 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoRa Receiver
Papers and Code
DR-LoRA: Dynamic Rank LoRA for Mixture-of-Experts Adaptation
Jan 08, 2026Mixture-of-Experts (MoE) has become a prominent paradigm for scaling Large Language Models (LLMs). Parameter-efficient fine-tuning (PEFT), such as LoRA, is widely adopted to adapt pretrained MoE LLMs to downstream tasks. However, existing approaches assign identical LoRA ranks to all experts, overlooking the intrinsic functional specialization within MoE LLMs. This uniform allocation leads to resource mismatch, task-relevant experts are under-provisioned while less relevant ones receive redundant parameters. We propose a Dynamic Rank LoRA framework named DR-LoRA, which dynamically grows expert LoRA ranks during fine-tuning based on task-specific demands. DR-LoRA employs an Expert Saliency Scoring mechanism that integrates expert routing frequency and LoRA rank importance to quantify each expert's demand for additional capacity. Experts with higher saliency scores are prioritized for rank expansion, enabling the automatic formation of a heterogeneous rank distribution tailored to the target task. Experiments on multiple benchmarks demonstrate that DR-LoRA consistently outperforms standard LoRA and static allocation strategies under the same parameter budget, achieving superior task performance with more efficient parameter utilization.
Dataset and UAV Propagation Channel Modeling for LoRa in the 860 MHz ISM Band
Dec 17, 2025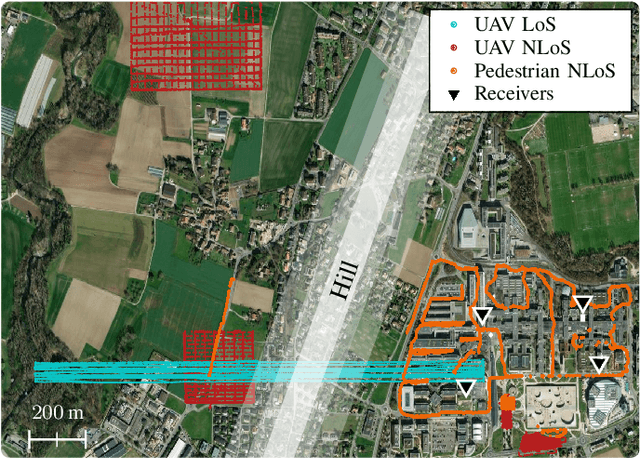
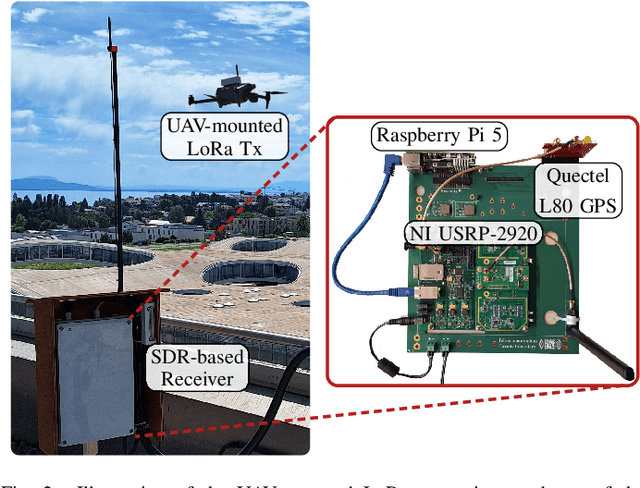
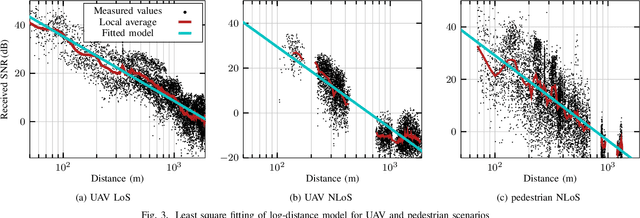
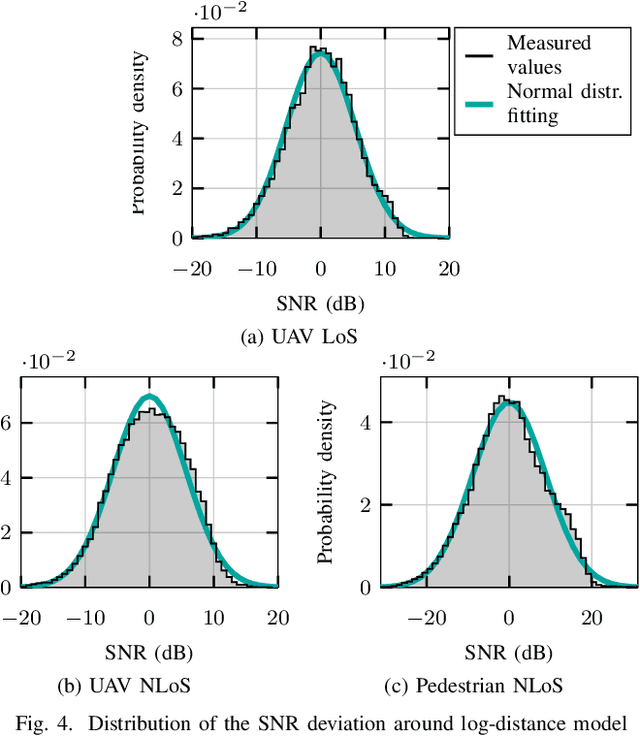
LoRa is one of the most widely used low-power wide-area network technology for the Internet of Things. To achieve long-range communication with low power consumption at a low cost, LoRa uses a chirp spread spectrum modulation and transmits in the sub-GHz unlicensed industrial, scientific, and medical (ISM) frequency bands. Due to the rapid densification of IoT networks, it is crucial to obtain tailored channel models to evaluate the performance of LoRa networks. While channel models for cellular technologies have been investigated extensively, specific characteristics of LoRa transmissions operating at long range with a rather small (~ 250kHz) bandwidth require dedicated measurement campaigns and modeling efforts. In this work, we leverage an SDR-based testbed to gather and publish a dataset of LoRa frames transmitted in a campus environment. The dataset includes IQ samples of the received frames at multiple locations and allows for the evaluation of channel variations with high time resolution. Using the gathered data, we derive empirical propagation channel models for LoRa that include receiver correlation over distance for three scenarios: unmanned aerial vehicle (UAV) line-of-sight (LoS), UAV non-LoS, and pedestrian non-LoS. Furthermore, the dataset is annotated with synchronization information, enabling the evaluation of receiver algorithms using experimental data.
LoRaCompass: Robust Reinforcement Learning to Efficiently Search for a LoRa Tag
Nov 14, 2025



The Long-Range (LoRa) protocol, known for its extensive range and low power, has increasingly been adopted in tags worn by mentally incapacitated persons (MIPs) and others at risk of going missing. We study the sequential decision-making process for a mobile sensor to locate a periodically broadcasting LoRa tag with the fewest moves (hops) in general, unknown environments, guided by the received signal strength indicator (RSSI). While existing methods leverage reinforcement learning for search, they remain vulnerable to domain shift and signal fluctuation, resulting in cascading decision errors that culminate in substantial localization inaccuracies. To bridge this gap, we propose LoRaCompass, a reinforcement learning model designed to achieve