 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMicro Expression Spotting
Papers and Code
MEGC2026: Micro-Expression Grand Challenge on Visual Question Answering
Mar 09, 2026Facial micro-expressions (MEs) are involuntary movements of the face that occur spontaneously when a person experiences an emotion but attempts to suppress or repress the facial expression, typically found in a high-stakes environment. In recent years, substantial advancements have been made in the areas of ME recognition, spotting, and generation. The emergence of multimodal large language models (MLLMs) and large vision-language models (LVLMs) offers promising new avenues for enhancing ME analysis through their powerful multimodal reasoning capabilities. The ME grand challenge (MEGC) 2026 introduces two tasks that reflect these evolving research directions: (1) ME video question answering (ME-VQA), which explores ME understanding through visual question answering on relatively short video sequences, leveraging MLLMs or LVLMs to address diverse question types related to MEs; and (2) ME long-video question answering (ME-LVQA), which extends VQA to long-duration video sequences in realistic settings, requiring models to handle temporal reasoning and subtle micro-expression detection across extended time periods. All participating algorithms are required to submit their results on a public leaderboard. More details are available at https://megc2026.github.io.
MELDAE: A Framework for Micro-Expression Spotting, Detection, and Automatic Evaluation in In-the-Wild Conversational Scenes
Oct 26, 2025Accurately analyzing spontaneous, unconscious micro-expressions is crucial for revealing true human emotions, but this task remains challenging in wild scenarios, such as natural conversation. Existing research largely relies on datasets from controlled laboratory environments, and their performance degrades dramatically in the real world. To address this issue, we propose three contributions: the first micro-expression dataset focused on conversational-in-the-wild scenarios; an end-to-end localization and detection framework, MELDAE; and a novel boundary-aware loss function that improves temporal accuracy by penalizing onset and offset errors. Extensive experiments demonstrate that our framework achieves state-of-the-art results on the WDMD dataset, improving the key F1_{DR} localization metric by 17.72% over the strongest baseline, while also demonstrating excellent generalization capabilities on existing benchmarks.
MEGC2025: Micro-Expression Grand Challenge on Spot Then Recognize and Visual Question Answering
Jun 18, 2025
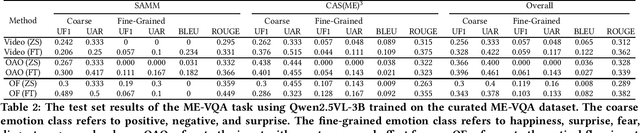
Facial micro-expressions (MEs) are involuntary movements of the face that occur spontaneously when a person experiences an emotion but attempts to suppress or repress the facial expression, typically found in a high-stakes environment. In recent years, substantial advancements have been made in the areas of ME recognition, spotting, and generation. However, conventional approaches that treat spotting and recognition as separate tasks are suboptimal, particularly for analyzing long-duration videos in realistic settings. Concurrently, the emergence of multimodal large language models (MLLMs) and large vision-language models (LVLMs) offers promising new avenues for enhancing ME analysis through their powerful multimodal reasoning capabilities. The ME grand challenge (MEGC) 2025 introduces two tasks that reflect these evolving research directions: (1) ME spot-then-recognize (ME-STR), which integrates ME spotting and subsequent recognition in a unified sequential pipeline; and (2) ME visual question answering (ME-VQA), which explores ME understanding through visual question answering, leveraging MLLMs or LVLMs to address diverse question types related to MEs. All participating algorithms are required to run on this test set and submit their results on a leaderboard. More details are available at https://megc2025.github.io.
