 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessment of L2 Oral Proficiency using Speech Large Language Models
May 27, 2025



The growing population of L2 English speakers has increased the demand for developing automatic graders for spoken language assessment (SLA). Historically, statistical models, text encoders, and self-supervised speech models have been utilised for this task. However, cascaded systems suffer from the loss of information, while E2E graders also have limitations. With the recent advancements of multi-modal large language models (LLMs), we aim to explore their potential as L2 oral proficiency graders and overcome these issues. In this work, we compare various training strategies using regression and classification targets. Our results show that speech LLMs outperform all previous competitive baselines, achieving superior performance on two datasets. Furthermore, the trained grader demonstrates strong generalisation capabilities in the cross-part or cross-task evaluation, facilitated by the audio understanding knowledge acquired during LLM pre-training.
Scaling and Prompting for Improved End-to-End Spoken Grammatical Error Correction
May 27, 2025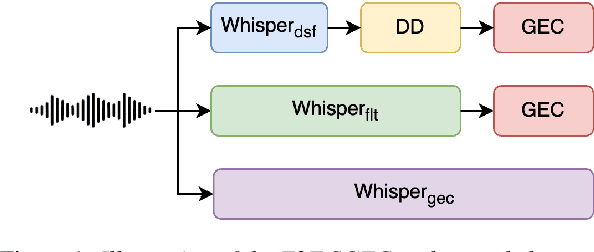
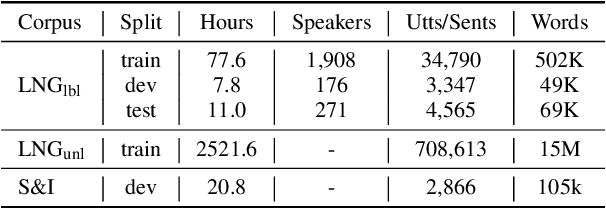
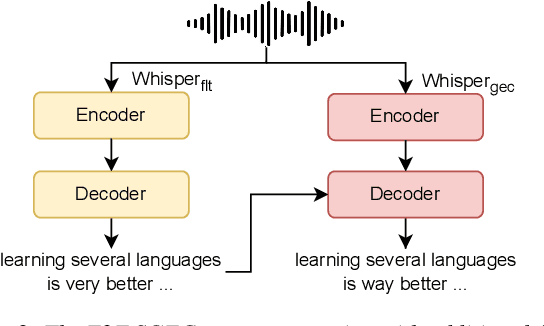
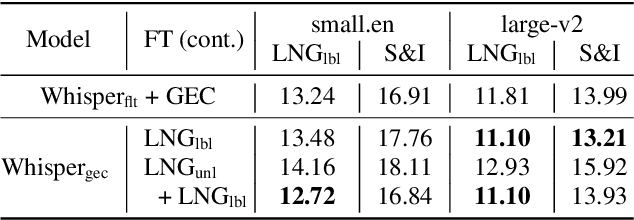
Spoken Grammatical Error Correction (SGEC) and Feedback (SGECF) are crucial for second language learners, teachers and test takers. Traditional SGEC systems rely on a cascaded pipeline consisting of an ASR, a module for disfluency detection (DD) and removal and one for GEC. With the rise of end-to-end (E2E) speech foundation models, we investigate their effectiveness in SGEC and feedback generation. This work introduces a pseudo-labelling process to address the challenge of limited labelled data, expanding the training data size from 77 hours to approximately 2500 hours, leading to improved performance. Additionally, we prompt an E2E Whisper-based SGEC model with fluent transcriptions, showing a slight improvement in SGEC performance, with more significant gains in feedback generation. Finally, we assess the impact of increasing model size, revealing that while pseudo-labelled data does not yield performance gain for a larger Whisper model, training with prompts proves beneficial.
Universal Acoustic Adversarial Attacks for Flexible Control of Speech-LLMs
May 20, 2025The combination of pre-trained speech encoders with large language models has enabled the development of speech LLMs that can handle a wide range of spoken language processing tasks. While these models are powerful and flexible, this very flexibility may make them more vulnerable to adversarial attacks. To examine the extent of this problem, in this work we investigate universal acoustic adversarial attacks on speech LLMs. Here a fixed, universal, adversarial audio segment is prepended to the original input audio. We initially investigate attacks that cause the model to either produce no output or to perform a modified task overriding the original prompt. We then extend the nature of the attack to be selective so that it activates only when specific input attributes, such as a speaker gender or spoken language, are present. Inputs without the targeted attribute should be unaffected, allowing fine-grained control over the model outputs. Our findings reveal critical vulnerabilities in Qwen2-Audio and Granite-Speech and suggest that similar speech LLMs may be susceptible to universal adversarial attacks. This highlights the need for more robust training strategies and improved resistance to adversarial attacks.
LegoSLM: Connecting LLM with Speech Encoder using CTC Posteriors
May 16, 2025Recently, large-scale pre-trained speech encoders and Large Language Models (LLMs) have been released, which show state-of-the-art performance on a range of spoken language processing tasks including Automatic Speech Recognition (ASR). To effectively combine both models for better performance, continuous speech prompts, and ASR error correction have been adopted. However, these methods are prone to suboptimal performance or are inflexible. In this paper, we propose a new paradigm, LegoSLM, that bridges speech encoders and LLMs using the ASR posterior matrices. The speech encoder is trained to generate Connectionist Temporal Classification (CTC) posteriors over the LLM vocabulary, which are used to reconstruct pseudo-audio embeddings by computing a weighted sum of the LLM input embeddings. These embeddings are concatenated with text embeddings in the LLM input space. Using the well-performing USM and Gemma models as an example, we demonstrate that our proposed LegoSLM method yields good performance on both ASR and speech translation tasks. By connecting USM with Gemma models, we can get an average of 49% WERR over the USM-CTC baseline on 8 MLS testsets. The trained model also exhibits modularity in a range of settings -- after fine-tuning the Gemma model weights, the speech encoder can be switched and combined with the LLM in a zero-shot fashion. Additionally, we propose to control the decode-time influence of the USM and LLM using a softmax temperature, which shows effectiveness in domain adaptation.
ASR Error Correction using Large Language Models
Sep 14, 2024



