 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging the Semantic-Collaborative Gap: An Asymmetric Graph Architecture for Cold-Start Item Recommendation
Jun 04, 2026Collaborative filtering and graph-based recommendation models are highly effective because they leverage observed user interactions, but this dependence creates a fundamental cold-start challenge when newly added content has no interaction history. In Tubi's production retrieval system, this challenge is further constrained by the serving interface: new content must be assigned a standalone embedding immediately, and the model must also produce device embeddings suitable for approximate nearest-neighbor retrieval. We address this setting by formulating cold-start recommendation as an inductive graph-completion problem on a temporal bipartite device-content graph. We propose Shallow-RHS, an asymmetric link-prediction architecture in which the left-hand side (LHS) device tower leverages temporally valid watch-history message passing to capture collaborative signals, while the right-hand side (RHS) content tower is intentionally shallow with respect to the graph and encodes content solely from intrinsic features. The RHS tower does not use ID-based embeddings, content-side subgraphs, neighbor aggregation, or interaction-derived representations, forcing the content encoder to map intrinsic features into a collaborative-filtering-aware embedding space. After training, the learned content encoder generates embeddings for both warm and newly ingested content, enabling implicit graph completion through retrieval of warm surrogate neighbors. We further extend the same representation-completion principle to device cold-start by constructing cohort-based embeddings from demographic features. Large-scale online experiments demonstrate consistent relative improvements in content cold-start engagement, promotion speed, impression acquisition, and device cold-start engagement.
Vidmento: Creating Video Stories Through Context-Aware Expansion With Generative Video
Jan 29, 2026Video storytelling is often constrained by available material, limiting creative expression and leaving undesired narrative gaps. Generative video offers a new way to address these limitations by augmenting captured media with tailored visuals. To explore this potential, we interviewed eight video creators to identify opportunities and challenges in integrating generative video into their workflows. Building on these insights and established filmmaking principles, we developed Vidmento, a tool for authoring hybrid video stories that combine captured and generated media through context-aware expansion. Vidmento surfaces opportunities for story development, generates clips that blend stylistically and narratively with surrounding media, and provides controls for refinement. In a study with 12 creators, Vidmento supported narrative development and exploration by systematically expanding initial materials with generative media, enabling expressive video storytelling aligned with creative intent. We highlight how creators bridge story gaps with generative content and where they find this blending capability most valuable.
Rewriting Video: Text-Driven Reauthoring of Video Footage
Jan 13, 2026Video is a powerful medium for communication and storytelling, yet reauthoring existing footage remains challenging. Even simple edits often demand expertise, time, and careful planning, constraining how creators envision and shape their narratives. Recent advances in generative AI suggest a new paradigm: what if editing a video were as straightforward as rewriting text? To investigate this, we present a tech probe and a study on text-driven video reauthoring. Our approach involves two technical contributions: (1) a generative reconstruction algorithm that reverse-engineers video into an editable text prompt, and (2) an interactive probe, Rewrite Kit, that allows creators to manipulate these prompts. A technical evaluation of the algorithm reveals a critical human-AI perceptual gap. A probe study with 12 creators surfaced novel use cases such as virtual reshooting, synthetic continuity, and aesthetic restyling. It also highlighted key tensions around coherence, control, and creative alignment in this new paradigm. Our work contributes empirical insights into the opportunities and challenges of text-driven video reauthoring, offering design implications for future co-creative video tools.
Low-Rank Adaptation of Neural Fields
Apr 22, 2025Processing visual data often involves small adjustments or sequences of changes, such as in image filtering, surface smoothing, and video storage. While established graphics techniques like normal mapping and video compression exploit redundancy to encode such small changes efficiently, the problem of encoding small changes to neural fields (NF) -- neural network parameterizations of visual or physical functions -- has received less attention. We propose a parameter-efficient strategy for updating neural fields using low-rank adaptations (LoRA). LoRA, a method from the parameter-efficient fine-tuning LLM community, encodes small updates to pre-trained models with minimal computational overhead. We adapt LoRA to instance-specific neural fields, avoiding the need for large pre-trained models yielding a pipeline suitable for low-compute hardware. We validate our approach with experiments in image filtering, video compression, and geometry editing, demonstrating its effectiveness and versatility for representing neural field updates.
