 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Vocabulary Continuous Speech
Papers and Code
Listen, Look, Drive: Coupling Audio Instructions for User-aware VLA-based Autonomous Driving
Jan 17, 2026Vision Language Action (VLA) models promise an open-vocabulary interface that can translate perceptual ambiguity into semantically grounded driving decisions, yet they still treat language as a static prior fixed at inference time. As a result, the model must infer continuously shifting objectives from pixels alone, yielding delayed or overly conservative maneuvers. We argue that effective VLAs for autonomous driving need an online channel in which users can influence driving with specific intentions. To this end, we present EchoVLA, a user-aware VLA that couples camera streams with in situ audio instructions. We augment the nuScenes dataset with temporally aligned, intent-specific speech commands generated by converting ego-motion descriptions into synthetic audios. Further, we compose emotional speech-trajectory pairs into a multimodal Chain-of-Thought (CoT) for fine-tuning a Multimodal Large Model (MLM) based on Qwen2.5-Omni. Specifically, we synthesize the audio-augmented dataset with different emotion types paired with corresponding driving behaviors, leveraging the emotional cues embedded in tone, pitch, and speech tempo to reflect varying user states, such as urgent or hesitant intentions, thus enabling our EchoVLA to interpret not only the semantic content but also the emotional context of audio commands for more nuanced and emotionally adaptive driving behavior. In open-loop benchmarks, our approach reduces the average L2 error by $59.4\%$ and the collision rate by $74.4\%$ compared to the baseline of vision-only perception. More experiments on nuScenes dataset validate that EchoVLA not only steers the trajectory through audio instructions, but also modulates driving behavior in response to the emotions detected in the user's speech.
LegoSLM: Connecting LLM with Speech Encoder using CTC Posteriors
May 16, 2025Recently, large-scale pre-trained speech encoders and Large Language Models (LLMs) have been released, which show state-of-the-art performance on a range of spoken language processing tasks including Automatic Speech Recognition (ASR). To effectively combine both models for better performance, continuous speech prompts, and ASR error correction have been adopted. However, these methods are prone to suboptimal performance or are inflexible. In this paper, we propose a new paradigm, LegoSLM, that bridges speech encoders and LLMs using the ASR posterior matrices. The speech encoder is trained to generate Connectionist Temporal Classification (CTC) posteriors over the LLM vocabulary, which are used to reconstruct pseudo-audio embeddings by computing a weighted sum of the LLM input embeddings. These embeddings are concatenated with text embeddings in the LLM input space. Using the well-performing USM and Gemma models as an example, we demonstrate that our proposed LegoSLM method yields good performance on both ASR and speech translation tasks. By connecting USM with Gemma models, we can get an average of 49% WERR over the USM-CTC baseline on 8 MLS testsets. The trained model also exhibits modularity in a range of settings -- after fine-tuning the Gemma model weights, the speech encoder can be switched and combined with the LLM in a zero-shot fashion. Additionally, we propose to control the decode-time influence of the USM and LLM using a softmax temperature, which shows effectiveness in domain adaptation.
Literary and Colloquial Tamil Dialect Identification
Aug 25, 2024Culture and language evolve together. The old literary form of Tamil is used commonly for writing and the contemporary colloquial Tamil is used for speaking. Human-computer interaction applications require Colloquial Tamil (CT) to make it more accessible and easy for the everyday user and, it requires Literary Tamil (LT) when information is needed in a formal written format. Continuing the use of LT alongside CT in computer aided language learning applications will both preserve LT, and provide ease of use via CT, at the same time. Hence there is a need for the conversion between LT and CT dialects, which demands as a first step, dialect identification. Dialect Identification (DID) of LT and CT is an unexplored area of research. In the current work, keeping the nuances of both these dialects in mind, five methods are explored which include two implicit methods - Gaussian Mixture Model (GMM) and Convolutional Neural Network (CNN); two explicit methods - Parallel Phone Recognition (PPR) and Parallel Large Vocabulary Continuous Speech Recognition (P-LVCSR); two versions of the proposed explicit Unified Phone Recognition method (UPR-1 and UPR-2). These methods vary based on: the need for annotated data, the size of the unit, the way in which modelling is carried out, and the way in which the final decision is made. Even though the average duration of the test utterances is less - 4.9s for LT and 2.5s for CT - the systems performed well, offering the following identification accuracies: 87.72% (GMM), 93.97% (CNN), 89.24% (PPR), 94.21% (P-LVCSR), 88.57% (UPR-1), 93.53% (UPR-1 with P-LVCSR), 94.55% (UPR-2), and 95.61% (UPR-2 with P-LVCSR).