ME-TST+: Micro-expression Analysis via Temporal State Transition with ROI Relationship Awareness
Aug 11, 2025Micro-expressions (MEs) are regarded as important indicators of an individual's intrinsic emotions, preferences, and tendencies. ME analysis requires spotting of ME intervals within long video sequences and recognition of their corresponding emotional categories. Previous deep learning approaches commonly employ sliding-window classification networks. However, the use of fixed window lengths and hard classification presents notable limitations in practice. Furthermore, these methods typically treat ME spotting and recognition as two separate tasks, overlooking the essential relationship between them. To address these challenges, this paper proposes two state space model-based architectures, namely ME-TST and ME-TST+, which utilize temporal state transition mechanisms to replace conventional window-level classification with video-level regression. This enables a more precise characterization of the temporal dynamics of MEs and supports the modeling of MEs with varying durations. In ME-TST+, we further introduce multi-granularity ROI modeling and the slowfast Mamba framework to alleviate information loss associated with treating ME analysis as a time-series task. Additionally, we propose a synergy strategy for spotting and recognition at both the feature and result levels, leveraging their intrinsic connection to enhance overall analysis performance. Extensive experiments demonstrate that the proposed methods achieve state-of-the-art performance. The codes are available at https://github.com/zizheng-guo/ME-TST.
Boosting Micro-Expression Analysis via Prior-Guided Video-Level Regression
Aug 26, 2025Micro-expressions (MEs) are involuntary, low-intensity, and short-duration facial expressions that often reveal an individual's genuine thoughts and emotions. Most existing ME analysis methods rely on window-level classification with fixed window sizes and hard decisions, which limits their ability to capture the complex temporal dynamics of MEs. Although recent approaches have adopted video-level regression frameworks to address some of these challenges, interval decoding still depends on manually predefined, window-based methods, leaving the issue only partially mitigated. In this paper, we propose a prior-guided video-level regression method for ME analysis. We introduce a scalable interval selection strategy that comprehensively considers the temporal evolution, duration, and class distribution characteristics of MEs, enabling precise spotting of the onset, apex, and offset phases. In addition, we introduce a synergistic optimization framework, in which the spotting and recognition tasks share parameters except for the classification heads. This fully exploits complementary information, makes more efficient use of limited data, and enhances the model's capability. Extensive experiments on multiple benchmark datasets demonstrate the state-of-the-art performance of our method, with an STRS of 0.0562 on CAS(ME)$^3$ and 0.2000 on SAMMLV. The code is available at https://github.com/zizheng-guo/BoostingVRME.
Causal-Ex: Causal Graph-based Micro and Macro Expression Spotting
Mar 12, 2025



Detecting concealed emotions within apparently normal expressions is crucial for identifying potential mental health issues and facilitating timely support and intervention. The task of spotting macro and micro-expressions involves predicting the emotional timeline within a video, accomplished by identifying the onset, apex, and offset frames of the displayed emotions. Utilizing foundational facial muscle movement cues, known as facial action units, boosts the accuracy. However, an overlooked challenge from previous research lies in the inadvertent integration of biases into the training model. These biases arising from datasets can spuriously link certain action unit movements to particular emotion classes. We tackle this issue by novel replacement of action unit adjacency information with the action unit causal graphs. This approach aims to identify and eliminate undesired spurious connections, retaining only unbiased information for classification. Our model, named Causal-Ex (Causal-based Expression spotting), employs a rapid causal inference algorithm to construct a causal graph of facial action units. This enables us to select causally relevant facial action units. Our work demonstrates improvement in overall F1-scores compared to state-of-the-art approaches with 0.388 on CAS(ME)^2 and 0.3701 on SAMM-Long Video datasets.
CMED: A Child Micro-Expression Dataset
Mar 27, 2025Micro-expressions are short bursts of emotion that are difficult to hide. Their detection in children is an important cue to assist psychotherapists in conducting better therapy. However, existing research on the detection of micro-expressions has focused on adults, whose expressions differ in their characteristics from those of children. The lack of research is a direct consequence of the lack of a child-based micro-expressions dataset as it is much more challenging to capture children's facial expressions due to the lack of predictability and controllability. This study compiles a dataset of spontaneous child micro-expression videos, the first of its kind, to the best of the authors knowledge. The dataset is captured in the wild using video conferencing software. This dataset enables us to then explore key features and differences between adult and child micro-expressions. This study also establishes a baseline for the automated spotting and recognition of micro-expressions in children using three approaches comprising of hand-created and learning-based approaches.