Error correction (EC) models play a crucial role in refining Automatic Speech Recognition (ASR) transcriptions, enhancing the readability and quality of transcriptions. Without requiring access to the underlying code or model weights, EC can improve performance and provide domain adaptation for black-box ASR systems. This work investigates the use of large language models (LLMs) for error correction across diverse scenarios. 1-best ASR hypotheses are commonly used as the input to EC models. We propose building high-performance EC models using ASR N-best lists which should provide more contextual information for the correction process. Additionally, the generation process of a standard EC model is unrestricted in the sense that any output sequence can be generated. For some scenarios, such as unseen domains, this flexibility may impact performance. To address this, we introduce a constrained decoding approach based on the N-best list or an ASR lattice. Finally, most EC models are trained for a specific ASR system requiring retraining whenever the underlying ASR system is changed. This paper explores the ability of EC models to operate on the output of different ASR systems. This concept is further extended to zero-shot error correction using LLMs, such as ChatGPT. Experiments on three standard datasets demonstrate the efficacy of our proposed methods for both Transducer and attention-based encoder-decoder ASR systems. In addition, the proposed method can serve as an effective method for model ensembling.
Learn and Don't Forget: Adding a New Language to ASR Foundation Models
Jul 09, 2024



Foundation ASR models often support many languages, e.g. 100 languages in Whisper. However, there has been limited work on integrating an additional, typically low-resource, language, while maintaining performance on the original language set. Fine-tuning, while simple, may degrade the accuracy of the original set. We compare three approaches that exploit adaptation parameters: soft language code tuning, train only the language code; soft prompt tuning, train prepended tokens; and LoRA where a small set of additional parameters are optimised. Elastic Weight Consolidation (EWC) offers an alternative compromise with the potential to maintain performance in specific target languages. Results show that direct fine-tuning yields the best performance for the new language but degrades existing language capabilities. EWC can address this issue for specific languages. If only adaptation parameters are used, the language capabilities are maintained but at the cost of performance in the new language.
Cross-Lingual Transfer Learning for Speech Translation
Jul 01, 2024



