 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterest Point Detection
Papers and Code
Semantically Aware UAV Landing Site Assessment from Remote Sensing Imagery via Multimodal Large Language Models
Feb 01, 2026Safe UAV emergency landing requires more than just identifying flat terrain; it demands understanding complex semantic risks (e.g., crowds, temporary structures) invisible to traditional geometric sensors. In this paper, we propose a novel framework leveraging Remote Sensing (RS) imagery and Multimodal Large Language Models (MLLMs) for global context-aware landing site assessment. Unlike local geometric methods, our approach employs a coarse-to-fine pipeline: first, a lightweight semantic segmentation module efficiently pre-screens candidate areas; second, a vision-language reasoning agent fuses visual features with Point-of-Interest (POI) data to detect subtle hazards. To validate this approach, we construct and release the Emergency Landing Site Selection (ELSS) benchmark. Experiments demonstrate that our framework significantly outperforms geometric baselines in risk identification accuracy. Furthermore, qualitative results confirm its ability to generate human-like, interpretable justifications, enhancing trust in automated decision-making. The benchmark dataset is publicly accessible at https://anonymous.4open.science/r/ELSS-dataset-43D7.
UniGeo: A Unified 3D Indoor Object Detection Framework Integrating Geometry-Aware Learning and Dynamic Channel Gating
Jan 30, 2026The growing adoption of robotics and augmented reality in real-world applications has driven considerable research interest in 3D object detection based on point clouds. While previous methods address unified training across multiple datasets, they fail to model geometric relationships in sparse point cloud scenes and ignore the feature distribution in significant areas, which ultimately restricts their performance. To deal with this issue, a unified 3D indoor detection framework, called UniGeo, is proposed. To model geometric relations in scenes, we first propose a geometry-aware learning module that establishes a learnable mapping from spatial relationships to feature weights, which enabes explicit geometric feature enhancement. Then, to further enhance point cloud feature representation, we propose a dynamic channel gating mechanism that leverages learnable channel-wise weighting. This mechanism adaptively optimizes features generated by the sparse 3D U-Net network, significantly enhancing key geometric information. Extensive experiments on six different indoor scene datasets clearly validate the superior performance of our method.
Tuberculosis Screening from Cough Audio: Baseline Models, Clinical Variables, and Uncertainty Quantification
Jan 12, 2026In this paper, we propose a standardized framework for automatic tuberculosis (TB) detection from cough audio and routinely collected clinical data using machine learning. While TB screening from audio has attracted growing interest, progress is difficult to measure because existing studies vary substantially in datasets, cohort definitions, feature representations, model families, validation protocols, and reported metrics. Consequently, reported gains are often not directly comparable, and it remains unclear whether improvements stem from modeling advances or from differences in data and evaluation. We address this gap by establishing a strong, well-documented baseline for TB prediction using cough recordings and accompanying clinical metadata from a recently compiled dataset from several countries. Our pipeline is reproducible end-to-end, covering feature extraction, multimodal fusion, cougher-independent evaluation, and uncertainty quantification, and it reports a consistent suite of clinically relevant metrics to enable fair comparison. We further quantify performance for cough audio-only and fused (audio + clinical metadata) models, and release the full experimental protocol to facilitate benchmarking. This baseline is intended to serve as a common reference point and to reduce methodological variance that currently holds back progress in the field.
ExposeAnyone: Personalized Audio-to-Expression Diffusion Models Are Robust Zero-Shot Face Forgery Detectors
Jan 05, 2026Detecting unknown deepfake manipulations remains one of the most challenging problems in face forgery detection. Current state-of-the-art approaches fail to generalize to unseen manipulations, as they primarily rely on supervised training with existing deepfakes or pseudo-fakes, which leads to overfitting to specific forgery patterns. In contrast, self-supervised methods offer greater potential for generalization, but existing work struggles to learn discriminative representations only from self-supervision. In this paper, we propose ExposeAnyone, a fully self-supervised approach based on a diffusion model that generates expression sequences from audio. The key idea is, once the model is personalized to specific subjects using reference sets, it can compute the identity distances between suspected videos and personalized subjects via diffusion reconstruction errors, enabling person-of-interest face forgery detection. Extensive experiments demonstrate that 1) our method outperforms the previous state-of-the-art method by 4.22 percentage points in the average AUC on DF-TIMIT, DFDCP, KoDF, and IDForge datasets, 2) our model is also capable of detecting Sora2-generated videos, where the previous approaches perform poorly, and 3) our method is highly robust to corruptions such as blur and compression, highlighting the applicability in real-world face forgery detection.