* 18 pages, 6 figures, submitted to "Circuits, Systems, and Signal Processing"
CNVSRC 2023: The First Chinese Continuous Visual Speech Recognition Challenge
Jun 14, 2024



The first Chinese Continuous Visual Speech Recognition Challenge aimed to probe the performance of Large Vocabulary Continuous Visual Speech Recognition (LVC-VSR) on two tasks: (1) Single-speaker VSR for a particular speaker and (2) Multi-speaker VSR for a set of registered speakers. The challenge yielded highly successful results, with the best submission significantly outperforming the baseline, particularly in the single-speaker task. This paper comprehensively reviews the challenge, encompassing the data profile, task specifications, and baseline system construction. It also summarises the representative techniques employed by the submitted systems, highlighting the most effective approaches. Additional information and resources about this challenge can be accessed through the official website at http://cnceleb.org/competition.
mmWave-Whisper: Phone Call Eavesdropping and Transcription Using Millimeter-Wave Radar
Oct 22, 2024



This paper introduces mmWave-Whisper, a system that demonstrates the feasibility of full-corpus automated speech recognition (ASR) on phone calls eavesdropped remotely using off-the-shelf frequency modulated continuous wave (FMCW) millimeter-wave radars. Operating in the 77-81 GHz range, mmWave-Whisper captures earpiece vibrations from smartphones, converts them into audio, and processes the audio to produce speech transcriptions automatically. Unlike previous work that focused on loudspeakers or limited vocabulary, this is the first work to perform such a speech recognition by handling large vocabulary and full sentences on earpiece vibrations from smartphones. This approach expands the potential of radar-audio eavesdropping. mmWave-Whisper addresses challenges such as the lack of large scale training datasets, low SNR, and limited frequency information in radar data through a systematic pipeline designed to leverage synthetic training data, domain adaptation, and inference by incorporating OpenAI's Whisper automatic speech recognition model. The system achieves a word accuracy rate of 44.74% and a character accuracy rate of 62.52% over a range of 25 cm to 125 cm. The paper highlights emerging misuse modalities of AI as the technology evolves rapidly.
Surrogate Gradient Spiking Neural Networks as Encoders for Large Vocabulary Continuous Speech Recognition
Dec 01, 2022



Compared to conventional artificial neurons that produce dense and real-valued responses, biologically-inspired spiking neurons transmit sparse and binary information, which can also lead to energy-efficient implementations. Recent research has shown that spiking neural networks can be trained like standard recurrent neural networks using the surrogate gradient method. They have shown promising results on speech command recognition tasks. Using the same technique, we show that they are scalable to large vocabulary continuous speech recognition, where they are capable of replacing LSTMs in the encoder with only minor loss of performance. This suggests that they may be applicable to more involved sequence-to-sequence tasks. Moreover, in contrast to their recurrent non-spiking counterparts, they show robustness to exploding gradient problems without the need to use gates.
Replay to Remember: Continual Layer-Specific Fine-tuning for German Speech Recognition
Jul 14, 2023While Automatic Speech Recognition (ASR) models have shown significant advances with the introduction of unsupervised or self-supervised training techniques, these improvements are still only limited to a subsection of languages and speakers. Transfer learning enables the adaptation of large-scale multilingual models to not only low-resource languages but also to more specific speaker groups. However, fine-tuning on data from new domains is usually accompanied by a decrease in performance on the original domain. Therefore, in our experiments, we examine how well the performance of large-scale ASR models can be approximated for smaller domains, with our own dataset of German Senior Voice Commands (SVC-de), and how much of the general speech recognition performance can be preserved by selectively freezing parts of the model during training. To further increase the robustness of the ASR model to vocabulary and speakers outside of the fine-tuned domain, we apply Experience Replay for continual learning. By adding only a fraction of data from the original domain, we are able to reach Word-Error-Rates (WERs) below 5\% on the new domain, while stabilizing performance for general speech recognition at acceptable WERs.