robust and efficient search for a LoRa tag. For exploitation under domain shift and signal fluctuation, LoRaCompass learns a robust spatial representation from RSSI to maximize the probability of moving closer to a tag, via a spatially-aware feature extractor and a policy distillation loss function. It further introduces an exploration function inspired by the upper confidence bound (UCB) that guides the sensor toward the tag with increasing confidence. We have validated LoRaCompass in ground-based and drone-assisted scenarios within diverse unseen environments covering an area of over 80km^2. It has demonstrated high success rate (>90%) in locating the tag within 100m proximity (a 40% improvement over existing methods) and high efficiency with a search path length (in hops) that scales linearly with the initial distance.
FT-MDT: Extracting Decision Trees from Medical Texts via a Novel Low-rank Adaptation Method
Oct 06, 2025Knowledge of the medical decision process, which can be modeled as medical decision trees (MDTs), is critical to building clinical decision support systems. However, current MDT construction methods rely heavily on time-consuming and laborious manual annotation. To address this challenge, we propose PI-LoRA (Path-Integrated LoRA), a novel low-rank adaptation method for automatically extracting MDTs from clinical guidelines and textbooks. We integrate gradient path information to capture synergistic effects between different modules, enabling more effective and reliable rank allocation. This framework ensures that the most critical modules receive appropriate rank allocations while less important ones are pruned, resulting in a more efficient and accurate model for extracting medical decision trees from clinical texts. Extensive experiments on medical guideline datasets demonstrate that our PI-LoRA method significantly outperforms existing parameter-efficient fine-tuning approaches for the Text2MDT task, achieving better accuracy with substantially reduced model complexity. The proposed method achieves state-of-the-art results while maintaining a lightweight architecture, making it particularly suitable for clinical decision support systems where computational resources may be limited.
HapticLLaMA: A Multimodal Sensory Language Model for Haptic Captioning
Aug 08, 2025Haptic captioning is the task of generating natural language descriptions from haptic signals, such as vibrations, for use in virtual reality, accessibility, and rehabilitation applications. While previous multimodal research has focused primarily on vision and audio, haptic signals for the sense of touch remain underexplored. To address this gap, we formalize the haptic captioning task and propose HapticLLaMA, a multimodal sensory language model that interprets vibration signals into descriptions in a given sensory, emotional, or associative category. We investigate two types of haptic tokenizers, a frequency-based tokenizer and an EnCodec-based tokenizer, that convert haptic signals into sequences of discrete units, enabling their integration with the LLaMA model. HapticLLaMA is trained in two stages: (1) supervised fine-tuning using the LLaMA architecture with LoRA-based adaptation, and (2) fine-tuning via reinforcement learning from human feedback (RLHF). We assess HapticLLaMA's captioning performance using both automated n-gram metrics and human evaluation. HapticLLaMA demonstrates strong capability in interpreting haptic vibration signals, achieving a METEOR score of 59.98 and a BLEU-4 score of 32.06 respectively. Additionally, over 61% of the generated captions received human ratings above 3.5 on a 7-point scale, with RLHF yielding a 10% improvement in the overall rating distribution, indicating stronger alignment with human haptic perception. These findings highlight the potential of large language models to process and adapt to sensory data.