AI Assisted Next Gen Outdoor Optical Networks: Camera Sensing for Monitoring and User Localization
Dec 19, 2025We consider outdoor optical access points (OAPs), which, enabled by recent advances in metasurface technology, have attracted growing interest. While OAPs promise high data rates and strong physical-layer security, practical deployments still expose vulnerabilities and misuse patterns that necessitate a dedicated monitoring layer - the focus of this work. We therefore propose a user positioning and monitoring system that infers locations from spatial intensity measurements on a photodetector (PD) array. Specifically, our hybrid approach couples an optics-informed forward model and sparse, model-based inversion with a lightweight data-driven calibration stage, yielding high accuracy at low computational cost. This design preserves the interpretability and stability of model-based reconstruction while leveraging learning to absorb residual nonidealities and device-specific distortions. Under identical hardware and training conditions (both with 5 x 10^5 samples), the hybrid method attains consistently lower mean-squared error than a generic deep-learning baseline while using substantially less training time and compute. Accuracy improves with array resolution and saturates around 60 x 60-80 x 80, indicating a favorable accuracy-complexity trade-off for real-time deployment. The resulting position estimates can be cross-checked with real-time network logs to enable continuous monitoring, anomaly detection (e.g., potential eavesdropping), and access control in outdoor optical access networks.
CASL: Curvature-Augmented Self-supervised Learning for 3D Anomaly Detection
Nov 17, 2025Deep learning-based 3D anomaly detection methods have demonstrated significant potential in industrial manufacturing. However, many approaches are specifically designed for anomaly detection tasks, which limits their generalizability to other 3D understanding tasks. In contrast, self-supervised point cloud models aim for general-purpose representation learning, yet our investigation reveals that these classical models are suboptimal at anomaly detection under the unified fine-tuning paradigm. This motivates us to develop a more generalizable 3D model that can effectively detect anomalies without relying on task-specific designs. Interestingly, we find that using only the curvature of each point as its anomaly score already outperforms several classical self-supervised and dedicated anomaly detection models, highlighting the critical role of curvature in 3D anomaly detection. In this paper, we propose a Curvature-Augmented Self-supervised Learning (CASL) framework based on a reconstruction paradigm. Built upon the classical U-Net architecture, our approach introduces multi-scale curvature prompts to guide the decoder in predicting the spatial coordinates of each point. Without relying on any dedicated anomaly detection mechanisms, it achieves leading detection performance through straightforward anomaly classification fine-tuning. Moreover, the learned representations generalize well to standard 3D understanding tasks such as point cloud classification. The code is available at https://github.com/zyh16143998882/CASL.
CoRe-GS: Coarse-to-Refined Gaussian Splatting with Semantic Object Focus
Sep 05, 2025Mobile reconstruction for autonomous aerial robotics holds strong potential for critical applications such as tele-guidance and disaster response. These tasks demand both accurate 3D reconstruction and fast scene processing. Instead of reconstructing the entire scene in detail, it is often more efficient to focus on specific objects, i.e., points of interest (PoIs). Mobile robots equipped with advanced sensing can usually detect these early during data acquisition or preliminary analysis, reducing the need for full-scene optimization. Gaussian Splatting (GS) has recently shown promise in delivering high-quality novel view synthesis and 3D representation by an incremental learning process. Extending GS with scene editing, semantics adds useful per-splat features to isolate objects effectively. Semantic 3D Gaussian editing can already be achieved before the full training cycle is completed, reducing the overall training time. Moreover, the semantically relevant area, the PoI, is usually already known during capturing. To balance high-quality reconstruction with reduced training time, we propose CoRe-GS. We first generate a coarse segmentation-ready scene with semantic GS and then refine it for the semantic object using our novel color-based effective filtering for effective object isolation. This is speeding up the training process to be about a quarter less than a full training cycle for semantic GS. We evaluate our approach on two datasets, SCRREAM (real-world, outdoor) and NeRDS 360 (synthetic, indoor), showing reduced runtime and higher novel-view-synthesis quality.
Catoni-Style Change Point Detection for Regret Minimization in Non-Stationary Heavy-Tailed Bandits
May 26, 2025Regret minimization in stochastic non-stationary bandits gained popularity over the last decade, as it can model a broad class of real-world problems, from advertising to recommendation systems. Existing literature relies on various assumptions about the reward-generating process, such as Bernoulli or subgaussian rewards. However, in settings such as finance and telecommunications, heavy-tailed distributions naturally arise. In this work, we tackle the heavy-tailed piecewise-stationary bandit problem. Heavy-tailed bandits, introduced by Bubeck et al., 2013, operate on the minimal assumption that the finite absolute centered moments of maximum order $1+\epsilon$ are uniformly bounded by a constant $v<+\infty$, for some $\epsilon \in (0,1]$. We focus on the most popular non-stationary bandit setting, i.e., the piecewise-stationary setting, in which the mean of reward-generating distributions may change at unknown time steps. We provide a novel Catoni-style change-point detection strategy tailored for heavy-tailed distributions that relies on recent advancements in the theory of sequential estimation, which is of independent interest. We introduce Robust-CPD-UCB, which combines this change-point detection strategy with optimistic algorithms for bandits, providing its regret upper bound and an impossibility result on the minimum attainable regret for any policy. Finally, we validate our approach through numerical experiments on synthetic and real-world datasets.