SpeakEasy: Enhancing Text-to-Speech Interactions for Expressive Content Creation
Apr 07, 2025



Novice content creators often invest significant time recording expressive speech for social media videos. While recent advancements in text-to-speech (TTS) technology can generate highly realistic speech in various languages and accents, many struggle with unintuitive or overly granular TTS interfaces. We propose simplifying TTS generation by allowing users to specify high-level context alongside their script. Our Wizard-of-Oz system, SpeakEasy, leverages user-provided context to inform and influence TTS output, enabling iterative refinement with high-level feedback. This approach was informed by two 8-subject formative studies: one examining content creators' experiences with TTS, and the other drawing on effective strategies from voice actors. Our evaluation shows that participants using SpeakEasy were more successful in generating performances matching their personal standards, without requiring significantly more effort than leading industry interfaces.
VideoMix: Aggregating How-To Videos for Task-Oriented Learning
Mar 27, 2025Tutorial videos are a valuable resource for people looking to learn new tasks. People often learn these skills by viewing multiple tutorial videos to get an overall understanding of a task by looking at different approaches to achieve the task. However, navigating through multiple videos can be time-consuming and mentally demanding as these videos are scattered and not easy to skim. We propose VideoMix, a system that helps users gain a holistic understanding of a how-to task by aggregating information from multiple videos on the task. Insights from our formative study (N=12) reveal that learners value understanding potential outcomes, required materials, alternative methods, and important details shared by different videos. Powered by a Vision-Language Model pipeline, VideoMix extracts and organizes this information, presenting concise textual summaries alongside relevant video clips, enabling users to quickly digest and navigate the content. A comparative user study (N=12) demonstrated that VideoMix enabled participants to gain a more comprehensive understanding of tasks with greater efficiency than a baseline video interface, where videos are viewed independently. Our findings highlight the potential of a task-oriented, multi-video approach where videos are organized around a shared goal, offering an enhanced alternative to conventional video-based learning.
TutoAI: A Cross-domain Framework for AI-assisted Mixed-media Tutorial Creation on Physical Tasks
Mar 12, 2024Mixed-media tutorials, which integrate videos, images, text, and diagrams to teach procedural skills, offer more browsable alternatives than timeline-based videos. However, manually creating such tutorials is tedious, and existing automated solutions are often restricted to a particular domain. While AI models hold promise, it is unclear how to effectively harness their powers, given the multi-modal data involved and the vast landscape of models. We present TutoAI, a cross-domain framework for AI-assisted mixed-media tutorial creation on physical tasks. First, we distill common tutorial components by surveying existing work; then, we present an approach to identify, assemble, and evaluate AI models for component extraction; finally, we propose guidelines for designing user interfaces (UI) that support tutorial creation based on AI-generated components. We show that TutoAI has achieved higher or similar quality compared to a baseline model in preliminary user studies.