There has been increasing interest in building multilingual foundation models for NLP and speech research. Zero-shot cross-lingual transfer has been demonstrated on a range of NLP tasks where a model fine-tuned on task-specific data in one language yields performance gains in other languages. Here, we explore whether speech-based models exhibit the same transfer capability. Using Whisper as an example of a multilingual speech foundation model, we examine the utterance representation generated by the speech encoder. Despite some language-sensitive information being preserved in the audio embedding, words from different languages are mapped to a similar semantic space, as evidenced by a high recall rate in a speech-to-speech retrieval task. Leveraging this shared embedding space, zero-shot cross-lingual transfer is demonstrated in speech translation. When the Whisper model is fine-tuned solely on English-to-Chinese translation data, performance improvements are observed for input utterances in other languages. Additionally, experiments on low-resource languages show that Whisper can perform speech translation for utterances from languages unseen during pre-training by utilizing cross-lingual representations.
Muting Whisper: A Universal Acoustic Adversarial Attack on Speech Foundation Models
May 09, 2024



Recent developments in large speech foundation models like Whisper have led to their widespread use in many automatic speech recognition (ASR) applications. These systems incorporate `special tokens' in their vocabulary, such as $\texttt{<endoftext>}$, to guide their language generation process. However, we demonstrate that these tokens can be exploited by adversarial attacks to manipulate the model's behavior. We propose a simple yet effective method to learn a universal acoustic realization of Whisper's $\texttt{<endoftext>}$ token, which, when prepended to any speech signal, encourages the model to ignore the speech and only transcribe the special token, effectively `muting' the model. Our experiments demonstrate that the same, universal 0.64-second adversarial audio segment can successfully mute a target Whisper ASR model for over 97\% of speech samples. Moreover, we find that this universal adversarial audio segment often transfers to new datasets and tasks. Overall this work demonstrates the vulnerability of Whisper models to `muting' adversarial attacks, where such attacks can pose both risks and potential benefits in real-world settings: for example the attack can be used to bypass speech moderation systems, or conversely the attack can also be used to protect private speech data.
Investigating the Emergent Audio Classification Ability of ASR Foundation Models
Nov 15, 2023



Text and vision foundation models can perform many tasks in a zero-shot setting, a desirable property that enables these systems to be applied in general and low-resource settings. However, there has been significantly less work on the zero-shot abilities of ASR foundation models, with these systems typically fine-tuned to specific tasks or constrained to applications that match their training criterion and data annotation. In this work we investigate the ability of Whisper and MMS, ASR foundation models trained primarily for speech recognition, to perform zero-shot audio classification. We use simple template-based text prompts at the decoder and use the resulting decoding probabilities to generate zero-shot predictions. Without training the model on extra data or adding any new parameters, we demonstrate that Whisper shows promising zero-shot classification performance on a range of 8 audio-classification datasets, outperforming existing state-of-the-art zero-shot baseline's accuracy by an average of 9%. One important step to unlock the emergent ability is debiasing, where a simple unsupervised reweighting method of the class probabilities yields consistent significant performance gains. We further show that performance increases with model size, implying that as ASR foundation models scale up, they may exhibit improved zero-shot performance.
Towards End-to-End Spoken Grammatical Error Correction
Nov 09, 2023Grammatical feedback is crucial for L2 learners, teachers, and testers. Spoken grammatical error correction (GEC) aims to supply feedback to L2 learners on their use of grammar when speaking. This process usually relies on a cascaded pipeline comprising an ASR system, disfluency removal, and GEC, with the associated concern of propagating errors between these individual modules. In this paper, we introduce an alternative "end-to-end" approach to spoken GEC, exploiting a speech recognition foundation model, Whisper. This foundation model can be used to replace the whole framework or part of it, e.g., ASR and disfluency removal. These end-to-end approaches are compared to more standard cascaded approaches on the data obtained from a free-speaking spoken language assessment test, Linguaskill. Results demonstrate that end-to-end spoken GEC is possible within this architecture, but the lack of available data limits current performance compared to a system using large quantities of text-based GEC data. Conversely, end-to-end disfluency detection and removal, which is easier for the attention-based Whisper to learn, does outperform cascaded approaches. Additionally, the paper discusses the challenges of providing feedback to candidates when using end-to-end systems for spoken GEC.