MmWave-LoRadar Empowered Vehicular Integrated Sensing and Communication Systems: LoRa Meets FMCW
May 16, 2025The integrated sensing and communication (ISAC) technique is regarded as a key component in future vehicular applications. In this paper, we propose an ISAC solution that integrates Long Range (LoRa) modulation with frequency-modulated continuous wave (FMCW) radar in the millimeter-wave (mmWave) band, called mmWave-LoRadar. This design introduces the sensing capabilities to the LoRa communication with a simplified hardware architecture. Particularly, we uncover the dual discontinuity issues in time and phase of the mmWave-LoRadar received signals, rendering conventional signal processing techniques ineffective. As a remedy, we propose a corresponding hardware design and signal processing schemes under the compressed sampling framework. These techniques effectively cope with the dual discontinuity issues and mitigate the demands for high-sampling-rate analog-to-digital converters while achieving good performance. Simulation results demonstrate the superiority of the mmWave-LoRadar ISAC system in vehicular communication and sensing networks.
Super-LoRa: Enhancing LoRa Throughput via Payload Superposition
Apr 16, 2025This paper presents Super-LoRa, a novel approach to enhancing the throughput of LoRa networks by leveraging the inherent robustness of LoRa modulation against interference. By superimposing multiple payload symbols, Super-LoRa significantly increases the data rate while maintaining lower transmitter and receiver complexity. Our solution is evaluated through both simulations and real-world experiments, showing a potential throughput improvement of up to 5x compared to standard LoRa. This advancement positions Super-LoRa as a viable solution for data-intensive IoT applications such as smart cities and precision agriculture, which demand higher data transmission rates.
On Performance of LoRa Fluid Antenna Systems
Feb 21, 2025This paper advocates a fluid antenna system (FAS) assisting long-range communication (LoRa-FAS) for Internet-of-Things (IoT) applications. Our focus is on pilot sequence overhead and placement for FAS. Specifically, we consider embedding pilot sequences within symbols to reduce the equivalent symbol error rate (SER), leveraging the fact that the pilot sequences do not convey source information and correlation detection at the LoRa receiver needs not be performed across the entire symbol. We obtain closed-form approximations for the probability density function (PDF) and cumulative distribution function (CDF) of the FAS channel, assuming perfect channel state information (CSI). Moreover, the approximate SER, hence the bit error rate (BER), of the proposed LoRa-FAS is derived. Simulation results indicate that substantial SER gains can be achieved by FAS within the LoRa framework, even with a limited size of FAS. Furthermore, our analytical results align well with that of the Clarke's exact spatial correlation model. Finally, the correlation factor for the block correlation model should be selected as the proportion of the exact correlation matrix's eigenvalues greater than $1$.
Low-Rank Adaptation of Neural Fields
Apr 22, 2025Processing visual data often involves small adjustments or sequences of changes, such as in image filtering, surface smoothing, and video storage. While established graphics techniques like normal mapping and video compression exploit redundancy to encode such small changes efficiently, the problem of encoding small changes to neural fields (NF) -- neural network parameterizations of visual or physical functions -- has received less attention. We propose a parameter-efficient strategy for updating neural fields using low-rank adaptations (LoRA). LoRA, a method from the parameter-efficient fine-tuning LLM community, encodes small updates to pre-trained models with minimal computational overhead. We adapt LoRA to instance-specific neural fields, avoiding the need for large pre-trained models yielding a pipeline suitable for low-compute hardware. We validate our approach with experiments in image filtering, video compression, and geometry editing, demonstrating its effectiveness and versatility for representing neural field updates.
Fighting Fire with Fire: Channel-Independent RF Fingerprinting via the Ratio of Linear to Logarithmic Differential Spectrum
Mar 28, 2025Eliminating the influence of temporally varying channel components on the radio frequency fingerprint (RFF) extraction has been an enduring and challenging issue. To overcome this problem, we propose a channel-independent RFF extraction method inspired by the idea of 'fighting fire with fire'. Specifically, we derive the linear differential spectrum and the logarithmic differential spectrum of the channel frequency responses (CFRs) from the received signals at different times, and then calculate the ratio of the two spectrums. It is found that the division operation effectively counteracts the channel effects, while simultaneously preserving the integrity of the RFFs. Our experiments on LTE-V2X, LoRa and Wi-Fi devices show that the proposed method achieves an average identification accuracy exceeding 95% across various environments.