Emphasizing Unseen Words: New Vocabulary Acquisition for End-to-End Speech Recognition
Feb 21, 2023Due to the dynamic nature of human language, automatic speech recognition (ASR) systems need to continuously acquire new vocabulary. Out-Of-Vocabulary (OOV) words, such as trending words and new named entities, pose problems to modern ASR systems that require long training times to adapt their large numbers of parameters. Different from most previous research focusing on language model post-processing, we tackle this problem on an earlier processing level and eliminate the bias in acoustic modeling to recognize OOV words acoustically. We propose to generate OOV words using text-to-speech systems and to rescale losses to encourage neural networks to pay more attention to OOV words. Specifically, we enlarge the classification loss used for training neural networks' parameters of utterances containing OOV words (sentence-level), or rescale the gradient used for back-propagation for OOV words (word-level), when fine-tuning a previously trained model on synthetic audio. To overcome catastrophic forgetting, we also explore the combination of loss rescaling and model regularization, i.e. L2 regularization and elastic weight consolidation (EWC). Compared with previous methods that just fine-tune synthetic audio with EWC, the experimental results on the LibriSpeech benchmark reveal that our proposed loss rescaling approach can achieve significant improvement on the recall rate with only a slight decrease on word error rate. Moreover, word-level rescaling is more stable than utterance-level rescaling and leads to higher recall rates and precision on OOV word recognition. Furthermore, our proposed combined loss rescaling and weight consolidation methods can support continual learning of an ASR system.
An Asynchronous WFST-Based Decoder For Automatic Speech Recognition
Mar 16, 2021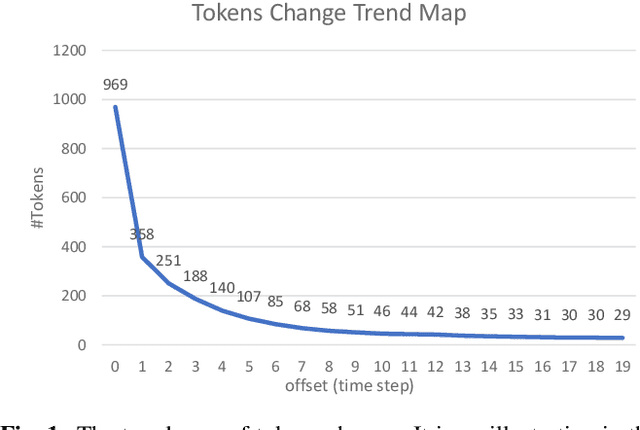
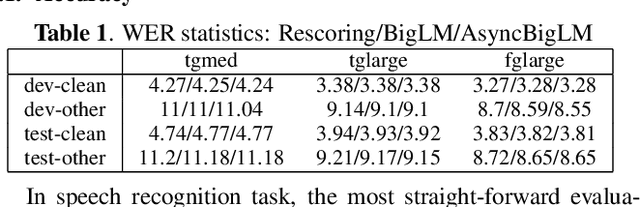
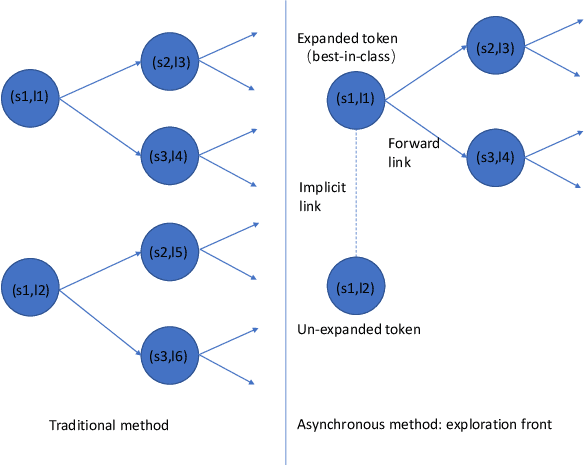
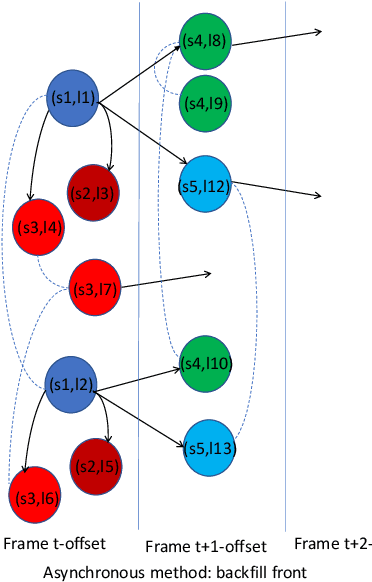
We introduce asynchronous dynamic decoder, which adopts an efficient A* algorithm to incorporate big language models in the one-pass decoding for large vocabulary continuous speech recognition. Unlike standard one-pass decoding with on-the-fly composition decoder which might induce a significant computation overhead, the asynchronous dynamic decoder has a novel design where it has two fronts, with one performing "exploration" and the other "backfill". The computation of the two fronts alternates in the decoding process, resulting in more effective pruning than the standard one-pass decoding with an on-the-fly composition decoder. Experiments show that the proposed decoder works notably faster than the standard one-pass decoding with on-the-fly composition decoder, while the acceleration will be more obvious with the increment of data complexity.