Reconsidering Explicit Longitudinal Mammography Alignment for Enhanced Breast Cancer Risk Prediction
Jun 24, 2025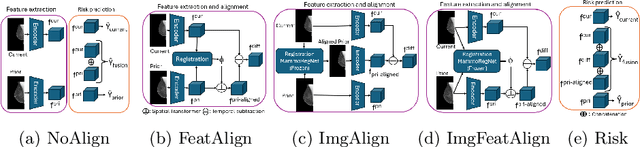
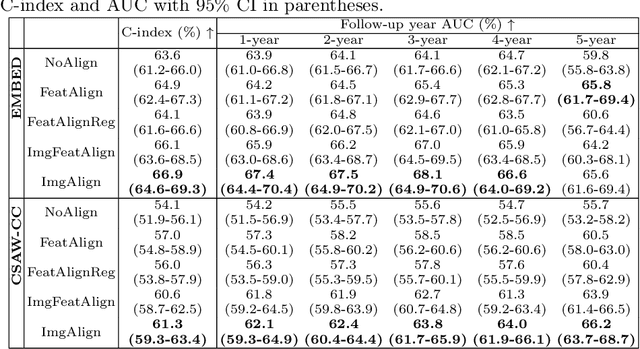
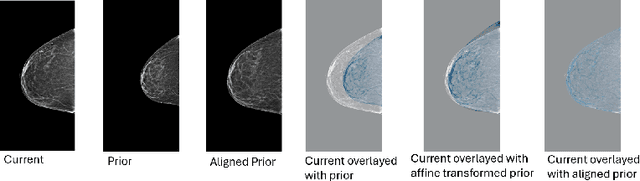

Regular mammography screening is essential for early breast cancer detection. Deep learning-based risk prediction methods have sparked interest to adjust screening intervals for high-risk groups. While early methods focused only on current mammograms, recent approaches leverage the temporal aspect of screenings to track breast tissue changes over time, requiring spatial alignment across different time points. Two main strategies for this have emerged: explicit feature alignment through deformable registration and implicit learned alignment using techniques like transformers, with the former providing more control. However, the optimal approach for explicit alignment in mammography remains underexplored. In this study, we provide insights into where explicit alignment should occur (input space vs. representation space) and if alignment and risk prediction should be jointly optimized. We demonstrate that jointly learning explicit alignment in representation space while optimizing risk estimation performance, as done in the current state-of-the-art approach, results in a trade-off between alignment quality and predictive performance and show that image-level alignment is superior to representation-level alignment, leading to better deformation field quality and enhanced risk prediction accuracy. The code is available at https://github.com/sot176/Longitudinal_Mammogram_Alignment.git.
BoxFusion: Reconstruction-Free Open-Vocabulary 3D Object Detection via Real-Time Multi-View Box Fusion
Jun 18, 2025Open-vocabulary 3D object detection has gained significant interest due to its critical applications in autonomous driving and embodied AI. Existing detection methods, whether offline or online, typically rely on dense point cloud reconstruction, which imposes substantial computational overhead and memory constraints, hindering real-time deployment in downstream tasks. To address this, we propose a novel reconstruction-free online framework tailored for memory-efficient and real-time 3D detection. Specifically, given streaming posed RGB-D video input, we leverage Cubify Anything as a pre-trained visual foundation model (VFM) for single-view 3D object detection by bounding boxes, coupled with CLIP to capture open-vocabulary semantics of detected objects. To fuse all detected bounding boxes across different views into a unified one, we employ an association module for correspondences of multi-views and an optimization module to fuse the 3D bounding boxes of the same instance predicted in multi-views. The association module utilizes 3D Non-Maximum Suppression (NMS) and a box correspondence matching module, while the optimization module uses an IoU-guided efficient random optimization technique based on particle filtering to enforce multi-view consistency of the 3D bounding boxes while minimizing computational complexity. Extensive experiments on ScanNetV2 and CA-1M datasets demonstrate that our method achieves state-of-the-art performance among online methods. Benefiting from this novel reconstruction-free paradigm for 3D object detection, our method exhibits great generalization abilities in various scenarios, enabling real-time perception even in environments exceeding 1000 square meters.