 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvances in Automated Fetal Brain MRI Segmentation and Biometry: Insights from the FeTA 2024 Challenge
May 05, 2025


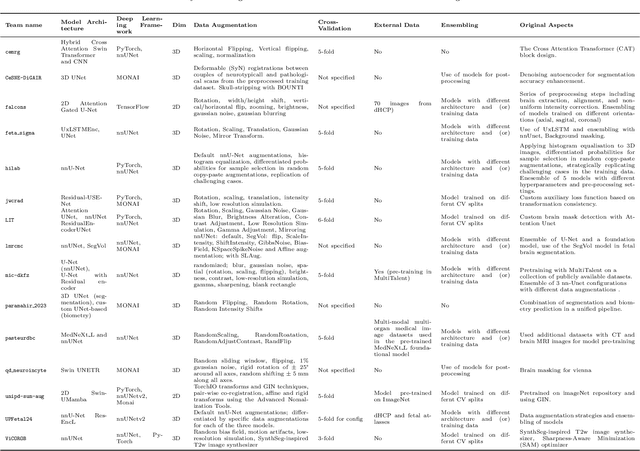
Accurate fetal brain tissue segmentation and biometric analysis are essential for studying brain development in utero. The FeTA Challenge 2024 advanced automated fetal brain MRI analysis by introducing biometry prediction as a new task alongside tissue segmentation. For the first time, our diverse multi-centric test set included data from a new low-field (0.55T) MRI dataset. Evaluation metrics were also expanded to include the topology-specific Euler characteristic difference (ED). Sixteen teams submitted segmentation methods, most of which performed consistently across both high- and low-field scans. However, longitudinal trends indicate that segmentation accuracy may be reaching a plateau, with results now approaching inter-rater variability. The ED metric uncovered topological differences that were missed by conventional metrics, while the low-field dataset achieved the highest segmentation scores, highlighting the potential of affordable imaging systems when paired with high-quality reconstruction. Seven teams participated in the biometry task, but most methods failed to outperform a simple baseline that predicted measurements based solely on gestational age, underscoring the challenge of extracting reliable biometric estimates from image data alone. Domain shift analysis identified image quality as the most significant factor affecting model generalization, with super-resolution pipelines also playing a substantial role. Other factors, such as gestational age, pathology, and acquisition site, had smaller, though still measurable, effects. Overall, FeTA 2024 offers a comprehensive benchmark for multi-class segmentation and biometry estimation in fetal brain MRI, underscoring the need for data-centric approaches, improved topological evaluation, and greater dataset diversity to enable clinically robust and generalizable AI tools.
PESFormer: Boosting Macro- and Micro-expression Spotting with Direct Timestamp Encoding
Oct 24, 2024



The task of macro- and micro-expression spotting aims to precisely localize and categorize temporal expression instances within untrimmed videos. Given the sparse distribution and varying durations of expressions, existing anchor-based methods often represent instances by encoding their deviations from predefined anchors. Additionally, these methods typically slice the untrimmed videos into fixed-length sliding windows. However, anchor-based encoding often fails to capture all training intervals, and slicing the original video as sliding windows can result in valuable training intervals being discarded. To overcome these limitations, we introduce PESFormer, a simple yet effective model based on the vision transformer architecture to achieve point-to-interval expression spotting. PESFormer employs a direct timestamp encoding (DTE) approach to replace anchors, enabling binary classification of each timestamp instead of optimizing entire ground truths. Thus, all training intervals are retained in the form of discrete timestamps. To maximize the utilization of training intervals, we enhance the preprocessing process by replacing the short videos produced through the sliding window method.Instead, we implement a strategy that involves zero-padding the untrimmed training videos to create uniform, longer videos of a predetermined duration. This operation efficiently preserves the original training intervals and eliminates video slice enhancement.Extensive qualitative and quantitative evaluations on three datasets -- CAS(ME)^2, CAS(ME)^3 and SAMM-LV -- demonstrate that our PESFormer outperforms existing techniques, achieving the best performance.
Towards Extreme Image Compression with Latent Feature Guidance and Diffusion Prior
Apr 29, 2024Compressing images at extremely low bitrates (below 0.1 bits per pixel (bpp)) is a significant challenge due to substantial information loss. Existing extreme image compression methods generally suffer from heavy compression artifacts or low-fidelity reconstructions. To address this problem, we propose a novel extreme image compression framework that combines compressive VAEs and pre-trained text-to-image diffusion models in an end-to-end manner. Specifically, we introduce a latent feature-guided compression module based on compressive VAEs. This module compresses images and initially decodes the compressed information into content variables. To enhance the alignment between content variables and the diffusion space, we introduce external guidance to modulate intermediate feature maps. Subsequently, we develop a conditional diffusion decoding module that leverages pre-trained diffusion models to further decode these content variables. To preserve the generative capability of pre-trained diffusion models, we keep their parameters fixed and use a control module to inject content information. We also design a space alignment loss to provide sufficient constraints for the latent feature-guided compression module. Extensive experiments demonstrate that our method outperforms state-of-the-art approaches in terms of both visual performance and image fidelity at extremely low bitrates.