Effects of Number of Filters of Convolutional Layers on Speech Recognition Model Accuracy
Feb 03, 2021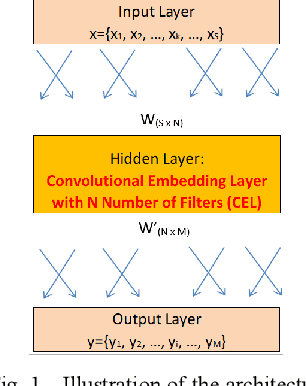
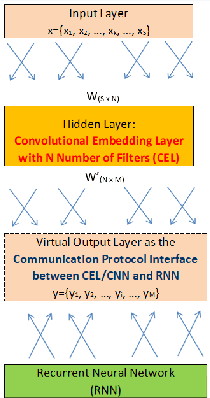
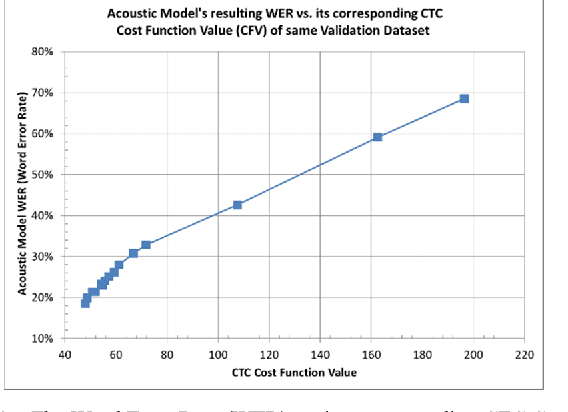
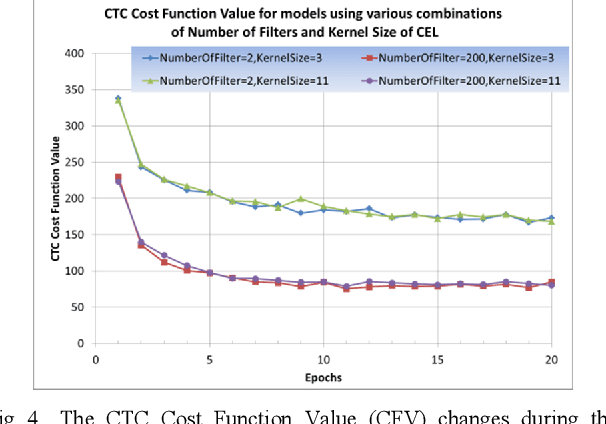
Inspired by the progress of the End-to-End approach [1], this paper systematically studies the effects of Number of Filters of convolutional layers on the model prediction accuracy of CNN+RNN (Convolutional Neural Networks adding to Recurrent Neural Networks) for ASR Models (Automatic Speech Recognition). Experimental results show that only when the CNN Number of Filters exceeds a certain threshold value is adding CNN to RNN able to improve the performance of the CNN+RNN speech recognition model, otherwise some parameter ranges of CNN can render it useless to add the CNN to the RNN model. Our results show a strong dependency of word accuracy on the Number of Filters of convolutional layers. Based on the experimental results, the paper suggests a possible hypothesis of Sound-2-Vector Embedding (Convolutional Embedding) to explain the above observations. Based on this Embedding hypothesis and the optimization of parameters, the paper develops an End-to-End speech recognition system which has a high word accuracy but also has a light model-weight. The developed LVCSR (Large Vocabulary Continuous Speech Recognition) model has achieved quite a high word accuracy of 90.2% only by its Acoustic Model alone, without any assistance from intermediate phonetic representation and any Language Model. Its acoustic model contains only 4.4 million weight parameters, compared to the 35~68 million acoustic-model weight parameters in DeepSpeech2 [2] (one of the top state-of-the-art LVCSR models) which can achieve a word accuracy of 91.5%. The light-weighted model is good for improving the transcribing computing efficiency and also useful for mobile devices, Driverless Vehicles, etc. Our model weight is reduced to ~10% the size of DeepSpeech2, but our model accuracy remains close to that of DeepSpeech2. If combined with a Language Model, our LVCSR system is able to achieve 91.5% word accuracy.