MMME: A Spontaneous Multi-Modal Micro-Expression Dataset Enabling Visual-Physiological Fusion
Jun 12, 2025Micro-expressions (MEs) are subtle, fleeting nonverbal cues that reveal an individual's genuine emotional state. Their analysis has attracted considerable interest due to its promising applications in fields such as healthcare, criminal investigation, and human-computer interaction. However, existing ME research is limited to single visual modality, overlooking the rich emotional information conveyed by other physiological modalities, resulting in ME recognition and spotting performance far below practical application needs. Therefore, exploring the cross-modal association mechanism between ME visual features and physiological signals (PS), and developing a multimodal fusion framework, represents a pivotal step toward advancing ME analysis. This study introduces a novel ME dataset, MMME, which, for the first time, enables synchronized collection of facial action signals (MEs), central nervous system signals (EEG), and peripheral PS (PPG, RSP, SKT, EDA, and ECG). By overcoming the constraints of existing ME corpora, MMME comprises 634 MEs, 2,841 macro-expressions (MaEs), and 2,890 trials of synchronized multimodal PS, establishing a robust foundation for investigating ME neural mechanisms and conducting multimodal fusion-based analyses. Extensive experiments validate the dataset's reliability and provide benchmarks for ME analysis, demonstrating that integrating MEs with PS significantly enhances recognition and spotting performance. To the best of our knowledge, MMME is the most comprehensive ME dataset to date in terms of modality diversity. It provides critical data support for exploring the neural mechanisms of MEs and uncovering the visual-physiological synergistic effects, driving a paradigm shift in ME research from single-modality visual analysis to multimodal fusion. The dataset will be publicly available upon acceptance of this paper.
PESFormer: Boosting Macro- and Micro-expression Spotting with Direct Timestamp Encoding
Oct 24, 2024



The task of macro- and micro-expression spotting aims to precisely localize and categorize temporal expression instances within untrimmed videos. Given the sparse distribution and varying durations of expressions, existing anchor-based methods often represent instances by encoding their deviations from predefined anchors. Additionally, these methods typically slice the untrimmed videos into fixed-length sliding windows. However, anchor-based encoding often fails to capture all training intervals, and slicing the original video as sliding windows can result in valuable training intervals being discarded. To overcome these limitations, we introduce PESFormer, a simple yet effective model based on the vision transformer architecture to achieve point-to-interval expression spotting. PESFormer employs a direct timestamp encoding (DTE) approach to replace anchors, enabling binary classification of each timestamp instead of optimizing entire ground truths. Thus, all training intervals are retained in the form of discrete timestamps. To maximize the utilization of training intervals, we enhance the preprocessing process by replacing the short videos produced through the sliding window method.Instead, we implement a strategy that involves zero-padding the untrimmed training videos to create uniform, longer videos of a predetermined duration. This operation efficiently preserves the original training intervals and eliminates video slice enhancement.Extensive qualitative and quantitative evaluations on three datasets -- CAS(ME)^2, CAS(ME)^3 and SAMM-LV -- demonstrate that our PESFormer outperforms existing techniques, achieving the best performance.
Synergistic Spotting and Recognition of Micro-Expression via Temporal State Transition
Sep 15, 2024



Micro-expressions are involuntary facial movements that cannot be consciously controlled, conveying subtle cues with substantial real-world applications. The analysis of micro-expressions generally involves two main tasks: spotting micro-expression intervals in long videos and recognizing the emotions associated with these intervals. Previous deep learning methods have primarily relied on classification networks utilizing sliding windows. However, fixed window sizes and window-level hard classification introduce numerous constraints. Additionally, these methods have not fully exploited the potential of complementary pathways for spotting and recognition. In this paper, we present a novel temporal state transition architecture grounded in the state space model, which replaces conventional window-level classification with video-level regression. Furthermore, by leveraging the inherent connections between spotting and recognition tasks, we propose a synergistic strategy that enhances overall analysis performance. Extensive experiments demonstrate that our method achieves state-of-the-art performance. The codes and pre-trained models are available at https://github.com/zizheng-guo/ME-TST.