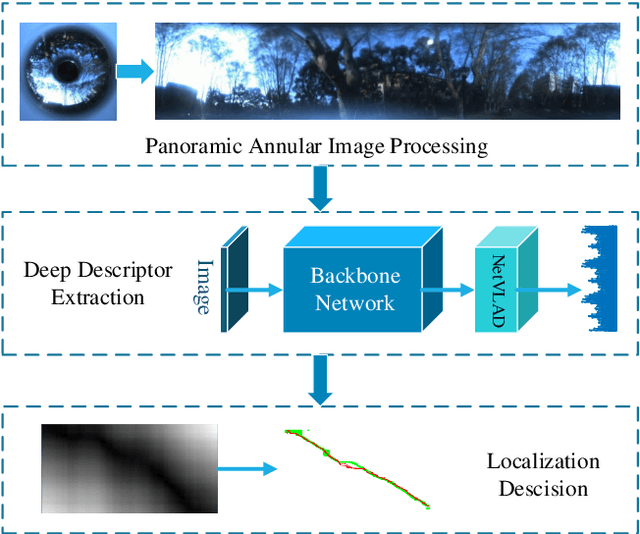
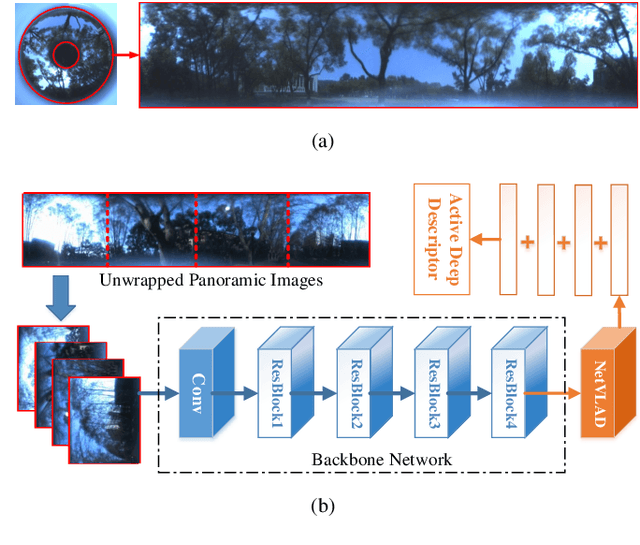
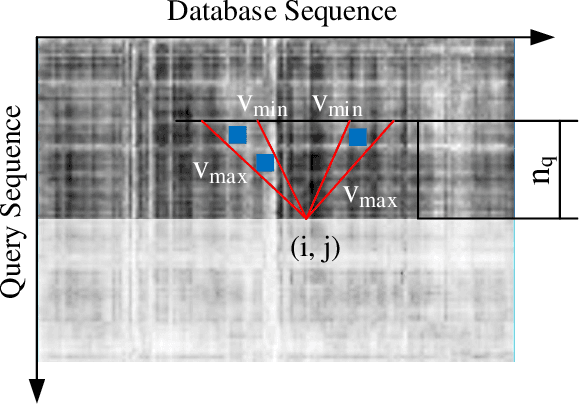
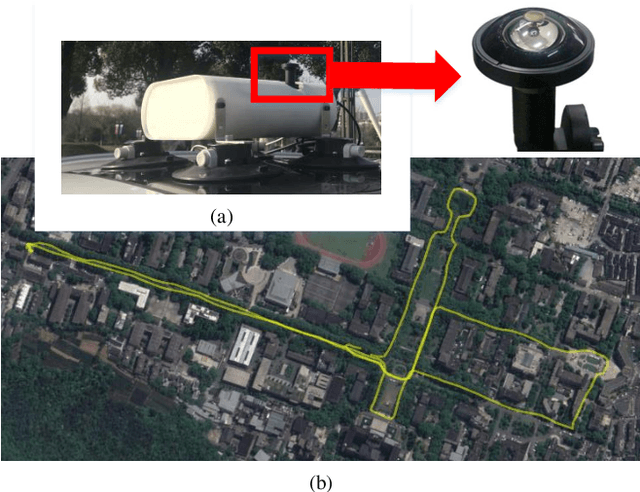
Visual localization is an attractive problem that estimates the camera localization from database images based on the query image. It is a crucial task for various applications, such as autonomous vehicles, assistive navigation and augmented reality. The challenging issues of the task lie in various appearance variations between query and database images, including illumination variations, season variations, dynamic object variations and viewpoint variations. In order to tackle those challenges, Panoramic Annular Localizer into which panoramic annular lens and robust deep image descriptors are incorporated is proposed in this paper. The panoramic annular images captured by the single camera are processed and fed into the NetVLAD network to form the active deep descriptor, and sequential matching is utilized to generate the localization result. The experiments carried on the public datasets and in the field illustrate the validation of the proposed system.