Sensitive Data Detection with High-Throughput Neural Network Models for Financial Institutions
Dec 17, 2020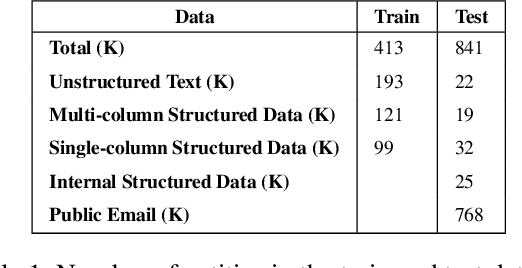
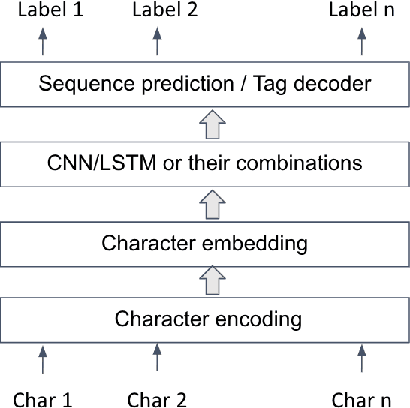
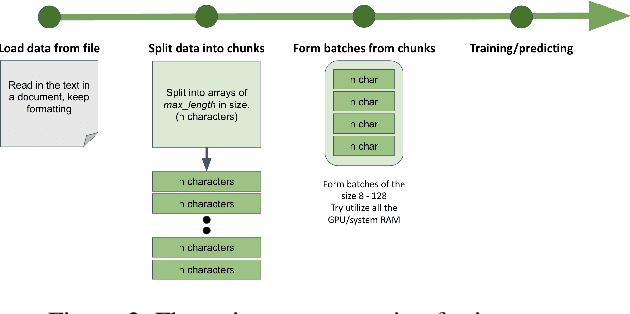
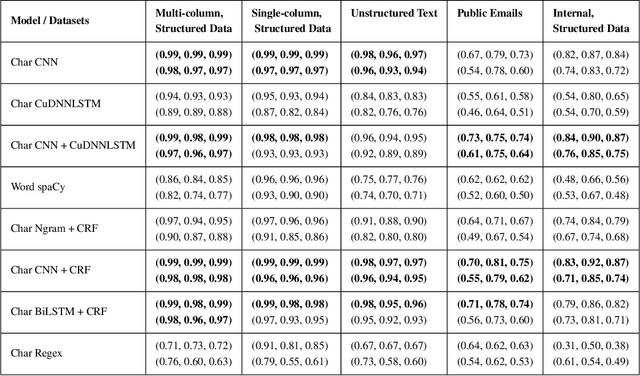
Named Entity Recognition has been extensively investigated in many fields. However, the application of sensitive entity detection for production systems in financial institutions has not been well explored due to the lack of publicly available, labeled datasets. In this paper, we use internal and synthetic datasets to evaluate various methods of detecting NPI (Nonpublic Personally Identifiable) information commonly found within financial institutions, in both unstructured and structured data formats. Character-level neural network models including CNN, LSTM, BiLSTM-CRF, and CNN-CRF are investigated on two prediction tasks: (i) entity detection on multiple data formats, and (ii) column-wise entity prediction on tabular datasets. We compare these models with other standard approaches on both real and synthetic data, with respect to F1-score, precision, recall, and throughput. The real datasets include internal structured data and public email data with manually tagged labels. Our experimental results show that the CNN model is simple yet effective with respect to accuracy and throughput and thus, is the most suitable candidate model to be deployed in the production environment(s). Finally, we provide several lessons learned on data limitations, data labelling and the intrinsic overlap of data entities.
Rekall: Specifying Video Events using Compositions of Spatiotemporal Labels
Oct 07, 2019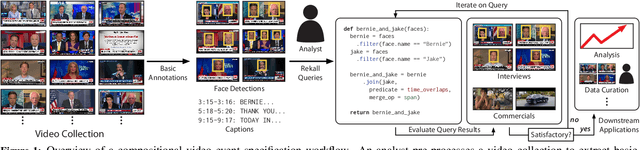
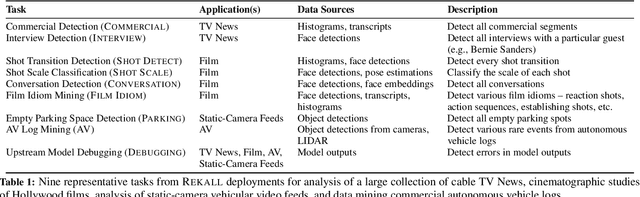
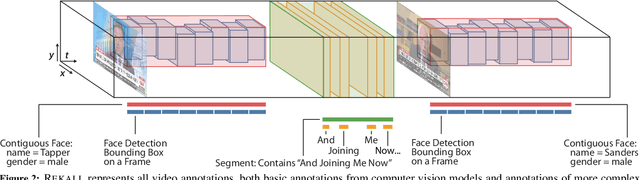

Many real-world video analysis applications require the ability to identify domain-specific events in video, such as interviews and commercials in TV news broadcasts, or action sequences in film. Unfortunately, pre-trained models to detect all the events of interest in video may not exist, and training new models from scratch can be costly and labor-intensive. In this paper, we explore the utility of specifying new events in video in a more traditional manner: by writing queries that compose outputs of existing, pre-trained models. To write these queries, we have developed Rekall, a library that exposes a data model and programming model for compositional video event specification. Rekall represents video annotations from different sources (object detectors, transcripts, etc.) as spatiotemporal labels associated with continuous volumes of spacetime in a video, and provides operators for composing labels into queries that model new video events. We demonstrate the use of Rekall in analyzing video from cable TV news broadcasts, films, static-camera vehicular video streams, and commercial autonomous vehicle logs. In these efforts, domain experts were able to quickly (in a few hours to a day) author queries that enabled the accurate detection of new events (on par with, and in some cases much more accurate than, learned approaches) and to rapidly retrieve video clips for human-in-the-loop tasks such as video content curation and training data curation. Finally, in a user study, novice users of Rekall were able to author queries to retrieve new events in video given just one hour of query development time.
Towards Automated Machine Learning: Evaluation and Comparison of AutoML Approaches and Tools
Sep 03, 2019
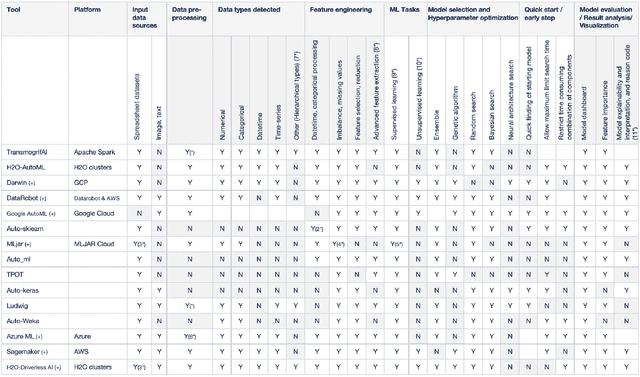

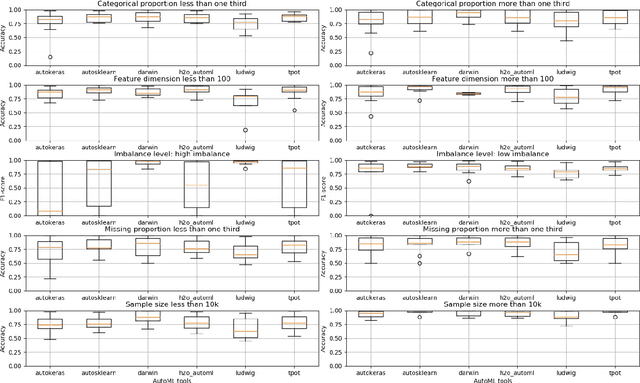
There has been considerable growth and interest in industrial applications of machine learning (ML) in recent years. ML engineers, as a consequence, are in high demand across the industry, yet improving the efficiency of ML engineers remains a fundamental challenge. Automated machine learning (AutoML) has emerged as a way to save time and effort on repetitive tasks in ML pipelines, such as data pre-processing, feature engineering, model selection, hyperparameter optimization, and prediction result analysis. In this paper, we investigate the current state of AutoML tools aiming to automate these tasks. We conduct various evaluations of the tools on many datasets, in different data segments, to examine their performance, and compare their advantages and disadvantages on different test cases.